Автор: Денис Аветисян
Новое исследование показывает, способны ли большие языковые модели выделять тонкие детали в доказательствах, необходимые для проверки фактов.

Оценка возможностей современных моделей извлечения гранулированных доказательств на чешском и словацком языках.
Несмотря на растущую потребность в автоматизированной проверке фактов, точное выявление подтверждающих или опровергающих доказательств в текстах остается сложной задачей. В данной работе, посвященной вопросу ‘Can LLMs extract human-like fine-grained evidence for evidence-based fact-checking?’, исследованы возможности больших языковых моделей (LLM) в извлечении детальных доказательств для утверждений на чешском и словацком языках. Результаты анализа новой размеченной базы данных показали, что увеличение размера модели не всегда приводит к повышению точности извлечения доказательств, а некоторые модели демонстрируют оптимальное соотношение между размером и качеством. Возможно ли дальнейшее улучшение производительности LLM в задаче извлечения доказательств за счет разработки более эффективных методов обучения и архитектур?
Построение основы: Чешско-словацкий набор данных
Для адекватной оценки способности больших языковых моделей (LLM) извлекать релевантные доказательства из текста, необходимы надежные и качественные наборы данных, особенно для языков с богатой морфологией и ограниченными ресурсами. В отличие от языков с более простой структурой, где ключевые слова могут служить достаточным индикатором релевантности, для языков, таких как чешский и словацкий, требуется более тонкий подход, учитывающий различные формы слов и грамматические конструкции. Недостаток специализированных ресурсов для этих языков затрудняет объективную оценку LLM, что приводит к переоценке их возможностей или неспособности выявить реальные ограничения. Создание тщательно аннотированных наборов данных, учитывающих морфологическую сложность, становится критически важным шагом для продвижения исследований в области обработки естественного языка и разработки более эффективных и точных моделей.
Новый чешско-словацкий набор данных призван решить проблему оценки возможностей больших языковых моделей (LLM) в извлечении доказательств, предоставляя детальные аннотации, выходящие за рамки простого совпадения ключевых слов. В отличие от существующих наборов данных, ориентированных на поверхностный анализ, данный ресурс фокусируется на точной идентификации фрагментов текста, действительно поддерживающих или опровергающих конкретное утверждение. Это достигается за счет ручной разметки каждого релевантного участка, с указанием типа связи между доказательством и заявлением. Такой подход позволяет более глубоко оценить способность LLM к пониманию смысла и логической аргументации, а не только к поиску определенных слов или фраз, что является критически важным для задач, требующих высокого уровня точности и надежности.
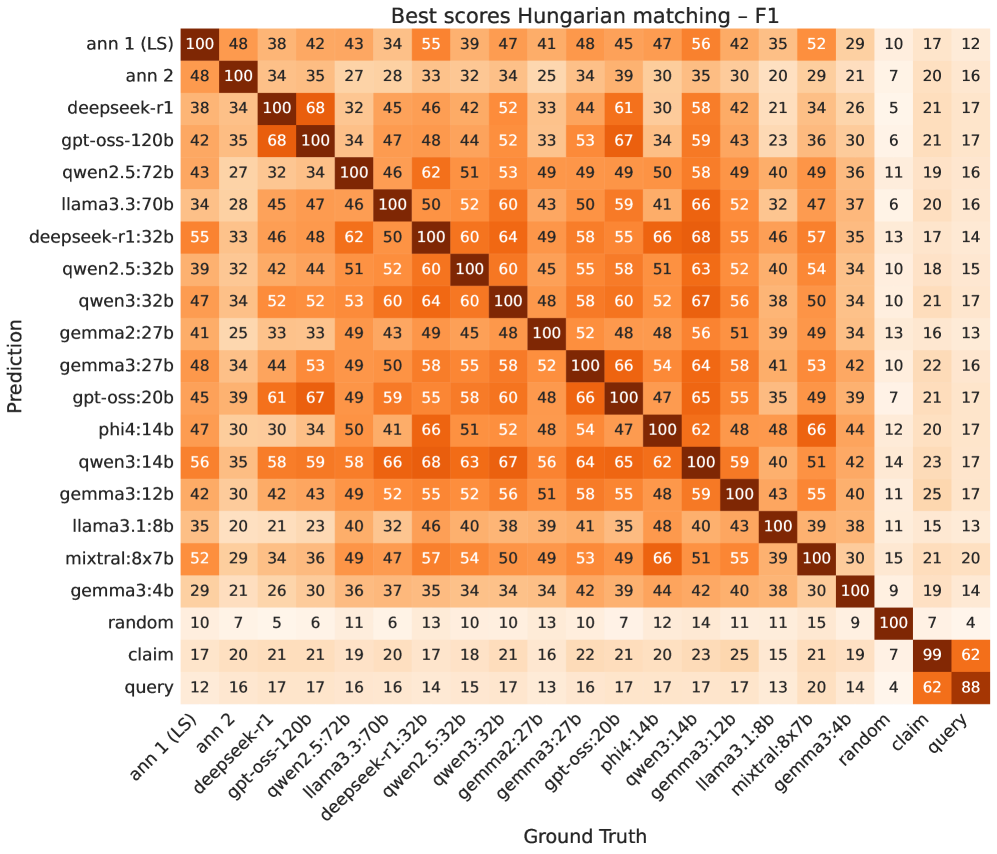
Для обеспечения достоверности и надежности разработанного чешско-словацкого набора данных, была проведена строгая оценка согласованности между аннотаторами. Этот процесс позволил установить, что уровень согласованности, измеренный с помощью F1-меры на уровне токенов, достиг 47%. Данный показатель свидетельствует о высокой степени консенсуса между экспертами в процессе разметки данных, что, в свою очередь, гарантирует, что набор данных представляет собой надежную и последовательную “истину”, необходимую для объективной оценки возможностей языковых моделей в извлечении доказательств и тонких смысловых нюансов. Высокая согласованность между аннотаторами является ключевым фактором, подтверждающим качество и пригодность набора данных для использования в качестве эталона в исследованиях.
