Автор: Денис Аветисян
Исследователи предлагают инновационную модель для поиска аномальных групп в графовых данных, способную эффективно работать даже при ограниченном количестве примеров.
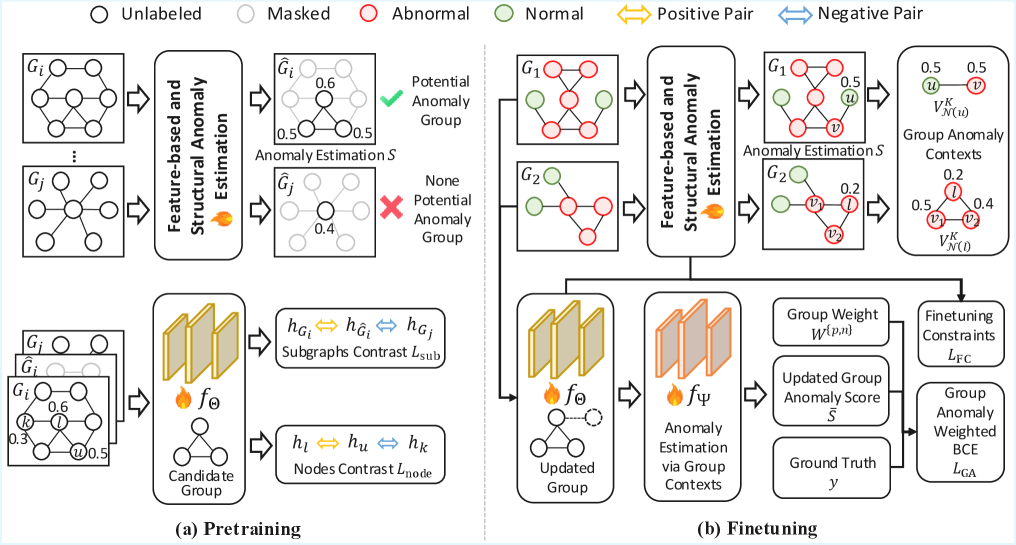
Представлена модель GFM4GA, использующая двухуровневое контрастное обучение и контекстную информацию для обнаружения групповых аномалий в графах.
Обнаружение аномальных групп в сетевых данных представляет собой сложную задачу, особенно в условиях ограниченного количества размеченных примеров. В данной работе представлена модель GFM4GA: Graph Foundation Model for Group Anomaly Detection, использующая принципы графовых фундаментальных моделей для эффективного выявления групповых аномалий. Предложенный подход, основанный на контрастивном обучении и анализе контекста, позволяет адаптироваться к новым, ранее не встречавшимся аномальным группам. Сможет ли данная архитектура стать основой для создания более устойчивых и интеллектуальных систем обнаружения аномалий в сложных сетевых структурах?
Там, где группы становятся угрозой: вызов для обнаружения аномалий
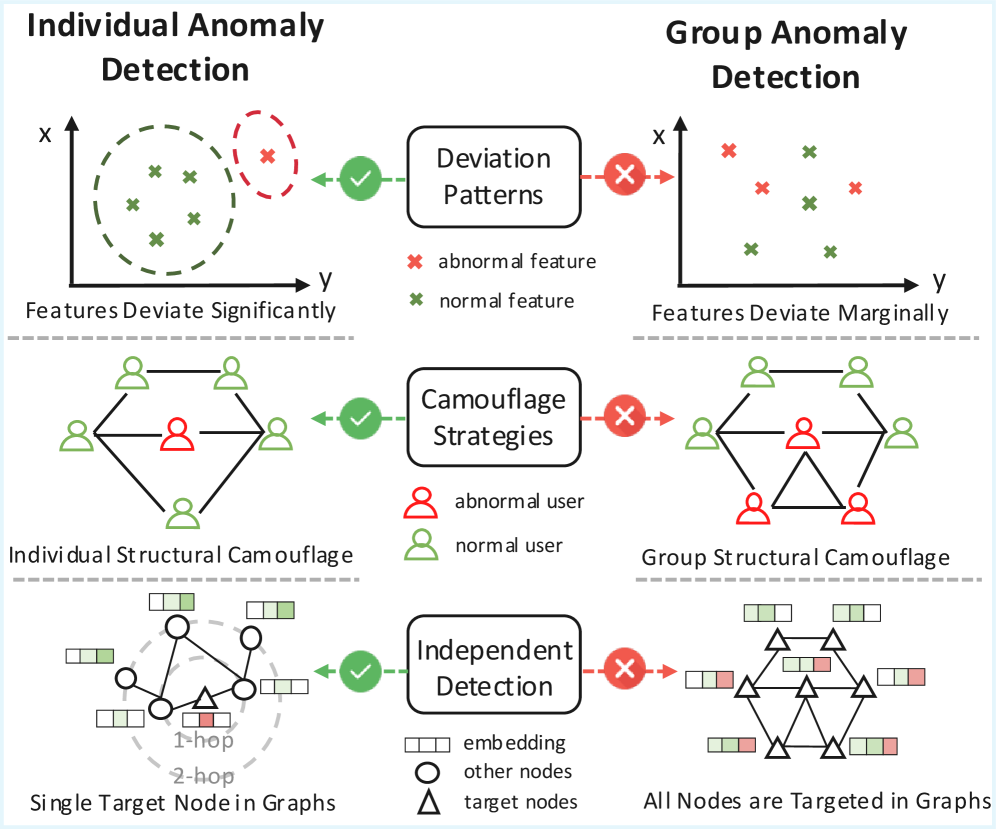
Традиционные методы обнаружения аномалий в графах часто концентрируются на выявлении отдельных узлов, игнорируя критически важные аномальные группы, которые представляют значительные риски. В то время как анализ отдельных узлов может выявить изолированные случаи мошенничества или сбои в сети, именно скоординированные действия группы злоумышленников или сложные взаимодействия между скомпрометированными устройствами часто представляют наибольшую угрозу. Например, в финансовых сетях аномальная группа может представлять собой синдикат мошенников, координирующих свои действия для обмана. В сетях кибербезопасности, группа скомпрометированных узлов может представлять собой сеть ботов, осуществляющих распределенную атаку. Таким образом, фокусировка исключительно на индивидуальных аномалиях может привести к упущению из виду этих более сложных и опасных групповых угроз, подчеркивая необходимость сдвига парадигмы в обнаружении аномалий.
