Автор: Денис Аветисян
Новая система использует возможности больших мультимодальных языковых моделей и экспертные знания для выявления дефектов на производстве без трудоемкой дообучающей оптимизации.

Представлен фреймворк EAGLE, использующий экспертное сопровождение и механизмы внимания для точного обнаружения аномалий в мультимодальных данных, не требуя тонкой настройки модели.
Обнаружение аномалий в промышленности критически важно для интеллектуального производства, однако многие существующие подходы глубокого обучения ограничиваются выдачей лишь бинарных решений без детальных объяснений. В данной работе представлена методика ‘EAGLE: Expert-Augmented Attention Guidance for Tuning-Free Industrial Anomaly Detection in Multimodal Large Language Models’, предлагающая фреймворк, не требующий дополнительной настройки моделей, который объединяет экспертные модели с мультимодальными большими языковыми моделями (MLLM) для точного обнаружения аномалий и формирования семантически понятных описаний. Эксперименты на наборах данных MVTec-AD и VisA показали, что EAGLE улучшает производительность обнаружения аномалий в различных MLLM без обновления параметров, достигая результатов, сравнимых с методами, основанными на тонкой настройке. Каким образом интеграция экспертных знаний может еще больше повысить интерпретируемость и надежность MLLM в задачах промышленного контроля качества?
Пределы Традиционного Обнаружения Аномалий
Традиционные модели глубокого обучения, демонстрирующие высокую эффективность в различных областях, зачастую оказываются недостаточно эффективными в задачах промышленного обнаружения аномалий (IAD). Это связано с их принципиальной зависимостью от бинарной классификации — определение события как “нормального” или “аномального” — что не позволяет уловить тонкие нюансы и семантическое содержание отклонений. В отличие от человеческого анализа, модели не способны понять почему возникла аномалия, лишь констатируют её наличие. Такой подход ограничивает возможности проведения анализа первопричин и, как следствие, разработки превентивных мер для поддержания стабильности и безопасности промышленных процессов. В результате, несмотря на способность выявлять отклонения, системы на основе бинарной классификации часто не предоставляют ценной информации, необходимой для принятия обоснованных решений и оптимизации производственных операций.
Традиционные модели машинного обучения, несмотря на свою эффективность в различных задачах, часто сталкиваются с трудностями при анализе аномалий в промышленных процессах из-за отсутствия прозрачности в принятии решений. Неспособность предоставить понятное объяснение обнаруженной аномалии существенно затрудняет проведение анализа первопричин и, как следствие, реализацию эффективных мер по предотвращению повторных сбоев. В критически важных промышленных системах, где простой может привести к значительным финансовым потерям или даже угрожать безопасности, простого обнаружения недостаточно; необходимо понимать, что именно привело к возникновению отклонения от нормы, чтобы оперативно устранить проблему и повысить надежность оборудования. Отсутствие интерпретируемости ограничивает возможности проведения предиктивной аналитики и своевременного проведения технического обслуживания, что снижает общую эффективность производства и увеличивает риск аварийных ситуаций.
В промышленных системах обнаружение аномалий — это лишь первый шаг к обеспечению надежности и безопасности. Критически важным является создание систем, способных не просто сигнализировать об отклонении от нормы, но и предоставлять понятное объяснение причины возникновения этой аномалии. Такой подход позволяет оперативно выявлять коренные причины дефектов, предотвращать потенциальные аварии и оптимизировать процессы контроля качества. Возможность интерпретации результатов анализа позволяет инженерам и операторам быстро реагировать на возникающие проблемы, снижая риски и повышая эффективность производства. Без объяснений обнаруженные аномалии остаются лишь симптомами, требующими дорогостоящей и трудоемкой диагностики, в то время как система, предоставляющая четкое понимание проблемы, позволяет перейти к проактивному управлению и превентивному обслуживанию оборудования.
