Автор: Денис Аветисян
В новой работе представлена методика оценки стабильности наборов данных для классификации сетевого трафика, позволяющая вовремя обнаруживать изменения и поддерживать высокую точность моделей.
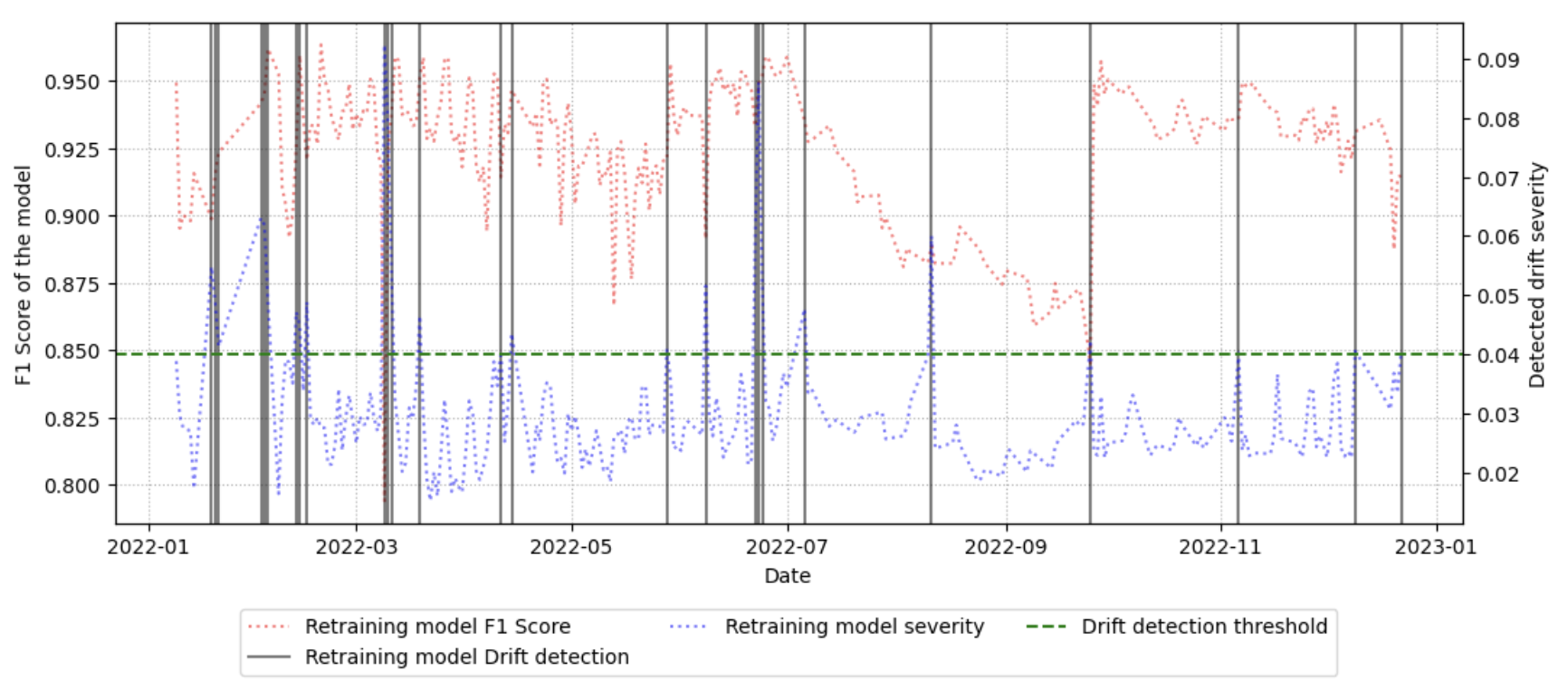
Предложенный подход использует метод MFWDD для выявления дрифта с учетом важности признаков, оптимизируя процесс переобучения моделей машинного обучения.
Несмотря на эффективность машинного обучения в классификации сетевого трафика, быстрое устаревание данных и эволюция сетевых протоколов приводят к снижению точности моделей. В работе, озаглавленной ‘Drift-Based Dataset Stability Benchmark’, предложен новый подход к оценке стабильности наборов данных, использующий метод обнаружения концептуального дрифта, усиленный анализом важности признаков. Данный фреймворк позволяет выявлять слабые места в данных и оптимизировать процесс переобучения моделей, поддерживая их актуальность. Возможно ли, с помощью предложенной методологии, создать самоподстраивающиеся системы классификации сетевого трафика, способные адаптироваться к постоянно меняющимся условиям?