Новый чешско-словацкий набор данных играет ключевую роль в объективной оценке возможностей больших языковых моделей (LLM) в области извлечения доказательств. Его создание позволило получить надежную основу для проведения сравнительного анализа и выявления слабых мест существующих алгоритмов. В отличие от упрощенных подходов, основанных на совпадении ключевых слов, данный набор данных обеспечивает оценку способности LLM к более тонкому пониманию контекста и выявлению релевантной информации. Это, в свою очередь, стимулирует дальнейшие исследования и разработки в области извлечения доказательств, направленные на повышение точности и надежности систем искусственного интеллекта, работающих с морфологически сложными и менее распространенными языками.
LLM и извлечение доказательств: Новые горизонты
Большие языковые модели (LLM) представляют собой перспективный подход к автоматическому выявлению и извлечению фрагментов текста, подтверждающих или опровергающих заданное утверждение. В отличие от традиционных методов информационного поиска, основанных на сопоставлении ключевых слов, LLM используют контекстное понимание и генеративные возможности для определения релевантных отрывков. Этот процесс включает в себя анализ семантической связи между утверждением и текстом, что позволяет моделям идентифицировать доказательства, даже если они не содержат точных совпадений по ключевым словам. Использование LLM для извлечения доказательств позволяет автоматизировать процесс анализа больших объемов текстовой информации и повысить эффективность проверки фактов и обоснования утверждений.
Для автоматического выявления и извлечения релевантных фрагментов текста, подтверждающих определенное утверждение, исследуются большие языковые модели (LLM), такие как DeepSeek-R1, Qwen3 и GPT-OSS. Эти модели демонстрируют способность к пониманию контекста и генерации текста, что позволяет им не просто находить ключевые слова, но и идентифицировать фрагменты, семантически связанные с заданным утверждением. Использование генеративных возможностей позволяет LLM формулировать ответ на основе извлеченных данных, а не просто возвращать релевантные отрывки, что повышает качество и точность извлеченной информации.
Недостаточно просто применить большие языковые модели (LLM) для извлечения доказательств из текста; для существенного повышения качества и релевантности извлеченных фрагментов необходимо использовать дополнительные техники, такие как constrained decoding. Этот метод ограничивает генерацию модели, направляя ее на выбор только тех токенов, которые соответствуют заданным критериям или шаблонам, что позволяет избежать нерелевантных или ошибочных извлечений. В частности, constrained decoding позволяет задавать ограничения на длину извлеченного фрагмента, его синтаксическую структуру или семантическую близость к исходному утверждению, что повышает точность и надежность автоматического извлечения доказательств.