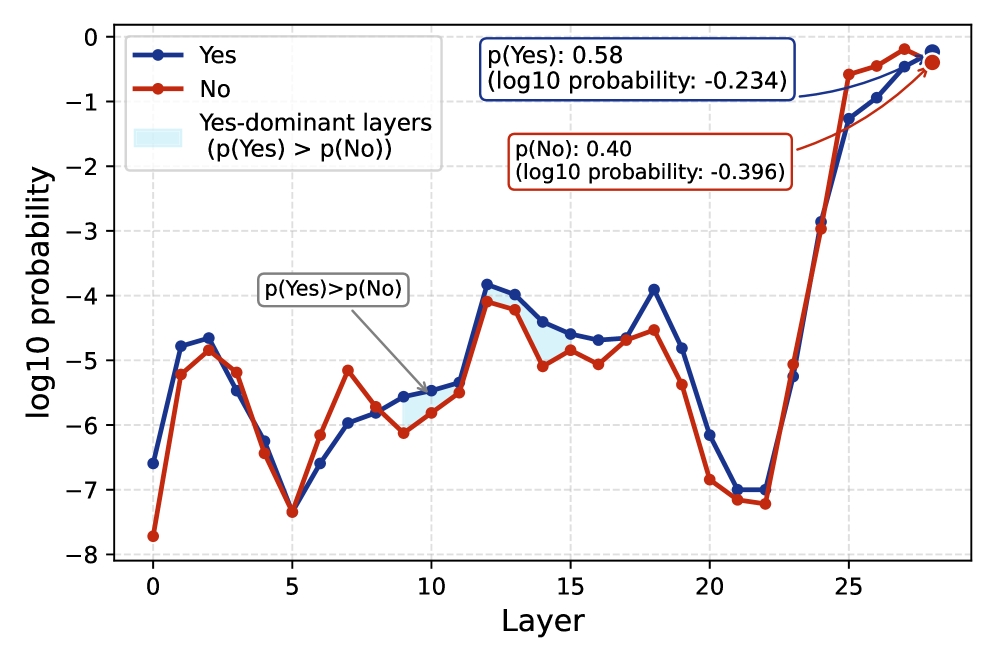
Преодоление Семантического Разрыва с Мультимодальными Моделями
Мультимодальные большие языковые модели (MLLM) представляют собой перспективное решение для более глубокого понимания аномалий, объединяя визуальную информацию с лингвистическим анализом. Традиционные методы анализа аномалий часто ограничены обработкой только текстовых или числовых данных. MLLM, напротив, способны обрабатывать и интерпретировать данные из различных модальностей, включая изображения и видео, что позволяет им выявлять аномалии, которые могут быть неочевидны при анализе только текстовой информации. Это достигается за счет использования архитектур, которые позволяют моделям устанавливать связи между визуальными особенностями и лингвистическими описаниями, повышая точность и надежность обнаружения аномалий в сложных сценариях.
Ранние подходы к созданию мультимодальных больших языковых моделей (MLLM), такие как AnomalyGPT, использовали архитектуры, специализированные для конкретных задач обнаружения аномалий. AnomalyGPT, в частности, демонстрировал возможности анализа изображений и текста для выявления отклонений, что требовало разработки отдельных модулей для визуальной обработки и лингвистического анализа. Эти первоначальные реализации, хотя и ограниченные в масштабе и обобщающей способности, послужили основой для последующих, более сложных систем, показав принципиальную возможность интеграции визуальной информации в процессы языкового моделирования и предоставив ценный опыт в разработке архитектур, способных к совместному анализу различных типов данных. Исследования в рамках AnomalyGPT позволили определить ключевые проблемы, связанные с согласованием визуальных и текстовых представлений, и стимулировали дальнейшие разработки в области мультимодального обучения.
Эффективная интеграция существующих моделей обнаружения аномалий изображений (IAD) в качестве «экспертов по зрению» в рамках многомодальных больших языковых моделей (MLLM) представляла собой сложную задачу. Основная проблема заключалась в переносе знаний, полученных IAD при анализе изображений, в текстовую область MLLM, обеспечивая согласованное и эффективное взаимодействие между модальностями. Традиционные подходы к переносу знаний часто оказывались неэффективными из-за расхождений в представлениях данных и архитектурных различий между IAD и MLLM. Поэтому требовались инновационные методы, включающие, например, обучение с подкреплением, адаптацию слоев или разработку новых механизмов внимания, для успешного использования возможностей IAD в рамках MLLM и обеспечения более точного и контекстуально-обоснованного обнаружения аномалий.
