Автор: Денис Аветисян
Новый подход сочетает в себе активное обучение и методы машинного обучения с подкреплением, позволяя нейросетям эффективнее учиться распознавать объекты на изображениях, требуя меньше размеченных данных.

Предложена платформа MGRAL, использующая улучшение метрики mAP в качестве сигнала вознаграждения для выбора наиболее информативных выборок в процессе активного обучения для обнаружения объектов.
Ограниченность размеченных данных часто становится узким местом в обучении высокоточных моделей обнаружения объектов. В данной работе, посвященной ‘Performance-guided Reinforced Active Learning for Object Detection’, предложен новый подход к активному обучению, использующий обучение с подкреплением для выбора наиболее информативных образцов. Ключевой особенностью является максимизация улучшения средней точности (mAP) в качестве сигнала вознаграждения, что позволяет эффективно оптимизировать процесс разметки. Может ли данная методика открыть новые перспективы для создания более эффективных и экономичных систем обнаружения объектов, требующих минимальных затрат на ручную разметку?
Вызов Эффективного Обнаружения Объектов
Обнаружение объектов, являясь фундаментальной задачей компьютерного зрения, требует значительных объемов размеченных данных для обеспечения надежной и точной работы. Эффективность алгоритмов напрямую зависит от качества и количества обучающих примеров, на которых они были обучены. Разметка данных, включающая в себя выделение объектов на изображениях или видео и присвоение им соответствующих категорий, представляет собой трудоемкий и дорогостоящий процесс. Чем сложнее сценарий и чем больше разнообразие объектов, тем больше данных требуется для достижения приемлемого уровня производительности. В связи с этим, создание и использование обширных, высококачественных наборов данных является критически важным фактором для развития и внедрения систем обнаружения объектов в различных областях, от автономных транспортных средств до медицинского анализа изображений.
Создание высокоточных систем обнаружения объектов традиционно требует огромных объемов размеченных данных, таких как те, что представлены в наборах COCO и VOC. Процесс ручной аннотации каждого объекта на изображениях — трудоемкий и дорогостоящий, требующий значительных временных затрат и квалифицированного персонала. Необходимость точно обвести и классифицировать тысячи или даже миллионы объектов становится серьезным препятствием для широкого внедрения подобных технологий, особенно в областях, где данные уникальны или быстро меняются. Этот фактор существенно ограничивает возможности автоматизации и масштабирования систем компьютерного зрения, подчеркивая потребность в более эффективных методах обучения, не требующих столь обширных размеченных данных.
Ограниченность размеченных данных становится серьезным препятствием для внедрения систем обнаружения объектов в условиях ограниченных ресурсов или при работе с быстро меняющимися классами объектов. В частности, для приложений, работающих на мобильных устройствах или в условиях недостаточной вычислительной мощности, сбор и аннотация больших наборов данных для обучения моделей становятся непосильной задачей. Кроме того, в областях, где появляются новые типы объектов, такие как инновационные промышленные детали или редкие виды животных, необходимость постоянной переподготовки моделей на новых данных создает значительные трудности и задерживает развертывание эффективных систем. Данная проблема стимулирует поиск альтернативных подходов к обучению моделей, не требующих огромных объемов размеченных данных, например, методы обучения с подкреплением или самообучения.

Активное Обучение: Более Разумный Подход к Выбору Данных
Активное обучение представляет собой принципиально иной подход к построению моделей машинного обучения, отличающийся от традиционных методов, где для обучения используются случайно отобранные данные. Вместо этого, активное обучение стратегически отбирает наиболее информативные или неопределенные образцы данных для ручной разметки. Это позволяет добиться сопоставимой или даже более высокой точности модели, используя значительно меньший объем размеченных данных, что существенно снижает затраты на аннотацию и время, необходимое для обучения. Фактически, вместо пассивного использования всего доступного датасета, алгоритм активно “запрашивает” у эксперта разметку только тех данных, которые наиболее важны для улучшения его производительности.
Активное обучение позволяет достичь сопоставимой производительности с традиционными методами машинного обучения, используя значительно меньший объем размеченных данных. Вместо случайного выбора данных для разметки, алгоритмы активного обучения фокусируются на отборе наиболее неопределенных или информативных экземпляров. Это достигается путем оценки каждого неразмеченного образца с использованием различных критериев, таких как энтропия, маржинальное расстояние или ожидаемый модельный выход. Выбирая данные, в которых модель наиболее неуверена или которые, как ожидается, внесут наибольший вклад в улучшение ее точности, активное обучение оптимизирует процесс разметки и снижает затраты на аннотацию данных, сохраняя при этом высокую производительность.
