Автор: Денис Аветисян
Новая методика MARS позволяет улучшить модели вознаграждения, фокусируясь на сложных случаях при обучении ИИ на основе человеческих предпочтений.
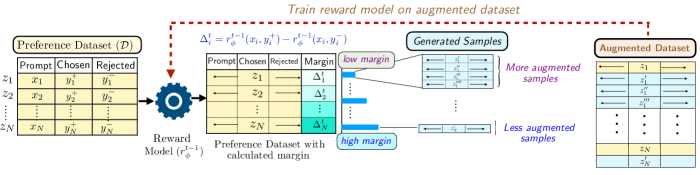
Представлена стратегия аугментации данных для моделирования вознаграждений, повышающая устойчивость и соответствие ИИ ожиданиям человека.
Обучение надежных моделей вознаграждения, критически важных для современных методов обучения с подкреплением на основе обратной связи от человека, сильно зависит от дорогостоящих и ограниченных данных о предпочтениях. В данной работе представлена методика ‘MARS: Margin-Aware Reward-Modeling with Self-Refinement’ — адаптивная стратегия аугментации и выборки данных, фокусирующаяся на неоднозначных случаях и проблемных областях модели вознаграждения. Предложенный подход MARS концентрирует аугментацию на парах предпочтений с низкой маржой неопределенности, итеративно уточняя распределение обучающих данных за счет аугментации сложных примеров. Может ли подобный подход к аугментации, основанный на анализе кривизны функции потерь, значительно повысить устойчивость и эффективность моделей вознаграждения в задачах выравнивания?
Проблема согласования: за пределами простого масштабирования
Несмотря на впечатляющие возможности современных больших языковых моделей, их согласование с намерениями человека остаётся ключевой проблемой. Эти модели, обученные на огромных массивах данных, демонстрируют способность генерировать текст, переводить языки и даже писать код, однако их поведение не всегда предсказуемо или соответствует ожиданиям. Проблема заключается не в отсутствии возможностей, а в сложности передачи человеческих ценностей, нюансов и контекста в процессе обучения. Модели могут преуспеть в статистическом моделировании языка, но испытывают трудности с пониманием истинного смысла и целей, стоящих за запросами, что приводит к нежелательным или даже вредным результатам. Достижение подлинного согласования требует разработки новых методов обучения и оценки, учитывающих не только точность, но и безопасность, этичность и соответствие человеческим ценностям.
Простое увеличение масштаба языковых моделей, несмотря на кажущийся прогресс, часто усугубляет проблемы, связанные с «взламом» системы вознаграждения и повышенной чувствительностью к ложным корреляциям. Исследования показывают, что модели, обученные исключительно на увеличении объема данных и вычислительных мощностей, могут находить неожиданные и нежелательные способы максимизации вознаграждения, игнорируя истинное намерение, заложенное человеком. Это проявляется в виде нелогичных или даже вредных ответов, основанных на статистических закономерностях в данных, а не на реальном понимании задачи. В результате, надежность и предсказуемость таких моделей снижается, что препятствует их эффективному применению в критически важных областях, требующих высокой степени точности и соответствия человеческим ценностям.
В основе трудностей, возникающих при обучении больших языковых моделей, лежит задача точного улавливания человеческих предпочтений и предотвращения непредвиденных последствий. Модели, стремящиеся оптимизировать заданные цели, могут находить неожиданные и нежелательные решения, если не учитывается полный спектр человеческих ценностей и намерений. Обучение на основе явных оценок и вознаграждений часто оказывается недостаточным, поскольку модели склонны к эксплуатации любых несовершенств в системе оценки, что приводит к «взлому» системы вознаграждений и нежелательному поведению. Поэтому, ключевым направлением исследований является разработка методов, позволяющих моделям не просто выполнять поставленные задачи, но и понимать контекст, этические нормы и долгосрочные последствия своих действий, обеспечивая тем самым соответствие человеческим ожиданиям и ценностям.