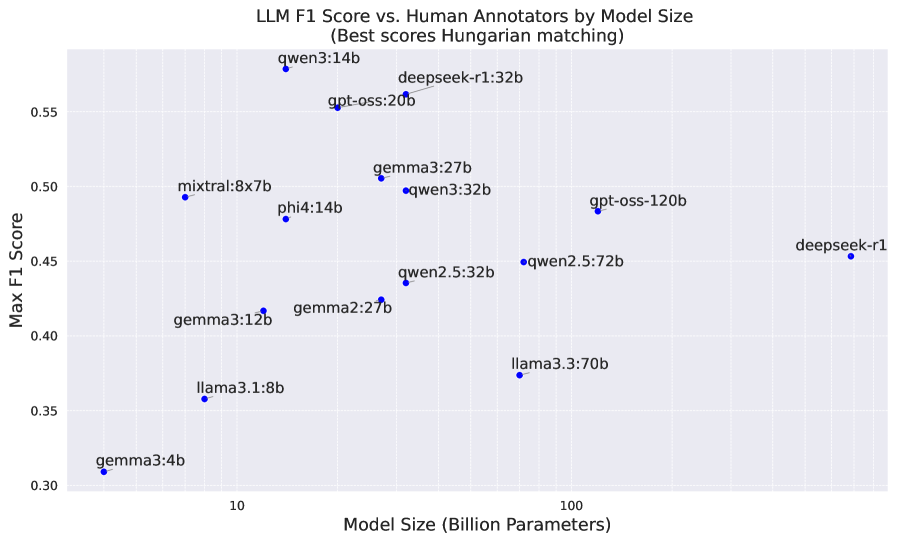
Новые методы извлечения доказательств, основанные на больших языковых моделях (LLM), таких как 14B Qwen3, 32B DeepSeek-R1 и 20B GPT-OSS, демонстрируют значительное улучшение по сравнению с традиционными методами информационного поиска. Эти модели, оцениваемые по токеному F1-счету до 56% в сравнении с ручной аннотацией, позволяют перейти от простого поиска ключевых слов к более глубокому семантическому пониманию контекста и релевантности доказательств. В отличие от традиционных систем, которые опираются на статистические соответствия, LLM способны учитывать сложные лингвистические связи и контекстуальные нюансы, что повышает точность и полноту извлеченных фрагментов текста, подтверждающих конкретное утверждение.
Оценка производительности: Базовые показатели и метрики
Оценка производительности больших языковых моделей (LLM) требует сопоставления с не-нейронными базовыми решениями, такими как Random Baseline, Claim Baseline и Query Baseline. Эти базовые модели служат точкой отсчета и позволяют установить минимальный порог производительности, определяя, насколько эффективно LLM превосходит случайные или упрощенные методы. Random Baseline генерирует ответы случайным образом, Claim Baseline основывается исключительно на утверждении вопроса, а Query Baseline использует только поисковый запрос без анализа контекста. Сравнение с этими базовыми решениями необходимо для объективной оценки прогресса и определения реальной ценности, вносимой нейронными моделями в задачу извлечения информации или ответов на вопросы.
Для точного вычисления метрики F1 на уровне токенов, необходимо использовать алгоритм венгерского метода (Hungarian algorithm). Этот алгоритм позволяет оптимально сопоставить токены, предсказанные моделью, с эталонными (ground truth) токенами, обеспечивая корректную оценку как точности (precision), так и полноты (recall). В отличие от простых методов сопоставления, венгерский метод гарантирует нахождение наилучшего соответствия, даже в случаях, когда количество предсказанных токенов не совпадает с количеством эталонных. Это критически важно для справедливого сравнения производительности различных языковых моделей и человеческих аннотаций, поскольку позволяет избежать завышения или занижения оценок из-за неоптимального сопоставления токенов.
Оценка на основе токенов F1 является ключевым показателем для определения степени соответствия извлеченных доказательств и эталонных данных. Этот показатель объединяет точность ($Precision = \frac{TruePositives}{TruePositives + FalsePositives}$) и полноту ($Recall = \frac{TruePositives}{TruePositives + FalseNegatives}$), вычисляя их гармоническое среднее. Высокий показатель F1 указывает на то, что модель способна точно извлекать релевантную информацию, минимизируя как ложные срабатывания (извлечение нерелевантных данных), так и ложные отрицания (пропуск релевантных данных). Использование токенов в качестве единицы измерения позволяет проводить более детальный анализ, чем оценка на уровне предложений или документов, и обеспечивает более точную оценку качества извлечения информации.
В ходе проведенных сравнительных тестов модели машинного обучения демонстрируют различную точность. В частности, модель mixtral:8x7b показала уровень ошибок в 61.8%, что указывает на частоту неверных ответов или неточного извлечения информации. При этом модель qwen2.5:72b достигла наименьшего уровня ошибок среди протестированных моделей, что свидетельствует о её более высокой эффективности в решении поставленных задач. Полученные результаты служат основой для дальнейшей оптимизации и разработки моделей, позволяя определить приоритетные направления улучшения и оценить прогресс в области искусственного интеллекта.
Влияние и перспективы развития
Точная экстракция доказательств имеет решающее значение для целого ряда приложений, требующих надежной обработки информации. В частности, эта способность играет ключевую роль в автоматической проверке фактов, где системы должны выявлять и подтверждать достоверность утверждений, опираясь на соответствующие источники. Не менее важна она и для систем ответов на вопросы, где извлечение релевантных доказательств позволяет генерировать точные и обоснованные ответы. В сфере юриспруденции, автоматизированное извлечение доказательств из правовых документов может существенно ускорить и упростить процесс анализа, а также повысить точность юридических заключений. Таким образом, развитие методов точной экстракции доказательств открывает новые возможности для создания интеллектуальных систем, способных надежно и эффективно обрабатывать информацию в различных областях.
