Автор: Денис Аветисян
Новое исследование показывает, что повышение точности на известных данных не всегда гарантирует эффективное обнаружение неизвестных, и ключевую роль играет стратегия обучения.
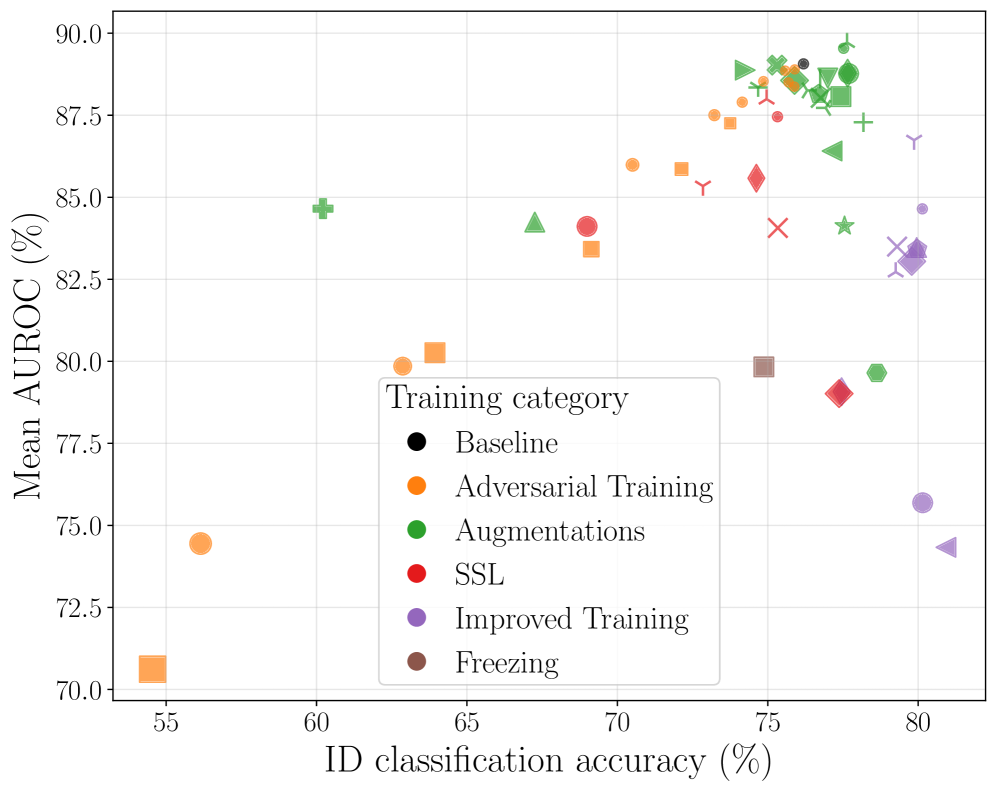
Эффективность методов выявления аномалий напрямую зависит от стратегии обучения и характеристик полученного пространства признаков.
Несмотря на значительный прогресс в области обнаружения внераспределительных данных (OOD), их взаимодействие с современными методами обучения, направленными на максимизацию точности и обобщающей способности на распределительных данных (ID), остаётся малоизученным. В работе ‘One Model, Many Behaviors: Training-Induced Effects on Out-of-Distribution Detection’ проведено всестороннее эмпирическое исследование, показавшее, что повышение точности ID не всегда приводит к улучшению производительности OOD, а может даже её снизить после достижения определенного порога. На основе анализа 56 моделей ResNet-50, обученных с использованием различных стратегий, авторы выявили сложную взаимосвязь между методом обучения, выбором детектора OOD и итоговой производительностью. Какие новые подходы к обучению позволят создавать модели, одновременно обладающие высокой точностью на ID и надежной способностью к обнаружению OOD?