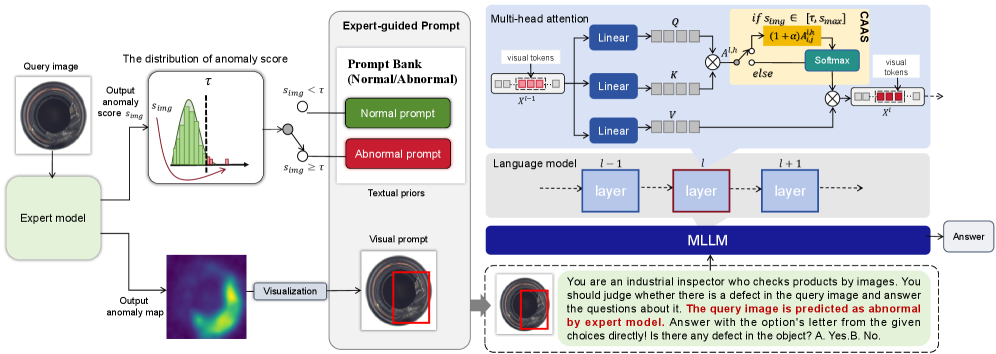
EAGLE: Рамки для Интеллектуального Анализа Аномалий
Фреймворк EAGLE представляет собой инновационный подход к анализу аномалий, основанный на синергии специализированных моделей — таких как PatchCore — и больших многомодальных моделей (MLLM). В отличие от традиционных методов, EAGLE не требует этапа тонкой настройки параметров (tuning-free), что упрощает его внедрение и адаптацию к новым задачам. Сочетание экспертных моделей, обеспечивающих точное обнаружение аномалий, и MLLM, способных к семантическому анализу и генерации интерпретируемых объяснений, позволяет достичь высокой точности обнаружения и глубокого понимания природы аномалий. Данный подход позволяет не только идентифицировать аномальные области, но и предоставить содержательные объяснения причин их возникновения.
В рамках EAGLE, визуальные подсказки, представленные в виде карт аномалий, генерируемых экспертной моделью (например, PatchCore), служат контекстной информацией для большой мультимодальной модели (MLLM). Эти карты аномалий, отображающие области изображения, вызывающие подозрения, направляют внимание MLLM на релевантные участки. В результате, MLLM способна не только обнаруживать аномалии, но и генерировать интерпретируемые объяснения, указывающие на конкретные визуальные признаки, послужившие основанием для определения аномалии. Данный подход позволяет получить не просто результат детекции, но и понять, почему модель пришла к такому выводу.
В основе EAGLE лежат два ключевых компонента, обеспечивающих надежный отбор визуальных подсказок и фокусировку внимания на критических аномальных признаках. Distribution-Based Thresholding (DBT) позволяет автоматически определять оптимальный порог для генерации карт аномалий, основываясь на распределении оценок уверенности экспертной модели. Это обеспечивает выбор наиболее значимых аномалий для последующего анализа. Confidence-Aware Attention Sharpening (CAAS) использует оценки уверенности экспертной модели для усиления внимания MLLM на областях изображения, соответствующих высоковероятностным аномалиям. CAAS эффективно подавляет внимание к областям с низкой уверенностью, улучшая точность локализации и интерпретации аномалий.

Количественная Оценка Неопределенности и Оптимизация Производительности
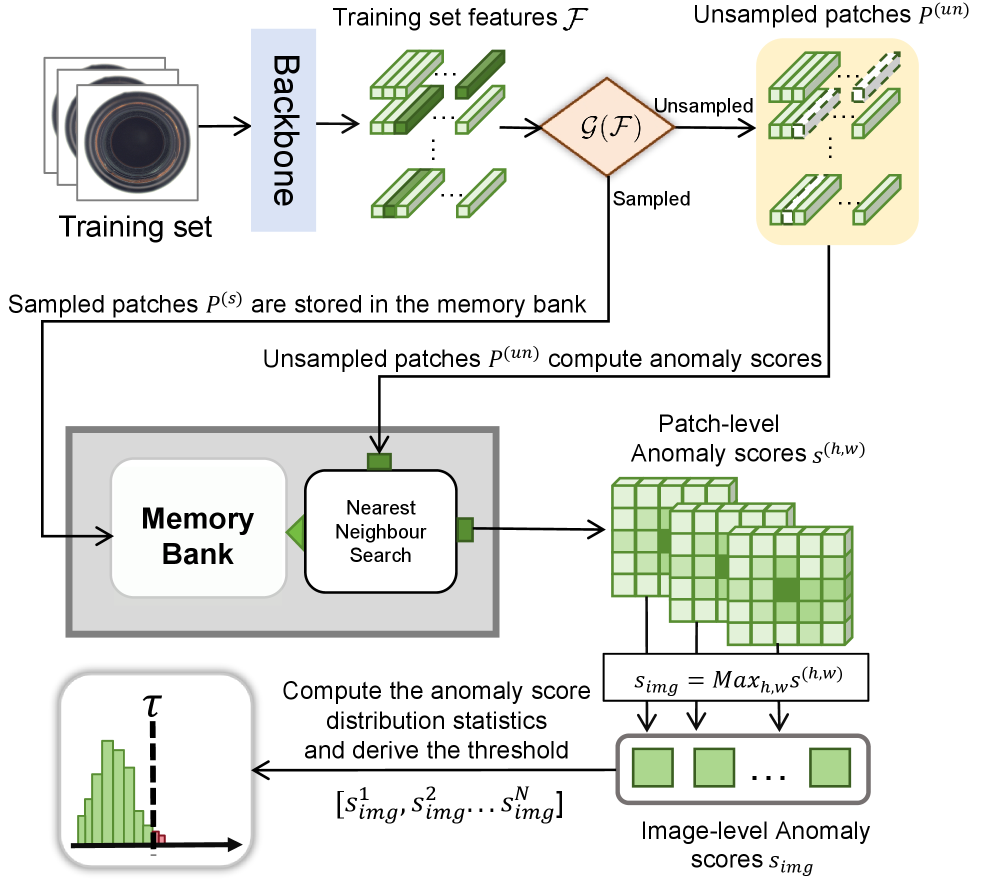
Метод пороговой обработки на основе распределений (DBT) использует принципы теории экстремальных значений (EVT) для определения оптимальных порогов принятия решений при отборе визуальных подсказок. Этот подход позволяет максимизировать отношение сигнал/шум, что критически важно для повышения точности и надежности систем машинного зрения. DBT анализирует распределение вероятностей экстремальных значений в данных, позволяя точно определить порог, при котором полезный сигнал наиболее ярко выражен, а шум минимизирован. В результате, система способна более эффективно идентифицировать аномалии и дефекты, даже в сложных и зашумленных изображениях, что существенно улучшает общую производительность и стабильность работы.
