Автор: Денис Аветисян
Новый подход, основанный на обучении с подкреплением, позволяет создавать более устойчивые и эффективные языковые модели, генерируя данные, близкие к реальным условиям использования.
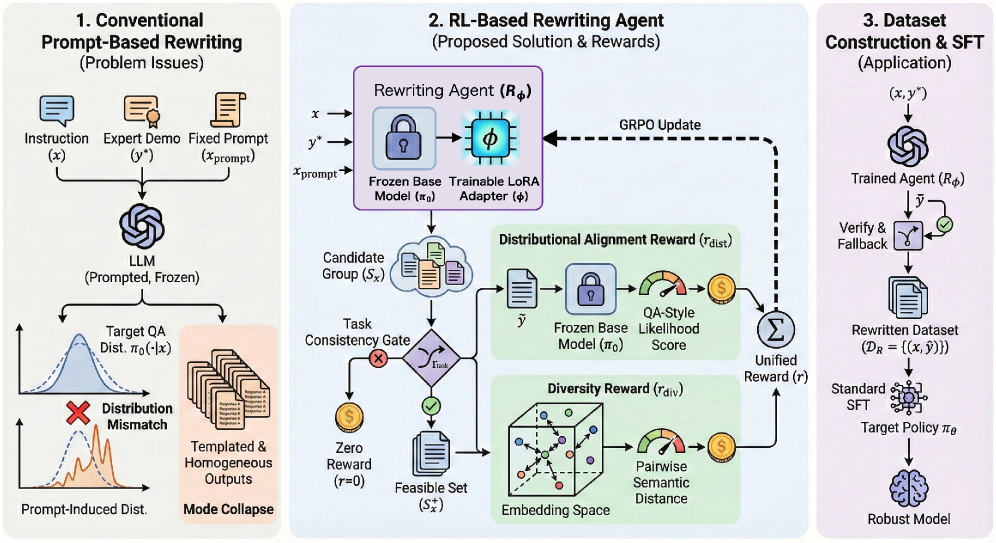
В статье представлена система на основе обучения с подкреплением, которая переписывает обучающие данные для снижения смещения распределений и предотвращения катастрофического забывания при тонкой настройке больших языковых моделей.
Несмотря на значительный прогресс в области больших языковых моделей (LLM), адаптация к новым задачам часто сопряжена с риском «катастрофического забывания». В данной работе, ‘Patch the Distribution Mismatch: RL Rewriting Agent for Stable Off-Policy SFT’, предложен подход к решению этой проблемы, основанный на переписывании обучающих данных с использованием обучения с подкреплением. Разработанный агент генерирует более согласованные с распределением модели данные, повышая стабильность и эффективность тонкой настройки. Способны ли подобные методы существенно снизить потребность в больших объемах размеченных данных и обеспечить более надежную адаптацию LLM к разнообразным сценариям?
Смещение Распределений: Пророчество Системного Сбоя
Несмотря на впечатляющую мощь, большие языковые модели (LLM) демонстрируют снижение производительности при столкновении с расхождением между данными, на которых они обучались, и данными, с которыми они сталкиваются в реальной эксплуатации. Это явление, известное как смещение распределения, возникает из-за того, что модель, оптимизированная для конкретного набора данных, может испытывать трудности при обработке входных данных, значительно отличающихся от тех, на которых она была обучена. В результате, даже незначительные изменения в стиле, тематике или формате входных данных могут привести к заметному ухудшению качества генерируемого текста или точности ответов. Данная проблема представляет собой серьезную преграду для надежного развертывания LLM в динамичных и непредсказуемых условиях реального мира, требуя разработки специальных стратегий для повышения их устойчивости к смещению распределения.
Явление переноса распределения данных оказывает существенное влияние на большие языковые модели, приводя к так называемому катастрофическому забыванию — утрате ранее приобретенных знаний при адаптации к новым данным. Особенно остро эта проблема проявляется из-за вариативности на уровне отдельных токенов при генерации текста. Незначительные изменения в последовательности слов, вызванные этой вариативностью, могут приводить к существенным отклонениям в результатах, поскольку модель, обученная на определенном распределении токенов, теряет способность адекватно обрабатывать незнакомые или редко встречающиеся комбинации. В результате, даже небольшое расхождение между данными обучения и реальными условиями эксплуатации может привести к резкому снижению производительности модели и потере ее способности генерировать связный и осмысленный текст.