Математическая чистота данных: выявление неизвестного
Глубокие нейронные сети демонстрируют высокую точность при обработке данных, соответствующих их обучающей выборке, однако их надежность существенно снижается при столкновении с ранее не встречавшимися, нестандартными данными. Эта уязвимость представляет серьезную угрозу в критически важных приложениях, таких как автономное вождение или медицинская диагностика, где ошибочные предсказания могут привести к нежелательным последствиям. Неспособность адекватно реагировать на “выходящие за рамки” данные обусловлена тем, что модели часто экстраполируют закономерности, выученные на тренировочном наборе, даже если эти закономерности неприменимы к новым, неизвестным ситуациям, что подчеркивает необходимость разработки методов повышения робастности и надежности глубокого обучения в условиях реального мира.
Уязвимость моделей глубокого обучения перед данными, не соответствующими обучающей выборке, обусловлена их склонностью к излишней уверенности в предсказаниях, даже когда сталкиваются с незнакомыми входными данными. Эта чрезмерная уверенность может привести к ошибочным решениям в критических ситуациях, подчеркивая необходимость надежной оценки неопределенности. Способность модели правильно определять, когда ее предсказания ненадежны, становится ключевым фактором для обеспечения безопасности и надежности систем, работающих в реальных условиях. Разработка методов, позволяющих точно измерить уровень уверенности модели в своих ответах, представляет собой важную задачу для исследователей в области машинного обучения и искусственного интеллекта.
Оценка эффективности обнаружения внераспределительных данных (OOD) требует использования надежных метрик, выходящих за рамки простой точности. Такие показатели, как площадь под ROC-кривой (AUROC) и частота ложных тревог при 95% обнаружении (FPR95), позволяют оценить баланс между выявлением незнакомых входных данных и избежанием ложных срабатываний. Однако проведенное исследование выявило слабую корреляцию (0.04) между точностью на обучающих данных (ID accuracy) и эффективностью обнаружения OOD. Это демонстрирует, что высокая точность при обработке данных, соответствующих распределению обучающей выборки, не гарантирует надежное обнаружение новых, незнакомых данных, что подчеркивает важность разработки специализированных методов оценки и повышения устойчивости моделей глубокого обучения к внераспределительным данным.
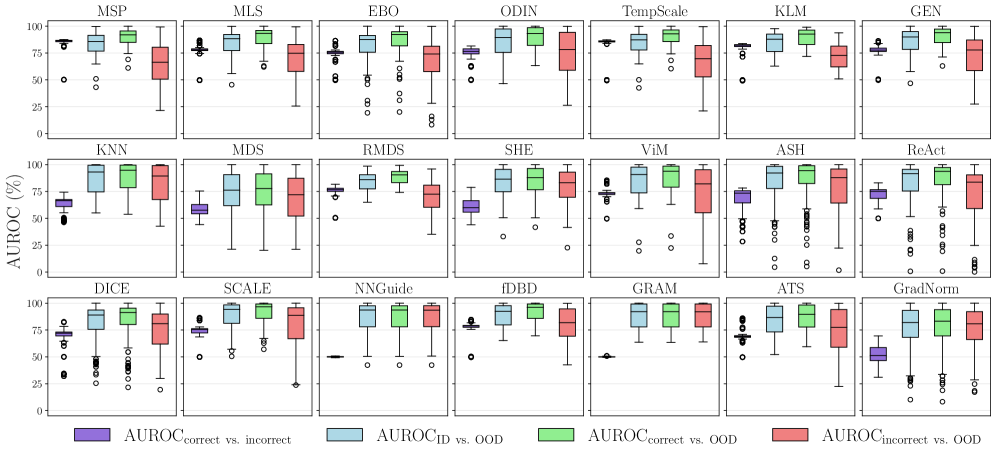
Методы выявления данных вне распределения: поиск аномалий
Существует широкий спектр методов обнаружения входных данных, выходящих за пределы распределения обучающей выборки (OOD). Простейшие подходы, такие как Maximum Softmax Probability (MSP) и Maximum Logit Score (MLS), оценивают уверенность классификатора, полагая, что низкая уверенность указывает на OOD образец. Более сложные методы используют представления, полученные из промежуточных слоев нейронной сети (feature space representations), для анализа и выявления аномалий. Эти методы варьируются от вычисления расстояний до центроидов классов до моделирования распределения признаков и оценки вероятности принадлежности входных данных к известным классам. Развитие этих методов направлено на повышение точности и надежности обнаружения OOD данных, что критически важно для безопасности и надежности систем машинного обучения.
