Автор: Денис Аветисян
В статье представлен комплексный подход к эффективному выявлению значимых последовательностей в базах данных, позволяющий оптимизировать процесс анализа и выделить наиболее релевантные паттерны.
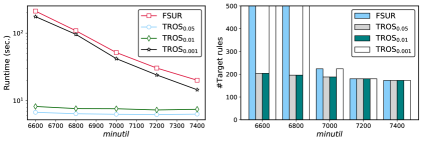
Оптимизированный майнинг последовательных правил с использованием стратегий отсечения, верхних границ и метрик схожести.
Поиск закономерностей в последовательностях данных часто затруднен вычислительной сложностью и избыточностью результатов. В данной работе, посвященной ‘Guided Exploration of Sequential Rules’, предложен комплексный подход к эффективному поиску целевых последовательных правил, основанный на стратегиях отсечения, верхних границах и метриках сходства. Разработанный метод позволяет снизить вычислительные затраты и выявлять наиболее релевантные закономерности, учитывая частоту и полезность правил. Не позволит ли данный подход значительно расширить возможности анализа последовательных данных в различных областях, таких как персонализированные рекомендации и прогнозирование поведения пользователей?
Раскрытие Скрытых Узоров: Основа Интеллектуального Анализа Данных
В современном мире, характеризующемся огромным объемом данных, простое хранение информации уже не является достаточным. Ценность заключается не в количестве накопленных данных, а в способности извлекать из них полезные знания и принимать обоснованные решения. Поэтому всё большее значение приобретают методы, позволяющие не просто агрегировать данные, но и выявлять скрытые закономерности и взаимосвязи, которые могут быть использованы для повышения эффективности, прогнозирования тенденций и получения конкурентных преимуществ. Наличие данных само по себе не гарантирует успеха; ключевым фактором является способность преобразовать их в действенные идеи и практические решения.
В эпоху обилия данных, простая их аккумуляция уже недостаточна; необходимы действенные выводы. Методы анализа закономерностей предоставляют инструменты для автоматического обнаружения этих выводов, выходя за рамки простого суммирования и агрегации информации. Вместо ручного поиска, алгоритмы способны самостоятельно выявлять скрытые связи и тенденции в больших объемах данных, позволяя извлекать ценные знания, которые иначе остались бы незамеченными. Этот автоматизированный процесс не только экономит время и ресурсы, но и позволяет обнаруживать неочевидные закономерности, способствующие принятию обоснованных решений и оптимизации различных процессов. Таким образом, анализ закономерностей представляет собой ключевой элемент в преобразовании необработанных данных в полезные знания.
Традиционные методы поиска закономерностей, несмотря на свою эффективность в выявлении статичных связей, зачастую оказываются недостаточно чувствительными к динамике данных, изменяющихся во времени. В то время как классические алгоритмы успешно идентифицируют общие тенденции, они испытывают трудности при анализе последовательностей событий, временных зависимостей и эволюционирующих паттернов. Это ограничение особенно заметно при работе с данными, характеризующимися высокой степенью изменчивости, например, в финансовых рынках, социальных сетях или системах мониторинга здоровья. Неспособность учитывать временной аспект может приводить к неполным или неточным выводам, что снижает ценность извлеченных знаний и ограничивает возможности прогнозирования и принятия решений. Поэтому, для эффективного анализа данных, подверженных временным изменениям, требуется разработка специализированных методов, способных учитывать последовательность событий и динамику отношений между ними.
Последовательные Инсайты: Добыча Временных Связей
Последовательная интеллектуальный анализ данных (sequential pattern mining) представляет собой расширение традиционных методов поиска закономерностей, вводящее учёт временной последовательности событий. В отличие от классического поиска ассоциативных правил, где порядок элементов не имеет значения, последовательный анализ данных выявляет закономерности, основанные на конкретном порядке следования событий во времени. Это позволяет обнаруживать правила типа «клиенты, совершившие покупку A в понедельник, с высокой вероятностью приобретут товар B на следующей неделе», что невозможно при использовании методов, не учитывающих временной аспект. Такой подход особенно важен при анализе данных, связанных с временными рядами, логами событий или транзакциями, где порядок следования имеет решающее значение для выявления значимых связей.
