Автор: Денис Аветисян
Новый подход к построению нейронных сетей позволяет комбинировать экспертные модели с динамическим управлением, обеспечивая баланс между производительностью и интерпретируемостью.
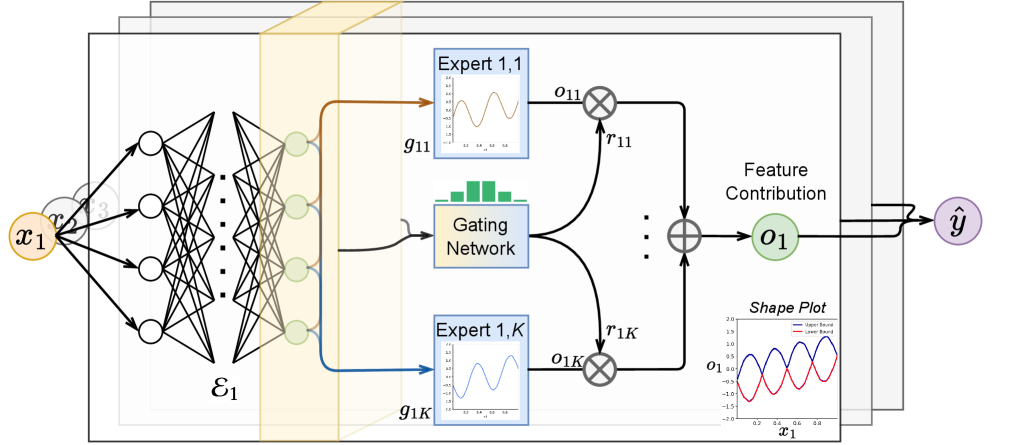
Представлена архитектура Neural Additive Experts (NAE), расширяющая аддитивные модели за счет смеси экспертов и контекстного управления для контролируемого моделирования взаимодействия признаков.
Поиск баланса между точностью и интерпретируемостью моделей машинного обучения остается сложной задачей. В данной работе, посвященной разработке ‘Neural Additive Experts: Context-Gated Experts for Controllable Model Additivity’, предложен новый подход, использующий смесь экспертов и динамическое управление потоком информации для моделирования сложных взаимодействий между признаками. Предложенная архитектура позволяет гибко настраивать степень аддитивности модели, обеспечивая прозрачность вкладов каждого признака при сохранении высокой предсказательной силы. Сможет ли данный подход стать ключевым инструментом для создания более надежных и понятных систем искусственного интеллекта?
За пределами линейных моделей: потребность в гибких взаимодействиях
Традиционные обобщенные аддитивные модели (GAM) зарекомендовали себя как инструменты, обеспечивающие высокую интерпретируемость результатов анализа данных. Однако, их способность к моделированию сложных, нелинейных взаимодействий между признаками ограничена. В то время как GAM эффективно устанавливают связь между отдельными переменными и целевым показателем, они часто не способны уловить ситуации, когда влияние одного признака на результат существенно меняется в зависимости от значений других признаков. Это ограничение снижает прогностическую силу моделей в задачах, где взаимодействие признаков играет важную роль, что требует поиска альтернативных подходов, способных более адекватно отражать реальные зависимости в данных и повышать точность прогнозов.
Несмотря на свою способность выявлять сложные взаимодействия между признаками, глубокое обучение зачастую страдает от недостатка интерпретируемости. В отличие от более прозрачных моделей, таких как обобщенные аддитивные модели, «черный ящик» глубоких нейронных сетей затрудняет понимание того, каким образом определенные признаки влияют на конечный результат. Кроме того, обучение и применение глубоких моделей требует значительных вычислительных ресурсов и больших объемов данных, что делает их непрактичными для задач с ограниченными ресурсами или небольшими датасетами. Таким образом, хотя глубокое обучение и демонстрирует высокую точность, его сложность и требовательность к ресурсам создают потребность в альтернативных подходах, способных обеспечить баланс между выразительностью и понятностью.