Эволюция Проблем Классификации Сетевого Трафика
Традиционные методы классификации сетевого трафика, основанные на глубоком анализе пакетов данных (Deep Packet Inspection, DPI), сталкиваются со всё возрастающими трудностями. Широкое распространение технологий шифрования, таких как Encrypted Server Name Indication (ESNI), эффективно скрывает содержимое пакетов, делая DPI неэффективным инструментом для идентификации приложений и сервисов. В результате, анализ полезной нагрузки пакетов становится всё менее информативным, а классификация трафика — всё более сложной задачей. Это требует разработки новых подходов, способных обходить ограничения, накладываемые современными протоколами шифрования, и обеспечивать точную идентификацию сетевых приложений даже при отсутствии доступа к содержимому пакетов.
В связи с повсеместным распространением шифрования, такого как ESNI, традиционные методы классификации сетевого трафика, основанные на глубоком анализе пакетов, теряют свою эффективность. В результате, наблюдается переход к методам косвенного анализа, которые фокусируются на метаданных — информации о трафике, такой как временные метки, размеры пакетов и характеристики потока, а не на его содержимом. Такой подход позволяет идентифицировать приложения и сервисы, даже если данные зашифрованы, обеспечивая сохранение видимости сетевой активности и возможность эффективного управления трафиком. Исследования в этой области направлены на разработку алгоритмов, способных извлекать полезную информацию из метаданных и адаптироваться к постоянно меняющимся характеристикам сетевого трафика.
Современные сети характеризуются постоянно растущей сложностью трафика, обусловленной увеличением числа устройств, разнообразием приложений и новыми сетевыми протоколами. Это предъявляет повышенные требования к техникам классификации сетевого трафика, которым необходимо не только распознавать известные типы соединений, но и адаптироваться к постоянно появляющимся новым. Традиционные методы, основанные на статичных сигнатурах, оказываются неэффективными в условиях динамически меняющегося ландшафта угроз и приложений. В связи с этим, разрабатываются более гибкие и интеллектуальные подходы, использующие методы машинного обучения и анализа больших данных для выявления аномалий и паттернов в сетевом трафике, что позволяет более точно и эффективно классифицировать соединения и обеспечивать безопасность сети. Подобные техники способны оперативно реагировать на новые типы трафика и адаптироваться к изменяющимся условиям, обеспечивая надежную защиту от современных сетевых угроз.

Машинное Обучение для Адаптивной Классификации
Классификаторы машинного обучения (ML) предоставляют эффективный подход к классификации сетевого трафика, позволяя автоматизировать и адаптировать анализ в реальном времени. В отличие от традиционных методов, основанных на сигнатурах или эвристиках, ML-классификаторы способны выявлять закономерности в данных, не требуя предварительного определения правил. Они обучаются на размеченных данных о сетевом трафике и, используя алгоритмы, такие как деревья решений, случайные леса или нейронные сети, классифицируют новые пакеты данных на основе выявленных признаков. Это позволяет автоматически идентифицировать приложения, типы трафика или потенциальные угрозы, значительно снижая нагрузку на администраторов сети и повышая эффективность мониторинга.
Производительность классификаторов машинного обучения, используемых для анализа сетевого трафика, подвержена влиянию явления, известного как «смещение данных» (data drift). Это происходит, когда статистические свойства данных, на которых был обучен классификатор, изменяются со временем. Например, изменение преобладающих сетевых протоколов, появление новых приложений или изменение поведения пользователей могут привести к отклонению текущего трафика от исходного распределения данных обучения. В результате, точность классификатора снижается, увеличивается количество ложных срабатываний и пропущенных событий, что негативно влияет на эффективность анализа и защиты сети.
Для поддержания эффективности моделей машинного обучения в условиях изменяющегося сетевого трафика необходим непрерывный мониторинг и адаптация. Это включает в себя регулярную оценку производительности модели с использованием актуальных данных, а также автоматическую перетренировку или обновление модели при обнаружении значительного ухудшения точности классификации. Методы адаптации включают в себя инкрементное обучение, где модель обновляется небольшими порциями новых данных, и стратегии активного обучения, при которых модель запрашивает маркировку наиболее информативных примеров для улучшения своей производительности. Важно также отслеживать статистические характеристики трафика для выявления изменений в распределении признаков, что может служить индикатором дрифта данных и необходимости адаптации модели.