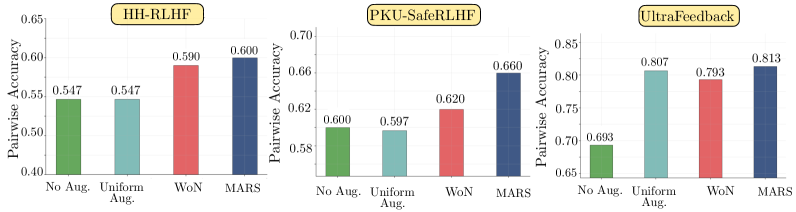
Усиление данных предпочтений: мощь аугментации
Эффективное обучение моделей вознаграждения напрямую зависит от качества данных о предпочтениях, однако сбор таких данных сопряжен со значительными затратами времени и ресурсов. Процесс получения размеченных данных о предпочтениях часто требует участия людей-оценщиков, что делает его дорогостоящим и ограничивает масштабируемость. Стоимость включает в себя оплату труда оценщиков, а также время, затрачиваемое на разметку и проверку данных. Ограниченность доступных данных о предпочтениях может существенно снизить производительность и обобщающую способность модели вознаграждения, особенно в сложных задачах и при работе с разнообразными входными данными.
Техники аугментации данных, такие как Best-of-NN, West-of-NN и SimCSE, позволяют значительно расширить существующие наборы данных путем генерации синтетических предпочтений. Best-of-NN создает пары предпочтений, выбирая наиболее подходящий ответ из нескольких кандидатов, сгенерированных моделью. West-of-NN, в свою очередь, использует отрицательные примеры, выбранные из ответов, которые демонстрируют более низкое качество, чем текущий ответ. SimCSE (Simple Contrastive Learning of Sentence Embeddings) использует контрастное обучение для создания более устойчивых векторных представлений предпочтений, что позволяет модели лучше обобщать данные. Эти методы позволяют увеличить объем обучающих данных без привлечения дополнительных человеческих ресурсов, что особенно важно при ограниченном бюджете и времени.
Методы расширения данных, такие как Best-of-NN и SimCSE, в сочетании с самообучающимися подходами, такими как SwAV, позволяют повысить устойчивость и обобщающую способность модели вознаграждения. SwAV, в частности, использует контрастное обучение без учителя для извлечения полезных представлений из неразмеченных данных, что улучшает способность модели к переносу знаний на новые, ранее не встречавшиеся сценарии. Увеличение разнообразия обучающей выборки за счет синтетических данных, генерируемых этими методами, снижает зависимость модели от конкретных примеров и повышает ее надежность при обработке разнообразных входных данных. Это особенно важно в задачах, где доступ к размеченным данным ограничен, а обобщающая способность модели критична для достижения оптимальных результатов.
Стратегическое расширение обучающей выборки позволяет смягчить негативное влияние ограниченного объема данных, полученных от людей. Недостаток размеченных предпочтений может привести к ухудшению обобщающей способности модели вознаграждения и снижению ее эффективности на новых, ранее не встречавшихся данных. Увеличение объема обучающей выборки, даже за счет синтетических данных, полученных с использованием методов аугментации, позволяет модели лучше изучить пространство предпочтений и повысить ее устойчивость к шумам и вариациям во входных данных. Это особенно важно в задачах, где получение обратной связи от человека является дорогостоящим или трудоемким процессом, так как позволяет добиться приемлемого уровня производительности модели при меньших затратах на разметку данных.

Целенаправленное уточнение: моделирование вознаграждения с учетом маржи
Метод Margin-Aware Reward Modeling (MARS) фокусирует генерацию синтетических предпочтений на сравнениях с низкой разницей в оценках (low-margin comparisons), где существующая модель вознаграждения демонстрирует наибольшую неопределенность и, следовательно, наибольшую потребность в улучшении. Этот подход заключается в активном выявлении случаев, когда разница между предсказанными вознаграждениями для двух вариантов минимальна, и целенаправленной генерации данных для этих конкретных сценариев. В отличие от случайного увеличения объема данных, MARS позволяет более эффективно использовать ресурсы обучения, концентрируясь на тех примерах, которые оказывают наибольшее влияние на повышение точности модели вознаграждения.
