Автор: Денис Аветисян
Исследование демонстрирует, что самообучение позволяет значительно повысить точность выделения объектов на изображениях, особенно в задачах локализации.
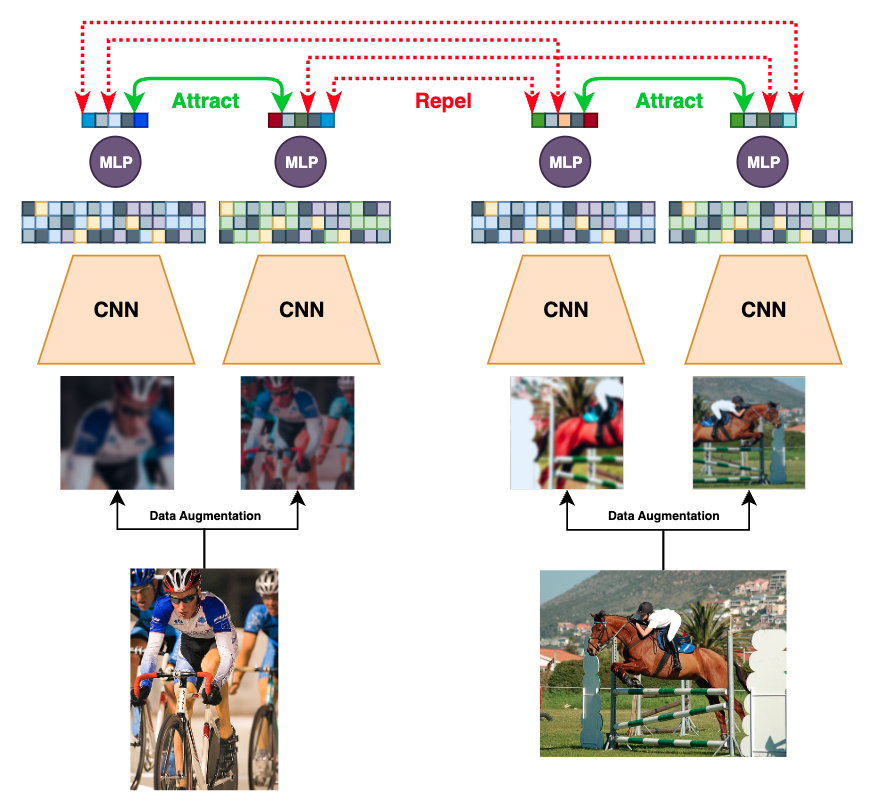
Предлагаемый подход к извлечению признаков с использованием самообучения превосходит традиционные предобученные сети в задачах обнаружения объектов, даже при ограниченном количестве размеченных данных.
Несмотря на значительный прогресс в области глубокого обучения, задача обнаружения объектов по-прежнему требует больших объемов размеченных данных, что является существенным ограничением для многих практических приложений. В данной работе, посвященной ‘A Self-Supervised Approach for Enhanced Feature Representations in Object Detection Tasks’, предлагается метод, основанный на самообучении, для повышения качества извлекаемых признаков. Полученные результаты демонстрируют, что предложенная модель превосходит современные предобученные сети, особенно в задачах точной локализации объектов, при использовании ограниченного количества размеченных данных. Каким образом дальнейшее развитие методов самообучения позволит создать более надежные и эффективные системы обнаружения объектов, снижая зависимость от дорогостоящей ручной разметки?
Прозрение сквозь пиксели: вызовы компьютерного зрения
Компьютерное зрение, подпитываемое достижениями глубокого обучения, совершило впечатляющий прорыв в понимании изображений. Благодаря развитию сверточных нейронных сетей и других архитектур глубокого обучения, системы компьютерного зрения теперь способны решать задачи, которые ранее казались недостижимыми, такие как распознавание объектов на изображениях и видео, сегментация изображений, а также определение сложных сцен. Эти успехи проявляются в широком спектре приложений, от автономных транспортных средств и медицинского анализа изображений до систем видеонаблюдения и улучшения качества фотографий. Современные алгоритмы демонстрируют точность, приближающуюся к человеческой, в некоторых задачах, открывая новые возможности для автоматизации и анализа визуальной информации, и постоянно расширяя границы возможного в области искусственного интеллекта.
Традиционные методы компьютерного зрения, как правило, требуют огромных объемов размеченных данных для эффективной работы. Это обстоятельство существенно ограничивает их применение в ситуациях, когда доступ к таким данным ограничен или отсутствует вовсе. Необходимость ручной разметки изображений — трудоемкий и дорогостоящий процесс, который становится особенно проблематичным в специализированных областях, таких как медицинская диагностика или анализ редких видов объектов. В условиях дефицита размеченных данных, точность и надежность традиционных алгоритмов резко снижается, что стимулирует поиск альтернативных подходов, способных эффективно обучаться на ограниченных выборках и обобщать полученные знания на новые, ранее не встречавшиеся изображения.
