Автор: Денис Аветисян
Новый подход к обнаружению финансовых преступлений позволяет объединить данные из разных источников, не раскрывая конфиденциальную информацию.
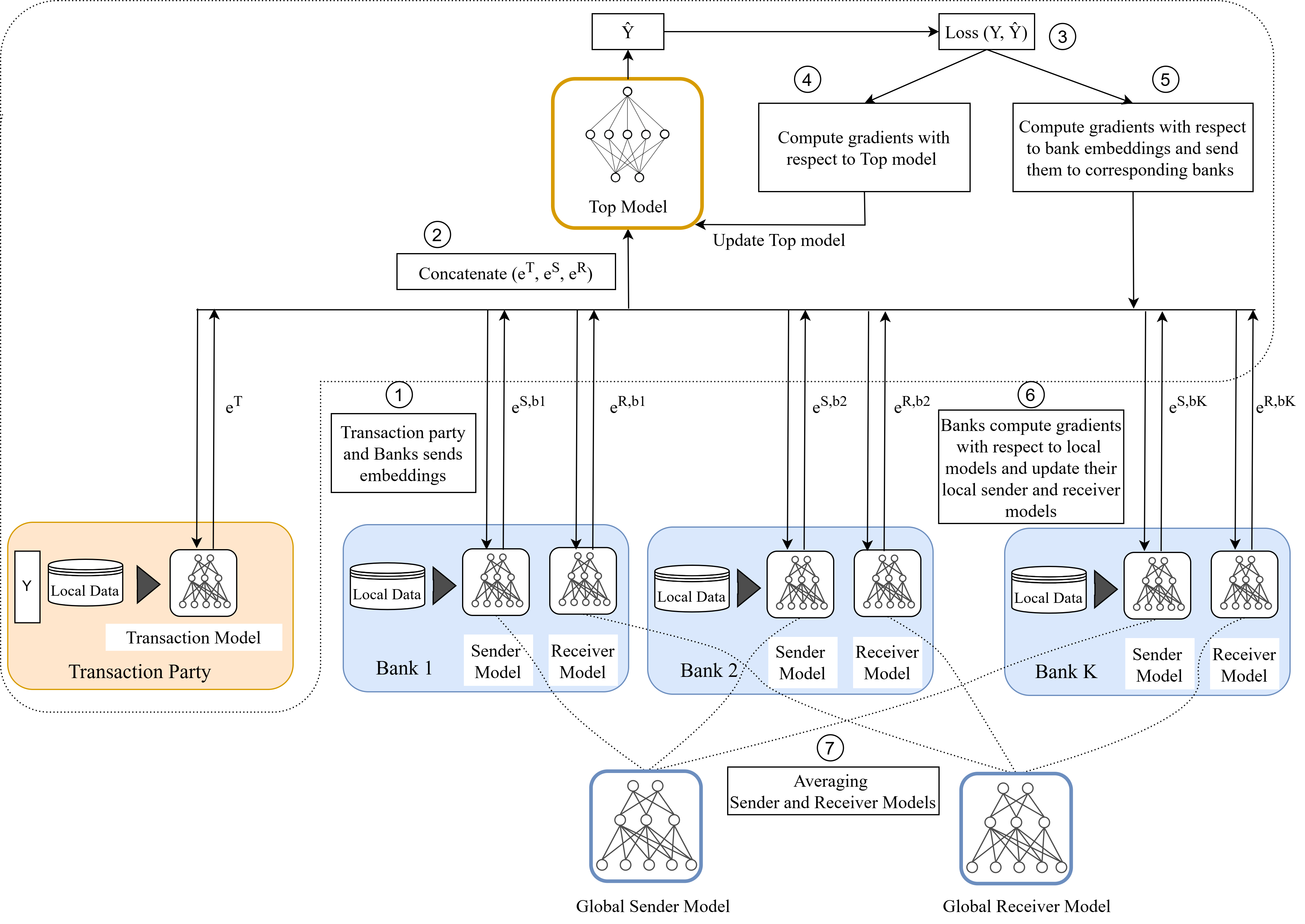
Предложена гибридная методика федеративного обучения для совместной тренировки моделей обнаружения финансовых преступлений с сохранением приватности данных.