Выявление аномальных групп имеет решающее значение в различных областях, включая обнаружение мошеннических операций и обеспечение сетевой безопасности. Традиционные методы анализа часто концентрируются на отдельных сущностях, упуская из виду скоординированные действия, которые представляют значительно больший риск. Например, в сфере финансовых преступлений, единичные подозрительные транзакции могут быть легко замаскированы, в то время как скоординированная сеть мошенников, осуществляющих множество небольших операций, остается незамеченной. Аналогично, в кибербезопасности, изолированные атаки могут быть легко отражены, однако, аномальные группы, координирующие распределенные атаки типа «отказ в обслуживании», представляют серьезную угрозу. В связи с этим, необходим переход к аналитическим подходам, способным идентифицировать и анализировать не отдельные аномалии, а именно аномальные группы и их взаимодействие, что требует переосмысления существующих методологий и разработки новых алгоритмов.
Существующие методы обнаружения аномалий сталкиваются со значительными трудностями при анализе групповых структур. Сложность заключается не только в самой природе этих структур, но и в критической нехватке размеченных данных, необходимых для обучения алгоритмов. В отличие от анализа отдельных узлов, где можно опираться на более обширные наборы данных, выявление аномальных групп требует учета взаимосвязей между элементами и поиска паттернов, которые не встречаются в нормальной активности. Эта дефицитность размеченных данных особенно сильно влияет на способность алгоритмов к обобщению и адаптации к новым, ранее не встречавшимся аномалиям, что снижает эффективность обнаружения и требует разработки инновационных подходов, способных учиться на ограниченном количестве примеров и выявлять скрытые групповые связи.
