Автор: Денис Аветисян
Обзор мета-обучения и мета-обучения с подкреплением демонстрирует эволюцию от градиентных алгоритмов к современным универсальным агентам на основе трансформеров.
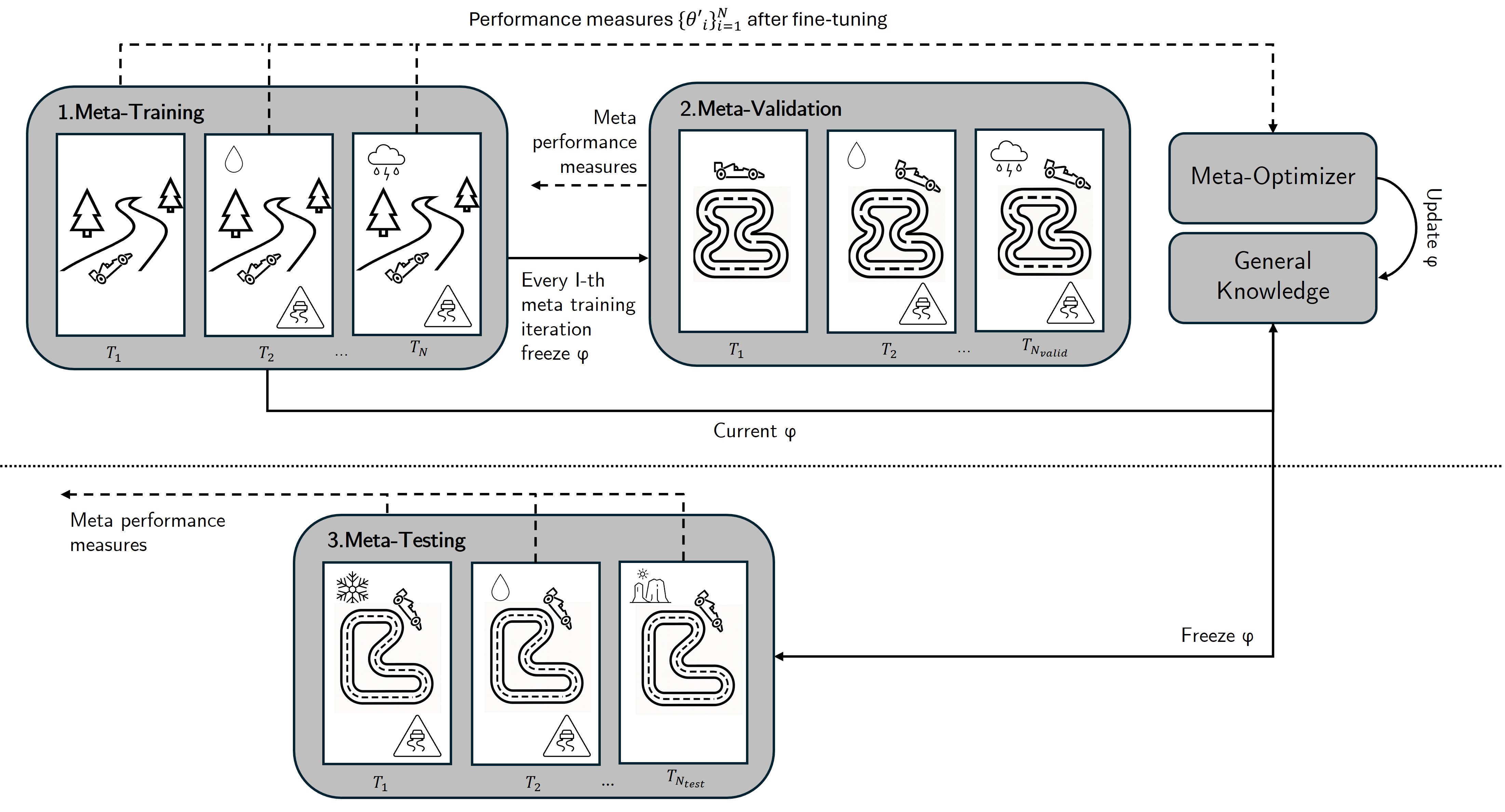
Всесторонний анализ мета-обучения с подкреплением, прослеживающий развитие от алгоритмов на основе градиентов к современным трансформерным архитектурам и перспективам создания автономных, адаптирующихся систем.
