Автор: Денис Аветисян
Исследование показывает, что современные языковые модели демонстрируют более продвинутые стратегии в повторяющихся играх, чем люди, превосходя нас в умении предугадывать действия соперника.
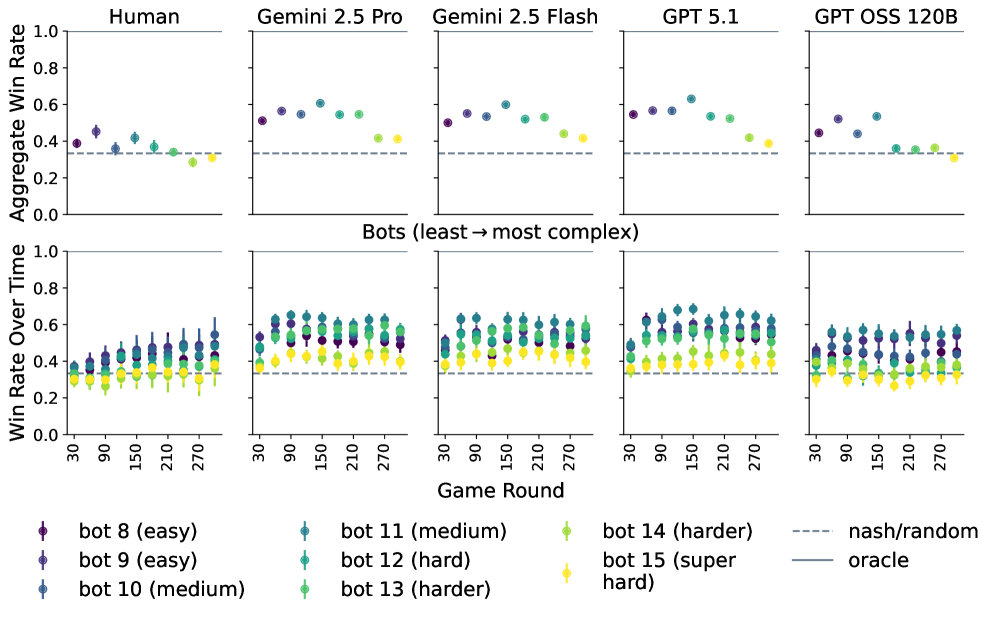
Анализ интерпретируемых программ, полученных с помощью автоматического синтеза моделей, выявил превосходство языковых моделей в моделировании стратегий оппонентов в рамках поведенческой теории игр.
По мере все более широкого внедрения больших языковых моделей (LLM) в социальные и стратегические взаимодействия, возникает необходимость в понимании различий между их поведением и человеческим. В работе ‘Discovering Differences in Strategic Behavior Between Humans and LLMs’ предложен подход, использующий инструмент автоматического обнаружения программ AlphaEvolve для выявления интерпретируемых моделей поведения как людей, так и LLM, что позволяет выявить структурные факторы, определяющие их стратегические решения. Анализ многократно повторяющейся игры «камень-ножницы-бумага» показал, что передовые LLM способны к более глубокому стратегическому мышлению, чем люди. Какие еще аспекты когнитивных способностей LLM могут превосходить человеческие, и как это повлияет на взаимодействие человека и искусственного интеллекта в будущем?
Стратегическое взаимодействие как ключ к пониманию интеллекта
Понимание стратегического поведения, то есть способности агентов адаптироваться к действиям оппонентов, является краеугольным камнем исследования интеллекта. Способность предвидеть возможные ходы соперника, корректировать собственную тактику в ответ на изменяющиеся обстоятельства и, в конечном итоге, добиваться оптимального результата — всё это признаки разумного поведения. Изучение стратегий, применяемых в различных взаимодействиях, будь то биологические виды, экономические агенты или искусственные системы, позволяет глубже понять механизмы, лежащие в основе принятия решений и адаптации, что, в свою очередь, открывает новые перспективы в разработке более совершенного искусственного интеллекта и понимании природы интеллекта в целом. По сути, способность к стратегическому взаимодействию не просто следствие интеллекта, но и его неотъемлемая часть.