Для эффективного выявления аномальных групп необходимы принципиально новые подходы, способные улавливать едва заметные закономерности в их структуре и обобщать информацию на основе ограниченного числа примеров. Традиционные методы часто оказываются неэффективными из-за сложности анализа взаимосвязей внутри групп и дефицита размеченных данных, описывающих аномальное групповое поведение. Разрабатываемые инновационные алгоритмы стремятся преодолеть эти ограничения, используя методы машинного обучения, позволяющие выявлять отклонения от нормы даже при недостатке обучающих данных. Особое внимание уделяется техникам, способным к самообучению и адаптации к изменяющимся условиям, что критически важно для обнаружения сложных и динамичных аномальных групп в реальных сценариях, например, в сетях распространения мошеннических схем или в системах информационной безопасности.
GFM4GA: Фундамент для обнаружения групповых аномалий
GFM4GA использует возможности графовых фундаментальных моделей, предварительно обученных на обширных корпусах графов. Предварительное обучение позволяет моделям извлекать устойчивые и информативные представления узлов и связей в графе. Этот процесс включает в себя анализ структуры графа и характеристик узлов на больших наборах данных, что позволяет моделям выучить обобщенные признаки и взаимосвязи. В результате, GFM4GA способна эффективно представлять графы, даже при наличии неполной или зашумленной информации, и использовать эти представления для решения различных задач, включая обнаружение аномалий. Использование предварительно обученных моделей значительно снижает потребность в большом количестве размеченных данных для конкретной задачи.
В основе GFM4GA лежит модуль оценки аномалий на основе признаков, использующий метод главных компонент (PCA) для количественной оценки отклонений в поведении узлов графа. PCA позволяет выделить наиболее значимые признаки, описывающие нормальное поведение узлов, и спроецировать данные в пространство меньшей размерности. Аномалии выявляются как узлы, демонстрирующие значительные отклонения от реконструированных данных в этом пространстве, измеряемые, например, через среднеквадратичную ошибку реконструкции. Данный подход позволяет эффективно определять аномалии, основываясь на отклонениях в многомерном пространстве признаков, а не только на изолированных свойствах узлов.