Существует заметный разрыв в современных методах моделирования: потребность в алгоритмах, способных одновременно эффективно улавливать сложные взаимосвязи между признаками и сохранять возможность интерпретации результатов. Традиционные обобщенные аддитивные модели (GAM) обеспечивают прозрачность, однако часто оказываются неспособными адекватно отразить нелинейные взаимодействия, ограничивая их прогностическую силу. В то же время, глубокое обучение, хоть и преуспевает в выявлении этих взаимодействий, зачастую жертвует понятностью полученных моделей, что затрудняет анализ вклада отдельных факторов. Таким образом, возникает необходимость в разработке новых подходов, сочетающих в себе выразительность сложных моделей и возможность осмысленного анализа влияния каждого признака на конечный результат, что особенно важно для принятия обоснованных решений и понимания лежащих в основе данных закономерностей.
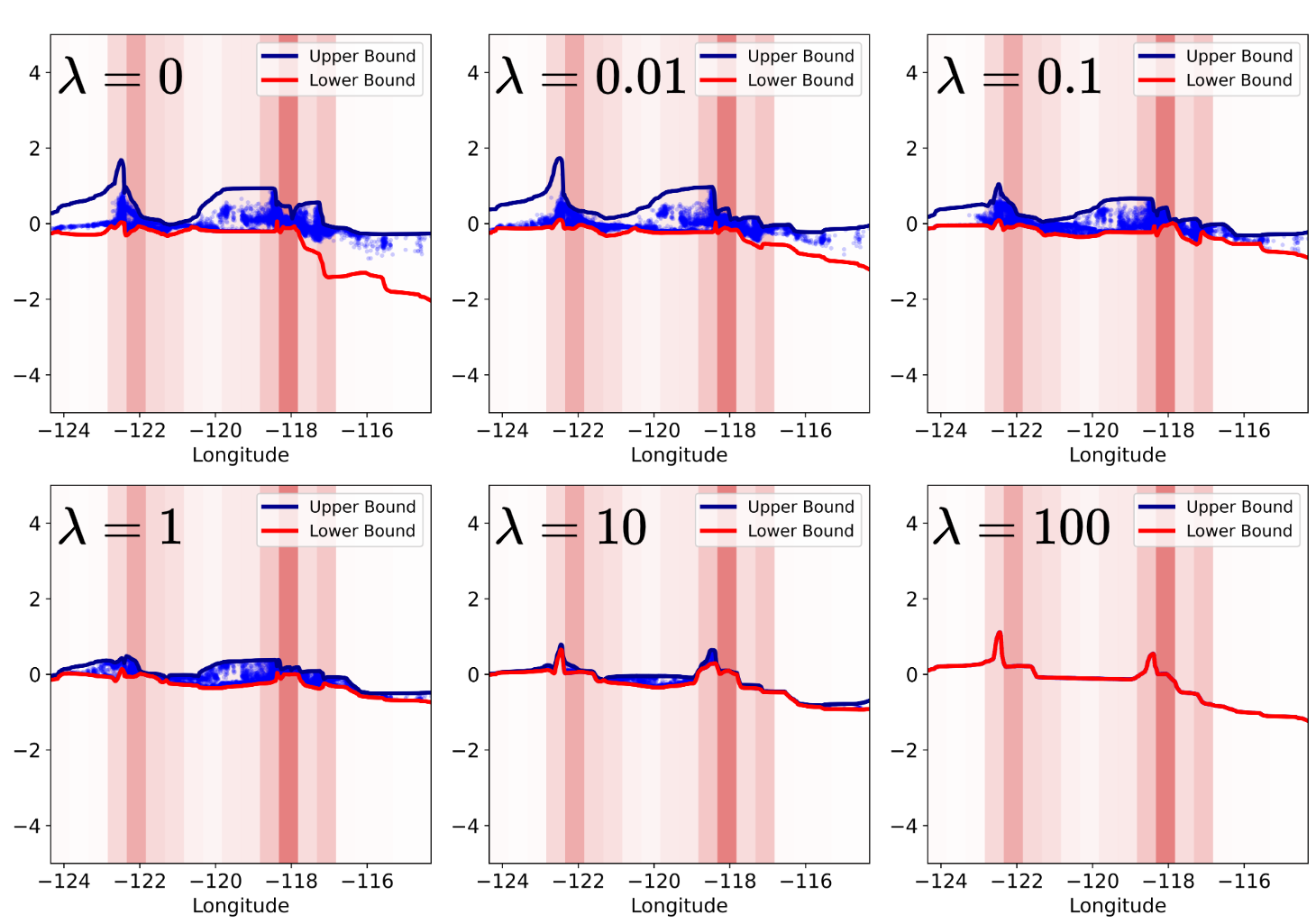
Нейронные аддитивные эксперты: новый подход
Нейронные аддитивные эксперты (NAE) развивают аддитивную структуру обобщенных аддитивных моделей (GAM), заменяя простые функции, применяемые к каждому признаку, специализированными «экспертными сетями». Вместо использования, например, линейной регрессии или сплайнов для моделирования влияния каждого признака на целевую переменную, NAE использует нейронные сети различной архитектуры для каждого признака. Это позволяет каждой «экспертной сети» независимо изучать нелинейные зависимости, специфичные для соответствующего признака, сохраняя при этом аддитивную природу модели, где общая предсказание является суммой вкладов каждой экспертной сети.