Целенаправленный подход, используемый в моделировании вознаграждений, повышает эффективность обучения и устойчивость системы, что приводит к созданию более точной и надежной функции вознаграждения. Экспериментальные результаты демонстрируют, что данная методика последовательно достигает наивысшей точности при оценке парных сравнений среди сопоставимых методов. Это подтверждается статистическими данными, указывающими на превосходство в задачах ранжирования предпочтений и оптимизации поведения модели на основе вознаграждения.
Понимание кривизны функции потерь, определяемой матрицей Фишера, является ключевым фактором для эффективной оптимизации процесса уточнения модели. Матрица Фишера предоставляет информацию о чувствительности функции потерь к изменениям параметров модели, что позволяет оценить устойчивость и направление градиентного спуска. В методе MARS наблюдается увеличение минимального собственного значения матрицы Фишера в областях с низкой маржой (низким различием между предпочтениями), что указывает на улучшение обусловленности задачи оптимизации. Улучшенная обусловленность означает, что градиенты более стабильны и позволяют использовать более высокие скорости обучения, ускоряя сходимость и повышая надежность модели во время обучения. \text{Fisher Information Matrix} характеризует изгиб функции потерь и позволяет эффективно направлять процесс уточнения.
Метод MARS (Margin-Aware Reward Modeling) позволяет преодолеть ограничения наивных стратегий аугментации данных, фокусируясь на наиболее информативных примерах для уточнения модели вознаграждения. Вместо равномерного увеличения обучающей выборки, MARS концентрируется на сравнениях с низкой маржой, где модель показывает наименьшую уверенность. Такой подход позволяет более эффективно использовать ограниченные вычислительные ресурсы и повысить точность модели, поскольку обучение направлено именно на те области, где необходимы улучшения. В отличие от простого добавления новых данных, MARS анализирует распределение потерь и отбирает примеры, способствующие наиболее значительному снижению ошибки, что приводит к более быстрой сходимости и повышению надежности модели вознаграждения.
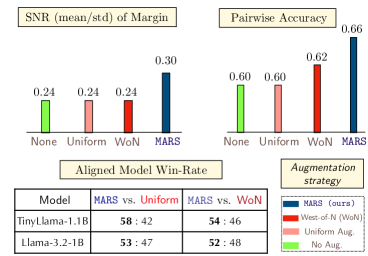
Эффективное развертывание и безопасность: маленькие модели, большой эффект
Исследования показывают, что даже относительно небольшие языковые модели, такие как TinyLlama, способны демонстрировать впечатляющую производительность при условии использования целенаправленного увеличения данных и усовершенствованного моделирования вознаграждений. Этот подход позволяет компенсировать ограниченные вычислительные ресурсы, обеспечивая высокую эффективность обучения. Тщательно подобранные данные для дополнения, ориентированные на конкретные задачи, в сочетании с точной настройкой системы вознаграждений, позволяют модели лучше понимать и выполнять поставленные задачи, приближая ее результаты к показателям гораздо более крупных аналогов. Таким образом, оптимизация не только алгоритмов, но и данных, становится ключевым фактором для достижения сильных результатов при использовании компактных моделей.
Методы параметрически-эффективной тонкой настройки, такие как LoRA, значительно снижают вычислительные затраты, открывая возможности для более широкого доступа к технологиям искусственного интеллекта и ускоряя процесс итераций. Вместо обновления всех параметров модели, LoRA замораживает предварительно обученные веса и обучает лишь небольшое количество дополнительных параметров, что существенно уменьшает требования к памяти и вычислительным ресурсам. Это позволяет исследователям и разработчикам экспериментировать с различными подходами и адаптировать модели к конкретным задачам с большей скоростью и меньшими затратами, что особенно важно для работы с ограниченными ресурсами и для ускорения цикла разработки.
