Автор: Денис Аветисян
Исследование показывает, как сочетание графовых нейронных сетей и ансамблевого обучения повышает точность прогнозирования кредитных дефолтов.
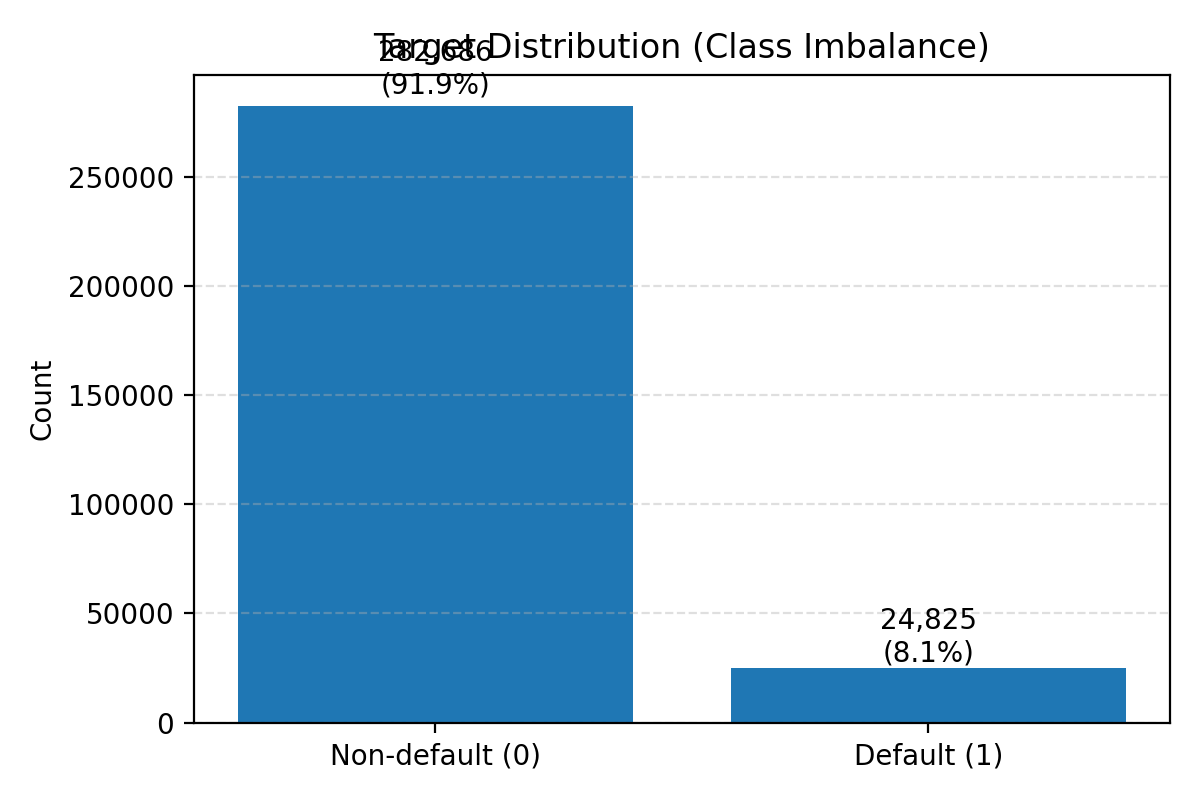
В статье рассматриваются гетерогенные графы, методы повышения справедливости и интерпретируемости моделей для оценки кредитоспособности.
Несмотря на эффективность табличных моделей в оценке кредитного риска, они зачастую не учитывают сложные взаимосвязи между заемщиками, финансовыми институтами и транзакциями. В работе ‘Relational Graph Modeling for Credit Default Prediction: Heterogeneous GNNs and Hybrid Ensemble Learning’ предложена методика, использующая гетерогенные графовые нейронные сети (GNN) для моделирования этих взаимосвязей и повышения точности прогнозирования дефолтов. Полученные результаты показывают, что комбинирование GNN с ансамблевым обучением на основе табличных признаков обеспечивает наилучшую производительность, улучшая как ROC-AUC, так и PR-AUC. Каким образом учет реляционных сигналов в графовых моделях может способствовать более справедливому и прозрачному принятию кредитных решений?
Математическая Сущность Кредитного Риска
Точная оценка риска невозврата кредитов имеет первостепенное значение для поддержания финансовой стабильности, однако традиционные методы часто оказываются неэффективными при работе со сложными взаимосвязями между заемщиками. Эти методы, как правило, рассматривают каждого заемщика изолированно, игнорируя важные данные о его связях с другими заемщиками, совместном финансировании или участии в общих бизнес-проектах. В результате, существующие модели недостаточно учитывают системные риски, когда неспособность одного заемщика погасить кредит может спровоцировать цепную реакцию, затрагивающую множество других. Поэтому, для повышения точности прогнозов и снижения вероятности финансовых кризисов, необходимы новые подходы, способные учитывать сложность и взаимозависимость современных финансовых систем.
Оценка кредитного риска, основанная исключительно на статических характеристиках заемщиков, зачастую оказывается неполной и не позволяет выявить скрытые закономерности. Такой подход игнорирует важную контекстуальную информацию, включая историю взаимоотношений между заемщиками, динамику изменений в их финансовом положении и влияние внешних факторов. Например, связи между созаемщиками или гарантами, а также данные о транзакциях и платежной дисциплине, могут существенно повысить точность прогнозирования дефолта. Игнорирование этих аспектов приводит к упрощенной модели оценки риска и, как следствие, к потенциальным финансовым потерям для кредиторов. Более современные подходы, учитывающие динамику и взаимосвязи в данных, позволяют выявлять более сложные паттерны и повышать надежность оценки кредитоспособности.