Энерго-ориентированные методы обнаружения OOD-входов основываются на вычислении «энергии» входных данных. В рамках этого подхода, более высокая энергия указывает на то, что входной пример, вероятно, не принадлежит обучающему распределению. Методика упрощенной энергии Хопфилда (Simplified Hopfield Energy) является одним из примеров, где энергия определяется как E(x) = -log(p(x)), где p(x) — вероятность входных данных x. По сути, такие методы стремятся моделировать плотность вероятности обучающих данных и идентифицировать образцы с низкой вероятностью как OOD.
Методы ODIN (Out-of-distribution Input Normalization) и SCALE (Score-calibrated likelihood estimation) улучшают обнаружение вне-распределительных (OOD) входных данных путем целенаправленного изменения входных данных или внутренних представлений модели. ODIN применяет небольшие, направленные возмущения к входным данным, оптимизированные для увеличения максимальной вероятности класса, что позволяет повысить дискриминационную способность модели и улучшить разделение между распределениями в распределении и вне его. SCALE, в свою очередь, фокусируется на изменении внутренней оценки уверенности модели путем калибровки оценок логарифмической вероятности, что позволяет более точно оценить уверенность модели в своих предсказаниях и, следовательно, улучшить обнаружение OOD-входных данных. Оба подхода направлены на повышение чувствительности модели к образцам, которые отличаются от тех, на которых она обучалась.
Метод оценки Махаланобиса использует статистические свойства пространства признаков для выявления аномалий, определяя расстояние между точкой данных и центром распределения признаков с учетом ковариационной матрицы. Более высокие значения расстояния Махаланобиса указывают на отклонение от типичного распределения входных данных и, следовательно, на вне-распределенный (OOD) образец. В свою очередь, подход ReAct (Robust Activation Clipping) направлен на повышение устойчивости к OOD-входам посредством обрезки активаций в нейронной сети. Ограничивая диапазон значений активаций, ReAct предотвращает чрезмерно сильные реакции на нетипичные входные данные, что снижает вероятность ложноположительных срабатываний при обнаружении OOD-входов и повышает общую надежность модели.
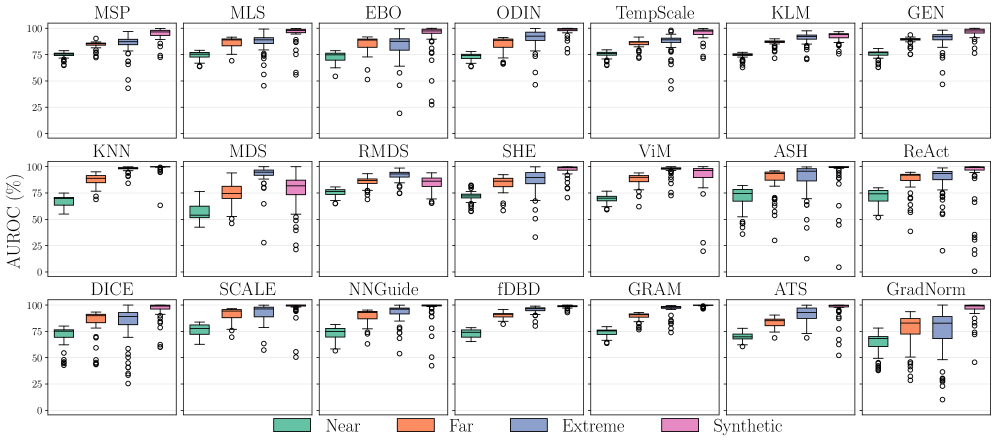
Повышение робастности модели: стратегии обучения для устойчивости
Архитектура ResNet-50 традиционно используется в качестве базовой для оценки методов обнаружения данных, выходящих за пределы обучающей выборки (OOD). Однако, в последнее время наблюдается растущий интерес к использованию архитектур Vision Transformer (ViT) для оценки обобщающей способности моделей. ViT, благодаря механизму самовнимания, потенциально способны лучше улавливать глобальные зависимости в данных, что может положительно сказаться на обнаружении OOD примеров. Исследования показывают, что ViT демонстрируют конкурентоспособные, а в некоторых случаях и превосходящие результаты по сравнению с ResNet-50 в задачах OOD-обнаружения, что делает их перспективной альтернативой для дальнейших исследований в данной области.