Игра в «Камень, Ножницы, Бумагу» в итерированном формате предоставляет исследователям уникальную возможность изучать динамику стратегического взаимодействия в контролируемых условиях. Упрощая сложность реальных взаимодействий, эта игра позволяет выделить и проанализировать ключевые аспекты адаптации и прогнозирования поведения оппонента. В отличие от непредсказуемых ситуаций в реальном мире, итерированная версия позволяет наблюдать за эволюцией стратегий на протяжении множества раундов, выявляя закономерности и предсказуемые реакции. Такой подход особенно ценен при изучении искусственного интеллекта, поскольку позволяет количественно оценить способность агентов к обучению и адаптации, а также сравнить их стратегические навыки с человеческими.
Исследование стратегического взаимодействия на примере игры «Камень, ножницы, бумага» предоставляет уникальную возможность сопоставить подходы к планированию и адаптации у людей и современных языковых моделей. В ходе экспериментов, передовые модели, такие как Gemini 2.5 Pro, Gemini 2.5 Flash и GPT 5.1, продемонстрировали более высокую результативность в этой игре, чем человеческие игроки. Этот факт указывает на способность этих моделей к более глубокому анализу действий оппонента, прогнозированию его шагов и построению эффективной стратегии, что свидетельствует о значительном прогрессе в области искусственного интеллекта и его способности к сложным когнитивным процессам.
Моделирование оппонента: базовые подходы и ограничения
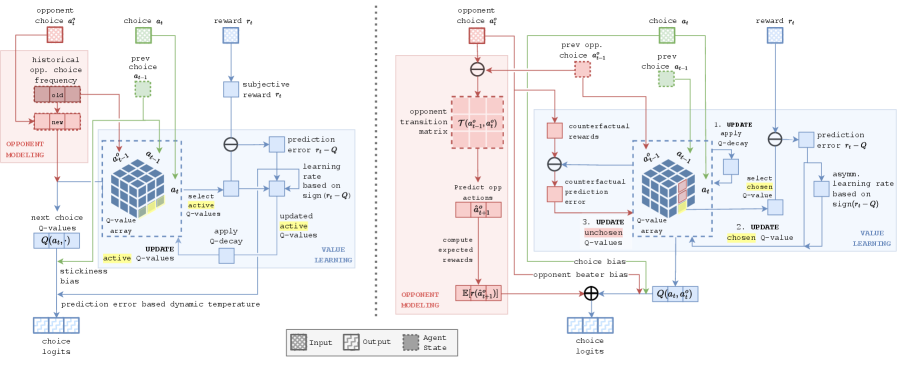
Моделирование оппонента является ключевым компонентом эффективной стратегии, поскольку позволяет предсказывать будущие действия на основе наблюдаемого поведения. Оценка вероятности различных действий противника позволяет агенту выбирать оптимальные собственные действия, максимизируя ожидаемый результат. Точность прогнозирования напрямую влияет на эффективность стратегии; чем лучше модель предсказывает действия оппонента, тем более обоснованными и эффективными будут собственные действия агента. Игнорирование моделирования оппонента или использование неточной модели может привести к неоптимальным решениям и снижению производительности в соревновательных сценариях.
Для задач моделирования оппонента, в качестве базовых подходов широко используются Contextual Sophisticated EWA (Exponential Weighted Average) и рекуррентные нейронные сети (RNN). Contextual Sophisticated EWA представляет собой метод взвешенного усреднения, учитывающий контекст предыдущих действий оппонента для прогнозирования будущих. RNN, в свою очередь, способны обрабатывать последовательности данных и выявлять зависимости во времени, что позволяет им моделировать более сложные стратегии. Оба подхода служат отправной точкой для оценки эффективности более современных методов, предоставляя возможность сравнения производительности и определения необходимости применения более сложных моделей.
Существующие методы моделирования оппонента, такие как Contextual Sophisticated EWA и рекуррентные нейронные сети (RNN), хотя и предоставляют базовые возможности для прогнозирования действий, могут быть сложны в реализации и не всегда способны уловить тонкости стратегической адаптации, что потенциально снижает эффективность. Передовые большие языковые модели (LLM) используют значительно более сложные модели оппонента, например, матрицы 3×3, отслеживающие ходы, обусловленные предыдущими действиями, в то время как модели, используемые людьми и GPT OSS 120B, остаются более простыми.