Основная сложность активного обучения заключается в разработке эффективных стратегий отбора пакетов данных (Batch Selection) для разметки на каждой итерации. Алгоритмы Batch Selection должны определять подмножество неразмеченных данных, которое принесет максимальную информационную выгоду для модели при минимальных затратах на разметку. Критерии отбора включают в себя неопределенность модели (например, наименьшая уверенность в предсказаниях), разнообразие данных (выбор образцов, представляющих различные классы или области признакового пространства) и ожидаемую модельную ошибку. Эффективность стратегии Batch Selection напрямую влияет на скорость обучения и общую производительность модели, требуя баланса между эксплуатацией текущих знаний и исследованием неразмеченных данных.
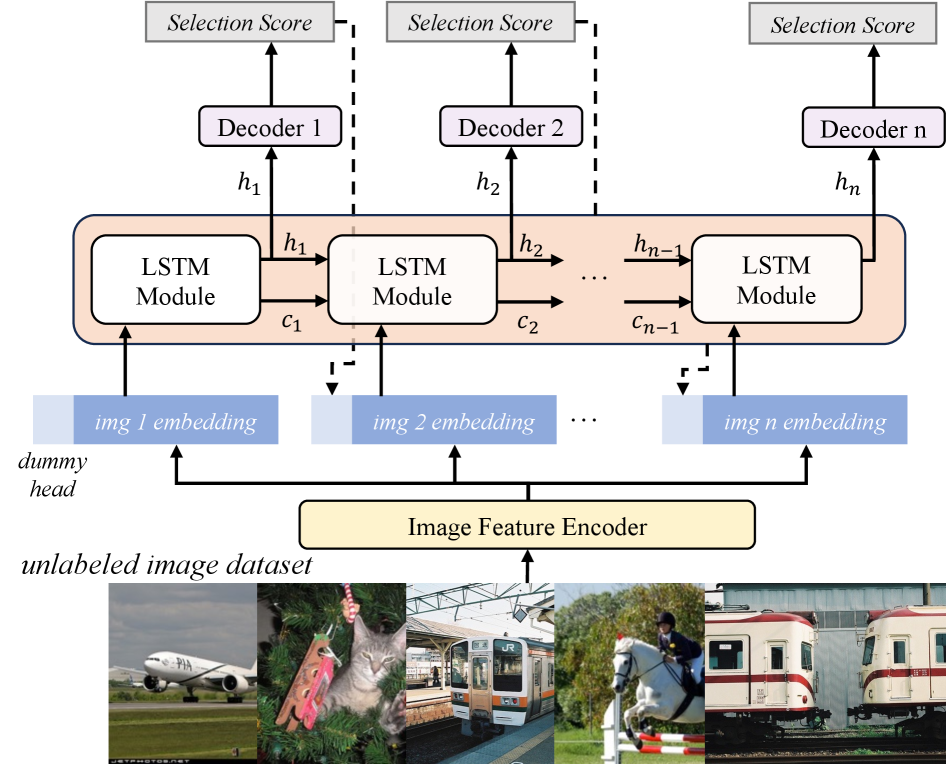
Performance-guided Reinforced Active Learning: Новый Подход
Предлагаемый метод Performance-guided Reinforced Active Learning (PARL) использует принципы обучения с подкреплением для оптимизации процесса выборки данных. Вместо случайного или эвристического отбора, PARL обучает агента, который формирует стратегию выбора пакетов данных для разметки. Агент оценивает потенциальные пакеты данных и выбирает те, которые, по его прогнозам, принесут наибольшую пользу в улучшении производительности модели. Этот подход позволяет динамически адаптировать процесс выборки к текущему состоянию модели, что приводит к более эффективному использованию ресурсов разметки и повышению точности модели машинного обучения.
В предложенном методе обучения с подкреплением (Reinforcement Learning) агент обучается политике выбора пакетов данных, используя изменение средней точности (Mean Average Precision, mAP) в качестве сигнала вознаграждения. Экспериментальные результаты на наборах данных VOC и COCO демонстрируют, что данная политика последовательно превосходит все базовые методы (baselines). Увеличение mAP служит прямым показателем улучшения производительности модели, а использование его в качестве сигнала вознаграждения позволяет агенту эффективно оптимизировать процесс выборки данных для достижения максимального прироста точности.
