Автор: Денис Аветисян
Новое исследование предлагает эффективный и экономичный метод обнаружения вредоносных запросов, направленных на эксплуатацию больших языковых моделей.
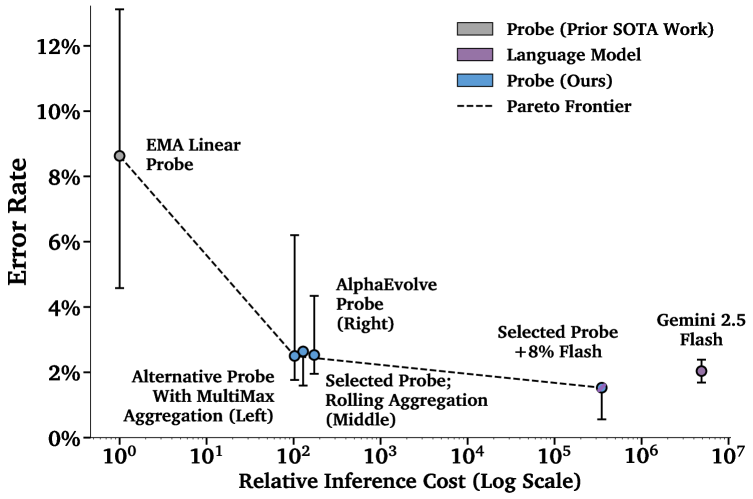
Активационный зондирование для смягчения рисков и противодействия атакам в условиях изменяющихся данных и длинных контекстов, с использованием подходов, таких как AlphaEvolve.
Несмотря на стремительное развитие мощных языковых моделей, обеспечение их безопасности от злоумышленников остаётся сложной задачей. В работе ‘Building Production-Ready Probes For Gemini’ исследуется метод активационного зондирования как экономичный способ выявления кибератак, направленных на большие языковые модели. Авторы демонстрируют, что модификации архитектуры зондов и обучение на разнообразных данных позволяют преодолеть проблему обобщения при изменении распределения входных данных, особенно при переходе к длинным контекстам. Смогут ли подобные подходы обеспечить надежную защиту языковых моделей в реальных сценариях использования и стать основой для автоматизированных систем обеспечения безопасности?
Взламывая Ограничения: Эволюция Угроз и Обход Защиты
Современные большие языковые модели (БЯМ) становятся все более уязвимыми к тщательно разработанным запросам, известным как “jailbreaking” — обход ограничений, заложенных разработчиками. Этот феномен представляет собой серьезную угрозу, поскольку позволяет злоумышленникам выводить из БЯМ нежелательный контент, включая инструкции по созданию опасных веществ, разжигание ненависти или распространение дезинформации. В отличие от традиционных кибератак, jailbreaking эксплуатирует способность моделей к генерации текста, а не уязвимости в коде, что делает обнаружение и предотвращение таких атак особенно сложным. Злоумышленники постоянно совершенствуют методы создания запросов, обходя существующие фильтры и ограничения, что требует непрерывного развития систем обнаружения и защиты.
Эффективное обнаружение кибер-злоупотреблений становится все более важным, однако стандартные подходы сталкиваются с существенными трудностями из-за непрерывной эволюции атак, в частности, создания так называемых “состязательных примеров”. Эти примеры представляют собой специально разработанные входные данные, предназначенные для обхода систем безопасности и получения нежелательного результата от языковой модели. Злоумышленники постоянно совершенствуют методы создания таких примеров, используя различные техники, чтобы замаскировать вредоносные запросы и обойти фильтры. В результате, традиционные методы обнаружения, основанные на статичных правилах или ограниченных наборах данных, быстро устаревают и становятся неэффективными против новых, более изощренных атак, что требует разработки адаптивных и устойчивых систем защиты.
Проблема обнаружения вредоносных запросов усугубляется явлением, известным как “смещение распределения”, когда модели, обученные на определенном наборе атак, оказываются неспособными эффективно противостоять новым, ранее невиданным методам обхода защиты. Особенно сложны так называемые “адаптивные атаки”, когда злоумышленник модифицирует запрос в режиме реального времени, основываясь на ответах модели, чтобы обойти защитные механизмы. Несмотря на развитие систем обнаружения, текущие методы не позволяют полностью исключить успешные атаки, оставляя вероятность успеха выше 1% даже при использовании самых передовых технологий защиты. Это подчеркивает необходимость постоянного совершенствования моделей и разработки более устойчивых к изменениям стратегий обнаружения.
