Автор: Денис Аветисян
Новое исследование показывает, как стремительное распространение поисковых систем на основе искусственного интеллекта трансформирует доступ к информации и влияет на наше восприятие мира.
Анализ влияния алгоритмов искусственного интеллекта на информационное пространство, подверженность дезинформации и потенциальные предвзятости в поисковых результатах.
Несмотря на стремительное развитие технологий искусственного интеллекта, влияние этих изменений на доступ к информации и формирование общественного мнения остается недостаточно изученным. В исследовании ‘The Rise of AI Search: Implications for Information Markets and Human Judgement at Scale’ проведен масштабный анализ 2,8 миллионов результатов поисковых запросов, выполненных в 243 странах в 2024-{2025} годах, который выявил резкое расширение использования AI-поиска и существенные изменения в представлении информации пользователям. Полученные данные свидетельствуют о политике AI-компаний, приводящей к неравномерному доступу к результатам AI-поиска, снижению разнообразия источников и увеличению доли информации с низкой достоверностью. Какие долгосрочные последствия эти тенденции окажут на информационную экосистему и принятие решений в масштабе общества?
От Слов к Смыслу: Эволюция Поиска
Традиционные методы поиска информации, основанные на сопоставлении ключевых слов, демонстрируют свою эффективность в простых запросах, однако сталкиваются с существенными ограничениями при обработке сложных и нюансированных формулировок. Поиск по ключевым словам зачастую не способен уловить истинный смысл вопроса, особенно если запрос содержит синонимы, метафоры или требует понимания контекста. В результате, пользователь может получить множество результатов, лишь косвенно относящихся к его потребности, что требует значительных усилий для фильтрации и анализа. В ситуациях, когда информация распределена по множеству источников и требует синтеза, традиционные системы оказываются неспособными предоставить готовый ответ, ограничиваясь лишь перечислением релевантных документов. Таким образом, несмотря на свою распространенность, существующие методы поиска все чаще не удовлетворяют растущие потребности пользователей в быстрой и точной информации.
Появление масштабных языковых моделей (LLM) знаменует собой переход от поиска по ключевым словам к пониманию смысла запроса, однако этот прогресс сопряжен с новыми трудностями. В отличие от традиционных систем, которые просто сопоставляют слова, LLM стремятся интерпретировать намерения пользователя и контекст вопроса. Это позволяет им предоставлять более релевантные и точные ответы, даже если запрос сформулирован неоднозначно или содержит сложные понятия. Вместе с тем, LLM подвержены галлюцинациям — генерации ложной информации, выдаваемой за факт — и могут быть подвержены манипуляциям через специально сформулированные запросы. Кроме того, обучение и функционирование таких моделей требует огромных вычислительных ресурсов и больших объемов данных, что ставит вопросы об их доступности и экологической устойчивости. Таким образом, хотя LLM открывают новые горизонты в области поиска информации, их внедрение требует решения серьезных технических и этических задач.
Новый подход к поиску информации, основанный на искусственном интеллекте, стремится к непосредственному синтезу ответов, минуя традиционный перечень ссылок. Вместо того чтобы просто находить документы, содержащие ключевые слова, система анализирует запрос и генерирует краткое, связное изложение ответа, что потенциально экономит время пользователя. Однако, подобная технология не лишена уязвимостей: непосредственная генерация ответов означает, что ИИ становится источником информации, и, следовательно, подвержен риску неточностей, предвзятости или даже намеренной дезинформации. В отличие от классического поиска, где пользователь сам оценивает достоверность найденных источников, в случае синтезированных ответов эта ответственность ложится на алгоритм, что требует разработки надежных механизмов проверки и верификации информации.