В ходе тщательной оценки на стандартных наборах данных, таких как MVTec-AD и VisA, система EAGLE продемонстрировала превосходство над существующими методами, что подтверждается показателями точности и F1-оценкой. Особенностью данного подхода является достижение конкурентоспособных результатов без необходимости какой-либо донастройки модели, что значительно упрощает внедрение и адаптацию системы к различным задачам и условиям. Данная способность обеспечивает высокую эффективность и надежность обнаружения аномалий, предоставляя возможность оперативного реагирования на потенциальные проблемы и поддержания стабильной работы производственных процессов.
Разработанная система предоставляет не только точное обнаружение дефектов, но и понятные объяснения, позволяющие операторам заранее выявлять и устранять потенциальные проблемы. Такой подход способствует повышению качества продукции и сокращению времени простоя оборудования. В основе лежит метод распределенного порогового отбора (DBT), который демонстрирует стабильное улучшение полноты обнаружения (recall) на различных наборах данных, обеспечивая надежность и эффективность работы системы в различных условиях эксплуатации. Возможность интерпретации результатов позволяет операторам не просто констатировать наличие дефекта, но и понимать его природу, что существенно упрощает процесс анализа и принятия решений.
Исследование демонстрирует, что даже самые передовые мультимодальные большие языковые модели нуждаются в направляющих усилиях экспертных систем для достижения стабильно высокой точности в обнаружении аномалий в промышленной среде. EAGLE, предложенный в статье, — это прагматичный подход, избегающий дорогостоящей и часто неэффективной тонкой настройки моделей. Как заметил Дэвид Марр: «Компьютер не может знать, что он не знает». В контексте данной работы, это означает, что МЛЛМ, несмотря на свою мощь, не способны самостоятельно определить границы нормального функционирования промышленного оборудования без дополнительной экспертной информации. Система, предоставляющая эту информацию, и есть ключ к успешному обнаружению отклонений, а не бесконечная гонка за параметрами модели.
Что дальше?
Представленный подход, безусловно, элегантен. Синергия экспертных моделей и больших мультимодальных языковых моделей выглядит многообещающе, особенно в контексте промышленного обнаружения аномалий. Однако, не стоит забывать, что любая абстракция рано или поздно столкнется с суровой реальностью продакшена. Порог, основанный на распределении, — это лишь временное решение; каждая новая партия данных, каждый новый сценарий — потенциальный источник ложных срабатываний, которые неизбежно потребуют адаптации и перенастройки.
Интересно, куда движется эта область. Вероятно, в сторону ещё более сложных иерархий экспертных моделей, стремящихся охватить все возможные вариации производственных процессов. Но не стоит ли тогда просто вернуться к хорошо отлаженным, пусть и менее «интеллектуальным» системам, которые, по крайней мере, предсказуемы в своей надежности? Всё, что можно задеплоить — однажды упадёт, это неминуемо. Вопрос лишь в том, насколько «красиво» оно упадет.
Следующим шагом, вероятно, станет исследование устойчивости EAGLE к «шуму» в данных — к нерелевантной информации, которая всегда присутствует в реальных промышленных условиях. И, конечно, необходимо учитывать вычислительные затраты. Элегантные решения часто оказываются непозволительно дорогими в реализации. В конечном итоге, всё сводится к прагматичному балансу между точностью, скоростью и стоимостью.
Оригинал статьи: https://arxiv.org/pdf/2602.17419.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-21 01:36