Обнаружение Тонких Сдвигов с Анализом Весов Признаков
Метод обнаружения смещения данных на основе весов признаков в моделях (MFWDD) представляет собой новый подход к выявлению изменений в распределении входных данных. В отличие от традиционных методов, которые анализируют данные напрямую, MFWDD отслеживает изменения весов, присваиваемых отдельным признакам внутри обученной модели машинного обучения. Предполагается, что значительные изменения в этих весах указывают на смещение данных, поскольку модель адаптируется к новым, отличающимся данным. Этот подход позволяет выявлять даже незначительные смещения, которые могут быть незаметны при прямом анализе данных, и особенно полезен в сценариях, где доступ к исходным данным ограничен или невозможен.
Метод обнаружения смещения данных на основе весов признаков (MFWDD) использует ряд статистических тестов для количественной оценки различий в распределениях данных. Тест Колмогорова-Смирнова (KS-тест) определяет, различаются ли два эмпирических распределения. Расстояние Вассерштейна (также известное как расстояние Землеройки) измеряет расстояние между двумя вероятностными распределениями, минимизируя работу, необходимую для преобразования одного распределения в другое. Максимальное расхождение средних (MMD) оценивает разницу между распределениями в пространстве признаков, используя ядра. Тест Пейджа-Хинкли (PHT) предназначен для обнаружения небольших, но устойчивых изменений в среднем значении временного ряда или последовательности данных, позволяя выявлять постепенное смещение данных.
Эффективность метода обнаружения сдвига данных на основе весов признаков (MFWDD) напрямую зависит от точной оценки значимости каждого признака для модели. Некорректная оценка важности признаков может привести к ложноположительным или ложноотрицательным результатам при определении сдвига. Для обеспечения надежности необходимо внедрить строгий оценочный процесс, включающий создание эталонного набора данных и периодическое сравнение с текущими данными с использованием статистических метрик, таких как тест Колмогорова-Смирнова, расстояние Вассерштейна, максимальное расхождение средних (MMD) и тест Пейджа-Хинкли (PHT). Этот процесс позволяет установить базовый уровень стабильности данных и выявлять даже незначительные отклонения, указывающие на потенциальный сдвиг в распределении признаков.
Бенчмаркинг Стабильности с Реальным Трафиком
Набор данных CESNET-TLS-Year22 представляет собой долгосрочный источник реального сетевого трафика, предназначенный для оценки стабильности моделей машинного обучения и тестирования методов обнаружения дрифта данных. Данный набор включает в себя записи сетевого трафика, собранные в течение длительного периода времени, что позволяет анализировать изменения в характеристиках трафика и оценивать, насколько хорошо модели сохраняют свою точность с течением времени. Использование реальных данных, в отличие от синтетических, обеспечивает более реалистичную оценку производительности алгоритмов обнаружения дрифта и позволяет выявить потенциальные проблемы, возникающие в реальных сетевых средах. Набор данных доступен для использования исследовательским сообществом с целью разработки и совершенствования методов поддержания стабильности моделей в условиях изменяющегося сетевого трафика.
Для выявления изменений в сетевом трафике и оценки эффективности MFWDD (метода обнаружения дрифта) в наборе данных CESNET-TLS-Year22 применяются алгоритмы машинного обучения XGBoost и K-Medoids. XGBoost, благодаря своей способности к градиентному бустингу, позволяет строить точные модели для классификации и прогнозирования трафика, выявляя аномалии и отклонения от нормального поведения. K-Medoids, как алгоритм кластеризации, способен группировать схожие типы трафика, позволяя обнаруживать изменения в структуре данных и выделять новые кластеры, указывающие на дрифт. Комбинированное использование этих алгоритмов обеспечивает комплексный анализ данных и позволяет количественно оценить стабильность модели и эффективность MFWDD в реальных условиях.
Применение предложенного рабочего процесса позволило добиться повышения стабильности модели на 5%, что подтверждается достигнутым значением F1-меры в 91% после разделения набора данных с учетом поведения дрифта. В ходе анализа было выявлено 53 события дрифта после разделения классов. Данный результат демонстрирует эффективность предложенного подхода к обнаружению и смягчению последствий дрифта данных, что приводит к улучшению производительности модели в динамически меняющейся среде.