Предлагаемый подход к активному обучению интеллектуально сбалансирует стратегии исследования и использования данных. Это достигается путем выбора образцов, которые максимизируют прирост производительности модели при одновременной минимизации затрат на разметку. Алгоритм динамически оценивает потенциальную информативность каждого образца, отдавая приоритет тем, которые, как ожидается, окажут наибольшее влияние на повышение точности, но при этом требуют минимальных усилий по разметке. Такой подход позволяет эффективно использовать ограниченный бюджет на разметку, концентрируясь на наиболее важных данных для обучения модели.
Использование представлений на основе ‘Feature Embedding’ значительно повышает способность агента к обобщению при работе с разнообразными экземплярами объектов. Вместо обработки необработанных данных, агент оперирует с компактными векторными представлениями, извлеченными из изображений с помощью предварительно обученных моделей. Эти векторные представления кодируют семантическую информацию об объектах, позволяя агенту оценивать сходство и различия между ними, даже если объекты имеют различные размеры, углы обзора или условия освещения. В результате, агент способен эффективно выбирать наиболее информативные образцы для аннотации, даже если эти образцы существенно отличаются от тех, которые он видел ранее, что способствует улучшению обобщающей способности модели и повышению точности обнаружения объектов на новых данных.
Усиление Надежности посредством Разнообразия и Неконтролируемого Анализа
Интеграция методов неконтролируемого обучения, таких как кластеризация или понижение размерности, играет ключевую роль в формировании более разнообразных выборок данных. Применение этих техник позволяет выявлять и учитывать скрытые структуры в неразмеченных данных, что, в свою очередь, способствует отбору образцов, представляющих различные подгруппы и особенности. Такой подход особенно важен в ситуациях, когда доступ к размеченным данным ограничен или когда наблюдается дисбаланс между классами. За счет увеличения разнообразия в обучающих выборках, алгоритмы машинного обучения становятся более устойчивыми к шуму и переобучению, демонстрируя улучшенную обобщающую способность и более точные прогнозы на новых, ранее невиданных данных.
Разнообразие в отборе данных играет ключевую роль в снижении предвзятости и повышении обобщающей способности моделей, особенно в условиях ограниченного или несбалансированного набора данных. Когда алгоритм обучается на узком спектре примеров, он может развить склонность к определенным характеристикам, игнорируя другие важные аспекты. Использование разнообразных данных позволяет модели столкнуться с более широким диапазоном ситуаций, что способствует формированию более устойчивых и точных представлений. В ситуациях, когда некоторые классы представлены недостаточно, акцент на разнообразии помогает алгоритму лучше понимать и классифицировать менее распространенные случаи, предотвращая доминирование более частых категорий и повышая общую надежность системы.
В рамках повышения эффективности обучения моделей активно используются метрики разнообразия для формирования репрезентативных выборок из неразмеченных данных. Подход заключается в оценке степени отличия каждого потенциального образца от уже отобранных, с приоритетом отбора тех, которые максимально расширяют охват всего неразмеченного набора. Это позволяет избежать предвзятости, возникающей при случайном отборе, и способствует улучшению обобщающей способности модели, особенно в ситуациях, когда размеченных данных недостаточно или они распределены неравномерно. Использование метрик разнообразия гарантирует, что отобранные образцы отражают всё многообразие данных, что критически важно для создания надежных и точных моделей машинного обучения.
Для значительного ускорения процесса обучения с подкреплением была применена таблица поиска, позволяющая эффективно хранить и извлекать предварительно вычисленные признаки. Данный подход позволил добиться впечатляющего увеличения скорости работы — в 1600 раз. Вместо 4800 минут, необходимых для обучения на четырех графических процессорах GTX 1080Ti, время обучения сократилось до 3 минут. Такое радикальное снижение вычислительных затрат открывает новые возможности для обучения сложных моделей в разумные сроки и с минимальными ресурсами, делая продвинутые алгоритмы доступными для более широкого круга исследователей и практиков.
Перспективы Развития: Адаптация к Динамичным Условиям
Предложенная архитектура открывает путь к непрерывному обучению моделей обнаружения объектов, позволяя им адаптироваться к новым классам объектов или меняющимся условиям окружающей среды без необходимости полной переподготовки с нуля. Вместо этого, система способна выборочно обновлять свои знания, используя новые данные для уточнения существующих представлений, что значительно сокращает вычислительные затраты и время, необходимое для поддержания актуальности модели. Такой подход особенно важен в динамичных сценариях, где объекты и окружение могут меняться со временем, позволяя системе оставаться эффективной и точной даже в условиях непрерывного потока информации и новых вызовов.
