Автор: Денис Аветисян
Новый подход позволяет создавать автономных агентов, способных к использованию инструментов, путем анализа естественного языка и выявления последовательностей действий.

Исследование демонстрирует возможность синтеза траекторий использования инструментов из текстовых корпусов, обходя необходимость в предопределенных инструментах и расширяя возможности обучения с подкреплением.
Несмотря на успехи больших языковых моделей, обучение автономных агентов, способных эффективно использовать инструменты в многошаговых взаимодействиях, остается сложной задачей из-за нехватки реалистичных данных. В работе «Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text» предложен новый подход к решению этой проблемы, основанный на извлечении траекторий использования инструментов непосредственно из текстовых корпусов. Авторы демонстрируют, что богатый опыт решения задач, содержащийся в тексте, может служить масштабируемым и аутентичным источником данных для обучения агентов. Способны ли подобные методы открыть путь к созданию более гибких и адаптивных автономных систем, способных эффективно решать широкий спектр задач?
Вызов масштабируемого использования инструментов
Несмотря на значительный прогресс в области больших языковых моделей, обеспечение надежного и обобщенного использования инструментов остается серьезной проблемой. Современные модели часто демонстрируют впечатляющие способности в обработке естественного языка, однако их применение к решению практических задач, требующих взаимодействия с внешними инструментами, сталкивается с существенными ограничениями. Существующие подходы, как правило, ограничены в способности адаптироваться к новым инструментам или незнакомым ситуациям, что препятствует их эффективному использованию в реальном мире. Способность к обобщению, то есть применению полученных навыков к различным инструментам и задачам без дополнительного обучения, остается ключевым препятствием на пути к созданию по-настоящему интеллектуальных систем, способных эффективно использовать инструменты для решения сложных проблем.
Существующие подходы к обучению языковых моделей использованию инструментов часто ограничены небольшими, вручную составленными наборами данных, что существенно снижает их адаптивность и эффективность в реальных условиях. Такая зависимость от тщательно отобранных примеров препятствует способности моделей обобщать знания и применять инструменты в новых, непредвиденных ситуациях. Вместо самостоятельного освоения навыков, модели вынуждены полагаться на заранее заданные сценарии, что делает их хрупкими и неспособными к решению задач, выходящих за рамки тренировочного набора. Подобное ограничение особенно заметно при взаимодействии со сложными инструментами, требующими многошаговых взаимодействий и умения адаптироваться к различным ответам и ошибкам.
Суть сложности заключается в создании разнообразных и многоходовых взаимодействий, необходимых для эффективного использования инструментов. Большие языковые модели испытывают трудности не просто в выполнении отдельных команд, а в поддержании последовательности действий, требующих уточнения, корректировки и адаптации к изменяющимся обстоятельствам. Это связано с тем, что для успешного освоения инструмента требуется не только понимание его функциональности, но и умение планировать цепочку действий, предвидеть возможные ошибки и оперативно реагировать на полученные результаты. Создание таких сложных диалогов, имитирующих реальный процесс решения задач с использованием инструментов, представляет собой значительную проблему для современных систем искусственного интеллекта, поскольку требует выхода за рамки простого сопоставления запросов и ответов и освоения навыков рассуждения и планирования.

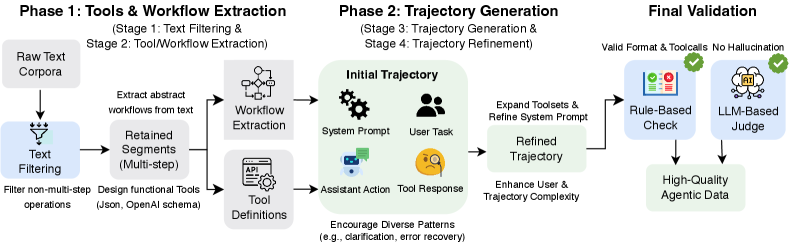
GEM: Конвейер синтеза траекторий из текста
Представляем GEM — методологию автоматической генерации многошаговых траекторий использования инструментов на основе корпусов текстовых данных. GEM позволяет создавать последовательности действий, имитирующие взаимодействие с различными инструментами, используя только текстовые данные в качестве входных данных. В отличие от ручной разработки, GEM автоматизирует процесс создания траекторий, что позволяет существенно увеличить объем и разнообразие синтетических данных для обучения и оценки моделей, работающих с инструментами. Методология не требует предварительно размеченных данных или экспертных знаний о конкретных инструментах, что делает ее масштабируемой и применимой к широкому спектру задач.
Метод GEM реализует автоматическое создание многошаговых траекторий использования инструментов посредством трех последовательных этапов. Сначала происходит извлечение рабочих процессов (workflow extraction), определяющее логическую структуру взаимодействия с инструментами. Затем, на этапе генерации траекторий (trajectory generation), формируется последовательность действий, соответствующая извлеченному рабочему процессу. Завершающий этап — уточнение траекторий (trajectory refinement) — направлен на обеспечение как структурной корректности, так и разнообразия генерируемых данных, что позволяет создавать более реалистичные и полные наборы данных для обучения моделей.
Представленный конвейер GEM позволяет создавать значительно более крупные и разнообразные наборы данных по сравнению с традиционными методами, обходя необходимость ручной курации. Синтезированные данные характеризуются в среднем 8,6 различными инструментами, используемыми в каждой траектории, и 46 сообщениями на диалог. Эти показатели существенно превосходят существующие наборы данных, такие как APIGEN-MT, который содержит в среднем 18,5 сообщений на диалог. Такое увеличение объема и разнообразия данных позволяет проводить более эффективное обучение и оценку моделей, взаимодействующих с инструментами.