Проверка Реальности: Точность и Достоверность Источников
Основной риск использования поисковых систем на основе искусственного интеллекта заключается в возможности генерации “галлюцинаций” — предоставления неточной или неподтвержденной информации. Данное явление обусловлено особенностями работы больших языковых моделей, которые могут создавать правдоподобные, но ложные утверждения, не имеющие подтверждения в исходных данных. Эти “галлюцинации” могут проявляться в виде вымышленных фактов, неверных цитат или ложной атрибуции информации, что требует критической оценки полученных результатов и перепроверки данных из независимых источников. Вероятность возникновения галлюцинаций повышается при обработке сложных запросов или при недостатке достоверной информации по заданной теме.
Оценка достоверности источников информации становится все более сложной задачей в условиях быстро меняющегося онлайн-ландшафта. Традиционные методы, основанные на репутации домена или авторитете издателя, теряют эффективность из-за роста количества динамически генерируемого контента, пользовательских платформ и децентрализованных источников. Появление фейковых новостей, дезинформации и предвзятых материалов усугубляет проблему, требуя от пользователей критического подхода к оценке информации и использования специализированных инструментов для проверки фактов и определения предвзятости. Кроме того, алгоритмы поисковых систем и социальных сетей могут усиливать эффект «эхо-камер«, ограничивая доступ к разнообразным точкам зрения и затрудняя объективную оценку источников.
Для оценки надежности источников информации, используемых поисковыми системами на базе ИИ, существуют специализированные инструменты и сервисы. Платформа “Media Bias/Fact Check” предоставляет аналитические отчеты об уклоне и фактической точности новостных источников, оценивая их на основе методологии, включающей проверку фактов и анализ предвзятости. Сервис “Cisco Umbrella” в первую очередь предназначен для сетевой безопасности, но также предоставляет данные о репутации веб-сайтов, идентифицируя потенциально вредоносные или неблагонадежные ресурсы. Важно отметить, что эти инструменты не обеспечивают абсолютной гарантии достоверности, поскольку оценки могут быть субъективными или устаревшими, а также не учитывать контекст конкретной информации. Поэтому их следует использовать как часть комплексного подхода к оценке надежности источников.
Измеряя Влияние: Поведение Пользователей и Новые Метрики
