Автор: Денис Аветисян
Исследователи предлагают инновационный подход к задаче ранжирования, основанный на генеративных моделях и принципах шумоподавления.
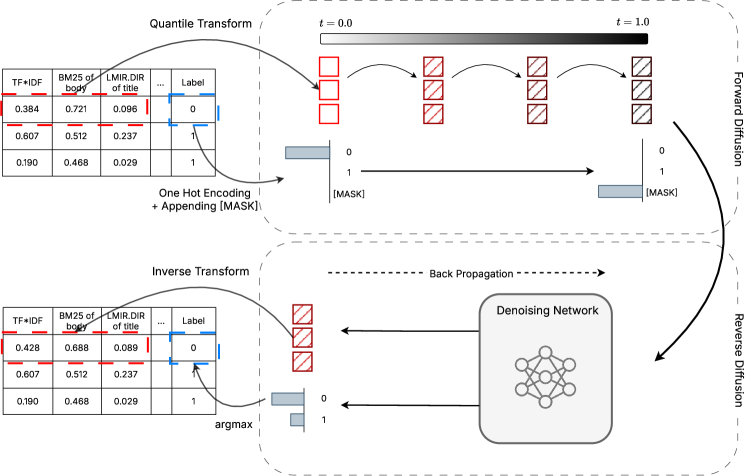
В статье представлена DiffusionRank — модель диффузии для обучения ранжированию, демонстрирующая повышенную точность и устойчивость при работе с табличными данными.
Традиционные методы обучения ранжированию часто ограничиваются дискриминативным моделированием вероятности релевантности документа запросу. В работе ‘From Noise to Order: Learning to Rank via Denoising Diffusion’ предложен альтернативный генеративный подход, основанный на диффузионных моделях, который моделирует совместное распределение признаков и меток релевантности. Разработанная DiffusionRank демонстрирует значительное улучшение точности и устойчивости по сравнению с дискриминативными методами, расширяя возможности TabDiff для задач ранжирования. Каковы перспективы дальнейшего использования прогресса в области генеративного моделирования, в частности диффузионных моделей, для повышения эффективности систем информационного поиска?
Точность ранжирования: вызовы и перспективы
Точность ранжирования результатов поиска играет фундаментальную роль в современной информационно-поисковой деятельности, оказывая непосредственное влияние на пользовательский опыт и общее качество поисковой системы. Эффективное ранжирование позволяет пользователям быстро находить наиболее релевантную информацию, экономя время и повышая удовлетворенность. В противном случае, неточные результаты могут привести к разочарованию, потере доверия и, как следствие, к отказу от использования конкретного поискового сервиса. Таким образом, постоянное совершенствование алгоритмов ранжирования является ключевой задачей для обеспечения удобства и эффективности поиска информации в цифровом мире.
Традиционные методы обучения ранжированию (LTR), несмотря на свою эффективность, зачастую сталкиваются с трудностями при обработке сложных распределений данных и масштабируемости. По мере роста объемов информации и усложнения поисковых запросов, классические алгоритмы, такие как Pointwise, Pairwise и Listwise подходы, испытывают ограничения в вычислительных ресурсах и способности эффективно обобщать данные. Это связано с тем, что они часто предполагают определенные упрощения в структуре данных, которые не всегда соответствуют реальным условиям. Например, обработка длинных списков результатов или учет контекстных факторов, таких как местоположение пользователя или история поиска, может значительно увеличить вычислительную сложность. Поэтому, разработка более эффективных и масштабируемых методов LTR, способных адаптироваться к изменяющимся данным и учитывать сложные взаимосвязи, остается актуальной задачей в области информационного поиска.
Существующие подходы к ранжированию информации зачастую не в полной мере учитывают тонкости оценки релевантности, отраженные в данных «Метки релевантности». Традиционные алгоритмы, хотя и демонстрируют неплохие результаты, склонны упрощать сложные взаимосвязи между запросом и документом, игнорируя контекстуальные нюансы и субъективные факторы, влияющие на восприятие релевантности пользователем. Это приводит к тому, что документы, действительно полезные в определенной ситуации, могут быть недооценены, а менее значимые — переоценены. Анализ данных «Метки релевантности» показывает, что оценка релевантности не является однозначной и линейной, а представляет собой многомерное пространство, требующее более сложных моделей и алгоритмов для адекватного отображения и учета всех влияющих факторов. Таким образом, для повышения точности ранжирования необходимо разрабатывать подходы, способные более полно и детально учитывать нюансы, заложенные в данных о релевантности.
