Автор: Денис Аветисян
Новый подход позволяет выявлять и устранять ложные зависимости в графовых нейросетях, повышая надежность и прозрачность их объяснений.
Предлагается фреймворк саморефлексии для уточнения масок важности ребер и повышения согласованности объяснений без дополнительного обучения.
Несмотря на успехи в области интерпретируемого машинного обучения на графах, модели часто уязвимы к ложным корреляциям, искажающим выделение ключевых структур. В данной работе, ‘Combating Spurious Correlations in Graph Interpretability via Self-Reflection’, предложен новый подход, использующий принцип саморефлексии, аналогичный применяемому в больших языковых моделях, для повышения надежности интерпретации графов. Предложенная схема итеративно уточняет важность ребер, смягчая влияние ложных корреляций и обеспечивая согласованность объяснений без дополнительного обучения. Возможно ли дальнейшее развитие этого подхода для создания более устойчивых и надежных систем анализа графов в различных областях применения?
Хрупкость Графовых Прогнозов: Эхо Случайных Связей
Несмотря на впечатляющую способность графовых нейронных сетей (GNN) моделировать взаимосвязи в данных, их прогнозы могут оказаться неожиданно хрупкими и зависеть от ложных корреляций. Исследования показывают, что даже незначительные изменения во входных данных или структуре графа способны привести к существенным изменениям в предсказаниях, что ставит под вопрос надежность моделей в критически важных приложениях. Эта уязвимость связана с тем, что GNN часто улавливают поверхностные закономерности, а не причинно-следственные связи, что приводит к ошибочным выводам и снижает доверие к результатам. Таким образом, несмотря на потенциал GNN в анализе реляционных данных, необходимо учитывать их склонность к зависимости от случайных корреляций и разрабатывать методы повышения устойчивости и надежности прогнозов.
Существенная проблема, ограничивающая применение графовых нейронных сетей (GNN), заключается в феномене, названном «галлюцинацией на уровне объяснений». Исследования показывают, что GNN могут выдавать объяснения своих предсказаний, основанные на совершенно нерелевантных признаках графа. Это означает, что сеть может указывать на связи или узлы, которые на самом деле не имеют никакого отношения к принятому решению, вводя в заблуждение относительно причинно-следственных связей. Такая «галлюцинация» подрывает доверие к модели, особенно в критически важных областях, где требуется верифицируемое обоснование каждого шага, и делает невозможным надежное использование GNN в ситуациях, требующих прозрачности и ответственности.
Отсутствие прозрачности в работе графовых нейронных сетей (GNN) существенно ограничивает их применение в областях, требующих надежных и обоснованных решений. В частности, в критически важных сферах, таких как здравоохранение, финансы и право, недостаточно просто получить прогноз — необходимо понимать, на каких конкретно факторах и связях он основан. Невозможность проверить логику рассуждений GNN, выявить потенциальные ошибки или предвзятости, делает их использование рискованным. Без возможности верифицировать процесс принятия решений, доверие к таким системам снижается, препятствуя их внедрению и широкому распространению в ответственных приложениях, где прозрачность и объяснимость являются первостепенными требованиями.
L2X: Архитектура для Надежного Рассуждения
Архитектура L2X обеспечивает принципиальное разделение предсказательной силы и объяснительных сигналов в графовых нейронных сетях (GNN). В отличие от традиционных GNN, где эти аспекты неявно переплетены, L2X явно разделяет процесс оценки важности ребер графа от процесса предсказания. Это достигается путем использования двух отдельных модулей: ‘upstream’ модуля, предназначенного для оценки влияния каждого ребра на задачу, и ‘downstream’ модуля, использующего эту оценку для выполнения предсказания. Такое разделение позволяет моделировать и интерпретировать, какие именно связи в графе являются наиболее значимыми для принятия решений, а также оценить вклад каждого ребра в конечное предсказание, что повышает прозрачность и надежность модели.
Архитектура L2X реализует разделение процессов анализа графа посредством двух последовательных модулей. Первый, «upstream» модуль, предназначен для явной оценки значимости каждого ребра графа, вычисляя метрику, отражающую вклад конкретного ребра в общую структуру и информационное содержание графа. Результаты этой оценки используются вторым, «downstream» модулем, который выполняет предсказание на основе графа, модифицированного с учетом важности ребер, определенной первым модулем. Таким образом, «upstream» модуль выступает в роли фильтра, выделяющего наиболее релевантные связи, а «downstream» модуль осуществляет предсказание, опираясь на отфильтрованную информацию.