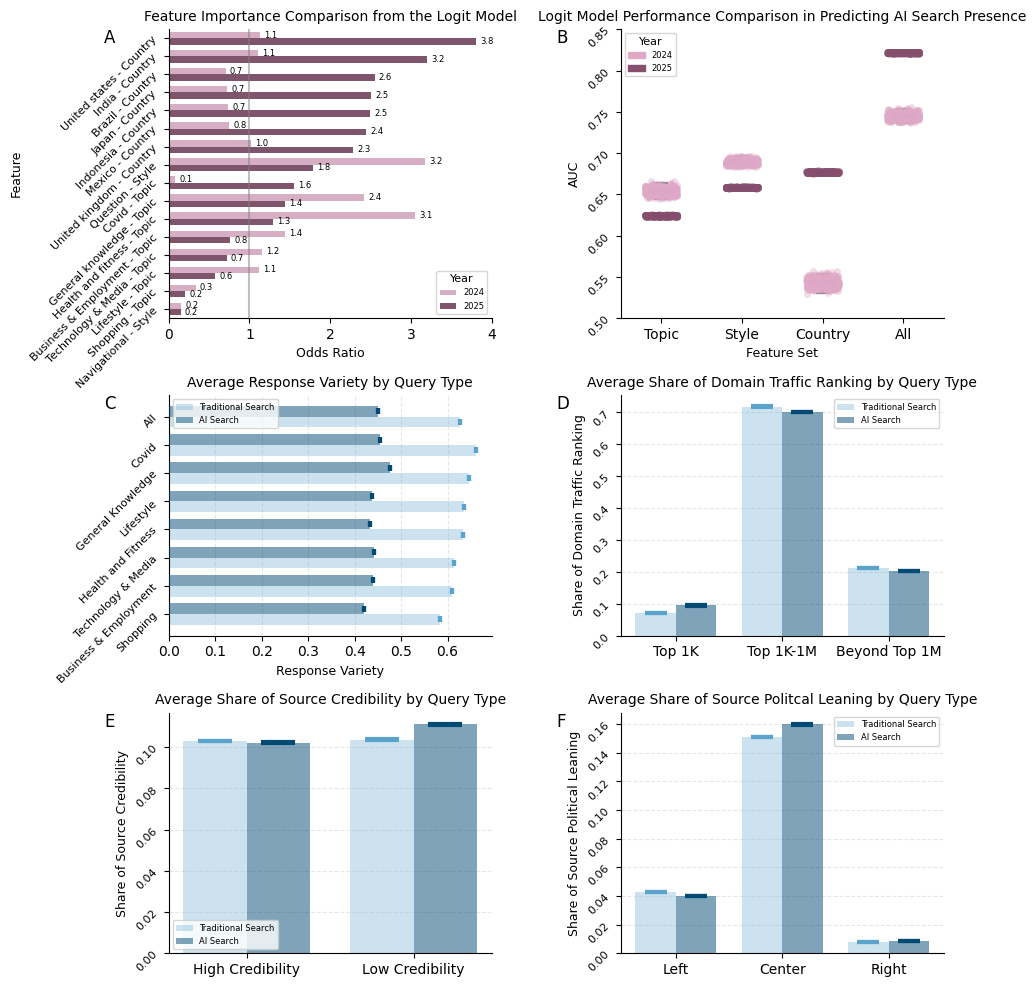
Мониторинг частоты выдачи ответов, сгенерированных искусственным интеллектом (AI Exposure), является ключевым фактором для оценки влияния AI на поведение пользователей в поисковых системах. Наблюдения показали стремительное расширение географии AI-поиска: если в 2024 году AI-ответы отображались в 7 странах, то к 2025 году их охват увеличился до 229 стран. Данный показатель свидетельствует о значительном росте интеграции AI в поисковые системы по всему миру и необходимости дальнейшего анализа его воздействия на пользовательский опыт и паттерны поиска.
Для анализа изменений в поисковом поведении и выявления закономерностей, связанных с использованием искусственного интеллекта, применяется анализ результатов поисковой выдачи (SERP) посредством SERP API. Этот подход позволяет собирать данные о представленных ответах и оценивать их разнообразие. В частности, используется метод SBERT (Sentence-BERT), позволяющий создавать векторные представления текстовых фрагментов и вычислять семантическую близость между ними. Измерение “Response Variety” (разнообразия ответов) позволяет количественно оценить, насколько различаются представленные в выдаче ответы, что, в свою очередь, может указывать на влияние AI-генерируемого контента и изменения в пользовательском поведении.
Анализ наборов данных, таких как ‘Natural Questions Dataset’ и ‘Google Trends’, позволяет получить ценную информацию о намерениях пользователей и их информационных потребностях. В ходе исследований было установлено, что пользователи, сталкивающиеся с AI-саммари в результатах поиска, демонстрируют показатель «Zero-Click Rate» в 80%, в то время как для пользователей, не взаимодействующих с AI-саммари, этот показатель составляет 60%. Разница в 20 процентных пунктов указывает на то, что AI-саммари, вероятно, удовлетворяют потребность пользователя в информации непосредственно в результатах поиска, снижая необходимость перехода на другие веб-сайты.
Анализ данных показал значительное увеличение видимости результатов, генерируемых искусственным интеллектом (AI), в поисковой выдаче в ряде ключевых стран. В Соединенных Штатах Америки этот показатель вырос на 67%, в Индии — на 60%, в Великобритании — на 54%, в Мексике — на 73%, в Индонезии — на 76%, в Японии — на 78%, а в Бразилии — на 82%. Данные изменения отражают расширение использования AI в поисковых системах в различных географических регионах и являются важным фактором при изучении влияния AI на поведение пользователей в сети.