Современные подходы к машинному обучению часто требуют централизованного доступа к данным, что вызывает опасения по поводу конфиденциальности и безопасности. В данной работе представлена методология ‘HybridFL: A Federated Learning Approach for Financial Crime Detection’ — гибридное федеративное обучение, позволяющее совместно обучать модели на распределенных данных различных учреждений без обмена самими данными. Предложенная архитектура эффективно объединяет горизонтальное и вертикальное разделение данных, значительно превосходя локальные модели и приближаясь по эффективности к централизованному обучению в контексте выявления финансовых преступлений. Возможно ли дальнейшее расширение возможностей федеративного обучения для решения более сложных задач анализа данных в финансовом секторе и за его пределами?
Разрозненность Данных: Препятствие на Пути к Финансовой Безопасности
Раздробленность данных между финансовыми институтами существенно затрудняет выявление преступной деятельности в финансовой сфере. Отсутствие единой картины транзакций и взаимосвязей между ними создает “слепые зоны”, позволяющие преступникам успешно скрывать свои операции и перемещать незаконные средства. Каждый банк или финансовая организация обладает лишь фрагментарной информацией, что препятствует комплексному анализу и своевременному обнаружению подозрительной активности. Эта проблема особенно актуальна в условиях возрастающей сложности финансовых потоков и развития новых схем мошенничества, требующих более эффективных механизмов для обнаружения и предотвращения финансовых преступлений.
Традиционные подходы к выявлению финансовой преступности, основанные на централизованном сборе и анализе данных, всё чаще сталкиваются с непреодолимыми препятствиями. Ограничения, связанные с защитой персональных данных и строгими нормативными требованиями, такими как GDPR и другие локальные законодательства, делают невозможным создание единых баз данных, охватывающих информацию из различных финансовых институтов. Попытки централизовать данные часто приводят к юридическим сложностям, высоким затратам на обеспечение соответствия требованиям и, как следствие, к существенному замедлению процесса выявления подозрительных операций. В результате, даже при наличии потенциально ценной информации, её использование для борьбы с финансовыми преступлениями оказывается затруднено или вовсе недоступно, что подрывает эффективность существующих систем безопасности.
Появляется новая парадигма обнаружения финансовых преступлений, основанная на совместном обучении без непосредственного обмена данными. Вместо централизованного хранения информации, данный подход позволяет различным финансовым учреждениям совместно анализировать данные, сохраняя при этом конфиденциальность и соблюдая нормативные требования. Используя такие методы, как федеративное обучение и конфиденциальные вычисления, алгоритмы могут обучаться на распределенных наборах данных, выявляя скрытые закономерности и связи, которые были бы невидимы при анализе изолированных источников. Это позволяет значительно расширить возможности обнаружения мошеннических операций и отмывания денег, обеспечивая более надежную защиту финансовой системы.
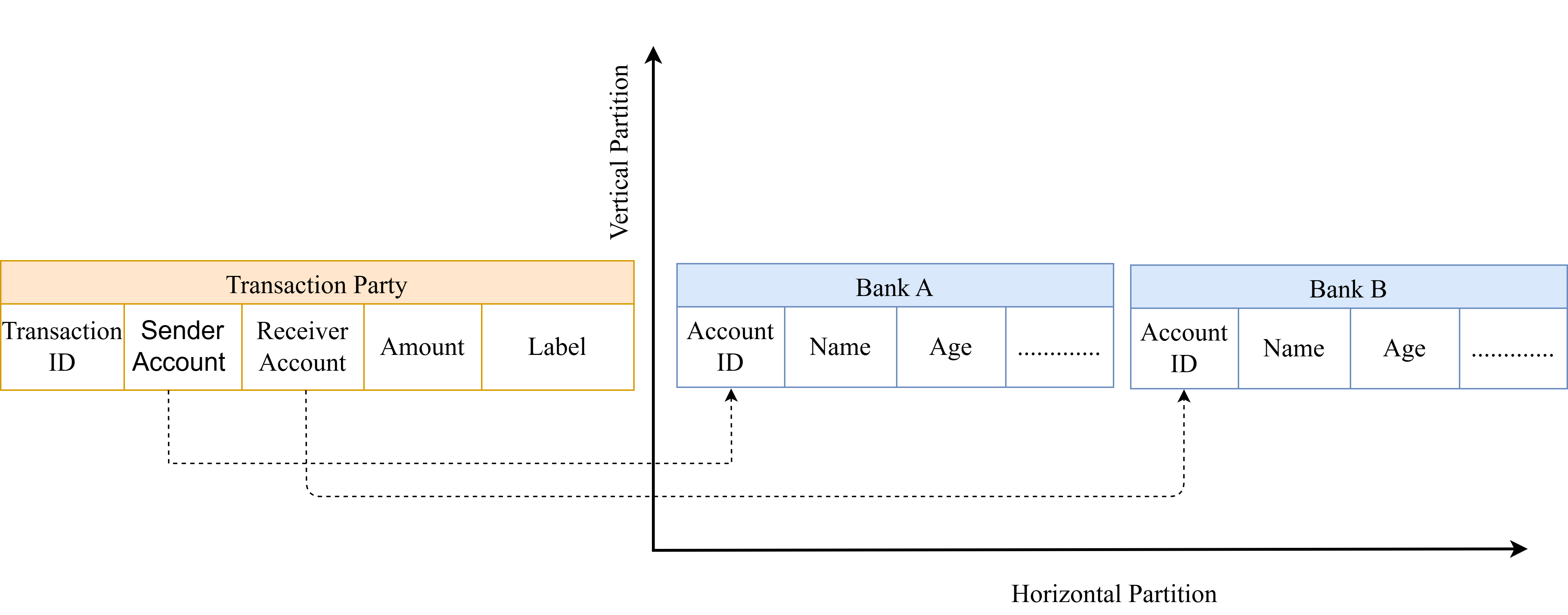