В архитектуре Neural Additive Experts (NAE) динамический механизм управления (gating mechanism) играет ключевую роль в комбинировании предсказаний отдельных экспертных сетей. Этот механизм, основанный на обучении, определяет веса, с которыми вклад каждой экспертной сети суммируется для получения итогового предсказания. В отличие от фиксированных комбинаций, динамическое управление позволяет модели адаптировать способ объединения вкладов экспертов в зависимости от входных данных, что обеспечивает возможность моделирования сложных нелинейных взаимодействий между признаками и повышения общей точности предсказаний. Веса, определяемые механизмом управления, являются параметрами, оптимизируемыми в процессе обучения с использованием стандартных алгоритмов градиентного спуска.
Архитектура Neural Additive Experts (NAE) позволяет моделировать нелинейные зависимости от признаков, сохраняя при этом возможность интерпретации предсказаний. В отличие от линейных моделей, NAE использует нейронные сети в качестве экспертов для каждого признака, что позволяет улавливать сложные нелинейные связи. При этом, общая предсказательная способность модели формируется как сумма вкладов от каждого эксперта, что обеспечивает разложение предсказания на отдельные эффекты признаков. Такое разложение облегчает понимание влияния каждого признака на итоговый результат, делая модель более прозрачной и пригодной для анализа.
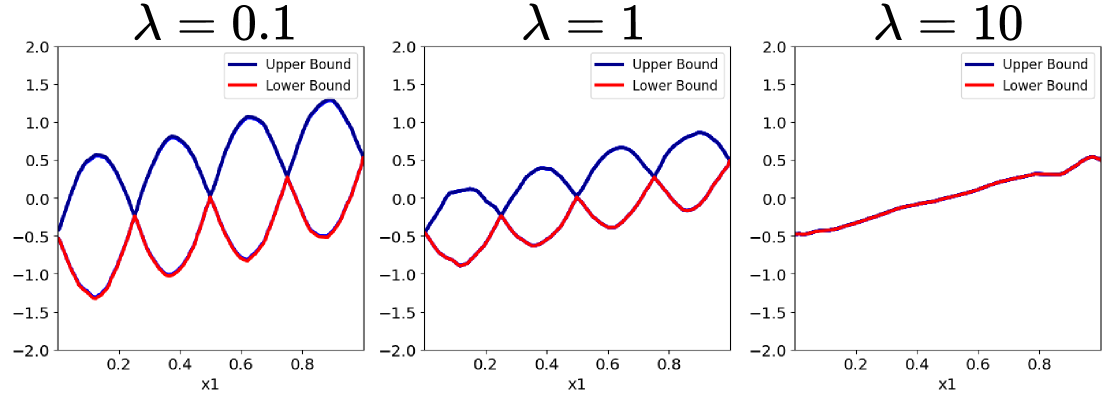
Оптимизация NAE: повышение производительности и эффективности
Эффективное кодирование признаков играет ключевую роль в работе NAE, поскольку предоставляет экспертным сетям релевантные латентные представления. Качество этих представлений напрямую влияет на способность модели выявлять и использовать сложные взаимосвязи в данных. Процесс кодирования признаков включает преобразование исходных данных в векторное пространство, где каждый вектор отражает характеристики конкретного экземпляра. Выбор подходящего метода кодирования, такого как one-hot encoding, embedding или другие методы снижения размерности, критически важен для обеспечения достаточной информативности и эффективности латентных представлений, используемых экспертными сетями для принятия решений.