Эффективное извлечение признаков продолжает оставаться ключевым препятствием на пути к созданию универсальных систем компьютерного зрения. Несмотря на значительные успехи, достигнутые благодаря глубокому обучению, способность алгоритмов обобщать полученные знания и корректно работать с незнакомыми изображениями напрямую зависит от качества выделяемых признаков. Традиционные подходы часто оказываются уязвимыми к изменениям освещения, ракурса или частичной окклюзии объектов, что требует разработки более устойчивых и инвариантных методов. Современные исследования направлены на создание признаков, способных отражать семантическое содержание изображений и игнорировать несущественные детали, что позволит системам компьютерного зрения надежно функционировать в различных условиях и решать широкий спектр задач, от автономного вождения до медицинской диагностики.
Самообучение: новый взгляд на извлечение знаний
Самообучающееся обучение (Self-Supervised Learning) представляет собой альтернативный подход к машинному обучению, позволяющий моделям извлекать полезные представления из данных без использования размеченных данных. Традиционные методы машинного обучения требуют больших объемов вручную размеченных данных, что является трудоемким и дорогостоящим процессом. В отличие от них, самообучающееся обучение использует внутреннюю структуру самих данных для создания задач обучения, например, предсказание недостающих частей изображения или порядка последовательности. Это позволяет моделям изучать полезные признаки и представления, которые могут быть использованы для решения различных задач, не требуя предварительной ручной разметки данных. Таким образом, самообучающееся обучение значительно расширяет возможности применения машинного обучения, особенно в тех областях, где размеченные данные ограничены или недоступны.
Контрастное обучение — это метод машинного обучения без учителя, который формирует представления данных путем сравнения схожих и различных примеров. В его основе лежит идея, что полезные представления можно получить, обучая модель отличать положительные пары (схожие примеры) от отрицательных (различные примеры). Этот процесс предполагает создание пар данных, где один пример служит “якорем”, а другой — либо его преобразованной версией (положительный пример), либо совершенно другим примером из набора данных (отрицательный пример). Модель обучается максимизировать сходство между “якорем” и положительным примером, одновременно минимизируя сходство с отрицательными примерами. Эффективность контрастного обучения во многом зависит от выбора функций преобразования данных и стратегий формирования отрицательных пар.
SimCLR использует метод контрастного обучения для формирования качественных представлений данных. В основе лежит функция потерь InfoNCE (Noise Contrastive Estimation), которая максимизирует сходство между представлениями различных аугментированных версий одного и того же примера, одновременно минимизируя сходство с представлениями других примеров. L = -log(\frac{exp(sim(z_i, z_i^+)/\tau)}{ \sum_{j=1}^N exp(sim(z_i, z_j)/\tau)}), где z_i — представление примера, z_i^+ — представление положительной пары (аугментированная версия того же примера), sim — функция измерения сходства (например, косинусное расстояние), а τ — параметр температуры, контролирующий резкость распределения. Таким образом, SimCLR обучает модель отличать аугментированные версии одного и того же примера от других, что приводит к формированию устойчивых и информативных представлений.
Архитектуры EfficientNet демонстрируют значительное улучшение производительности и эффективности моделей, основанных на SimCLR. Использование EfficientNet в качестве backbone сети позволяет снизить вычислительные затраты и потребление памяти при обучении представлений, не жертвуя качеством. Исследования показывают, что замена традиционных backbone сетей, таких как ResNet, на EfficientNet приводит к повышению точности классификации и скорости обучения, особенно при работе с большими наборами данных. Эффективность достигается за счет использования compound scaling, который оптимально масштабирует глубину, ширину и разрешение сети, что позволяет добиться лучшего баланса между точностью и вычислительной сложностью.
Оценка эффективности на задаче обнаружения объектов
Обнаружение объектов, являясь ключевой задачей компьютерного зрения, демонстрирует существенное улучшение производительности при использовании признаков, полученных посредством самообучения. В отличие от традиционных методов, требующих большого количества размеченных данных, самообучение позволяет модели извлекать полезные представления из неразмеченных данных, что особенно важно при ограниченном количестве доступных размеченных образцов. Этот подход позволяет модели лучше обобщать и адаптироваться к новым, ранее не встречавшимся объектам и сценам, повышая точность и надежность системы обнаружения объектов. Эффективность самообучения подтверждается результатами экспериментов, где модели, использующие признаки, полученные таким образом, показывают более высокие показатели точности по сравнению с моделями, обученными на размеченных данных без использования самообучения.