Для повышения различительной способности внутри групп, GFM4GA использует методы контрастивного обучения как на уровне отдельных узлов, так и на уровне подграфов. Контрастивное обучение на уровне узлов позволяет модели научиться различать нормальное поведение узла от аномального, максимизируя расстояние между представлениями узлов в этих двух состояниях. В свою очередь, контрастивное обучение на уровне подграфов фокусируется на выявлении аномальных паттернов взаимодействия между узлами, что особенно важно для обнаружения коллективных аномалий, которые могут быть незаметны при анализе отдельных узлов. Комбинация этих двух подходов позволяет GFM4GA эффективно выявлять отклонения в структуре и поведении графа, даже в сложных и неоднородных данных.
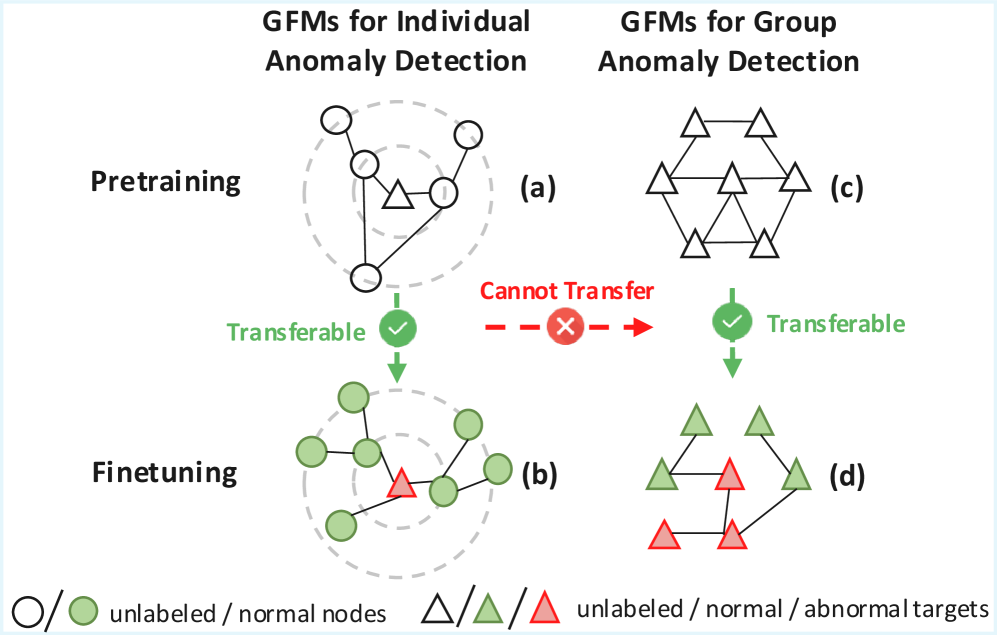
Предварительное обучение модели GFM4GA на обширных графовых корпусах и последующее применение специализированных методов обучения, таких как контрастивное обучение на уровне узлов и подграфов, позволяют ей эффективно обобщать полученные знания на ранее не встречавшиеся аномалии. Это достигается за счет формирования устойчивых представлений графов и способности выявлять отклонения от нормального поведения даже при ограниченном количестве размеченных данных, что особенно важно в сценариях обучения с небольшим числом примеров (few-shot learning). Такой подход позволяет модели адаптироваться к новым, неизвестным аномалиям без необходимости повторного обучения на большом количестве данных.
Строгая валидация на разнообразных графовых наборах данных
Для всесторонней оценки GFM4GA использовался широкий спектр графовых наборов данных, охватывающих различные области. Включены данные из социальных сетей, такие как Weixin, Weibo и Facebook, представляющие связи между пользователями. Также были использованы сети совместных обзоров Amazon, отражающие взаимосвязи между пользователями и продуктами, и сети транзакций T-Finance, моделирующие финансовые операции. Такое разнообразие данных позволило оценить общую применимость и надежность GFM4GA в различных сценариях.
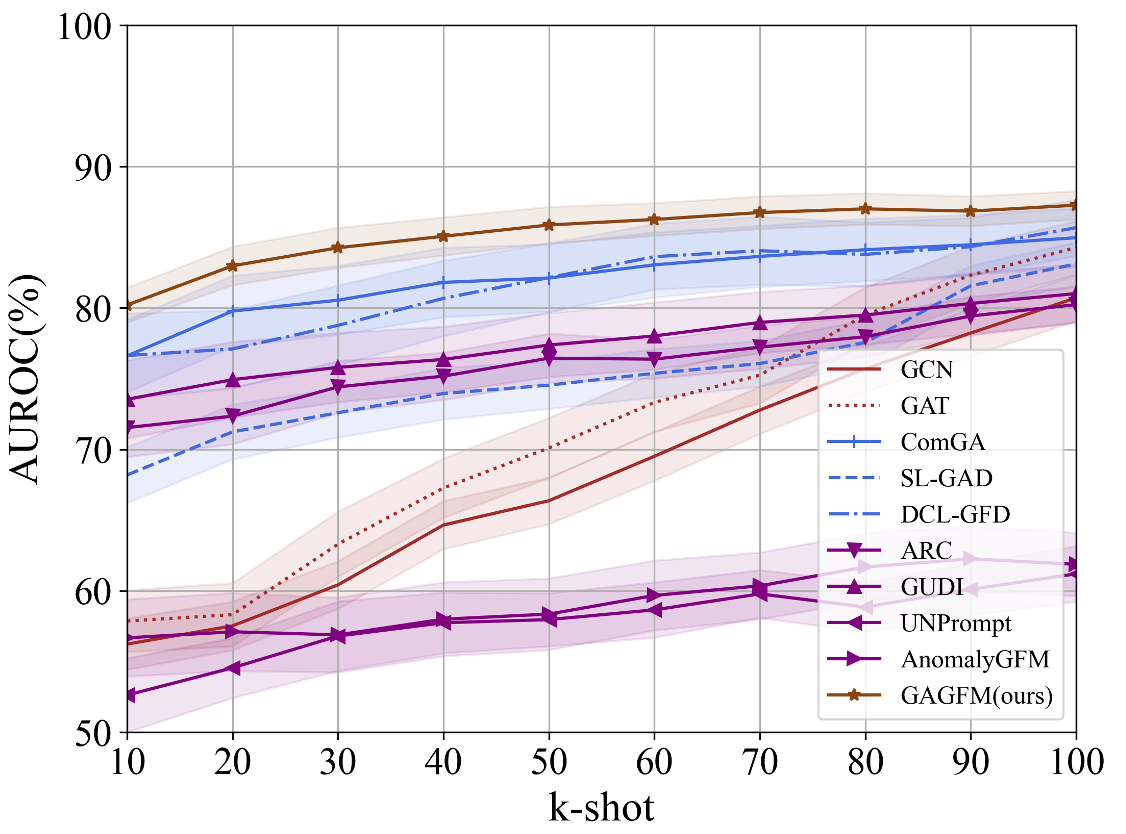
Для оценки производительности GFM4GA использовались стандартные метрики обнаружения аномалий: площадь под ROC-кривой (AUROC) и площадь под кривой точности-полноты (AUPRC). AUROC измеряет способность модели различать аномальные и нормальные узлы, в то время как AUPRC особенно важна при несбалансированных данных, где количество аномальных узлов значительно меньше нормальных. Обе метрики позволяют количественно оценить эффективность алгоритма в выявлении аномалий и сравнивать его с другими методами обнаружения аномалий в графах.