Для контроля сложности модели и предотвращения переобучения в NAE реализован член регуляризации. Этот член добавляется к функции потерь и наказывает за слишком большие веса в сети, способствуя созданию более обобщенной модели. Использование регуляризации позволяет снизить дисперсию модели и повысить ее способность к обобщению на новые, ранее не встречавшиеся данные, что особенно важно при работе с ограниченными объемами обучающих данных или при наличии зашумленных признаков. Выбор конкретного типа регуляризации (например, L1 или L2) и коэффициента регуляризации осуществляется эмпирически на основе валидационного набора данных.
На наборе данных Housing, разработанная нейронная архитектура (NAE) демонстрирует среднеквадратичную ошибку (RMSE) в 0.1306, что свидетельствует о превосходстве в моделировании сложных взаимосвязей между признаками по сравнению с альтернативными подходами. Для повышения вычислительной эффективности и снижения избыточности, в механизм управления (gating network) интегрирована маска, индуцирующая разреженность. Эта маска выборочно обнуляет наименее значимые оценки, что позволяет снизить вычислительные затраты и объем требуемой памяти без существенной потери точности модели.
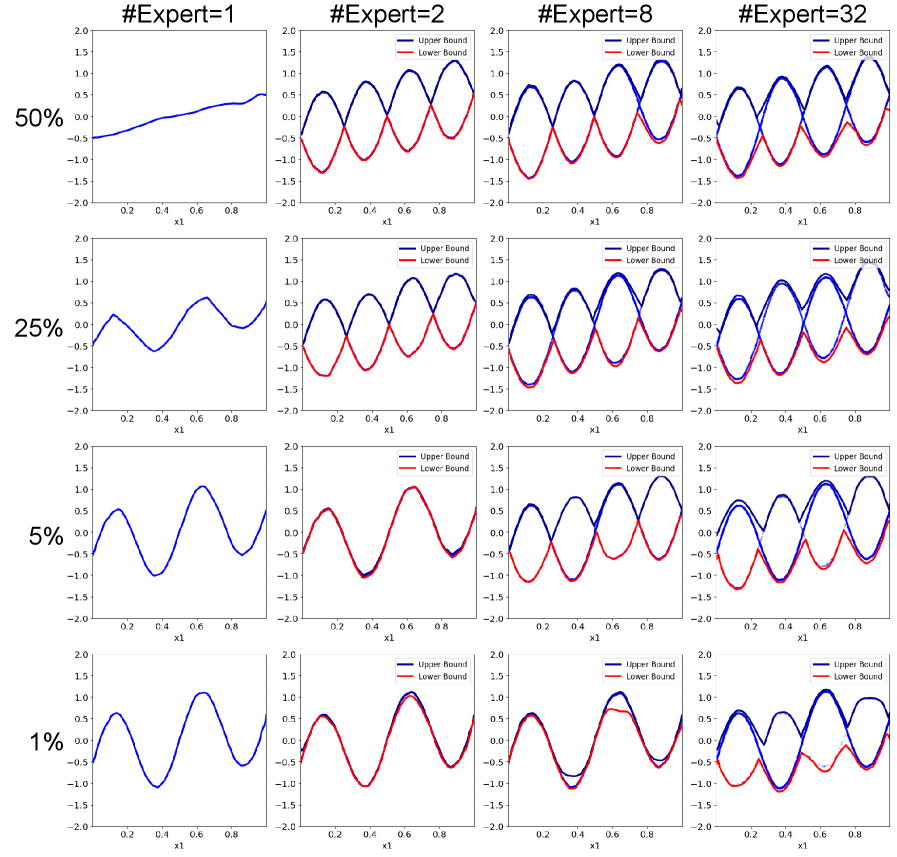
Масштабирование и адаптация NAE: NAE-D и NAE-E
Модель NAE-D упрощает процесс маршрутизации за счет использования диагональной матрицы маршрутизации. Данный подход позволяет существенно снизить вычислительную сложность модели без значительной потери в производительности. В отличие от полносвязных матриц маршрутизации, диагональная матрица требует значительно меньше параметров для хранения и вычисления, что приводит к уменьшению потребления памяти и ускорению процесса обучения и инференса. Эффективность данного упрощения подтверждается экспериментальными данными, демонстрирующими сохранение высокой точности модели при снижении вычислительных затрат.