Создание чешско-словацкого набора данных и соответствующей системы оценки представляет собой значимый вклад в область обработки естественного языка, особенно для языков с ограниченными ресурсами. Данный ресурс позволяет исследователям разрабатывать и тестировать модели извлечения доказательств и проверки фактов, не полагаясь на обширные корпусы текстов, доступные для таких языков, как английский. Уникальность этого набора данных заключается в его ориентации на сложные лингвистические особенности и культурные нюансы чешского и словацкого языков, что способствует созданию более точных и надежных систем искусственного интеллекта для этих регионов. Предоставление открытого доступа к этому набору данных и фреймворку оценки стимулирует дальнейшие исследования и способствует развитию технологий обработки языка для языков, которые исторически были недостаточно представлены в области искусственного интеллекта.
Дальнейшие исследования должны быть направлены на повышение устойчивости и обобщающей способности методов, основанных на больших языковых моделях (LLM), особенно в отношении обработки сложных и нюансированных утверждений. Существующие модели часто демонстрируют уязвимость при столкновении с утверждениями, требующими глубокого понимания контекста или учета различных интерпретаций. Работа в этом направлении предполагает разработку новых архитектур и методов обучения, способных улавливать тонкие смысловые оттенки и избегать поверхностных обобщений. Ключевым аспектом является создание моделей, которые не просто сопоставляют слова, но и способны к логическому выводу и критическому анализу информации, что позволит им более эффективно справляться с неоднозначными и противоречивыми данными. Успешное решение этой задачи откроет путь к созданию более надежных и заслуживающих доверия систем искусственного интеллекта.
Дальнейшее развитие методов извлечения доказательств и оценки достоверности информации открывает новые перспективы в области искусственного интеллекта. Ожидается, что усовершенствованные системы смогут не только автоматизировать процессы проверки фактов и ответов на вопросы, но и значительно повысить надежность и доверие к принимаемым ими решениям. Это особенно важно в критически важных областях, таких как юриспруденция, медицина и финансы, где точность и обоснованность информации имеют первостепенное значение. По мере развития технологий, можно ожидать появления более интеллектуальных систем, способных к критическому мышлению и выявлению скрытых противоречий, что приведет к созданию действительно надежных и заслуживающих доверия искусственных интеллектов.
Исследование, представленное в статье, акцентирует внимание на извлечении детализированных доказательств для проверки фактов на чешском и словацком языках. Это требует от больших языковых моделей не просто идентификации релевантной информации, но и понимания её нюансов и контекста. Как заметил Эдсгер Дейкстра: «Программирование похоже на создание маленькой вселенной». Подобно созданию вселенной, где каждая деталь имеет значение, извлечение точных доказательств требует внимательности к деталям и понимания взаимосвязей между ними. Работа с языковыми моделями показывает, что увеличение их размера не всегда приводит к пропорциональному улучшению качества извлечения доказательств, что подчеркивает важность не только мощности, но и продуманной структуры и логики системы.
Куда двигаться дальше?
Представленная работа, исследуя извлечение детализированных доказательств для проверки фактов, выявляет закономерность, знакомую любому, кто сталкивался со сложными системами: увеличение масштаба не всегда приводит к пропорциональному улучшению. Увеличение размеров языковых моделей демонстрирует эффект убывающей отдачи, что наводит на мысль о необходимости переосмысления архитектурных решений, а не только наращивания вычислительных мощностей. Инфраструктура должна развиваться без необходимости перестраивать весь квартал; подобно этому, развитие систем проверки фактов требует сосредоточиться на более тонких, структурных улучшениях.
Очевидным направлением дальнейших исследований представляется углубленное изучение влияния структуры данных и форматов аннотаций на эффективность моделей. Вместо слепого увеличения количества параметров, следует сосредоточиться на разработке более компактных и эффективных представлений знаний. Иными словами, элегантность решения часто заключается не в его сложности, а в простоте и ясности.
Не менее важным представляется расширение подобных исследований на другие языки и предметные области. Разнообразие лингвистических и культурных контекстов неизбежно выявит новые вызовы и ограничения существующих подходов. Подобно тому, как живой организм адаптируется к изменяющимся условиям среды, так и системы проверки фактов должны быть способны к эволюции и самосовершенствованию.
Оригинал статьи: https://arxiv.org/pdf/2511.21401.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- OM/USD
- SUI ПРОГНОЗ. SUI криптовалюта
2025-11-30 07:23