Федеративное Обучение: Совместная Работа без Компромиссов
Федеративное обучение (FL) представляет собой подход к построению моделей машинного обучения, при котором обучение происходит на децентрализованных устройствах или серверах, содержащих локальные наборы данных. Ключевой особенностью является то, что необработанные данные остаются на устройствах и не передаются центральному серверу. Вместо этого, локальные модели обучаются на каждом устройстве, а затем обмениваются только обновлениями моделей (например, градиентами или весами). Эти обновления агрегируются центральным сервером для создания глобальной модели, которая затем распространяется обратно на устройства. Такой подход обеспечивает конфиденциальность данных и снижает потребность в передаче больших объемов информации, что особенно важно в сценариях, связанных с чувствительными данными или ограниченной пропускной способностью сети.
Горизонтальное федеративное обучение (Horizontal Federated Learning) наиболее эффективно в ситуациях, когда наборы данных различных участников имеют одинаковый набор признаков, но различаются по набору примеров (например, разные больницы, собирающие данные об одних и тех же показателях у разных пациентов). В противоположность этому, вертикальное федеративное обучение (Vertical Federated Learning) подходит для сценариев, где участники обладают разными признаками, но общими примерами (например, банк и платформа электронной коммерции, имеющие информацию об одних и тех же пользователях, но разные данные о них).
Гибридное федеративное обучение (Hybrid Federated Learning) представляет собой комбинацию горизонтального и вертикального подходов, позволяющую реализовать более сложные сценарии совместной работы с данными. В отличие от чисто горизонтального или вертикального FL, гибридный подход позволяет объединять преимущества обоих методов, обрабатывая данные, различающиеся как по признакам, так и по выборкам. Это достигается путем последовательного или параллельного применения горизонтального и вертикального FL, что позволяет организациям сотрудничать даже при значительном различии в структуре и составе их данных. Например, одна организация может использовать горизонтальное FL для обучения модели на схожих данных пользователей, а затем использовать вертикальное FL для интеграции этих данных с информацией, имеющейся у другой организации, с различными признаками, но общими пользователями, тем самым улучшая общую точность и эффективность модели.
Повышение Безопасности и Приватности в Федеративных Системах
Безопасная агрегация (Secure Aggregation) представляет собой криптографический метод, обеспечивающий конфиденциальность обновлений моделей в федеративном обучении. В рамках данного подхода, каждый участник локально вычисляет градиенты на своих данных и шифрует их перед отправкой центральному серверу. Сервер агрегирует зашифрованные градиенты, не имея доступа к индивидуальным данным участников. Дешифровка агрегированного результата возможна только при наличии ключей от большинства участников, что гарантирует, что информация об отдельных данных не раскрывается. Этот процесс предотвращает утечку конфиденциальной информации, сохраняя при этом возможность эффективного обучения модели на распределенных данных.