Для повышения производительности модели как на обучающих данных (in-distribution), так и на данных, отличных от обучающих (out-of-distribution), применяются различные методы обучения. Adversarial Training предполагает добавление в обучающую выборку специально созданных примеров, незначительно отличающихся от исходных, но приводящих к неверной классификации, что заставляет модель становиться более устойчивой к небольшим изменениям входных данных. MixUp генерирует новые обучающие примеры путем линейной интерполяции между парами изображений и их соответствующими метками. CutMix, в свою очередь, создает новые примеры путем вырезания и вставки фрагментов изображений из других примеров, что способствует улучшению обобщающей способности модели и повышению устойчивости к зашумленным данным.
Методы регуляризации, такие как сглаживание меток (Label Smoothing) и экспоненциальное скользящее среднее (Exponential Moving Averages), направлены на предотвращение переобучения модели и повышение калибровки прогнозов. Сглаживание меток заменяет жесткие метки классов вероятностными распределениями, снижая уверенность модели в неверных предсказаниях и способствуя обобщающей способности. Экспоненциальное скользящее среднее, применяемое к весам модели, создает усредненную версию, которая менее чувствительна к отдельным выбросам в данных и способствует более стабильным и точным прогнозам. Комбинация этих методов позволяет модели лучше справляться с новыми, ранее не встречавшимися данными и выдавать более надежные оценки вероятностей.
Контрастное обучение (Contrastive Learning) позволяет формировать более устойчивые признаки, что улучшает способность модели различать данные из распределения (in-distribution) и данные вне распределения (out-of-distribution). Однако, проведенное исследование показало, что взаимодействие между стратегиями обучения и методами обнаружения OOD объясняет 21.05% дисперсии метрики AUROC. Это подчеркивает важность учета комбинаций различных подходов: применение контрастного обучения в сочетании с определенными методами обнаружения OOD может дать существенно лучшие результаты, чем использование этих методов изолированно. Таким образом, оптимизация стратегии обучения должна учитывать и выбранный метод обнаружения OOD для достижения максимальной производительности.