Маскирование ребер, основанное на выходных данных ‘upstream модуля’, является ключевым механизмом L2X, направленным на повышение надежности модели. Этот процесс заключается в удалении из графа ребер, которые модуль признал наименее важными для объяснения структуры данных. В результате модель вынуждена принимать решения, опираясь исключительно на оставшиеся, действительно влиятельные связи, что позволяет отсеять шумовые или избыточные соединения и сосредоточиться на критически важных элементах графа. Таким образом, достигается более интерпретируемое и устойчивое к искажениям принятие решений, поскольку модель не может полагаться на нерелевантные или случайные связи.
Саморефлексия: Оттачивая Верность Объяснений
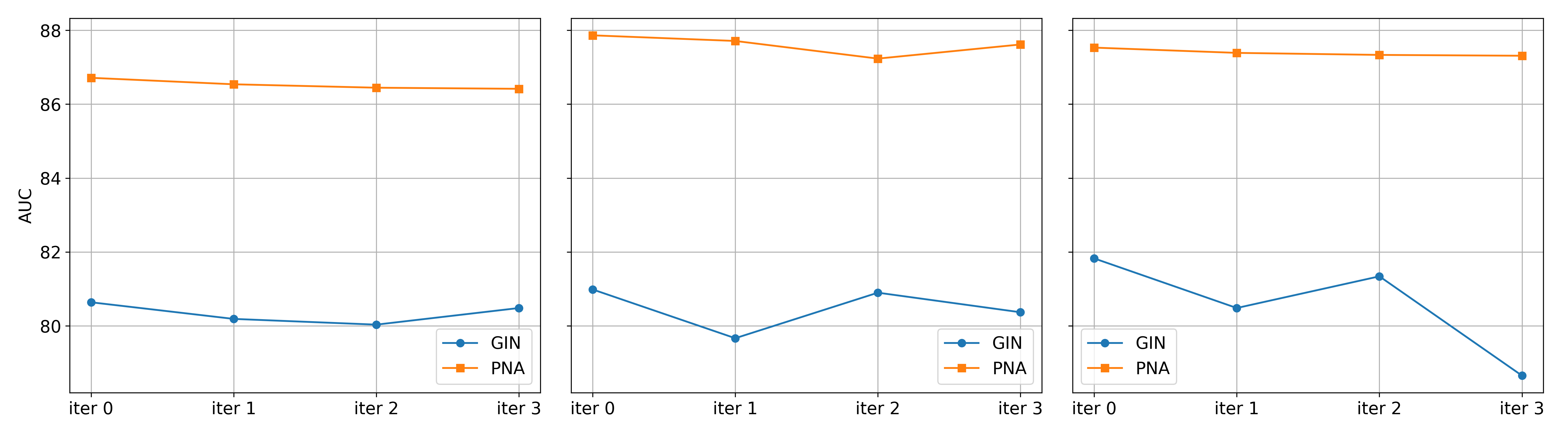
В рамках улучшения объяснимости моделей внедрён механизм “саморефлексии”, предполагающий итеративное усовершенствование объяснений. Данный процесс включает в себя последовательную критику и пересмотр первоначальных результатов моделью самой по себе. Каждая итерация предполагает анализ предыдущего объяснения, выявление потенциальных неточностей или недостатков, и последующую корректировку для получения более обоснованного и надёжного результата. Итеративный характер механизма позволяет модели постепенно приближаться к оптимальному объяснению, повышая его качество и достоверность.
В процессе саморефлексии используется функция потерь, называемая ‘mask consistency loss’, которая направлена на обеспечение стабильности и надёжности оценок важности ребер графа на каждой итерации. Данная функция потерь минимизирует расхождения между оценками важности ребер, полученными на разных итерациях саморефлексии, что способствует формированию более устойчивых и воспроизводимых объяснений. Это достигается путем штрафования значительных изменений в оценках важности ребер, гарантируя, что модель не будет произвольно менять своё мнение об их значимости в процессе уточнения объяснений. Стабильность оценок важности ребер является критическим фактором для обеспечения достоверности и интерпретируемости объяснений, генерируемых моделью.