Дифференциальная конфиденциальность (Differential Privacy) представляет собой метод защиты приватности данных, заключающийся в добавлении контролируемого шума к результатам запросов или вычислений. Этот шум маскирует вклад отдельных данных, предотвращая выявление информации об конкретных участниках набора данных. Уровень добавляемого шума регулируется параметром ε (эпсилон), определяющим баланс между полезностью данных и уровнем защиты конфиденциальности — чем меньше ε, тем выше защита, но ниже точность результатов. Метод гарантирует, что изменение или удаление отдельных записей из набора данных незначительно влияет на результат запроса, тем самым затрудняя идентификацию или вывод информации об отдельных лицах.
Интеграция методов безопасной агрегации и дифференциальной приватности с гибридным федеративным обучением позволяет создать надежную систему обнаружения финансовых преступлений, обеспечивающую защиту конфиденциальности данных. Безопасная агрегация гарантирует, что сервер, собирающий обновления модели от участников, не сможет восстановить индивидуальные данные, в то время как дифференциальная приватность добавляет контролируемый шум к этим обновлениям, еще больше снижая риск идентификации конкретных транзакций или пользователей. Гибридный подход, объединяющий централизованное и децентрализованное обучение, оптимизирует производительность модели при сохранении высокого уровня защиты данных, что особенно важно для чувствительной финансовой информации и соответствия нормативным требованиям.
Моделирование Транзакционного Поведения для Улучшенного Обнаружения
Для более точного выявления аномальной активности в финансовых транзакциях разработана модель, состоящая из трех энкодеров. Каждый энкодер анализирует данные с определенной перспективы: первый — характеристики самой транзакции, второй — поведение отправителя средств, а третий — поведение получателя. Такой подход позволяет выделить уникальные поведенческие паттерны, связанные с каждым участником и самой операцией. Разделение анализа на три компонента позволяет модели учитывать сложные взаимосвязи и более эффективно обнаруживать подозрительные действия, которые могли бы остаться незамеченными при анализе только общей информации о транзакциях. Полученные представления от каждого энкодера объединяются для формирования комплексной картины поведения, что значительно повышает точность обнаружения мошеннических операций.
Для повышения точности выявления аномальных транзакций предлагается архитектура, в которой информация, извлеченная тремя кодировщиками — анализирующими транзакцию, отправителя и получателя — объединяется в единой “Верхней Модели”. Эта модель служит для интеграции поведенческих особенностей, выявленных каждым из кодировщиков, позволяя сформировать комплексное представление о транзакции. В результате, “Верхняя Модель” способна более эффективно отличать нормальные транзакции от подозрительных, поскольку учитывает не только характеристики самой транзакции, но и профили отправителя и получателя, что значительно повышает надежность системы обнаружения мошеннических операций.
Для достижения максимальной эффективности разработанной модели, оптимизация финального слоя, получившего название “Top Model”, осуществлялась посредством алгоритма Adam — метода стохастического градиентного спуска, адаптирующего скорость обучения для каждого параметра. В процессе обучения применялись функции потерь, такие как Binary Cross-Entropy и Focal Loss, последняя из которых особенно эффективна при работе с несбалансированными данными, что характерно для задач обнаружения аномалий. Оценка качества модели проводилась на основе площади под кривой Precision-Recall (AUPRC), демонстрируя результат в 0.80 на синтетическом наборе данных AMLSim и 0.78 на реальном наборе данных SWIFT, что подтверждает высокую точность и надежность предложенного подхода к выявлению подозрительных транзакций.