В то время как стандартные алгоритмы машинного обучения требуют значительных объемов данных для адаптации к новым задачам, человек способен эффективно использовать накопленный опыт. Данная работа, озаглавленная ‘Meta-Learning and Meta-Reinforcement Learning — Tracing the Path towards DeepMind’s Adaptive Agent’, представляет собой всесторонний обзор мета-обучения с подкреплением, прослеживающий эволюцию от ранних градиентных методов до современных трансформер-based агентских систем. Основной упор делается на формализацию мета-обучения, позволяющую понять принципы создания универсальных, способных к самообучению систем, подобных Adaptive Agent от DeepMind. Какие перспективы открывает дальнейшее развитие мета-обучения для создания действительно автономных и интеллектуальных агентов?
Мета-обучение: От адаптации к обучению адаптироваться
Традиционное обучение с подкреплением часто сталкивается с серьезными трудностями в динамично меняющихся средах. Алгоритмы, разработанные для решения конкретной задачи, требуют полной переподготовки при малейших изменениях условий. Это связано с тем, что они не способны эффективно обобщать полученный опыт и адаптироваться к новым ситуациям без значительных затрат времени и вычислительных ресурсов. Каждый раз, когда среда меняется, агент вынужден заново изучать оптимальную стратегию, что делает такой подход неэффективным и ресурсоемким, особенно в условиях, где изменения происходят быстро и непредсказуемо. Таким образом, необходимость в более гибких и адаптивных методах обучения становится очевидной, что и послужило толчком к развитию мета-обучения.
Мета-обучение представляет собой принципиально новый подход к созданию интеллектуальных систем, позволяющий агентам не просто решать конкретные задачи, а приобретать способность быстро адаптироваться к новым условиям. Вместо многократного переобучения при изменении среды, агент, обученный с использованием мета-обучения, накапливает знания о том, как учиться. Это достигается путем обучения на множестве различных, но связанных задач, что позволяет выявить общие закономерности и стратегии, применимые к новым, ранее не встречавшимся ситуациям. Таким образом, мета-обучение позволяет агентам эффективно экстраполировать полученный опыт, значительно сокращая время и ресурсы, необходимые для освоения новых навыков и решения новых задач, что открывает перспективы для создания по-настоящему гибких и интеллектуальных систем.
Переход от обучения конкретным задачам к освоению адаптируемых стратегий является ключевым шагом в создании действительно интеллектуальных систем. Традиционные алгоритмы машинного обучения, как правило, оптимизированы для выполнения узкоспециализированных задач и требуют значительной переподготовки при изменении условий. В отличие от них, мета-обучение позволяет агентам приобретать навыки, необходимые для быстрой адаптации к новым, ранее не встречавшимся