Дальнейшие исследования направлены на интеграцию передовых алгоритмов обучения с подкреплением, в частности, архитектур, использующих сети LSTM. Эти рекуррентные нейронные сети позволяют моделировать последовательные решения, что критически важно для адаптации к динамически меняющимся условиям. Использование LSTM-сетей позволит системе не просто реагировать на текущую ситуацию, но и учитывать предыдущие действия и предвидеть будущие изменения, оптимизируя процесс обнаружения объектов в сложных и непредсказуемых средах. Такой подход позволит создавать системы, способные к непрерывному обучению и совершенствованию в реальном времени, что особенно актуально для приложений, требующих высокой степени надежности и адаптивности.
Для повышения эффективности стратегии отбора данных планируется исследование возможностей регрессии Гаусса — процесса, позволяющего более точно моделировать ожидаемые изменения в выходных данных модели. Такой подход позволит предсказывать, какие данные окажут наибольшее влияние на адаптацию системы обнаружения объектов к новым условиям или классам, что, в свою очередь, приведет к снижению потребности в больших объемах размеченных данных и ускорению процесса обучения. Использование Gaussian Process Regression позволит не просто выбирать данные случайным образом, а целенаправленно отбирать наиболее информативные примеры, способствующие более быстрой и точной настройке модели в динамически меняющейся среде. Это, в конечном итоге, позволит создать более устойчивые и эффективные системы обнаружения объектов, способные адаптироваться к новым вызовам без необходимости полной переподготовки.
Разработанный подход открывает перспективы для создания более надежных, эффективных и приспособляемых систем обнаружения объектов, предназначенных для использования в реальных условиях. Особенностью данной разработки является компактный размер модели, составляющий всего 33.0 миллиона параметров, что позволяет ее эффективно применять на устройствах с ограниченными вычислительными ресурсами. Это достигается за счет способности системы к непрерывному обучению и адаптации к новым условиям без необходимости полной переподготовки, что существенно сокращает время и затраты на обслуживание и обновление. Такой подход позволяет создавать системы, способные успешно функционировать в динамично меняющихся средах, обеспечивая высокую точность и стабильность обнаружения объектов в различных сценариях.
Представленное исследование демонстрирует элегантный подход к проблеме активного обучения в задачах обнаружения объектов. Авторы предлагают систему, в которой выбор наиболее информативных образцов для разметки осуществляется с помощью обучения с подкреплением, где улучшение метрики mAP выступает в качестве сигнала вознаграждения. Это позволяет значительно повысить эффективность использования данных и добиться лучших результатов модели. Как однажды заметил Эндрю Ын: «Мы должны стремиться к созданию систем, которые не просто работают, но и учатся с опытом». Данный подход, безусловно, соответствует этой философии, поскольку он позволяет модели адаптироваться и улучшаться на основе получаемой обратной связи, что особенно важно в контексте ограниченных ресурсов для разметки данных.
Что дальше?
Представленная работа, безусловно, вносит свой вклад в гармонизацию активного обучения и обучения с подкреплением. Однако, как часто бывает, решение одной задачи неизбежно обнажает новые грани нерешенных проблем. Стремление к повышению точности обнаружения объектов, измеряемой через mAP, не должно затмевать более фундаментальные вопросы. Действительно ли улучшение метрики является самоцелью, или же необходимо более глубокое понимание того, что именно делает образец информативным? Словно опытный музыкант, настраивающий инструмент, необходимо не просто добиться чистого звука, но и понять природу резонанса.
Будущие исследования могли бы сосредоточиться на исследовании методов, позволяющих агенту не просто выбирать образцы, но и понимать их. Интеграция принципов самообучения, позволяющих модели самостоятельно генерировать обучающие сигналы, представляется перспективным направлением. Ведь каждый интерфейс звучит, если настроен с вниманием. Недостаточно лишь увеличить громкость; необходима филигранная работа над тональностью и тембром. Иначе, любой, даже самый сложный алгоритм, превратится в какофонию.
И, наконец, стоит задуматься о границах применимости предложенного подхода. Насколько эффективно MGRAL будет работать в условиях ограниченных вычислительных ресурсов или в сценариях, где разметка данных сопряжена со значительными затратами? Плохой дизайн кричит, хороший шепчет. И порой, тишина является лучшим ответом.
Оригинал статьи: https://arxiv.org/pdf/2601.15688.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- Золото прогноз
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2026-01-24 23:46