Анализ последовательностей позволяет выявлять закономерности в поведении клиентов, например, предсказывать вероятность приобретения товара Y клиентом, совершившим покупку товара X на следующей неделе. Такие закономерности строятся на основе временной упорядоченности событий и могут использоваться для персонализированных рекомендаций, оптимизации маркетинговых кампаний и прогнозирования спроса. Данный подход отличается от традиционного анализа ассоциативных правил, который не учитывает временной аспект, и позволяет получить более точные и релевантные результаты при работе с данными, характеризующимися временной зависимостью.
Ассоциативные правила являются ключевым компонентом последовательного анализа данных, поскольку они позволяют количественно оценить взаимосвязь между элементами в последовательности событий. Эти правила формируются на основе таких показателей, как уверенность (confidence), поддержка (support) и прирост (lift), определяющих статистическую значимость и силу связи между предшествующими и последующими элементами. Например, правило вида “{A} -> {B}” указывает, что наличие элемента A в последовательности увеличивает вероятность появления элемента B. Численные значения уверенности, поддержки и прироста позволяют ранжировать правила и выделять наиболее значимые закономерности в данных, что критически важно для прогнозирования и принятия решений.
Надежность обнаруженных последовательных правил оценивается с использованием метрик, ключевой из которых является уверенность (confidence). Уверенность представляет собой долю последовательностей, содержащих прецедент (antecedent), в которых также присутствует консеквент (consequent). Формально, уверенность правила вида {A} -> {B} рассчитывается как confidence(A \rightarrow B) = support(A \cup B) / support(A), где support(X) — частота появления набора элементов X в базе данных последовательностей. Высокое значение уверенности указывает на сильную связь между прецедентом и консеквентом, позволяя делать более надежные прогнозы о будущих событиях на основе исторических данных.
Точность и Эффективность: Целенаправленное Обнаружение Шаблонов
Целевое обнаружение шаблонов (TaPM) решает задачу фокусировки процесса поиска, предоставляя пользователям возможность задавать предпочтения и ограничения. В отличие от традиционных методов, которые исследуют все возможные комбинации, TaPM позволяет сузить область поиска, указывая, например, минимальную частоту появления шаблона, его важность или конкретные атрибуты данных, которые необходимо учитывать. Это достигается за счет интеграции пользовательских критериев непосредственно в алгоритм поиска, что позволяет исключить из рассмотрения нерелевантные или неинтересные шаблоны и повысить эффективность анализа данных, особенно в больших базах данных.
Для повышения эффективности поиска закономерностей в больших базах данных используются методы фильтрации базы данных и вычисления верхней границы. Фильтрация базы данных позволяет исключить из рассмотрения транзакции, которые не соответствуют заданным критериям, значительно уменьшая объем данных для анализа. Вычисление верхней границы позволяет оценить потенциальную прибыльность (utility) закономерности на этапе поиска, отбрасывая те, которые не могут достичь заданного минимального порога. Комбинация этих методов позволяет существенно сократить пространство поиска, снижая вычислительные затраты и время выполнения алгоритмов поиска закономерностей.
Целевое обнаружение закономерностей (TaPM) использует метрики, такие как минимальная поддержка и пороги полезности, для фильтрации неинтересных или незначимых закономерностей. Минимальная поддержка определяет минимальное количество транзакций, в которых должна встречаться закономерность, чтобы она была учтена. Порог полезности, в свою очередь, оценивает закономерность на основе как частоты ее появления, так и значимости отдельных элементов, входящих в закономерность. Комбинированное использование этих метрик позволяет существенно сократить объем поиска и сосредоточиться на действительно релевантных данных, повышая эффективность анализа и снижая вычислительные затраты.
Метрика полезности (utility) оценивает шаблоны (patterns) не только по частоте их появления, но и по значимости каждого элемента в транзакциях. Для эффективной обработки данных используется структура данных — utility-list, позволяющая быстро вычислять полезность шаблонов и отфильтровывать нерелевантные. Наши исследования показывают, что применение данного подхода обеспечивает прирост производительности до одного порядка величины (10x) в задачах поиска шаблонов по метрике полезности, по сравнению с традиционными методами, ориентированными исключительно на частоту.