Генеративное ранжирование: новый взгляд на задачу
Генеративное рейтинг (Generative Ranking) использует возможности диффузионных моделей (Diffusion Models) для изучения сложных распределений данных и формирования более точных ранжирований. В отличие от традиционных методов, которые предсказывают релевантность по отдельным признакам, диффузионные модели стремятся смоделировать вероятностное распределение данных в целом. Это позволяет им учитывать взаимосвязи между признаками и генерировать ранжирования, отражающие более полную картину релевантности. Эффективность подхода заключается в способности модели улавливать сложные зависимости в данных и адаптироваться к различным типам запросов и документов, что приводит к повышению точности ранжирования по сравнению с традиционными методами.
В отличие от традиционных методов ранжирования, которые предсказывают релевантность документа по отдельности, генеративные модели ранжирования моделируют распределение данных в целом. Этот подход позволяет учитывать взаимосвязи между документами и запросами, а также неопределенность в данных. Вместо выдачи единой оценки релевантности, модель генерирует распределение вероятностей для каждого документа, отражающее степень его соответствия запросу. Это обеспечивает более устойчивые результаты, особенно в случаях неполных или зашумленных данных, и позволяет модели адаптироваться к изменениям в данных более эффективно, чем методы, основанные на предсказании отдельных оценок.
Эффективность генеративного ранжирования напрямую зависит от корректного моделирования как числовых, так и категориальных признаков. Для числовых признаков применяются стандартные диффузионные процессы, основанные на добавлении гауссовского шума и последующем его удалении. Категориальные признаки требуют специализированных подходов, таких как дискретизация и использование вероятностных моделей для представления их распределения. Оптимальное комбинирование этих диффузионных процессов, учитывающее специфику каждого типа признаков, критически важно для обучения модели и обеспечения высокой точности ранжирования. Недостаточное внимание к моделированию категориальных признаков может привести к снижению производительности системы, особенно в задачах, где эти признаки имеют значительное влияние на релевантность.
DiffusionRank: расширение возможностей табличных диффузионных моделей для ранжирования
Модель DiffusionRank представляет собой расширение архитектуры TabDiff, изначально разработанной для работы с табличными данными, и адаптировано для задачи обучения ранжированию (learning-to-rank). В отличие от традиционных подходов, DiffusionRank использует принципы диффузионных моделей для генерации релевантных документов в ответ на запрос. Этот переход позволяет модели эффективно моделировать сложные взаимосвязи между запросами и документами, используя данные в табличном формате для представления характеристик как запросов, так и документов. Адаптация TabDiff для ранжирования включает в себя модификацию структуры модели и функций потерь, чтобы соответствовать специфике задачи ранжирования, позволяя использовать преимущества генеративного подхода для повышения точности и эффективности.
Расширение модели TabDiff для задачи ранжирования позволяет эффективно учитывать сложные взаимосвязи между запросами и документами, что приводит к повышению точности ранжирования. Это достигается за счет способности модели улавливать нелинейные зависимости и учитывать контекст как запроса, так и документа при оценке их релевантности. В отличие от традиционных методов, которые могут упрощать эти взаимосвязи, DiffusionRank способен моделировать более тонкие нюансы, что особенно важно при обработке больших объемов данных и разнообразных запросов. Повышенная точность ранжирования напрямую влияет на качество результатов поиска и пользовательский опыт.