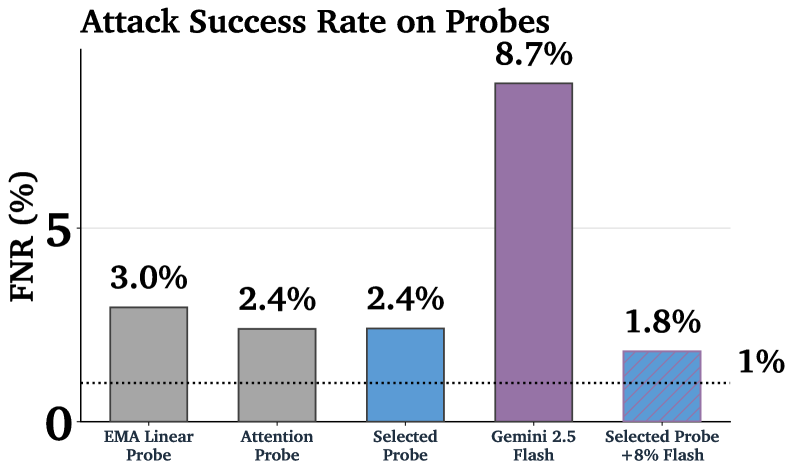
Анализ Внутренностей Модели: Обнаружение на Основе Активаций
Активационное зондирование (Activation Probing) представляет собой альтернативный подход к обнаружению злонамеренных намерений в больших языковых моделях (LLM), который заключается в анализе внутренних скрытых состояний (активаций) модели. В отличие от методов, фокусирующихся на входных или выходных данных, активационное зондирование позволяет исследовать, как модель обрабатывает информацию на промежуточных этапах. Этот подход позволяет выявлять признаки злонамеренного поведения, которые могут быть неявными во внешних проявлениях модели, и может быть использован для разработки более надежных механизмов защиты от атак и манипуляций. Анализ активаций может выявить аномальные паттерны, указывающие на попытки обхода ограничений или генерацию вредоносного контента.
Простейшая реализация обнаружения вредоносных намерений в больших языковых моделях (LLM) осуществляется с помощью “Линейного зонда” (Linear Probe), который анализирует скрытые состояния модели, используя линейную классификацию. Однако, для выявления более тонких и сложных паттернов, применяются более продвинутые методы, такие как “Зонд внимания” (Attention Probe). В отличие от линейного зонда, зонд внимания фокусируется на анализе весов внимания модели, позволяя выявлять зависимости между различными частями входного текста и, следовательно, более точно определять потенциально вредоносные запросы или генерируемые ответы. Такой подход позволяет учитывать контекст и взаимосвязи, которые могут быть упущены при использовании более простых методов анализа скрытых состояний.
В последнее время для повышения эффективности обнаружения вредоносных намерений в больших языковых моделях (LLM) были разработаны архитектуры, такие как ‘MultiMax Probe’ и ‘Max of Rolling Means Attention Probe’. Эти подходы особенно эффективны в задачах ‘Long-Context Generalization’, где необходимо анализировать длинные последовательности входных данных. Экспериментальные данные показывают, что ‘Attention Probe’, обученная на длинном контексте, достигает тестовых потерь в 2.38%, что свидетельствует о её способности эффективно обрабатывать и анализировать большие объемы информации для выявления аномалий.