Автоматизированное открытие интерпретируемых стратегий
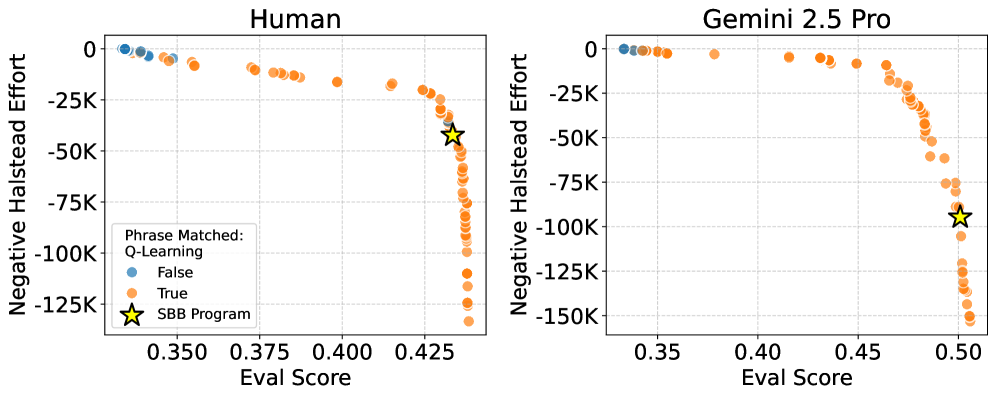
AlphaEvolve представляет собой автоматизированный фреймворк, предназначенный для поиска интерпретируемых моделей поведения. В отличие от традиционных методов машинного обучения, которые часто приводят к сложным и непрозрачным моделям, AlphaEvolve генерирует программы, которые могут быть легко проанализированы и поняты человеком. Процесс автоматического поиска моделей основан на определении и оптимизации программного кода, выполняющего желаемое поведение, и позволяет находить решения, которые одновременно обеспечивают высокую точность и простоту реализации. Фреймворк использует заданный шаблон программы (Program Template) для обеспечения структурированности и согласованности генерируемых моделей.
AlphaEvolve использует многоцелевую оптимизацию для одновременного повышения точности модели и снижения её сложности. Этот подход позволяет находить решения, которые не только хорошо предсказывают результаты, но и легко интерпретируются человеком. В процессе оптимизации, точность модели оценивается стандартными метриками, в то время как сложность измеряется такими показателями, как объём кода и сложность алгоритма. Балансировка между этими целями достигается путём определения оптимального компромисса, обеспечивающего высокую производительность и понятность генерируемых моделей. Использование многоцелевой оптимизации позволяет избежать ситуаций, когда повышение точности достигается за счёт чрезмерного усложнения кода, что затрудняет его анализ и отладку.
Процесс генерации моделей в AlphaEvolve опирается на предопределенный Шаблон Программы (Program Template), который задает структуру и формат генерируемого кода. Этот шаблон определяет допустимые операции, типы данных и общую архитектуру программы, гарантируя, что все сгенерированные модели будут соответствовать определенным критериям и будут иметь согласованный формат. Использование шаблона позволяет ограничить пространство поиска, упростить процесс оптимизации и обеспечить воспроизводимость результатов. Шаблон программы не является фиксированным и может быть изменен для адаптации к различным задачам и типам данных, однако он всегда служит основой для генерируемого кода, обеспечивая его структурированность и понятность.
Оценка полученных моделей в AlphaEvolve включает в себя метрику Halstead Effort, позволяющую количественно оценить сложность и понятность программного кода. Halstead Effort, рассчитываемый на основе количества операторов и уникальных операндов, выступает в качестве ключевой функции в процессе многоцелевой оптимизации наряду с прогностической точностью. Использование Halstead Effort в качестве целевой функции позволяет системе находить компромисс между достижением высокой точности предсказаний и поддержанием минимальной сложности кода, что способствует созданию более интерпретируемых и удобных для анализа моделей. Effort = L \times V , где L — количество строк кода, а V — объем кода, характеризующий сложность программы.
За пределами базовых подходов: перспективы открываемых стратегий
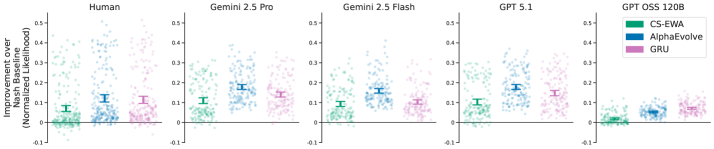
Исследования показали, что модели, разработанные с помощью AlphaEvolve, демонстрируют заметное превосходство над традиционными алгоритмами, такими как Contextual Sophisticated EWA и рекуррентные нейронные сети (RNN), в стратегических играх. Этот результат подтверждается количественными показателями эффективности, указывающими на более высокие показатели выигрыша и более оптимальные решения в сложных игровых сценариях. Превосходство новых моделей не ограничивается простым улучшением результатов; оно свидетельствует о способности автоматизированного процесса открытия стратегий генерировать инновационные подходы, превосходящие существующие, и открывает перспективы для создания более совершенных игровых агентов и алгоритмов принятия решений.