Традиционная процедура дообучения с учителем (Supervised Fine-Tuning, SFT), несмотря на свою эффективность в улучшении производительности больших языковых моделей, зачастую усугубляет проблему несоответствия между данными обучения и реальными условиями эксплуатации. Дело в том, что SFT, как правило, фокусируется на конкретном наборе данных, который может не полностью отражать разнообразие и изменчивость входных данных, с которыми модель столкнется в реальном мире. Это приводит к тому, что модель становится чрезмерно специализированной для данных дообучения, теряя способность обобщать и эффективно работать с новыми, незнакомыми данными. В результате, даже незначительные отклонения в распределении входных данных могут привести к значительному снижению производительности и проявлению эффекта катастрофического забывания, когда модель «забывает» знания, полученные на этапе предварительного обучения.

Переписывание Надзора: Превентивная Стратегия
Метод PatchingDistributionMismatch представляет собой эффективный способ борьбы с расхождением распределений (distribution shift) путем предварительной модификации данных, используемых для обучения с учителем (Supervised Fine-Tuning, SFT). Вместо адаптации модели к новым данным после развертывания, этот подход позволяет преобразовать целевые данные до этапа SFT, тем самым снижая разрыв между распределением данных, используемых при обучении, и распределением данных, с которыми модель сталкивается в реальной эксплуатации. Это позволяет повысить обобщающую способность модели и ее устойчивость к изменениям входных данных, возникающим в процессе развертывания.
Для решения проблемы расхождения между распределениями данных обучения и эксплуатации используется агент RLRewritingAgent, предназначенный для преобразования целевых значений супервизии. Этот агент обучается изменять исходные данные, используемые для обучения, таким образом, чтобы они лучше соответствовали данным, которые модель встретит в реальной среде. Фактически, агент выступает в роли посредника, адаптирующего данные супервизии для повышения обобщающей способности модели и снижения влияния расхождения распределений на качество работы.
Агент использует LoRA (Low-Rank Adaptation) для эффективной адаптации к новым данным, минимизируя количество обучаемых параметров и снижая вычислительные затраты. В качестве алгоритма оптимизации политики применяется GRPO (Generalized Reward-augmented Policy Optimization), позволяющий стабильно обучать агента, максимизируя вознаграждение и учитывая ограничения, что особенно важно при работе с распределением данных, смещенным от обучающего. Комбинация LoRA и GRPO обеспечивает быструю и эффективную адаптацию агента к изменениям в данных и позволяет достигать высокой производительности при решении задач переписывания супервизии.

Гарантирование Согласованности и Разнообразия Переписанных Данных
Агент RLRewritingAgent включает в себя механизм TaskConsistencyGate, предназначенный для обеспечения соответствия переписанных данных исходному замыслу экспертных демонстраций. Данный механизм оценивает семантическую близость между исходным и переписанным текстом, используя метрики, отражающие сохранение ключевых намерений и логической структуры. В случае отклонения от заданных пороговых значений, переписанные данные отбрасываются или подвергаются дополнительной корректировке, что позволяет гарантировать, что сгенерированные данные точно отражают исходные экспертные знания и избегают искажений смысла. Это критически важно для поддержания качества и надежности данных, используемых для обучения моделей.
Для предотвращения эффекта схлопывания модели (mode collapse) и повышения обобщающей способности, агент использует методы регуляризации разнообразия (DiversityRegularization). Эти методы направлены на максимизацию различий между сгенерированными образцами, предотвращая концентрацию генерации на ограниченном подмножестве возможных выходных данных. Регуляризация разнообразия достигается путем добавления штрафного члена к функции потерь, который оценивает степень различия между сгенерированными образцами и стимулирует агент к производству более разнообразного набора данных. Это позволяет агенту лучше адаптироваться к новым, ранее не встречавшимся входным данным и улучшает его устойчивость к шуму и вариациям.
Агент поддерживает генерацию данных в стиле «Вопрос-Ответ» (QAStyleGeneration), что позволяет эффективно увеличивать объем обучающей выборки. Этот метод предполагает создание новых примеров путем автоматической генерации вопросов на основе существующих данных и соответствующих ответов. QAStyleGeneration обеспечивает более компактное представление данных по сравнению с простым дублированием, что снижает вычислительные затраты и повышает эффективность обучения модели. Автоматически сгенерированные пары «вопрос-ответ» позволяют модели лучше обобщать знания и улучшать производительность при решении новых задач.