Синтезатор траекторий: Обучение на текстах
Траекторный синтезатор представляет собой специализированную модель, обученную для усвоения соответствия между текстовым описанием и генерируемой траекторией. Эта модель играет ключевую роль в эффективной генерации данных, поскольку позволяет напрямую преобразовывать текстовые инструкции в соответствующие последовательности действий или перемещений. Обучение модели направлено на установление прочной связи между лингвистическими характеристиками текста и параметрами генерируемой траектории, что позволяет создавать новые данные на основе текстовых запросов без необходимости ручной разработки или моделирования.
Обучение с учителем на надежном наборе данных, сформированном GEM, позволяет модели траектории обобщать полученные знания и успешно работать с текстом, выходящим за рамки исходного обучающего корпуса. Этот процесс позволяет модели не просто запоминать соответствия между текстом и траекторией для конкретных примеров, но и извлекать общие закономерности, что критически важно для генерации данных, основанных на новых, ранее не встречавшихся текстовых запросах. Использование такого подхода значительно повышает устойчивость и адаптивность модели к разнообразным входным данным, обеспечивая более качественную и предсказуемую генерацию траекторий.
В ходе обучения Траекторного Синтезатора были протестированы две базовые модели — Qwen3-8B и Qwen3-32B. Использование синтезатора GEM для обучения позволило достичь точности в 28.38%. Данный показатель сопоставим с точностью, достигаемой при использовании данных, сгенерированных моделью GLM-4.6, что подтверждает эффективность выбранных базовых моделей и метода обучения для задачи преобразования текста в траектории.
Эмпирическая валидация и широкие перспективы
Проведенные эксперименты на эталонных наборах данных, таких как BFCL V3 и τ2-bench, продемонстрировали значительное превосходство моделей, обученных на данных, сгенерированных GEM, по сравнению с моделями, обученными на традиционных наборах данных. В частности, достигнута точность до 44,88% на BFCL V3, а на τ2-bench в домене розничной торговли показатель Pass@4 составил 86,84%, что сопоставимо с результатами обучения на данных, непосредственно относящихся к данной области. Эти результаты указывают на эффективность подхода GEM в создании более надежных и обобщающих моделей, способных успешно решать сложные задачи.
Возможность GEM использовать огромные объемы неструктурированного текста открывает принципиально новые перспективы в создании обобщенных и адаптивных агентов. В отличие от традиционных подходов, требующих тщательно размеченных данных, GEM способен извлекать знания и паттерны непосредственно из необработанного текста, что значительно расширяет спектр доступных обучающих материалов. Это позволяет создавать агентов, способных к более гибкому обучению и адаптации к различным задачам и средам, поскольку они не ограничены узкоспециализированными наборами данных. Такой подход не только повышает эффективность обучения, но и способствует развитию более универсальных и интеллектуальных систем, способных к решению широкого круга проблем, что является ключевым шагом на пути к созданию искусственного общего интеллекта.
Данная работа имеет далеко идущие последствия для развития Искусственного Общего Интеллекта (ИОИ), поскольку решает критически важную задачу обеспечения надежных возможностей использования инструментов. Способность агентов эффективно взаимодействовать с различными инструментами — от простых калькуляторов до сложных программных комплексов — является ключевым фактором для достижения истинного ИОИ, способного к адаптации и решению широкого спектра задач. Развитие надежных механизмов использования инструментов позволяет агентам преодолевать ограничения, заложенные в их собственных знаниях, и эффективно использовать внешние ресурсы для достижения целей. Таким образом, исследование открывает новые перспективы в создании интеллектуальных систем, приближающих нас к реализации ИОИ, способного к самостоятельному обучению и решению сложных проблем в реальном мире.
Исследование демонстрирует, что создание автономных агентов возможно не через жёсткое определение инструментов, а через извлечение паттернов их использования непосредственно из текстовых данных. Этот подход позволяет обойти ограничения традиционного обучения с подкреплением и масштабировать процесс, делая его более реалистичным. Как заметил Блез Паскаль: «Всякое великое дело включает в себя что-то непостижимое». В данном случае, непостижимым является способность агента к адаптации и обучению, проявляющаяся в синтезе траекторий использования инструментов, полученных из неструктурированного текста. Особенно ценно, что исследование подчёркивает важность многошаговых взаимодействий, показывая, что полноценное обучение требует учёта последовательности действий, а не только изолированных команд.
Что Дальше?
Представленная работа, несомненно, открывает новые горизонты в обучении автономных агентов. Однако, следует признать, что извлечение траекторий использования инструментов из текстовых корпусов — это лишь первый шаг. Истинный вызов заключается не в количестве данных, а в их качестве и репрезентативности. Легко создать иллюзию интеллекта, манипулируя поверхностными паттернами, но подлинная адаптивность требует понимания глубинных причинно-следственных связей.
Масштабируется не серверная мощность, а ясные идеи. В будущем, вероятно, потребуется сместить фокус с простого извлечения траекторий на создание более сложных моделей, способных к абстракции и обобщению. Необходимо учитывать контекст, намерение и даже — если позволено такое антропоморфизм — «удивление» агента. Представленная работа — это экосистема, где каждая часть влияет на целое, и для достижения устойчивости необходимо тщательно изучать все взаимосвязи.
Ирония заключается в том, что, стремясь к созданию автономных агентов, мы неизбежно сталкиваемся с ограничениями человеческого языка и понимания. Возможно, ключ к успеху лежит не в создании более совершенных алгоритмов, а в разработке новых способов представления знаний и взаимодействия с миром. Настоящая сложность — не в коде, а в архитектуре.
Оригинал статьи: https://arxiv.org/pdf/2601.10355.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- SUI ПРОГНОЗ. SUI криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-01-18 09:31