Модель NAE-E использует дискретный подход к выбору экспертов, основанный на равномерном распределении активации между ними. Это означает, что каждый эксперт получает примерно одинаковую долю входных данных для обработки, что способствует повышению стабильности модели и предотвращает доминирование отдельных экспертов. Равномерное распределение активации снижает чувствительность модели к изменениям в данных и повышает её устойчивость к переобучению, что особенно важно при работе с зашумленными или неполными данными. Такой подход позволяет модели эффективно использовать все доступные эксперты, улучшая общую производительность и надежность.
При проведении симуляций на данных с коррелированными признаками, модель NAE демонстрирует стабильно низкое значение среднеквадратичной ошибки (RMSE), в то время как производительность модели NAM ухудшается. Данный результат указывает на повышенную устойчивость NAE к изменениям в данных. Варианты NAE-D и NAE-E, упрощающие модель и обеспечивающие дискретный выбор экспертов, подтверждают её адаптивность и потенциальную применимость в средах с ограниченными вычислительными ресурсами, где важна эффективность и стабильность работы.
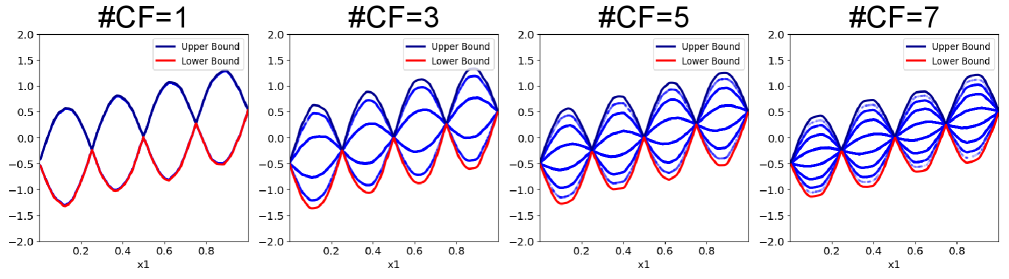
К точному и интерпретируемому прогнозированию
Новая архитектура нейронных сетей (NAE) демонстрирует уникальную способность моделировать сложные взаимодействия признаков, не жертвуя при этом интерпретируемостью. В отличие от многих современных «черных ящиков», NAE позволяет понять, как именно каждый признак влияет на итоговое предсказание, что делает её особенно ценной в областях, где важны не только точные результаты, но и прозрачность процесса принятия решений. Это особенно актуально в критических сферах, таких как медицина или финансы, где понимание причинно-следственных связей является ключевым для доверия и эффективного использования моделей. Благодаря этой особенности, NAE открывает новые возможности для применения искусственного интеллекта в задачах, требующих как высокой точности, так и глубокого понимания лежащих в основе закономерностей.
Разложение прогнозов на индивидуальные вклады признаков является ключевым преимуществом NAE, значительно упрощающим процесс отладки модели. Вместо работы с абстрактным «черным ящиком», специалисты получают возможность детально проанализировать, какие именно признаки оказали наибольшее влияние на конкретное предсказание. Это не только повышает доверие к модели, позволяя удостовериться в логичности ее работы, но и открывает возможности для принятия более обоснованных решений на основе ее результатов. Понимание вклада каждого признака позволяет выявлять потенциальные ошибки в данных или нежелательные смещения в модели, а также оптимизировать процесс принятия решений, учитывая наиболее значимые факторы.
Архитектура, лежащая в основе данной системы, обладает значительным потенциалом для дальнейшего развития. Её гибкость позволяет исследователям экспериментировать с различными подходами, в частности, с внедрением контекстно-зависимых экспертов — механизмов, которые динамически адаптируют свою работу в зависимости от входных данных. Кроме того, масштабируемость платформы открывает возможности для создания еще более эффективных и компактных архитектур, способных решать сложные задачи при минимальных вычислительных затратах. Эти направления исследований обещают не только повышение точности прогнозов, но и снижение требований к ресурсам, что делает систему перспективной для широкого спектра применений, включая мобильные устройства и системы реального времени.