Для обеспечения сохранения ключевой информации при генерации объяснений используется алгоритм GSAT, оптимизирующий взаимную информацию между замаскированным графом и исходным графом. Этот подход предполагает создание версии графа, в которой некоторые ребра удалены (замаскированы), а затем оптимизацию процесса восстановления этих ребер таким образом, чтобы максимально сохранить статистическую зависимость между замаскированным и исходным графами. Высокое значение взаимной информации указывает на то, что структура и свойства замаскированного графа тесно связаны с исходным, что гарантирует, что удаление или изменение ребер не приводит к существенной потере информации, необходимой для объяснения модели.
Процесс саморефлексии способствует монотонности важности ребер в графе объяснений. Это означает, что при итеративном уточнении объяснения, важность ключевых ребер не подвержена резким колебаниям, а демонстрирует тенденцию к стабильному увеличению или уменьшению. Такая стабильность важности ребер повышает уверенность в объяснении, поскольку указывает на то, что модель последовательно оценивает вклад каждого ребра в принятое решение, а не выдает случайные или противоречивые оценки.
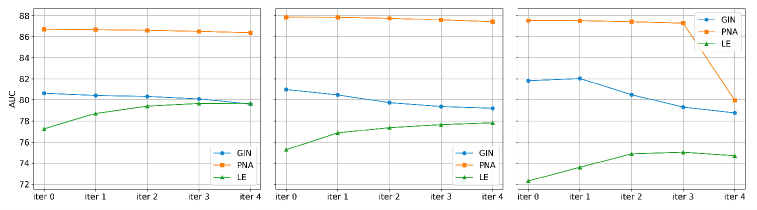
Оценка Устойчивости к Ложным Корреляциям
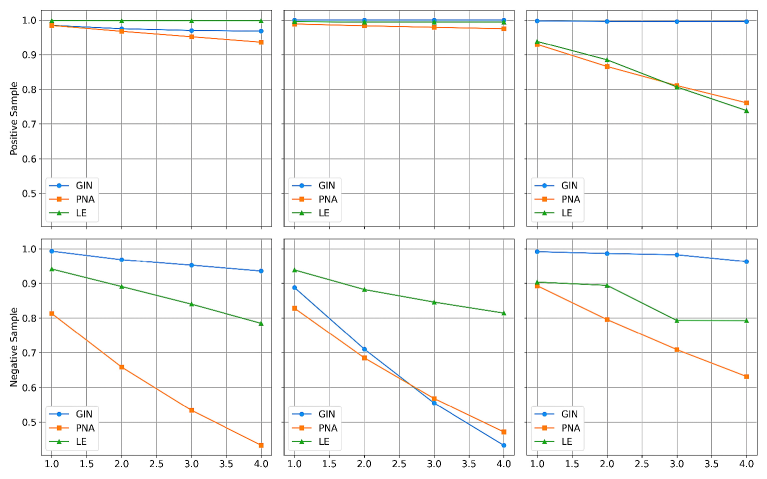
Для оценки устойчивости разработанного подхода L2X к ложным корреляциям, проводилось тестирование на синтетическом наборе данных ‘Spurious-Motif Benchmark’. Этот специально разработанный набор данных позволяет выявить, насколько модель опирается на несущественные признаки, не отражающие истинные закономерности. Использование саморефлексии в рамках L2X позволило не только обнаружить влияние этих ложных корреляций, но и эффективно снизить их воздействие на процесс принятия решений моделью. Такой подход обеспечивает более надежные и обоснованные результаты, особенно в тех случаях, когда данные содержат скрытые или вводящие в заблуждение факторы.
Исследования показали, что разработанный подход L2X демонстрирует значительное превосходство над базовыми графовыми нейронными сетями (GNN), включая GIN, PNA и LE, в процессе выявления и нейтрализации влияния ложных корреляций. В ходе экспериментов L2X эффективно обнаруживал признаки, не имеющие реальной связи с целевой задачей, и уменьшал их вклад в процесс принятия решений моделью. Это достигается за счет механизма саморефлексии, позволяющего L2X оценивать значимость различных признаков и игнорировать те, которые являются случайными или вводящими в заблуждение. В результате модель становится более устойчивой к шуму и способна делать более точные и надежные прогнозы, даже при наличии в данных ложных корреляций.