ситуациям. Это достигается за счет формирования обобщенных знаний о том, как эффективно учиться, что позволяет системе не просто решать отдельные задачи, а самостоятельно осваивать новые навыки, подобно тому, как это делает человек. Способность к быстрой адаптации и обобщению знаний, таким образом, становится определяющим фактором в развитии искусственного интеллекта, способного к самостоятельному обучению и решению сложных проблем в динамично меняющемся мире.
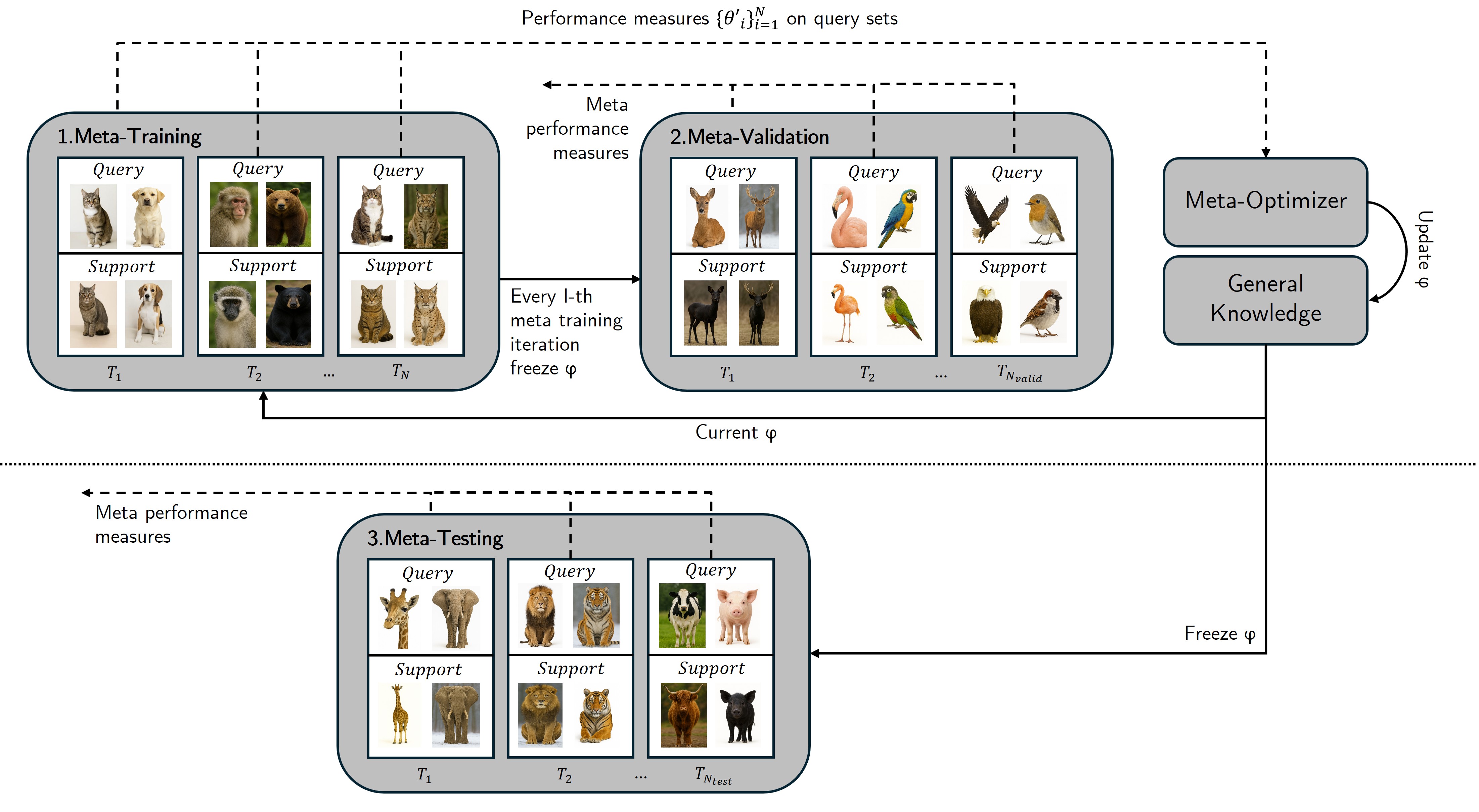
Основы адаптации: Градиентные и основанные на памяти подходы
Обучение на основе градиентов, представленное алгоритмом MAML (Model-Agnostic Meta-Learning), является базовым подходом к быстрой адаптации параметров модели к новым задачам. В основе MAML лежит поиск такой инициализации параметров, которая позволяет достичь высокой производительности на новых задачах всего за несколько шагов градиентного спуска. Алгоритм оптимизирует параметры модели таким образом, чтобы минимизировать потери после адаптации к новой задаче, используя градиенты, вычисленные на наборе задач. Это позволяет модели быстро «приспосабливаться» к незнакомым ситуациям, используя накопленный опыт, и эффективно обобщать знания между задачами. \nabla_{\theta} \sum_{T_i} L_{T_i}(\theta) — пример оптимизации, где θ — параметры модели, а L_{T_i} — функция потерь для задачи T_i .
Градиентные методы мета-обучения, такие как MAML, демонстрируют высокую эффективность при работе с относительно простыми распределениями задач. Однако, их производительность снижается при увеличении сложности этих распределений и возникновении задач, требующих учета долгосрочных зависимостей. Это связано с тем, что оптимизация градиентными методами стремится к локальному минимуму, и при высокой размерности пространства параметров или неоднородности задач, достижение глобального оптимума становится затруднительным. В частности, задачи, требующие запоминания и использования информации из предыдущих шагов или контекста, представляют сложность для градиентных методов, поскольку они не обладают встроенными механизмами для хранения и обработки такой информации.
Мета-обучение на основе памяти, использующее архитектуры, такие как рекуррентные нейронные сети (RNN), представляет собой альтернативный подход к быстрой адаптации модели к новым задачам. В отличие от методов на основе градиента, которые непосредственно изменяют параметры модели, подходы на основе памяти сохраняют и обрабатывают контекстную информацию о предыдущих задачах или шагах. Это позволяет модели учитывать историю взаимодействия с задачами и осуществлять более тонкую адаптацию, особенно в сценариях, где важны долгосрочные зависимости и учет предыдущего опыта. Сохранение информации в «памяти» позволяет модели извлекать релевантный контекст для текущей задачи, что приводит к улучшению обобщающей способности и эффективности в сложных задачах.