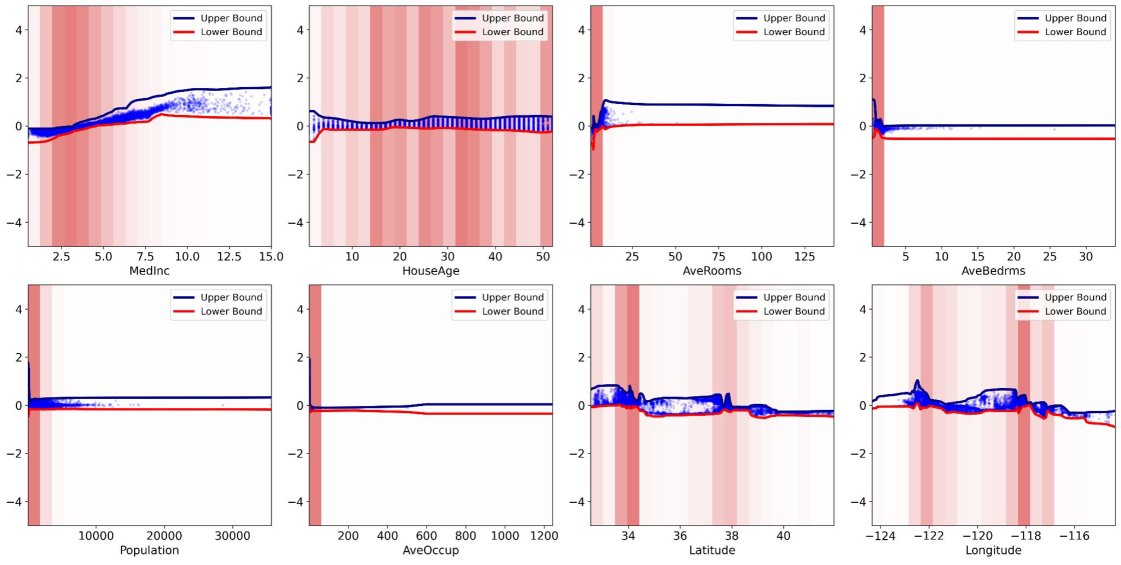
Предложенная работа исследует возможности создания нейронных аддитивных моделей, стремящихся к балансу между точностью и интерпретируемостью. Подобный подход к моделированию признаков и их взаимодействий позволяет системе эволюционировать и совершенствоваться со временем, адаптируясь к новым данным и уточняя свои представления. Как отмечал Анри Пуанкаре: «Математика — это искусство давать верные названия вещам». В контексте данной работы, стремление к четкому определению вклада каждого признака в общую модель является ключевым аспектом, обеспечивающим не только высокую точность, но и возможность глубокого понимания поведения системы. Это особенно важно для сложных систем, где прозрачность и управляемость становятся критическими факторами.
Что впереди?
Представленный подход к построению аддитивных нейронных сетей, несомненно, открывает новые возможности для управления сложностью и интерпретируемостью моделей. Однако, как и любая система, стремящаяся к адаптации, он не лишен ограничений. Вопрос о масштабируемости предложенного механизма динамического управления экспертами остается открытым — по мере увеличения числа признаков и экспертов, стоимость вычислений и сложность обучения неизбежно возрастают. Иногда лучше наблюдать за процессом, чем пытаться ускорить его.
Интересно, что дальнейшие исследования могут быть направлены не столько на увеличение точности, сколько на углубление понимания того, как модель приходит к своим решениям. Системы, как и люди, со временем учатся не спешить. Вместо бесконечной гонки за незначительным улучшением метрик, возможно, стоит сосредоточиться на создании систем, способных объяснять свою логику и адаптироваться к меняющимся требованиям, не теряя при этом своей прозрачности.
В конечном итоге, мудрые системы не борются с энтропией — они учатся дышать вместе с ней. Предложенная архитектура — лишь один из возможных путей, и будущее, вероятно, принесет новые, неожиданные решения. Иногда наблюдение — единственная форма участия.
Оригинал статьи: https://arxiv.org/pdf/2602.10585.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-15 04:20