В ходе всестороннего тестирования GFM4GA продемонстрировал превосходство над существующими передовыми методами обнаружения аномалий в графах. Среднее улучшение показателя AUROC (Area Under the Receiver Operating Characteristic curve) составило 2.85%, а среднего улучшения AUPRC (Area Under the Precision-Recall Curve) — 2.55% по всем протестированным наборам данных, включающим социальные сети (Weixin, Weibo, Facebook), сети совместных обзоров (Amazon) и сети транзакций (T-Finance). Данные результаты подтверждают эффективность предложенного подхода и указывают на его потенциал для практического применения.
Полученные результаты подтверждают эффективность предложенного подхода GFM4GA для обнаружения аномалий в графовых данных. Достигнутое среднее улучшение в 2.85% по метрике AUROC и 2.55% по метрике AUPRC на разнородных графовых наборах данных, включающих социальные сети, сети совместных обзоров и транзакционные сети, указывает на применимость данного метода в различных реальных задачах, таких как выявление мошеннических операций, обнаружение ботов в социальных сетях и анализ сетевых угроз.
К надёжному и адаптивному обнаружению аномалий
Архитектура базовой модели GFM4GA обеспечивает быструю адаптацию к новым областям графовых данных и задачам, требуя минимальной тонкой настройки. В отличие от традиционных подходов, требующих обширного обучения для каждой новой задачи, GFM4GA использует предварительно обученные представления, которые можно эффективно перенести на ранее невидимые графы. Это достигается благодаря тщательно спроектированной структуре модели, позволяющей извлекать общие признаки из различных графовых структур. Такая гибкость значительно сокращает время и вычислительные ресурсы, необходимые для развертывания системы обнаружения аномалий в новых доменах, делая GFM4GA особенно ценным инструментом в динамичных и постоянно меняющихся средах, где быстрая адаптация к новым данным имеет решающее значение.
В основе GFM4GA лежит механизм контрастивного обучения, значительно повышающий способность модели выявлять тонкие аномалии в группах данных. Этот подход позволяет системе не просто идентифицировать отклонения от нормы, но и различать незначительные, едва заметные изменения, которые могут сигнализировать о потенциальных проблемах. Благодаря контрастивному обучению, модель учится формировать более четкие представления о нормальном поведении, что существенно снижает количество ложных срабатываний и повышает точность обнаружения аномалий. Использование контрастивного обучения позволяет GFM4GA эффективно отделять истинные аномалии от шума, обеспечивая более надежную и точную работу в сложных и динамичных средах.