Продвинутое мета-обучение с подкреплением: Байесовский вывод и off-policy обучение
Эффективное обучение с подкреплением вне политики (off-policy meta-RL), реализованное в PEARL, значительно повышает эффективность использования данных за счет обучения на ранее собранных данных, что снижает потребность в дорогостоящих онлайн-взаимодействиях со средой. В традиционном обучении с подкреплением агент должен активно исследовать среду для сбора данных, что может быть ресурсоемким. PEARL использует данные из предыдущих задач или эпизодов для обучения политике, способной быстро адаптироваться к новым, но похожим задачам. Это достигается за счет использования реиграй-буфера (replay buffer), в котором хранятся переходы (состояние, действие, награда, следующее состояние). Обучение происходит путем выборки данных из этого буфера и обновления политики, что позволяет агенту обобщать полученные знания и быстрее обучаться новым задачам, требуя меньше прямых взаимодействий с окружающей средой.
Интеграция байесовского обучения с подкреплением позволяет агентам оценивать неопределенность в процессе обучения и принимать более обоснованные решения, особенно в средах с разреженным вознаграждением. В отличие от традиционных методов, которые возвращают единственную оценку значения действия, байесовский подход представляет значение как распределение вероятностей. Это позволяет агенту не только оценивать ожидаемое вознаграждение, но и измерять уверенность в этой оценке. В условиях разреженного вознаграждения, где положительные сигналы встречаются редко, учет неопределенности критически важен для эффективного исследования пространства состояний и избежания неоптимальных действий. Агент, осознающий свою неопределенность, будет склонен исследовать альтернативные варианты, что повышает вероятность обнаружения более выгодных стратегий, даже при отсутствии частых положительных сигналов. Использование байесовских методов, таких как гауссовские процессы или вариационное выведение, позволяет эффективно моделировать распределение значений и адаптировать стратегию исследования в зависимости от уровня неопределенности.
Алгоритмы, такие как VariBAD, объединяют возможности байесовского обучения с подкреплением и механизмы памяти для эффективного вывода характеристик задачи и последующей адаптации. В VariBAD используется байесовский вывод для оценки распределения вероятностей над параметрами задачи, позволяя агенту количественно оценивать неопределенность и учитывать ее при принятии решений. Механизмы памяти, такие как рекуррентные нейронные сети, позволяют агенту сохранять информацию о предыдущих взаимодействиях и использовать ее для прогнозирования будущих наград и состояний. Комбинация этих двух подходов позволяет агенту быстро адаптироваться к новым задачам, используя небольшое количество данных, и эффективно функционировать в условиях разреженного вознаграждения, что значительно повышает эффективность обучения в мета-обучении с подкреплением.
Адаптивный агент: Масштабирование обобщения с использованием современных методов
Адаптивный агент знаменует собой существенный прогресс в области обучения с подкреплением, используя архитектуры Transformer для моделирования последовательностей и обеспечения устойчивой адаптации к новым условиям. В отличие от традиционных подходов, полагающихся на фиксированные представления, агент способен динамически обрабатывать информацию и извлекать значимые закономерности из сложных последовательностей действий и наблюдений. Использование Transformer позволяет эффективно улавливать долгосрочные зависимости и контекст, что критически важно для успешного решения задач в динамичных и непредсказуемых средах. Данная архитектура позволяет агенту не просто реагировать на текущую ситуацию, но и предвидеть будущие события, что значительно повышает его эффективность и способность к обобщению полученных знаний.
Применение методов дистилляции знаний позволяет эффективно передавать опыт, накопленный крупными и сложными моделями, в более компактные и вычислительно эффективные агенты. Этот процесс, подобный обучению у опытного наставника, значительно снижает потребность в ресурсах для обучения и развертывания, делая сложные алгоритмы доступными для широкого спектра устройств и приложений. Дистилляция не просто копирует результаты работы большой модели, но и передает её способность к обобщению, позволяя небольшому агенту демонстрировать сопоставимую производительность, при этом требуя значительно меньше вычислительной мощности и энергии. Таким образом, данный подход открывает возможности для создания интеллектуальных систем, способных функционировать в условиях ограниченных ресурсов, например, на мобильных устройствах или встраиваемых системах.