Измерение Сходства Шаблонов: Определение Релевантности
Оценка значимости обнаруженной закономерности требует количественного определения ее схожести с запросом или целевым объектом пользователя. Простое выявление часто встречающихся комбинаций элементов недостаточно; необходимо установить, насколько эти комбинации соответствуют изначальным потребностям или интересу. Для этого используются различные метрики, позволяющие измерить степень перекрытия или соответствия между найденной закономерностью и заданным критерием. Без такой количественной оценки сложно определить, действительно ли обнаруженная закономерность полезна или представляет собой лишь случайное совпадение, что критически важно для практического применения методов анализа данных и извлечения знаний.
Для формальной оценки соответствия обнаруженной закономерности запросу пользователя или целевому признаку применяются метрики, такие как коэффициент сходства Дайса для целевых правил (TROS) и коэффициент Жаккара для целевых правил (TRJS). Эти метрики позволяют количественно определить степень перекрытия между элементами, входящими в обнаруженную закономерность, и элементами, представляющими интерес для пользователя. TROS и TRJS вычисляются на основе принципов теории множеств, учитывая как количество общих элементов, так и общую размерность рассматриваемых множеств. Использование данных метрик обеспечивает объективную и воспроизводимую оценку релевантности, что крайне важно для задач анализа данных и извлечения знаний, позволяя ранжировать закономерности по степени соответствия заданным критериям.
Оценка поддержки и частоты встречаемости паттернов остается ключевым аспектом анализа данных. Эти метрики позволяют понять, насколько распространен тот или иной паттерн в исследуемом наборе данных, что существенно для интерпретации результатов и определения значимости обнаруженных закономерностей. Высокая частота встречаемости указывает на более надежную и, вероятно, более важную связь между элементами данных, в то время как низкая частота может свидетельствовать о случайном совпадении или нишевом явлении. Таким образом, расчет поддержки и частоты предоставляет необходимый контекст для понимания значимости и применимости найденных паттернов, дополняя метрики, оценивающие сходство с запросом пользователя.
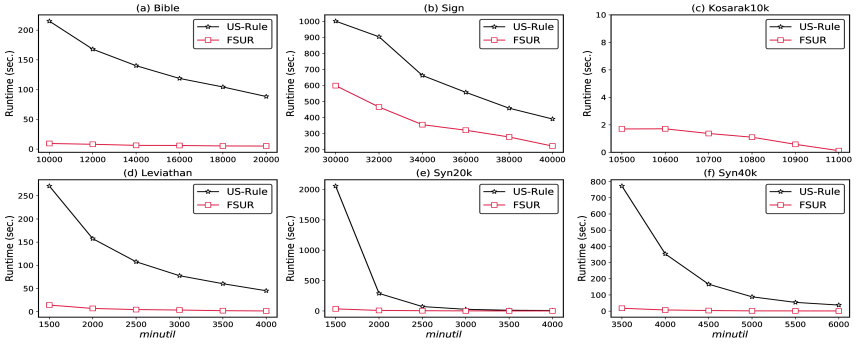
Предложенное решение демонстрирует производительность, сопоставимую с передовым алгоритмом TaSRM в задаче поиска часто встречающихся закономерностей. В ходе тестирования на библейском корпусе данных, новая методика позволила снизить количество расширений (expansions) в 20 раз по сравнению с базовым подходом FSURfilter. Это указывает на значительное повышение эффективности и оптимизацию процесса поиска, что позволяет обрабатывать большие объемы данных с меньшими вычислительными затратами и быстрее выявлять релевантные закономерности.
За Пределами Основ: Уточнение и Расширение Правил
Методы расширения правил, включающие в себя как левое, так и правое расширение, позволяют создавать более сложные и информативные правила, выходящие за рамки первоначальных ограничений. Изначально сформулированное правило, описывающее определенную закономерность, может быть дополнено новыми условиями или атрибутами слева (левое расширение), что уточняет контекст его применения. Аналогично, правое расширение позволяет добавить новые следствия или детали к результату, определяемому правилом. Такой подход позволяет не только углубить понимание взаимосвязей в данных, но и значительно повысить точность прогнозирования и детализацию получаемых знаний, открывая возможности для выявления более тонких и сложных закономерностей.