Неустойчивость распределений данных является характерной чертой реальных сценариев, где условия постоянно меняются. Именно поэтому адаптивность и надежность системы обнаружения аномалий приобретают первостепенное значение. В динамичных сетях, таких как финансовые рынки, системы кибербезопасности или инфраструктура критического значения, статические модели быстро теряют свою эффективность, поскольку новые типы аномалий, ранее не встречавшиеся в обучающей выборке, становятся все более распространенными. Способность модели гибко приспосабливаться к изменяющимся условиям и сохранять высокую точность обнаружения, минимизируя ложные срабатывания, является ключевым фактором для обеспечения надежной и эффективной защиты от возникающих угроз и поддержания стабильности систем в условиях неопределенности.
Архитектура GFM4GA открывает перспективы для создания систем проактивного обнаружения аномалий, способных защищать критически важную инфраструктуру и предотвращать возникновение новых угроз. В отличие от реактивных систем, реагирующих уже на произошедшие инциденты, GFM4GA позволяет предвидеть потенциальные проблемы, анализируя динамически меняющиеся данные и выявляя отклонения от нормального поведения до того, как они приведут к серьезным последствиям. Такой подход особенно важен для защиты сложных систем, таких как энергосети, транспортные системы и финансовые рынки, где даже незначительные сбои могут иметь катастрофические последствия. Благодаря способности быстро адаптироваться к новым данным и задачам, GFM4GA позволяет создавать самообучающиеся системы, постоянно совершенствующие свои алгоритмы обнаружения аномалий и повышающие надежность защиты от возникающих угроз.
Исследование демонстрирует, что даже самые элегантные теоретические построения, такие как предложенная модель GFM4GA для обнаружения аномалий в графах, неизбежно сталкиваются с суровой реальностью практической реализации. Авторы стремятся к обобщению, к созданию фундаментальной модели, способной адаптироваться к различным сценариям обнаружения аномальных групп, используя контрастивное обучение и контекстную информацию. Однако, как показывает опыт, любое обобщение — это компромисс, и рано или поздно найдется краевой случай, который потребует дополнительной доработки. Как заметил Бертран Рассел: «Всё, что оптимизировано, рано или поздно оптимизируют обратно». Эта фраза особенно точно отражает суть работы с графовыми данными — постоянной борьбы за баланс между обобщением и детализацией, между теорией и практикой.
Что дальше?
Представленная работа, несомненно, добавляет ещё один слой сложности в и без того перегруженную область обнаружения аномалий в графах. Очевидно, что идея использования «фундаментальных моделей» (сейчас это назовут AI и получат инвестиции) для выявления аномальных групп выглядит привлекательно. Однако, как показывает практика, элегантная теория быстро сталкивается с суровой реальностью: каждый новый алгоритм — это просто новая форма технического долга, который когда-нибудь придётся выплачивать. Вопрос в том, насколько быстро «контекст», который они так старательно моделируют, устареет, и потребуется переобучение всей этой сложной конструкции.
Очевидная проблема — масштабируемость. Вся эта контрастивная магия, безусловно, требует значительных вычислительных ресурсов. Когда данные вырастут на порядок, аномалии начнут проявляться в неожиданных местах, и «простые bash-скрипты» окажутся быстрее и надежнее. Нельзя забывать, что в конечном итоге, все эти «контекстуальные представления» сводятся к набору чисел, которые кто-то должен интерпретировать. А интерпретировать их правильно становится все сложнее.
Начинаешь подозревать, что большая часть усилий направлена на решение проблем, которые на самом деле не существуют. Вместо того чтобы гоняться за «фундаментальными моделями», возможно, стоит вернуться к основам и подумать о более простых, надежных и объяснимых подходах. Иначе, через пару лет документация снова соврет, а «красивый алгоритм» окажется бесполезен в реальном мире.
Оригинал статьи: https://arxiv.org/pdf/2601.10193.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- OM/USD
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- Золото прогноз
2026-01-16 14:05