Исследования демонстрируют, что автоматизированный процесс обнаружения стратегий, реализованный в AlphaEvolve, способен выявлять подходы, превосходящие традиционные, разработанные человеком. Это не просто количественное улучшение результатов в стратегических играх, но и свидетельство способности алгоритма находить более эффективные и оптимальные решения. Вместо следования заранее заданным шаблонам, система самостоятельно исследует пространство возможностей, открывая стратегии, которые могут быть более лаконичными, быстрыми в исполнении или требующими меньше вычислительных ресурсов. Такой подход позволяет не только достигать лучших показателей, но и повышает общую эффективность принимаемых решений, открывая перспективы для разработки более интеллектуальных и адаптивных систем.
В отличие от традиционных моделей, чьи решения часто представляют собой “черный ящик”, программы, разработанные AlphaEvolve, обладают внутренней прозрачностью. Это позволяет исследователям не просто наблюдать за результатами, но и анализировать логику, лежащую в основе каждого действия. Понимание этих механизмов принятия решений открывает новые возможности для оптимизации стратегий, а также для получения ценных знаний о природе стратегического мышления в целом. Такая интерпретируемость особенно важна в сложных игровых сценариях, где понимание причин успеха или неудачи имеет решающее значение для дальнейшего прогресса и разработки более эффективных алгоритмов.
Система AlphaEvolve генерирует решения, располагающиеся на границе Парето, что позволяет исследователям выбирать оптимальные модели, учитывая компромисс между производительностью и сложностью. Этот подход особенно важен в свете успехов передовых больших языковых моделей (LLM), демонстрирующих превосходные результаты благодаря более развитому стратегическому мышлению. Возможность получения спектра решений, отличающихся по сложности и эффективности, открывает путь к созданию специализированных моделей, адаптированных к конкретным задачам и ресурсам, а также способствует лучшему пониманию принципов, лежащих в основе эффективной стратегии принятия решений.

Исследование демонстрирует, что большие языковые модели способны к более сложным стратегическим действиям, чем люди, в повторяющихся играх. Это связано с их превосходной способностью к моделированию стратегий оппонентов, что выявляется благодаря анализу интерпретируемых программ, полученных посредством автоматического синтеза моделей. В этом контексте уместно вспомнить слова Блеза Паскаля: «Человек создан для того, чтобы думать». Действительно, способность к анализу и прогнозированию, продемонстрированная моделями, подчеркивает важность рационального мышления и способности к адаптации, что является ключевым аспектом стратегического поведения, особенно в контексте итерируемой игры «Камень, ножницы, бумага».
Куда двигаться дальше?
Представленные результаты заставляют задуматься: если машины демонстрируют более изощренное стратегическое поведение в повторяющихся играх, то не является ли человеческая стратегия лишь кажущейся сложностью, замаскированной неспособностью к глубокому моделированию оппонента? Полагаться на “интуицию” или “чувство игры” — это, возможно, просто констатация ограниченности вычислительных ресурсов. Если система держится на костылях, значит, мы переусложнили её. Необходимо отойти от попыток имитировать человеческое мышление и сосредоточиться на создании принципиально новых, прозрачных стратегий.
Особое внимание следует уделить исследованию границ применимости методов автоматического синтеза программ для анализа и генерации стратегий. Модульность без понимания контекста — иллюзия контроля. В данном случае, интерпретируемость полученных программ — ценный, но недостаточный критерий. Необходимо разрабатывать метрики, оценивающие устойчивость стратегий к изменениям в поведении оппонента, а также их адаптивность к новым игровым ситуациям.
Перспективным направлением представляется изучение взаимодействия между различными стратегическими агентами — как созданными на основе больших языковых моделей, так и использующими традиционные алгоритмы теории игр. Понимание того, как эти агенты будут сотрудничать, конкурировать и адаптироваться друг к другу, позволит создать более надежные и эффективные системы принятия решений в реальных условиях.
Оригинал статьи: https://arxiv.org/pdf/2602.10324.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-12 12:27