Методики итеративной доработки существующих правил позволяют значительно повысить их точность и прогностическую способность. В процессе такой доработки, правила не просто расширяются, но и подвергаются тонкой настройке на основе анализа данных и выявления закономерностей. Данный подход позволяет выявлять и устранять неточности, а также адаптировать правила к изменяющимся условиям. Постепенное улучшение правил, основанное на обратной связи от данных, обеспечивает более надежные и эффективные прогнозы, что особенно важно в сложных системах, где требуется высокая степень точности и адаптивности. Такой метод позволяет извлекать более глубокие знания из данных, чем простое применение фиксированных правил.
Сочетание целенаправленной добычи закономерностей и расширения правил открывает новые возможности для автоматического открытия знаний. Исследования показывают, что предварительное выявление значимых паттернов в данных, а затем использование этих паттернов для направленного расширения существующих правил, позволяет создавать более точные и информативные модели. Такой подход позволяет не просто генерировать сложные правила, но и автоматизировать процесс обнаружения скрытых взаимосвязей и закономерностей, которые ранее требовали ручного анализа. В результате, системы, использующие данный метод, способны самостоятельно извлекать ценную информацию из больших объемов данных, что особенно актуально в областях, где требуется постоянное обновление знаний и адаптация к изменяющимся условиям.
Полученные результаты демонстрируют, что применение более строгих ограничений к процессу расширения правил приводит к заметному, хотя и варьирующемуся, снижению их количества. Особенно выражен этот эффект на менее плотных наборах данных, что указывает на значительный потенциал для дальнейшей оптимизации алгоритмов. Данное наблюдение позволяет предположить, что точная настройка параметров, контролирующих расширение правил, может существенно повысить эффективность автоматического извлечения знаний и снизить вычислительные затраты, связанные с обработкой больших объемов информации. Такой подход открывает возможности для создания более компактных и точных моделей, применимых в различных областях, от анализа данных до разработки систем искусственного интеллекта.
Исследование, представленное в данной работе, фокусируется на оптимизации процесса поиска последовательных правил в базах данных, используя стратегии отсечения и метрики схожести для снижения вычислительных затрат. Этот подход перекликается с идеями Марвина Мински, который однажды сказал: «Лучший способ думать о будущем — это создать его». Подобно тому, как Мински подчеркивал важность активного формирования будущего, данная работа предлагает не просто пассивный поиск закономерностей, а активное управление процессом обнаружения наиболее релевантных последовательных правил, что позволяет более эффективно использовать ресурсы базы данных и извлекать полезную информацию. Оптимизация, представленная в статье, направлена на создание более продуктивного «будущего» анализа данных.
Куда Ведет Дорога?
Представленная работа, стремясь к оптимизации поиска последовательных правил, неминуемо сталкивается с фундаментальным вопросом: достаточно ли совершенства в алгоритмах, чтобы отсрочить неизбежное усложнение систем? Каждая оптимизация — лишь временная передышка, каждое правило, найденное в базе данных, — ещё один кирпичик в постоянно растущем, и в конечном счёте, неконтролируемом сооружении. Поиск «релевантных» паттернов, как и любая попытка упорядочить хаос, не отменяет его существование, а лишь временно маскирует.
Будущие исследования, вероятно, будут сосредоточены на адаптивности алгоритмов к изменяющимся данным — на способности системы «забывать» устаревшее, чтобы освободить место для нового. Однако, и это стоит признать, даже самая гибкая система не может избежать эрозии, вызванной временем. Стабильность, демонстрируемая алгоритмом сегодня, может оказаться лишь иллюзией, за которой скрывается медленное накопление ошибок, невидимых невооружённым взглядом.
В конечном счёте, ценность подобных исследований не в достижении абсолютной эффективности, а в понимании границ применимости наших методов. Система стареет не из-за ошибок, а из-за неизбежности времени. И иногда, самая мудрая стратегия — не пытаться её удержать, а достойно принять её увядание.
Оригинал статьи: https://arxiv.org/pdf/2602.16717.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-23 02:17