За Пределами Дообучения: Последствия и Перспективы
Предложенный метод выходит за рамки стандартной Supervised Fine-Tuning (SFT), представляя собой более устойчивое и приспособляемое решение для практического применения. Исследования показали, что новая методика демонстрирует сопоставимую производительность в математических задачах, достигая общей точности в 55.23%, что соответствует результатам, полученным при использовании стандартной SFT. Такое соответствие в сочетании с повышенной адаптивностью позволяет использовать данную разработку в широком спектре реальных сценариев, где требуется надежная и эффективная обработка математических данных и решение задач.
Традиционные методы обучения с подкреплением часто сталкиваются с трудностями при использовании данных, собранных в процессе обучения других агентов или при анализе неполных или смещенных наборов данных — проблема, известная как Off-Policy Learning. Предложенная схема обучения предоставляет эффективный путь для преодоления этих ограничений, позволяя использовать более широкий спектр доступных данных для улучшения производительности модели. Вместо того чтобы полагаться исключительно на данные, полученные непосредственно от текущей политики, данная разработка эффективно интегрирует информацию из разнообразных источников, повышая устойчивость и обобщающую способность модели даже в условиях, когда данные отличаются от тех, на которых она была изначально обучена. Это открывает возможности для более быстрого обучения и адаптации к новым задачам, используя накопленный опыт и знания из различных источников данных.
Разработанный подход демонстрирует значительное улучшение обобщающей способности модели на задачах, выходящих за рамки обучающей выборки. В частности, снижение падения обобщения на внедоменных бенчмарках достигло 7.35%, что на 11.82% меньше, чем при использовании стандартной Supervised Fine-Tuning (SFT), где данный показатель составляет 19.17%. Более того, оптимизация привела к существенному снижению потерь при последующей дообучении SFT до 0.44, что является значительным прогрессом по сравнению с исходными потерями на демонстрационных данных (0.74) и потерями при прямой переработке (0.63). Такое уменьшение потерь и повышение устойчивости к новым данным свидетельствует о более эффективном обучении и способности модели к адаптации в реальных условиях.
Исследование демонстрирует, что стабильность больших языковых моделей напрямую зависит от соответствия распределения данных обучения. Авторы предлагают элегантное решение — агента, использующего обучение с подкреплением для переписывания данных, тем самым сглаживая переход к новым задачам и предотвращая катастрофическое забывание. Это напоминает о мудрости Барбары Лисков: «Хороший дизайн — это признак хорошего понимания проблемы». Именно глубокое понимание проблемы смещения распределений позволило создать систему, которая не просто адаптируется к новым данным, но и формирует их, обеспечивая тем самым более устойчивое и предсказуемое поведение модели. Словно садовник, выращивающий устойчивые растения, авторы заботятся о долгосрочном здоровье и производительности своих систем.
Что Дальше?
Представленная работа, стремясь смягчить проблему смещения распределений в процессе дообучения больших языковых моделей, лишь слегка притормозила неизбежное. Создание агента, переписывающего данные, — это не решение, а отсрочка. Система усложняется, количество взаимодействующих компонентов растёт, а значит, вероятность каскадных отказов лишь увеличивается. Разделение данных для обучения не освобождает от общей судьбы, а лишь создаёт новые точки потенциальной хрупкости.
Настоящая проблема кроется не в самих данных, а в фундаментальной неспособности этих систем к адаптации к изменяющемуся миру. Усилия по генерации «внутрираспределённых» данных лишь маскируют более глубокую болезнь: модели, запертые в узком диапазоне первоначального обучения. Следующим шагом, вероятно, станет поиск методов, позволяющих моделям самостоятельно распознавать и компенсировать смещение, но даже это — временная мера.
В конечном итоге, всё стремится к зависимости. Создание более сложных систем управления данными лишь усугубляет эту зависимость. Вместо того, чтобы строить сложные архитектуры, следует искать принципиально иные подходы, основанные на самоорганизации и устойчивости к непредсказуемости. Иначе, рано или поздно, вся эта сложная конструкция рухнет под тяжестью собственного веса.
Оригинал статьи: https://arxiv.org/pdf/2602.11220.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-14 12:59