К Устойчивой Обнаружению Сетевых Вторжений
Методы проактивного обнаружения и смягчения дрейфа данных, такие как MFWDD, значительно повышают надежность систем обнаружения вторжений в сеть (NIDS). Поскольку сетевой трафик постоянно эволюционирует, изменяются и характеристики нормальной и вредоносной активности. Если NIDS не адаптируется к этим изменениям, его способность точно классифицировать трафик снижается, что приводит к увеличению числа ложных срабатываний и пропущенных атак. MFWDD, отслеживая статистические изменения в данных, позволяет NIDS поддерживать высокую точность даже в условиях изменяющейся сетевой среды. Это достигается за счет непрерывного мониторинга распределения признаков сетевого трафика и автоматической корректировки моделей обнаружения вторжений при обнаружении значительных отклонений, обеспечивая тем самым более стабильную и эффективную защиту сети.
Повышенная точность классификации сетевого трафика играет ключевую роль в современной защите от киберугроз. Улучшенные алгоритмы позволяют более эффективно выявлять вредоносную активность, отделяя её от легитимного трафика, что значительно сокращает время реагирования на инциденты. Вместо того чтобы полагаться на общие сигнатуры атак, точная классификация позволяет идентифицировать аномалии в поведении сети, даже если атака использует новые или замаскированные методы. Это особенно важно в условиях быстро меняющейся киберсреды, где злоумышленники постоянно совершенствуют свои тактики. В результате, системы обнаружения вторжений (IDS) становятся более проактивными и способными оперативно нейтрализовать угрозы, минимизируя потенциальный ущерб.
Современные системы обнаружения вторжений в сети (NIDS) подвержены влиянию дрейфа данных, что снижает их эффективность со временем. Для повышения устойчивости к этому явлению применяются передовые методы обнаружения дрейфа, использующие надежные наборы данных, такие как CESNET-TLS-Year22. Исследования показали, что применение взвешенного подхода, учитывающего важность признаков, значительно улучшает чувствительность обнаружения дрифта. В частности, удалось добиться показателя чувствительности в диапазоне от 0% до 15%, что является существенным улучшением по сравнению с 1%-40% без использования взвешивания. Это демонстрирует, что комбинация современных техник и качественных данных позволяет существенно укрепить общую безопасность сетевой инфраструктуры и обеспечить более надежную защиту от постоянно меняющихся угроз.
Исследование демонстрирует, что стабильность наборов данных сетевого трафика — критически важный аспект поддержания точности моделей машинного обучения. Предложенный подход, основанный на обнаружении отклонений (MFWDD) и учете важности признаков, позволяет оптимизировать процесс переобучения моделей и минимизировать влияние концептуального дрифта. Как заметил Блез Паскаль: «Все проблемы человечества происходят от того, что люди не умеют спокойно сидеть в комнате». В контексте данного исследования, эта фраза иллюстрирует необходимость постоянного мониторинга и адаптации к изменяющимся условиям сетевого трафика, поскольку «покой» в стабильности данных — иллюзия, требующая непрерывного анализа и коррекции.
Куда же дальше?
Представленная методика, оценивающая стабильность наборов данных для классификации сетевого трафика, хоть и представляет собой шаг вперед, не решает фундаментальной проблемы: сама природа концептуального дрифта остаётся скорее наблюдаемым явлением, нежели поддающимся строгому математическому описанию. Обнаружение дрифта, основанное на значимости признаков, — это, по сути, эвристика, позволяющая вовремя “подкрутить” модель, но не гарантирующая её абсолютной корректности в изменяющейся среде. Зачастую, удобство своевременной переподготовки затмевает потребность в алгоритме, способном предсказывать изменения в данных.
Будущие исследования должны сосредоточиться не только на более точных методах обнаружения дрифта, но и на разработке алгоритмов, способных к адаптации без полной переподготовки. Идея активного обучения, упомянутая в работе, перспективна, однако требует более глубокого анализа критериев выбора наиболее информативных экземпляров для разметки. В конечном счете, истинная элегантность заключается не в скорости реакции на изменения, а в способности предвидеть их, пусть даже и приблизительно.
Очевидным направлением является исследование влияния различных типов дрифта — внезапных, постепенных, периодических — на эффективность предлагаемой методики. Важно понять, какие признаки оказываются наиболее чувствительными к различным видам изменений, и как это можно использовать для более точной настройки алгоритмов обнаружения дрифта. Отказ от эмпирических оценок в пользу строгих математических доказательств — вот к чему следует стремиться.
Оригинал статьи: https://arxiv.org/pdf/2512.23762.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-05 00:06