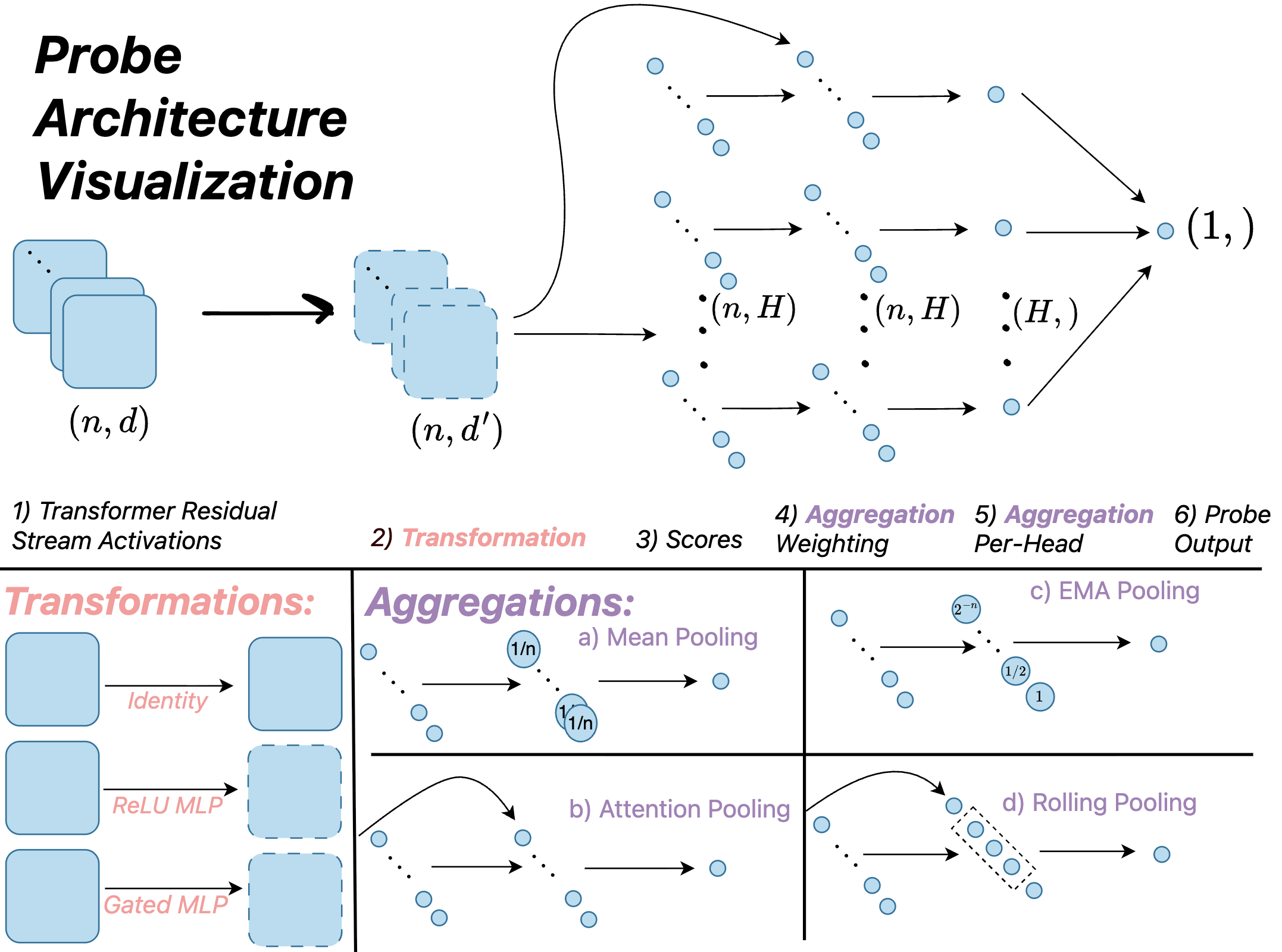
Автоматическая Оптимизация и Валидация Зондов: Искусственный Интеллект на Службе Безопасности
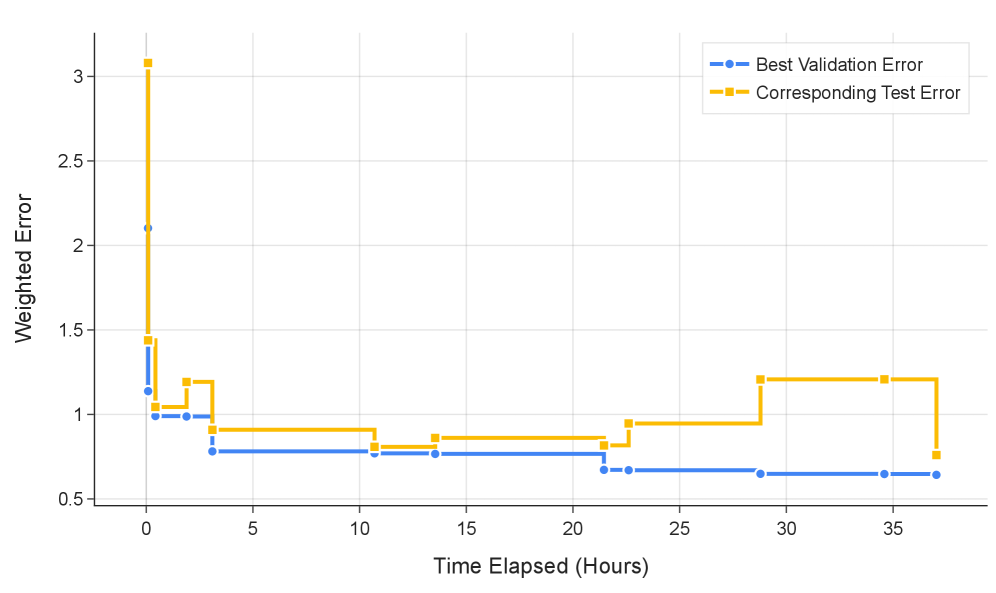
Система ‘AlphaEvolve’ использует возможности больших языковых моделей (LLM) для автоматической оптимизации архитектур зондов (probes), предназначенных для оценки устойчивости LLM к вредоносным запросам. Вместо ручного проектирования, ‘AlphaEvolve’ генерирует и уточняет конструкции зондов посредством промптинга, что позволяет автоматизировать процесс улучшения их эффективности. Такой подход демонстрирует перспективность использования искусственного интеллекта для разработки и совершенствования инструментов обеспечения безопасности LLM, позволяя создавать более надежные и устойчивые системы.