Улучшенные показатели, продемонстрированные L2X, приводят к формированию более достоверных объяснений, позволяя пользователям глубже понять ход рассуждений модели. Вместо предоставления необоснованных или вводящих в заблуждение интерпретаций, L2X выявляет и подчеркивает истинные факторы, влияющие на принятие решений. Это достигается за счет способности модели эффективно отсеивать ложные корреляции и концентрироваться на существенных признаках, что обеспечивает прозрачность и надежность результатов. Пользователи получают не просто предсказание, а детальное обоснование, позволяющее оценить релевантность и обоснованность выводов модели, что особенно важно в областях, где требуется высокая степень ответственности и доверия.
Исследования показали, что разработанный подход демонстрирует повышение точности на различных наборах данных и при использовании различных архитектур графовых нейронных сетей (LE и GIN). Особенно заметно снижение разрыва между точностью на обучающей и тестовой выборках для набора данных MolHIV, что свидетельствует о снижении переобучения на ложных корреляциях. Этот результат указывает на способность подхода обобщать знания и избегать запоминания специфических особенностей обучающей выборки, что критически важно для надежной работы моделей в реальных условиях и повышения доверия к ним. Уменьшение переобучения позволяет модели делать более точные предсказания на новых, ранее не встречавшихся данных, что подтверждает её устойчивость и способность к эффективному обобщению.
Повышенная интерпретируемость графовых нейронных сетей (GNN) становится ключевым фактором для их успешного внедрения в практические приложения, особенно в областях, где требуется высокая степень ответственности и прозрачности принятия решений. В контексте критически важных систем, таких как медицинская диагностика или финансовый анализ, недостаточно просто получить точный прогноз; необходимо понимать, на каких конкретно признаках и связях в графе модель основывает свои выводы. Способность четко объяснить логику работы GNN позволяет специалистам проверить корректность рассуждений модели, выявить потенциальные ошибки или предвзятости, а также повысить доверие к системе со стороны пользователей и регуляторов. Таким образом, улучшенная интерпретируемость не только способствует более эффективной отладке и совершенствованию моделей, но и является необходимым условием для их безопасного и этичного использования в реальном мире.
Исследование показывает, что попытки интерпретировать графовые нейронные сети часто сталкиваются с ложными корреляциями. Авторы предлагают механизм саморефлексии, позволяющий итеративно уточнять маски важности ребер, снижая влияние этих ошибочных связей. Этот подход напоминает слова Блеза Паскаля: «Все великие дела требуют времени». Действительно, построение надежной интерпретации требует не однократного анализа, а постоянного пересмотра и уточнения, как если бы система сама себя «чинила», устраняя несоответствия и ложные зависимости. Вместо того чтобы пытаться контролировать интерпретацию, предлагается позволить системе эволюционировать к более согласованному и правдивому представлению, признавая, что полный контроль — иллюзия.
Что дальше?
Представленная работа, стремясь обуздать иллюзорные корреляции в интерпретируемых графовых сетях, поднимает вопрос о самой природе объяснимости. Каждая новая маска важности ребер, отточенная саморефлексией, — это лишь временное усмирение хаоса. Ведь порядок — это всего лишь кэш между сбоями, а истинная устойчивость объяснений кроется не в устранении корреляций, а в понимании их природы и контекста возникновения.
Будущие исследования, вероятно, столкнутся с необходимостью выхода за рамки локальных масок и анализа влияния всей графовой структуры на устойчивость объяснений. Архитектуры, обещающие “самообъяснимость”, часто требуют жертвоприношений в виде вычислительных ресурсов и сложности внедрения. Вместо погони за идеальной маской, возможно, стоит обратить внимание на методы обнаружения и сигнализации о ситуациях, когда объяснения становятся ненадежными, предупреждая о потенциальных ошибках.
Экосистемы интерпретируемых графовых сетей растут не по плану. Каждый архитектурный выбор — это пророчество о будущей поломке. Истинный прогресс не в создании “идеальных” алгоритмов, а в разработке инструментов для навигации в неизбежном хаосе, признавая, что любая система — это лишь сложная адаптация к постоянно меняющимся условиям.
Оригинал статьи: https://arxiv.org/pdf/2601.11021.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-19 16:01