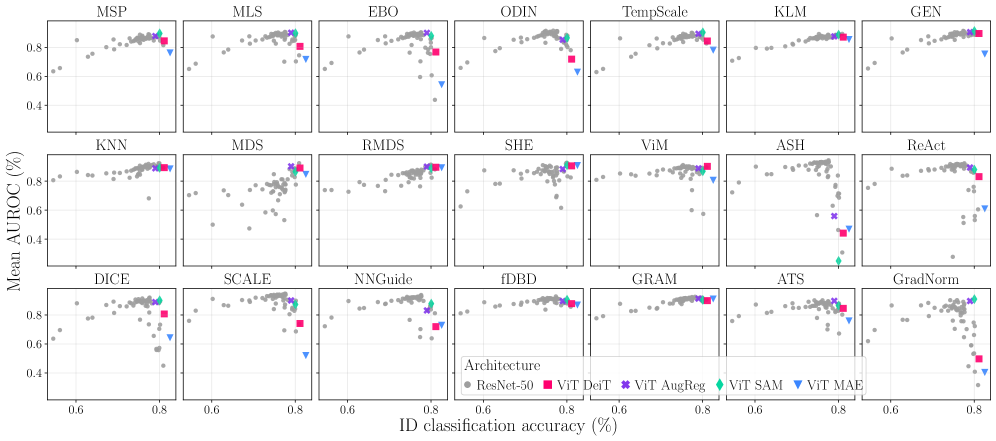
Значение калибровки данных и модели: выявление границ известного
Широко распространенная практика предварительного обучения моделей на наборе данных ImageNet, несмотря на свою популярность, оказывает существенное влияние на эффективность обнаружения данных, выходящих за рамки распределения (OOD). Исследования показывают, что выбор обучающего набора данных напрямую определяет способность модели к адекватному определению незнакомых входных данных. В то время как ImageNet обеспечивает прочную основу для многих задач компьютерного зрения, его состав и характеристики могут приводить к смещениям, которые ограничивают обобщающую способность модели в сценариях OOD. Таким образом, выбор набора данных для предварительного обучения требует тщательного рассмотрения, поскольку он определяет способность модели не только к классификации известных объектов, но и к надежному выявлению неизвестных, что критически важно для безопасности и надежности систем искусственного интеллекта.
Эффективное обнаружение данных, выходящих за пределы тренировочного распределения (OOD), требует не только идентификации новых, незнакомых входных данных, но и точной оценки неопределенности модели при их обработке. Калибровка модели, то есть соответствие между предсказанной уверенностью и фактической точностью, играет здесь ключевую роль. Неоткалиброванная модель может выдавать высокие оценки уверенности для ошибочных предсказаний на OOD данных, вводя в заблуждение принимающие решения системы. Точная оценка неопределенности позволяет модели сигнализировать о случаях, когда она не уверена в своем ответе, что критически важно для надежности и безопасности в приложениях, где ошибки могут иметь серьезные последствия. Таким образом, калибровка является неотъемлемой частью разработки надежных систем машинного обучения, способных эффективно работать с данными, отличными от тех, на которых они были обучены.
Понимание структуры внутреннего представления данных, формируемого моделью, играет ключевую роль в разработке и оценке методов обнаружения данных, не соответствующих тренировочному распределению (OOD). Именно особенности этого внутреннего пространства определяют, насколько эффективно модель способна различать данные, на которых она обучалась, и принципиально новые, незнакомые примеры. Если данные из разных классов в этом пространстве тесно переплетены, то и обнаружить аномалии становится крайне затруднительно. Исследователи подчеркивают, что анализ этого пространства позволяет не только проектировать более эффективные алгоритмы OOD-детектирования, но и адекватно оценивать их производительность, учитывая, насколько хорошо модель формирует четкие границы между известными и неизвестными данными. Таким образом, глубокое понимание структуры признакового пространства является фундаментом для создания надежных систем, способных обнаруживать и реагировать на неожиданные входные данные.
Исследования демонстрируют, что повышение эффективности обнаружения аномалий требует не только идентификации новых входных данных, но и усовершенствования представления признаков. Методы, такие как GRAM и ASH, направлены на достижение этой цели, используя статистику промежуточных слоев и отбрасывание неактивных активаций соответственно, для уточнения представления данных. Важно отметить, что сложность различных наборов данных, используемых для тестирования на предмет аномалий, оказывает значительное влияние на результаты. В ходе исследования было установлено, что внутренняя сложность различных наборов данных для обнаружения аномалий объясняет 34.22% разброса значений метрики AUROC, что подчеркивает трудности обобщения методов обнаружения аномалий и необходимость разработки более устойчивых и универсальных подходов.