Оценка качества обнаружения объектов обычно производится с использованием метрик среднего значения пересечения (Mean IoU) и точности локализации (Localization Accuracy). Mean IoU рассчитывается как отношение площади пересечения между предсказанной ограничивающей рамкой и истинной, к площади их объединения. Localization Accuracy определяет, насколько близко предсказанная ограничивающая рамка соответствует истинной, часто с использованием порогового значения IoU (например, IoU > 0.5 или IoU > 0.7). Эти метрики позволяют количественно оценить как точность классификации объектов, так и точность определения их местоположения на изображении, предоставляя комплексную оценку производительности модели.
Набор данных Pascal VOC является широко используемым эталоном для оценки производительности моделей обнаружения объектов в реалистичных сценариях. Он содержит аннотации для широкого спектра объектов, представленных в изображениях, что позволяет проводить количественную оценку точности и надежности различных алгоритмов. Набор данных включает в себя изображения, полученные из различных источников, отражающих разнообразие условий освещения, углов обзора и масштаба объектов, что обеспечивает более полную и объективную оценку производительности моделей в реальных условиях эксплуатации. Использование Pascal VOC позволяет исследователям сравнивать свои результаты с существующими решениями и отслеживать прогресс в области обнаружения объектов.
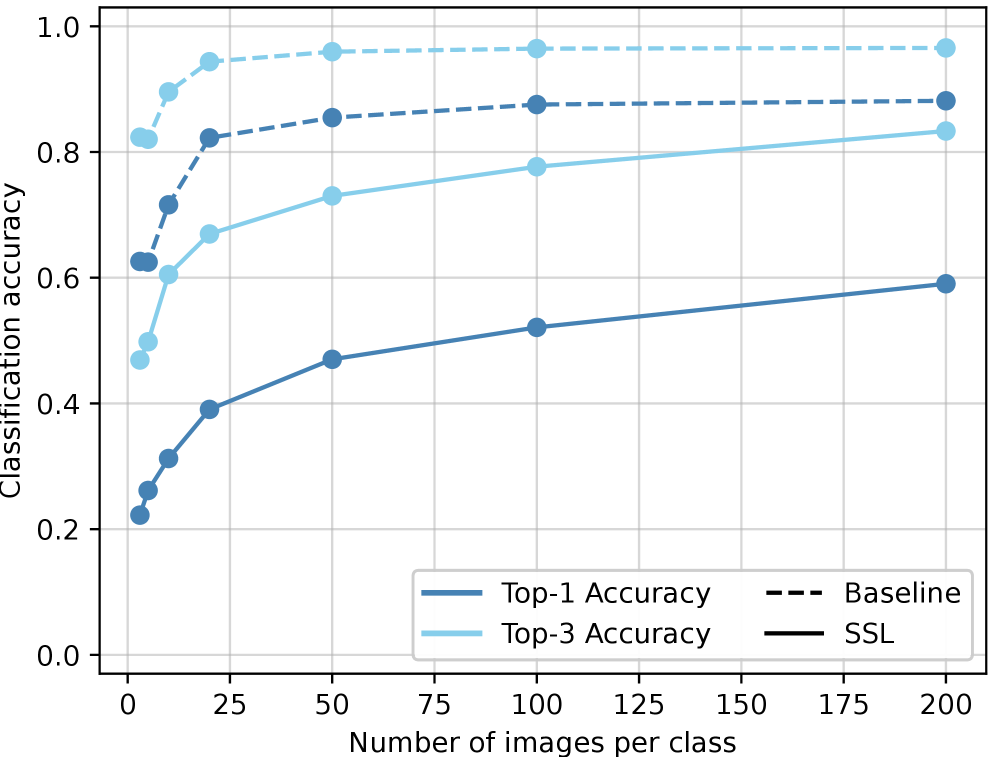
Предложенный алгоритм обучения без учителя (SSL) продемонстрировал превосходство над базовой моделью EfficientNetB1, предварительно обученной на ImageNet, в задачах локализации объектов. Эксперименты показали, что SSL-модель достигла более высокой точности локализации (Localization Accuracy) при значениях IoU 0.5 и IoU 0.7, что свидетельствует о повышенной способности к точному определению границ объектов даже при ограниченном количестве размеченных данных. Данный результат указывает на эффективность использования самообучения для улучшения производительности моделей обнаружения объектов в условиях дефицита размеченных данных.