В процессе работы AlphaEvolve использует возможности больших языковых моделей (LLM) для автоматической оптимизации архитектур зондов. Применяя метод промптинга для исследования и совершенствования конструкций зондов, AlphaEvolve добился улучшения производительности как для зонда ‘MultiMax Probe’, так и для ‘Max of Rolling Means Attention Probe’. В результате тестов, величина потерь составила 2.53%, что сопоставимо с показателями зонда, обученного на длинном контексте. Данный результат демонстрирует эффективность подхода, основанного на LLM, для автоматической оптимизации и создания высокопроизводительных зондов.
Оптимизированные зонды, разработанные в рамках AlphaEvolve, в сочетании с эталонными наборами данных, такими как ‘HarmBench’, формируют надежный комплекс для оценки и повышения устойчивости больших языковых моделей (LLM) к вредоносным запросам. Статистический анализ, проведенный на основе результатов тестирования, подтверждает, что зонды AlphaEvolve демонстрируют статистически значимое превосходство над базовыми методами оценки, что позволяет более эффективно выявлять уязвимости LLM и улучшать их способность противостоять манипуляциям и нежелательному контенту. Использование данного комплекса позволяет проводить объективную и количественную оценку эффективности различных стратегий защиты LLM.
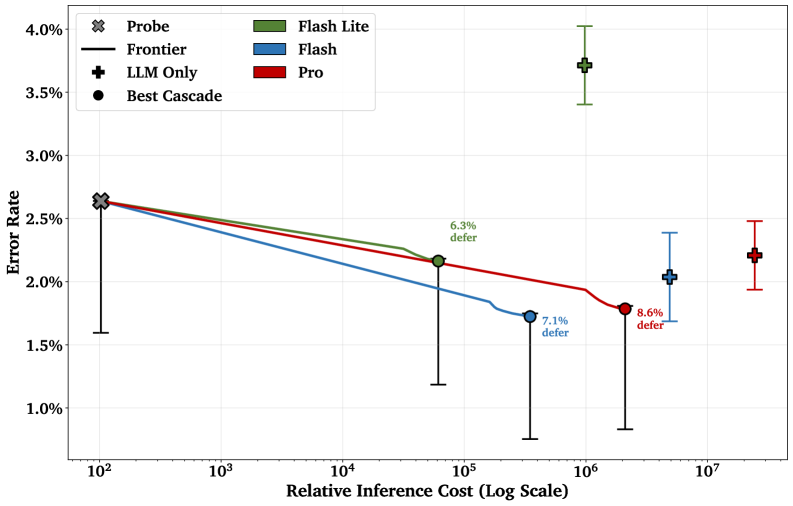
Эффективное и Масштабируемое Обнаружение Вредоносного Контента: Каскадные Классификаторы
Каскадные классификаторы представляют собой инновационный подход к обнаружению вредоносного контента, объединяющий скорость и экономичность простых алгоритмов с мощностью больших языковых моделей (LLM), таких как Gemini 2.5 Flash или Gemini 2.5 Pro. Суть метода заключается в использовании недорогого “щупа”, например, оптимизированного активационного зонда, для быстрой предварительной оценки текста. Если зонд уверен в отсутствии вредоносности, текст пропускается без дальнейшей обработки. В случаях, когда зонд не может дать однозначный ответ или обнаруживает признаки потенциальной угрозы, анализ передается более сложной и ресурсоемкой LLM, способной учитывать контекст и нюансы языка. Такая двухступенчатая система позволяет значительно снизить общую вычислительную нагрузку и, следовательно, стоимость обнаружения вредоносного контента, сохраняя при этом высокую точность.