Агент, использующий автоматическое обучение по учебному плану, демонстрирует способность к проактивному формированию последовательности задач, направленной на оптимизацию процесса обучения и, как следствие, ускорение адаптации к новым условиям. Вместо использования фиксированного набора заданий, агент самостоятельно определяет, какие задачи наиболее эффективно способствуют улучшению его навыков на каждом этапе обучения. Этот подход позволяет избежать застревания на сложных или нерелевантных задачах, а также обеспечивает более эффективное использование вычислительных ресурсов. По сути, агент выступает в роли собственного учителя, постоянно оценивая свой прогресс и подстраивая учебный план для достижения максимальной эффективности, что особенно важно при работе со сложными и динамично меняющимися средами.
Исследования, проведенные на сложных тестовых средах, таких как MetaWorld и XLand, продемонстрировали превосходные характеристики и обобщающую способность разработанного агента. Этот результат знаменует собой важный сдвиг в области обучения с подкреплением, поскольку агент успешно справляется с задачами, требующими более высокой степени адаптации и планирования, чем это было возможно в более ранних, упрощенных средах вроде grid-world, Atari и MuJoCo. Способность агента эффективно решать разнообразные и сложные задачи в MetaWorld и XLand подтверждает его потенциал для применения в реальных условиях, где окружающая среда динамична и непредсказуема. Данные результаты подчеркивают значительный прогресс в создании агентов, способных к обучению и адаптации в условиях возрастающей сложности, открывая новые возможности для автоматизации и решения сложных проблем.
Настоящий обзор систематизирует и уточняет ключевые метрики оценки, которые часто отсутствуют или недостаточно четко определены в существующих исследованиях в области обучения с подкреплением. Это позволило провести более строгие и сопоставимые эксперименты, выявив значительные преимущества разработанного адаптивного агента. В частности, анализ показал, что агент демонстрирует выдающиеся результаты в сложных задачах, требующих обобщения знаний, и способен эффективно функционировать в разнообразных средах, что подтверждает его статус крупномасштабного обобщающего агента. Четкое определение и использование унифицированных метрик позволяет не только объективно оценить прогресс в области, но и создает основу для дальнейших исследований и сравнения различных подходов к обучению.
Исследование эволюции мета-обучения с подкреплением демонстрирует закономерную тенденцию к созданию систем, способных адаптироваться к новым задачам без переобучения с нуля. Этот процесс напоминает создание сложного организма, где каждая часть взаимосвязана с другими. Как однажды заметил Линус Торвальдс: «Плохой дизайн — это когда что-то сложное делается сложным». Авторы статьи прослеживают переход от простых градиентных методов к сложным трансформерным архитектурам, что подтверждает стремление к элегантности и эффективности в алгоритмах обучения. Очевидно, что структура системы определяет её способность к адаптации и обобщению, что является ключевым аспектом в создании действительно интеллектуальных агентов.
Куда же дальше?
Представленный обзор, прослеживая эволюцию мета-обучения с акцентом на обучение с подкреплением, неизбежно обнажает фундаментальную сложность задачи создания действительно адаптивного агента. Переход от алгоритмов, основанных на градиентах, к трансформерам, безусловно, знаменует собой прогресс, однако он лишь смещает акцент проблемы, а не решает её. Способность агента к выводу задач остаётся узким местом; слишком часто «обобщение» сводится к распознаванию закономерностей в обучающей выборке, а не к пониманию глубинной структуры взаимодействия со средой.
Очевидно, что упрощение, заключённое в архитектуре трансформеров, имеет свою цену. Неизбежная сложность обучения таких моделей требует огромных вычислительных ресурсов и тщательно подобранных данных. Ирония заключается в том, что погоня за “общей” интеллектуальной способностью может привести к созданию систем, неспособных к эффективному обучению в принципиально новых, непредсказуемых ситуациях. Истинная адаптивность, вероятно, требует не увеличения масштаба моделей, а разработки принципиально новых подходов к представлению знаний и принятию решений.
Перспективы, кажется, лежат в исследовании более компактных, но при этом более выразительных представлений мира, возможно, вдохновлённых принципами нейробиологии. Важным направлением представляется разработка алгоритмов, способных к автономному исследованию среды и построению собственных моделей мира, не полагаясь исключительно на внешние данные. В конечном счёте, успех мета-обучения будет определяться не столько способностью агента быстро адаптироваться к новым задачам, сколько его способностью к самостоятельному обучению и самосовершенствованию.
Оригинал статьи: https://arxiv.org/pdf/2602.19837.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-02-25 03:18