Использование трансферного обучения, основанного на признаках, извлеченных методом самообучения, позволяет повысить эффективность задач обнаружения объектов даже при ограниченном объеме размеченных данных. Предварительное обучение модели на большом неразмеченном наборе данных с последующей тонкой настройкой на небольшом размеченном наборе позволяет модели обобщать знания и улучшать результаты, особенно в сценариях, где сбор и разметка данных являются дорогостоящими или трудоемкими. Это связано с тем, что самообучение позволяет модели изучать полезные представления признаков из неразмеченных данных, которые могут быть эффективно перенесены для решения задач обнаружения объектов, требующих меньшего количества размеченных примеров для достижения сопоставимой или даже более высокой точности.

Визуализация решений модели: взгляд внутрь «черного ящика»
Понимание факторов, определяющих решения модели, имеет решающее значение для отладки и повышения её эффективности. Анализ того, какие признаки изображения или данные оказывают наибольшее влияние на предсказание, позволяет выявить потенциальные ошибки в логике работы алгоритма. Например, если модель классифицирует изображения кошек, но при этом сильно реагирует на наличие определенных узоров на заднем плане, это может указывать на то, что она учится не на самих кошках, а на сопутствующих деталях. Выявление таких закономерностей позволяет разработчикам целенаправленно улучшать обучающие данные или архитектуру модели, добиваясь более точных и надежных результатов. В конечном итоге, глубокое понимание причин, лежащих в основе решений модели, является ключом к созданию систем компьютерного зрения, которым можно доверять.
Метод Grad-CAM предоставляет возможность визуализировать области изображения, оказывающие наибольшее влияние на принятое моделью решение. Он работает путем создания карты тепловой чувствительности, накладываемой на исходное изображение, где более яркие участки указывают на регионы, которые модель считает наиболее значимыми для классификации. По сути, Grad-CAM позволяет «заглянуть внутрь» нейронной сети и понять, какие визуальные признаки активируют ее для конкретного прогноза. Это особенно полезно при анализе сложных изображений, где трудно определить, на что именно обращает внимание модель, и позволяет выявить, соответствует ли ее фокус ожидаемым признакам или же указывает на потенциальные ошибки и предвзятости.
Метод визуализации градиентов, известный как Grad-CAM, позволяет выявить скрытые предубеждения и нежелательные закономерности в работе моделей компьютерного зрения. Анализ областей изображения, на которые модель обращает наибольшее внимание при принятии решения, может указать на то, что она фокусируется на несущественных деталях или признаках, искажающих результаты. Например, модель, обученная распознавать автомобили, может обращать внимание на фон вместо самого транспортного средства, или реагировать на определенный цвет, а не на форму. Такое обнаружение позволяет разработчикам скорректировать процесс обучения, убрав предвзятости и повысив надежность системы, что особенно важно для критически важных приложений, где точность и беспристрастность имеют первостепенное значение.
Повышение интерпретируемости моделей компьютерного зрения является ключевым фактором для создания более надежных и устойчивых систем. Возможность понять, какие именно признаки изображения влияют на принятие решения моделью, позволяет выявлять и устранять потенциальные ошибки, предвзятости и нежелательное поведение. Такой подход не только улучшает точность и обобщающую способность модели, но и способствует доверию к её результатам, особенно в критически важных областях применения, таких как медицинская диагностика или автономное вождение. В конечном итоге, прозрачность в принятии решений позволяет создавать системы, которые не просто «работают», но и объясняют, почему они принимают те или иные решения, что является необходимым условием для их широкого внедрения и эффективного использования.
Что дальше?
Представленные результаты, безусловно, демонстрируют прирост точности локализации. Однако, стоит помнить, что каждая новая функция, призванная «улучшить» детекцию, неизбежно превращается в дополнительный уровень сложности, требующий обслуживания. Улучшение на несколько процентов — это, конечно, приятно, но в продакшене рано или поздно выяснится, что эти самые проценты съедаются неожиданными краевыми случаями и особенностями данных. В конце концов, «бесконечная масштабируемость» — это фраза, которую уже слышали в 2012-м, только тогда она называлась «Big Data».
Интересно, что акцент сделан на улучшение качества признаков. Но не стоит забывать, что сама постановка задачи обнаружения объектов может быть неоптимальной. Попытки «выжать» больше из существующих архитектур, вероятно, будут продолжаться, пока не станет очевидно, что требуется принципиально новый подход к представлению и обработке визуальной информации. Если тесты зелёные — значит, они ничего не проверяют, а просто подтверждают, что модель хорошо запомнила обучающую выборку.
Вероятно, следующее поколение исследований будет направлено на разработку более устойчивых к изменениям данных и более адаптивных методов обучения без учителя. Но, как показывает история, каждое «революционное» решение — это лишь отсрочка неизбежного технического долга. И рано или поздно, даже самая элегантная архитектура потребует серьезной переработки.
Оригинал статьи: https://arxiv.org/pdf/2602.16322.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-19 14:14