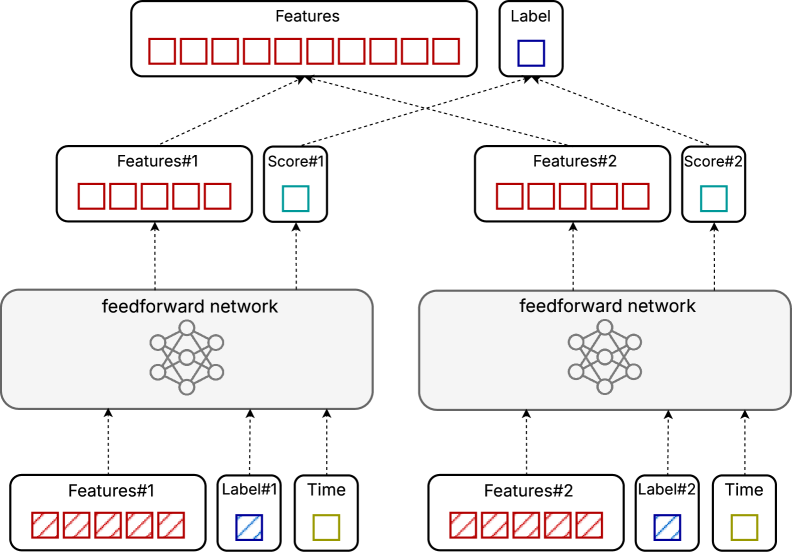
Модель DiffusionRank предоставляет возможность реализации как pointwise, так и pairwise подходов к задаче обучения ранжированию, что обеспечивает гибкость в проектировании модели. Pointwise подход рассматривает каждую релевантность документа для запроса независимо, предсказывая оценку релевантности для каждого документа. Pairwise подход, напротив, фокусируется на сравнении пар документов для заданного запроса, определяя, какой из документов более релевантен. Выбор между этими подходами позволяет адаптировать модель к специфическим требованиям задачи и доступным данным, оптимизируя производительность и точность ранжирования.
В основе архитектуры DiffusionRank лежит многослойная нейронная сеть прямого распространения (Feedforward Network), обеспечивающая функционирование как дискриминативных, так и генеративных компонентов модели. Дискриминативная часть сети используется для оценки релевантности документов для заданного запроса, определяя вероятность релевантности. Генеративный компонент, напротив, отвечает за создание представлений документов и запросов в скрытом пространстве, что позволяет модели учитывать сложные взаимосвязи между ними. Такая конструкция позволяет DiffusionRank эффективно решать задачу ранжирования, комбинируя преимущества дискриминативного анализа и генеративного моделирования данных.
Оценка эффективности DiffusionRank: результаты и сравнительный анализ
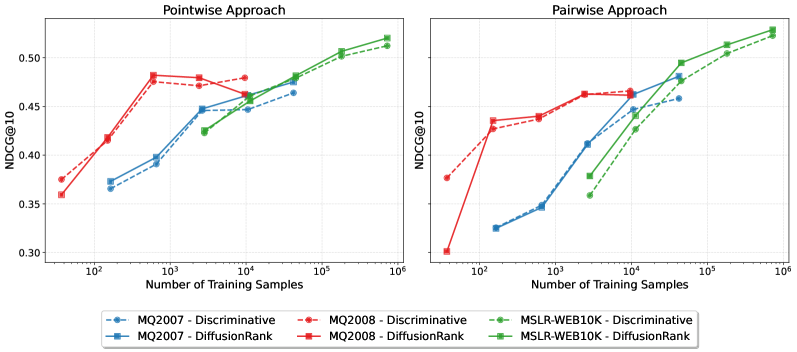
Исследования, проведенные на широко используемых наборах данных, таких как LETOR 4.0 и MSLR-WEB10K, наглядно демонстрируют эффективность алгоритма DiffusionRank в задачах ранжирования. Анализ результатов показал, что DiffusionRank успешно справляется со сложными запросами и способен предоставлять релевантные результаты, что подтверждается его способностью эффективно обрабатывать большие объемы данных и учитывать различные факторы, влияющие на релевантность. Данные наборы данных, известные своей репрезентативностью и разнообразием, позволили всесторонне оценить возможности DiffusionRank и подтвердить его потенциал для улучшения качества поиска и повышения удовлетворенности пользователей.