Будущее Поиска: Баланс Инноваций и Доверия
Появление так называемых “поисковых запросов без кликов”, обусловленное развитием поисковых систем на основе искусственного интеллекта, представляет собой заметную тенденцию, потенциально снижающую посещаемость внешних веб-сайтов. Исследования показали, что при столкновении с кратким ответом, сгенерированным ИИ, количество переходов на другие ресурсы уменьшается на 8%, в то время как без такого ответа снижение составляет 15%. Это указывает на то, что пользователи всё чаще находят необходимую информацию непосредственно в результатах поиска, не переходя на указанные веб-сайты, что создает новые вызовы для контент-мейкеров и владельцев ресурсов в сети.
В связи с растущей обеспокоенностью по поводу контроля над информацией и потенциальной предвзятости, возникающей в результате использования алгоритмов искусственного интеллекта в поисковых системах, появились предложения о введении так называемого “минимального порога переходов по ссылкам” (Link-Out Floor). Эта регуляторная мера направлена на то, чтобы гарантировать, что поисковые системы предоставляют пользователям доступ к разнообразным источникам информации, а не ограничиваются лишь собственными агрегированными ответами. Предполагается, что установление минимального процента переходов на внешние веб-сайты стимулирует конкуренцию, поддерживает независимые источники информации и предотвращает монополизацию контента со стороны крупных технологических компаний. Реализация подобной инициативы может оказать существенное влияние на структуру интернет-пространства, обеспечивая более сбалансированный доступ к знаниям и снижая риски формирования искаженной картины мира.
Современный поисковый ландшафт претерпевает значительные изменения под влиянием систем на основе искусственного интеллекта, таких как Google Search, ChatGPT Search, Perplexity AI, Microsoft Bing и Arc Search. Эти платформы активно формируют способы получения информации пользователями, всё чаще предлагая прямые ответы, а не просто ссылки на веб-сайты. Особенно заметно это стало после подписания Исполнительного приказа 14149, который стимулировал использование ИИ для предоставления ответов на общественно значимые вопросы. В частности, зафиксировано впечатляющее увеличение — на 5600% — количества ответов, генерируемых ИИ на запросы, связанные с Covid-19, что демонстрирует растущую роль искусственного интеллекта в оперативном предоставлении актуальной и проверенной информации.
Исследование показывает, что современные поисковые системы, движимые большими языковыми моделями, формируют информационное пространство не как статичную структуру, а как динамичную экосистему. Каждая зависимость от алгоритма — это обещание, данное прошлому, и любое изменение в коде несет в себе потенциал для непредвиденных последствий. Как отмечал Андрей Колмогоров: «Математика — это искусство неверных предположений». Именно это справедливо и для информационных систем: их предсказуемость ограничена, а склонность к самовосстановлению, упомянутая в исследовании, лишь иллюзия контроля над сложной сетью взаимодействий. Системы растут, а не строятся, и попытки полного контроля над информацией обречены на провал.
Что дальше?
Исследование демонстрирует не просто рост популярности поисковых систем на основе искусственного интеллекта, а формирование новой информационной экосистемы. Экосистемы не строятся по чертежам, они растут, и каждое развертывание — это маленький апокалипсис, обнажающий новые уязвимости. Нельзя говорить о контроле над информацией, когда алгоритм сам определяет, что достойно внимания, а что — нет. Каждый архитектурный выбор, каждая оптимизация — это пророчество о будущем сбое, о новой форме предвзятости, о новом способе манипуляции.
Попытки “исправить” алгоритмы, вычистить данные — лишь временные меры. Истина не находится в данных, а рождается в столкновении различных точек зрения. Ограничение доступа к информации, даже во имя борьбы с дезинформацией, лишь ускоряет формирование эхо-камер, усиливает поляризацию. Реальная проблема не в алгоритмах, а в нашей готовности делегировать им суждения.
Документация? Никто не пишет пророчества после их исполнения. Следующий этап исследований должен быть направлен не на поиск “правильных” ответов, а на изучение динамики этой новой информационной экосистемы, на понимание того, как она формирует наше восприятие реальности, и какие последствия это может иметь в долгосрочной перспективе. И, возможно, на принятие того факта, что контроль над информацией — это иллюзия.
Оригинал статьи: https://arxiv.org/pdf/2602.13415.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-17 16:49