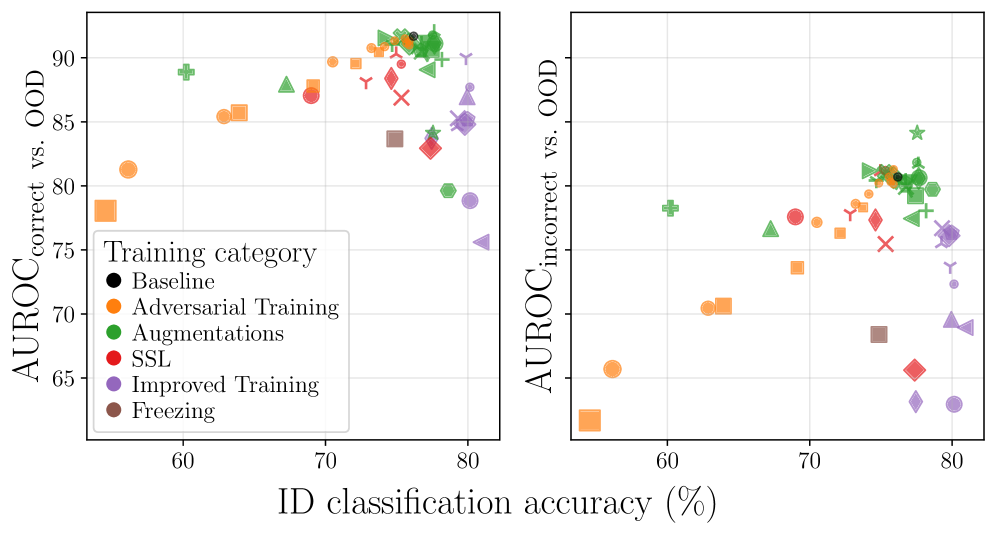
Исследование демонстрирует, что стремление к высокой точности на обучающей выборке не всегда гарантирует надежное обнаружение аномалий. Полученные результаты подчеркивают, что эффективность методов обнаружения данных, выходящих за рамки обучающей выборки (OOD detection), тесно связана со стратегией обучения и характеристиками полученного пространства признаков. Как заметил Ян Лекун: «Машинное обучение — это не магия, а математика». Эта фраза особенно актуальна в контексте данной работы, поскольку акцент смещается с эмпирической оценки производительности на понимание математических основ, определяющих обобщающую способность модели и её устойчивость к новым, ранее не встречавшимся данным. Важно не просто создать алгоритм, который «работает», а доказать его корректность и предсказуемость.
Куда Ведет Эта Дорога?
Представленные результаты, хотя и кажутся интуитивно очевидными для тех, кто знаком с асимптотической сложностью обобщения, подчеркивают парадоксальную природу современной детекции аномалий. Стремление к максимальной точности на обучающей выборке, подобно бесконечному преследованию предела, не гарантирует устойчивости к данным, выходящим за рамки известного распределения. Напротив, наблюдаемая зависимость эффективности методов от стратегии обучения указывает на то, что ключевым является не столько достижение высокой точности, сколько формирование специфической структуры пространства признаков.
Очевидным направлением для дальнейших исследований представляется формализация связи между стратегиями обучения и геометрическими свойствами пространства признаков. Необходимо разработать метрики, позволяющие предсказывать устойчивость модели к аномальным данным, исходя из характеристик полученного представления. Необходимо отойти от эмпирических оценок и перейти к строгому математическому анализу, позволяющему доказать, а не просто констатировать, влияние различных методов обучения на обобщающую способность.
И, наконец, остается открытым вопрос о природе самих аномалий. Если считать, что аномалия — это не просто точка, далекая от плотного кластера, а скорее нарушение инвариантов, присущих данным, то методы детекции должны быть направлены на выявление этих нарушений, а не на простое измерение расстояний в пространстве признаков. Такой подход потребует разработки новых, принципиально иных алгоритмов, основанных на теории категорий и топологическом анализе данных.
Оригинал статьи: https://arxiv.org/pdf/2601.10836.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2026-01-20 22:20