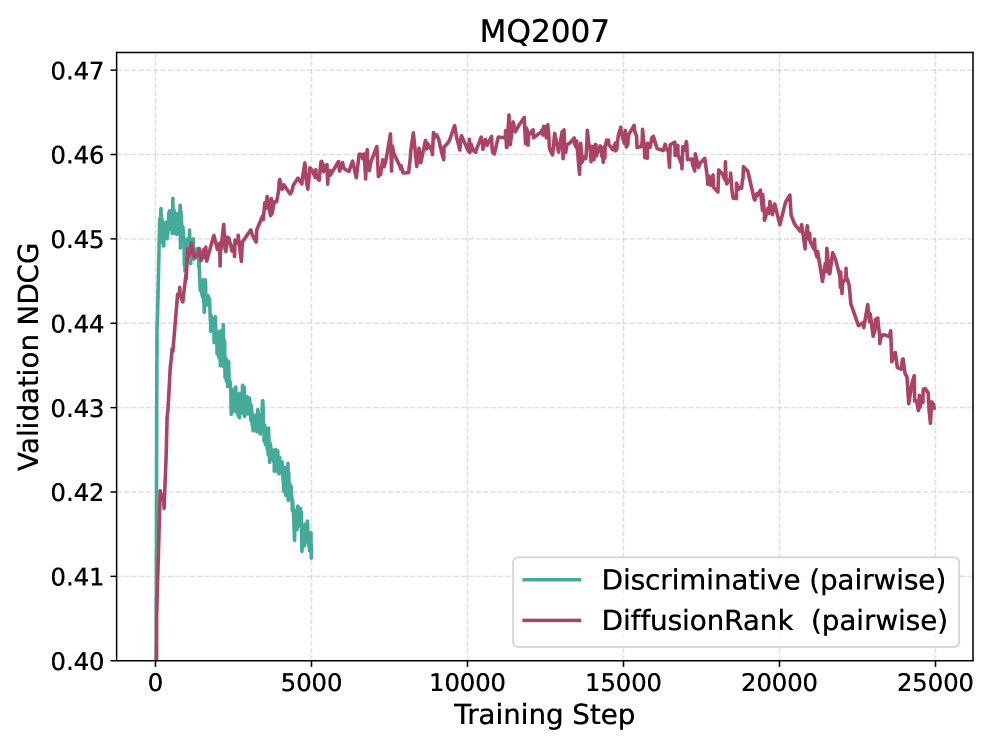
Оценка эффективности DiffusionRank проводилась с использованием общепринятых метрик, таких как MAP и NDCG, и продемонстрировала конкурентоспособные результаты по сравнению с существующими моделями обучения ранжированию, включая XGBoost. В ходе экспериментов DiffusionRank последовательно превосходил дискриминативные базовые модели, демонстрируя улучшение показателей MAP@10 и NDCG@10. Данное превосходство указывает на способность DiffusionRank более эффективно учитывать сложные взаимосвязи между объектами ранжирования, обеспечивая более релевантные и точные результаты поиска.
Результаты исследований демонстрируют значительный потенциал генеративных подходов в решении сложных задач ранжирования и повышении качества поисковой выдачи. Проведенные эксперименты на общепризнанных наборах данных MSLR-WEB10K и MQ2007 показали статистически значимые улучшения (p < 0.05), подтверждающие эффективность DiffusionRank в сравнении с традиционными методами. Это указывает на перспективность использования генеративных моделей для создания более релевантных и точных систем ранжирования, способных лучше соответствовать потребностям пользователей и эффективно обрабатывать сложные поисковые запросы.
Предложенный подход DiffusionRank, стремясь к упорядочиванию данных через денойзинг, несомненно, отражает стремление к элегантности в архитектуре систем. Как заметил Роберт Тарьян: «Простота — это высшая степень изысканности». В данном исследовании, подобно созданию живого организма, модель не просто оценивает релевантность, но и генерирует её, учитывая взаимодействие табличных признаков. Этот акцент на структуре, определяющей поведение системы, особенно важен при обучении ранжированию, где даже незначительные изменения в данных могут привести к существенным последствиям. Авторы подчеркивают важность робастности, что, в свою очередь, указывает на понимание того, что хорошая система должна быть устойчива к шуму и неопределенности.
Куда дальше?
Представленная работа, демонстрируя потенциал диффузионных моделей в задаче обучения ранжированию, неизбежно поднимает вопросы о границах применимости и истинной стоимости подобного подхода. Элегантность архитектуры, заключающаяся в совместном моделировании признаков и релевантности, покажется очевидной лишь тогда, когда система столкнется с данными, выходящими за рамки привычной структуры. Очевидно, что упрощение сложных взаимосвязей, неизбежное при любом моделировании, рано или поздно проявится в виде непредсказуемых ошибок.
Дальнейшие исследования должны быть направлены не только на повышение точности, но и на понимание устойчивости DiffusionRank к шуму и неполноте данных. Интересно было бы изучить возможности адаптации модели к различным типам табличных данных, а также рассмотреть способы интеграции с другими методами обучения ранжированию. В конечном итоге, ценность этой работы будет определяться не столько абсолютной производительностью, сколько способностью создавать системы, которые предсказуемо работают даже в условиях неопределенности.
Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. Истинное испытание для DiffusionRank — это не демонстрация превосходства на стандартных наборах данных, а способность адаптироваться и сохранять работоспособность в реальном, хаотичном мире информации.
Оригинал статьи: https://arxiv.org/pdf/2602.11453.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-16 02:02