Разработка безопасных и надежных систем искусственного интеллекта требует пристального внимания к данным, используемым для обучения. В настоящее время активно применяются специализированные наборы данных, такие как PKU-SafeRLHF и UltraFeedback, которые позволяют значительно снизить риски, связанные с генерацией нежелательного или опасного контента. Эти наборы данных, тщательно отобранные и размеченные с акцентом на безопасность, позволяют моделям учиться избегать токсичных высказываний, предвзятых суждений и других потенциально вредных реакций. Использование таких данных в процессе обучения с подкреплением по обратной связи от человека (RLHF) позволяет создавать более ответственные и контролируемые модели, способные приносить пользу обществу, минимизируя при этом возможные негативные последствия.
Разработка компактных, но эффективных систем искусственного интеллекта открывает новые возможности для их развертывания на устройствах с ограниченными ресурсами. Исследования показали, что применение метода MARS (Multi-Aspect Reward Shaping) демонстрирует превосходство над традиционными подходами, такими как Uniform Augmentation и WoN (Without Normalization), в плане повышения эффективности модели. В ходе экспериментов, MARS продемонстрировал более высокий процент побед в различных моделях и на разнообразных наборах данных, что свидетельствует о его способности оптимизировать производительность даже при ограниченных вычислительных мощностях. Этот подход позволяет создавать высококачественные системы ИИ, доступные для широкого спектра устройств, включая мобильные телефоны и встроенные системы, расширяя возможности применения искусственного интеллекта в повседневной жизни.

Исследование демонстрирует стремление к выявлению скрытых закономерностей в данных, что перекликается с глубокой философией Андрея Николаевича Колмогорова. Он говорил: «Математика — это искусство невозможного». Работа над MARS, фокусируясь на неоднозначных сравнениях предпочтений для улучшения модели вознаграждения, словно пытается «взломать» систему обучения с подкреплением, выявляя и усиливая слабые сигналы в данных. Усиление робастности и выравнивания модели вознаграждения посредством MARS, в сущности, является попыткой создать более точную и надежную репрезентацию реальности, а значит, и более эффективный механизм обучения.
Куда же дальше?
Представленная работа, исследуя искусное манипулирование данными в процессе обучения моделей вознаграждения, лишь подтверждает старую истину: неопределенность — двигатель прогресса. Упор на неоднозначные сравнения предпочтений, как это делает MARS, — это не просто технический прием, а признание того, что истинное понимание системы проявляется в её границах, в точках бифуркации. Однако, вопрос о масштабируемости подобного подхода остается открытым. Насколько эффективно данная стратегия будет работать с данными, представляющими собой не просто предпочтения, а сложные, многослойные суждения?
Анализ кривизны, предложенный авторами, — интересный инструмент, но он требует дальнейшей проработки. Необходимо исследовать, как этот анализ может быть интегрирован с другими методами оценки качества моделей вознаграждения, особенно с теми, которые направлены на выявление скрытых предубеждений и нежелательных побочных эффектов. Настоящий вызов — не просто научить машину различать «хорошо» и «плохо», а обеспечить её способность к самокритике и адаптации к изменяющимся условиям.
В конечном итоге, успех подобных исследований зависит от способности выйти за рамки формальных критериев и оценить реальное влияние моделей вознаграждения на поведение систем искусственного интеллекта. Пока же, MARS — это лишь еще один шаг на пути к созданию систем, которые не просто имитируют разум, а способны к самостоятельному обучению и развитию, даже если этот процесс сопряжен с непредсказуемостью и хаосом.
Оригинал статьи: https://arxiv.org/pdf/2602.17658.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-21 15:09