Реалистичная Генерация Данных и Перспективы Развития
Разработанная платформа AMLSim представляет собой мощный инструмент для генерации синтетических данных банковских транзакций, что позволяет значительно улучшить процесс обучения и оценки моделей машинного обучения. В отличие от использования реальных данных, которые часто ограничены по объему и могут содержать чувствительную информацию, AMLSim обеспечивает создание неограниченного количества разнообразных сценариев транзакций, имитирующих реальное поведение клиентов. Это особенно важно для задач обнаружения отмывания денег (AML), где модели должны быть обучены на большом количестве разнообразных примеров, чтобы эффективно выявлять подозрительные операции. Благодаря возможности контролируемого создания данных, исследователи и разработчики могут тщательно тестировать и оптимизировать алгоритмы, выявляя слабые места и повышая их устойчивость к различным видам мошенничества, что, в конечном итоге, способствует повышению эффективности систем финансовой безопасности.
Созданная симуляционная среда предоставляет уникальную возможность для всестороннего тестирования и усовершенствования всего конвейера гибридного федеративного обучения. Благодаря ей, исследователи могут контролируемо изменять различные параметры — объемы данных, характеристики участников, сетевые условия — и оценивать влияние этих изменений на производительность и устойчивость системы. Это позволяет выявлять узкие места и оптимизировать алгоритмы обучения, не прибегая к использованию реальных, конфиденциальных банковских данных. Таким образом, AMLSim выступает в качестве безопасной и эффективной платформы для разработки и отладки сложных систем федеративного обучения, значительно ускоряя процесс внедрения инновационных решений в финансовом секторе.
Предложенный гибридный алгоритм федеративного обучения демонстрирует производительность, находящуюся между централизованной моделью и моделью, обученной исключительно на данных активной стороны. Это свидетельствует об эффективном обучении на распределенных данных, разделенных как горизонтально, так и вертикально. Дальнейшие исследования направлены на масштабирование данного подхода для работы с более крупными и сложными наборами данных, а также на изучение передовых технологий, повышающих конфиденциальность. Особое внимание уделяется совершенствованию алгоритмов для защиты информации при сохранении высокой точности и эффективности обучения в условиях распределенных вычислений. Такой подход позволит создавать более надежные и безопасные системы машинного обучения для финансовых учреждений и других областей, где конфиденциальность данных является приоритетом.
Исследование, представленное в статье, демонстрирует стремление к преодолению ограничений традиционных подходов к обнаружению финансовых преступлений. Авторы предлагают гибридный подход к федеративному обучению, позволяющий объединить разрозненные данные из различных источников, не нарушая при этом конфиденциальность. Этот метод, по сути, является попыткой понять и взломать систему, чтобы извлечь из неё максимальную пользу. Как однажды заметил Джон Маккарти: «Всякий, кто изобретает, должен быть немного сумасшедшим». Эта фраза отражает дух исследования — смелость в поиске новых решений и готовность бросить вызов существующим нормам. В данном случае, речь идет о взломе системы защиты данных, чтобы сделать её более эффективной в борьбе с финансовой преступностью, сохраняя при этом приватность.
Что дальше?
Предложенный подход, безусловно, открывает двери для коллективного обучения моделей обнаружения финансовых преступлений, не жертвуя при этом конфиденциальностью данных. Однако, следует признать, что сама идея «федеративного обучения» — это лишь обход ограничений, а не их преодоление. Фрагментация данных остаётся проблемой, и эффективность метода напрямую зависит от качества и репрезентативности этих фрагментов у каждого участника. Вопрос о том, как гарантировать сопоставимость данных, собранных разными институтами с разными политиками и подходами, остается открытым.
Более того, за кажущейся безопасностью скрывается сложная игра с агрегацией моделей. Методы безопасных многосторонних вычислений (Secure Multi-Party Computation) — это элегантное решение, но они не лишены вычислительных издержек. Необходимо искать компромисс между уровнем защиты и производительностью, особенно при работе с большими объемами данных и сложными моделями. Следующим шагом видится разработка более адаптивных алгоритмов агрегации, учитывающих специфику данных каждого участника и минимизирующих потери информации.
В конечном счете, данное исследование — это лишь первый шаг на пути к созданию действительно децентрализованной и устойчивой системы обнаружения финансовых преступлений. Истинный прогресс потребует не только совершенствования технических аспектов, но и переосмысления самой концепции доверия и сотрудничества между финансовыми институтами. Возможно, будущее за системами, где данные никогда не покидают пределы организации, а модели обучаются непосредственно на этих данных, обмениваясь лишь знаниями, а не информацией.
Оригинал статьи: https://arxiv.org/pdf/2602.19207.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-02-25 05:04