Каскадные классификаторы позволяют оптимизировать затраты на выявление вредоносного контента, перекладывая анализ неоднозначных или сложных случаев на более мощную языковую модель. Вместо того, чтобы подвергать каждый запрос дорогостоящей обработке, система сначала использует быстрый и экономичный классификатор для первичной оценки. В случае неуверенности или необходимости более глубокого анализа, запрос направляется на обработку языковой моделью. Такой подход существенно снижает общие вычислительные издержки и, следовательно, финансовые затраты, при этом сохраняя высокую точность выявления вредоносного контента, что делает его особенно привлекательным для масштабных производственных систем обнаружения киберугроз.
Предложенный каскадный подход открывает реальную возможность для организации обнаружения киберугроз в режиме реального времени в рабочих развертываниях больших языковых моделей. Вместо того чтобы полагаться исключительно на ресурсоемкие языковые модели для анализа каждого запроса, система сначала использует быстрый и экономичный классификатор для выявления очевидных случаев. Лишь при возникновении неопределенности или двусмысленности запрос направляется на более детальный анализ мощной языковой модели. Такая стратегия позволяет значительно снизить вычислительные затраты и обеспечить масштабируемость системы, что критически важно для защиты от злоумышленников в динамичной среде современных LLM-приложений. Данный метод предоставляет практическое решение для эффективного мониторинга и предотвращения неправомерного использования языковых моделей в производственной среде.
Исследование, представленное в статье, напоминает процесс детального анализа сложной системы. Авторы стремятся не просто обнаружить уязвимости, но и понять принципы работы модели, чтобы предвидеть и предотвратить злонамеренные запросы. Этот подход созвучен идеям Карла Фридриха Гаусса: “Если бы я должен был выбирать между способностью видеть и способностью понимать, я бы выбрал последнее.” Подобно тому, как Гаусс искал глубинные закономерности в математике, данная работа фокусируется на понимании активаций языковой модели как способа обнаружения потенциальных угроз, особенно в условиях смещения распределений данных и при обработке длинных контекстов. Понимание внутренних механизмов позволяет создавать более надежные и устойчивые системы.
Что дальше?
Представленная работа, хотя и демонстрирует прогресс в обнаружении злонамеренных запросов к языковым моделям через активационное зондирование, лишь слегка приоткрывает дверь в гораздо более сложную систему. Что произойдёт, если атакующий научится не просто обходить зонд, а активно его использовать, направляя модель к предсказуемым ошибкам? Успешное зондирование сегодня — это, вероятно, лишь выявление наиболее очевидных паттернов. Истинный вызов заключается в предсказании тех векторов атаки, которые ещё не существуют, в реверс-инжиниринге потенциальных уязвимостей, скрытых в многослойной архитектуре.
Особое внимание следует уделить проблеме смещения распределений. Модель, обученная на синтетически сгенерированных атаках, может оказаться беспомощной перед реальными, непредсказуемыми запросами. Использование таких методов, как AlphaEvolve, для адаптации зондов к новым угрозам — это лишь первый шаг. Более перспективным представляется создание зондов, способных к самообучению, к построению внутренних моделей атак, предвосхищающих действия злоумышленника. Что если зонд сам станет активным участником «игры«, провоцируя атаки для анализа и улучшения своей защиты?
Наконец, необходимо признать, что зондирование — это лишь один из уровней защиты. Языковые модели, подобные Gemini, представляют собой сложные системы, уязвимые к атакам на разных уровнях. Поиск единого «серебряной пули» бессмыслен. Более реалистичным представляется создание многоуровневой системы защиты, объединяющей зондирование с другими методами, такими как формальная верификация и устойчивость к adversarial атакам. Иначе говоря, взламывать систему нужно быстрее, чем она учится взламывать себя.
Оригинал статьи: https://arxiv.org/pdf/2601.11516.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-20 03:36