Набор данных “Home Credit Default Risk” представляет собой сложный ориентир в области прогнозирования кредитных рисков, выделяясь своим масштабом и сложной структурой. Он содержит информацию о более чем ста тысячах заемщиков и сотнях признаков, включающих не только стандартные демографические данные, но и сведения о транзакциях, кредитной истории и использовании продуктов компании. Такое многообразие данных, в сочетании с высокой степенью несбалансированности классов — значительно больше клиентов своевременно погашают кредиты, чем допускают просрочки — требует применения передовых методов машинного обучения и тщательной обработки данных для выявления скрытых закономерностей и построения эффективных моделей прогнозирования. Сложность структуры данных, включающая различные типы переменных и взаимосвязи между ними, делает задачу анализа нетривиальной и требует от исследователей глубокого понимания предметной области и владения современными инструментами анализа данных.
Существующие методы оценки кредитного риска зачастую оказываются неспособны выявить тонкие взаимосвязи, скрытые в структуре заемных сетей и сопутствующих данных. Традиционные модели, фокусирующиеся на индивидуальных характеристиках заемщиков, игнорируют важную информацию о взаимодействиях между ними, таких как совместные кредиты или взаимозависимость финансовых обязательств. Этот подход приводит к неполной оценке риска, поскольку не учитывает, что финансовые трудности одного заемщика могут повлиять на платежеспособность других, связанных с ним. Анализ сетевых данных, включающий информацию о взаимосвязях между заемщиками, позволяет выявить скрытые группы риска и более точно прогнозировать вероятность дефолта, чем при использовании изолированных показателей.
Графовые Нейронные Сети: Моделирование Взаимосвязей
Нейронные сети на графах (GNN) предоставляют естественную структуру для представления и анализа взаимосвязей между заемщиками в виде “гетерогенного графа”. В таком графе, узлы могут представлять различные типы сущностей — например, отдельных заемщиков, кредитные организации, гарантов — а ребра отражают различные типы отношений между ними, такие как “выдал кредит”, “является гарантом”, или “имеет совместную задолженность”. Использование гетерогенного графа позволяет учитывать разнородность данных и сложные зависимости, которые невозможно эффективно смоделировать с помощью традиционных методов анализа. Каждый тип узла и ребра может иметь свои собственные атрибуты, что дополнительно обогащает представление данных и позволяет GNN извлекать более точные и информативные представления о взаимосвязях между заемщиками.
Архитектура «Relation-Aware Attentive Heterogeneous GNN» использует механизмы внимания, специфичные для каждого типа связи в гетерогенном графе, для захвата сложных взаимодействий между узлами. В отличие от стандартных GNN, которые применяют единый механизм внимания ко всем связям, данная архитектура назначает веса внимания индивидуально для каждого реляционного типа. Это позволяет модели различать важность различных типов связей (например, «одалживал», «является поручителем», «имеет общие связи») при агрегации информации от соседних узлов. Реализация включает в себя вычисление весов внимания на основе признаков ребра и узлов, что позволяет динамически адаптировать процесс агрегации к конкретному контексту каждой связи и, таким образом, более точно моделировать зависимости в данных.
Самообучающееся предварительное обучение с использованием ‘Контрастного обучения’ (Contrastive Learning) повышает качество векторных представлений (embeddings), генерируемых графовыми нейронными сетями (GNN), и улучшает их способность к обобщению. В рамках данного подхода, модель обучается различать пары положительных и отрицательных примеров, основанных на структуре графа. Положительные примеры представляют собой узлы, связанные в графе, в то время как отрицательные примеры формируются путем случайного выбора узлов. Минимизация расстояния между положительными парами и максимизация расстояния между отрицательными парами в векторном пространстве позволяет модели изучать более информативные и устойчивые представления, что приводит к повышению производительности в задачах, требующих обобщения на новые данные и узлы.
Для эффективного обучения представлений в нашей гетерогенной графовой структуре мы адаптировали алгоритм GraphSAGE. В отличие от стандартной реализации, предназначенной для однородных графов, наша модификация учитывает различные типы связей и узлов. Это достигается путем применения отдельных агрегаторов для каждого типа ребра, позволяя моделировать специфические взаимодействия между ними. В процессе агрегации соседних узлов, веса, присваиваемые каждому соседу, определяются на основе характеристик как узла, так и типа ребра, соединяющего их. Такой подход позволяет GraphSAGE эффективно извлекать значимую информацию из гетерогенной структуры данных, улучшая качество получаемых векторных представлений.
Гибридный Ансамбль: Синергия Графов и Деревьев Решений
Предлагаемая нами модель «Гибридный ансамбль» объединяет представления, полученные с помощью графовых нейронных сетей (GNN), с градиентно-усиленными деревьями решений для повышения точности прогнозирования. Интеграция GNN обеспечивает учет реляционных данных и структурных зависимостей в анализируемых данных, в то время как деревья решений эффективно моделируют нелинейные взаимодействия признаков. Такой подход позволяет использовать сильные стороны обеих парадигм машинного обучения, что приводит к улучшению общей производительности модели в задачах прогнозирования.
Компонент графовых нейронных сетей (GNN) предназначен для извлечения и кодирования реляционных данных, присутствующих в структуре графа, что позволяет учитывать взаимосвязи между объектами. В отличие от этого, компонент, основанный на градиентном бустинге, эффективно выявляет и моделирует нелинейные взаимодействия между отдельными признаками. Сочетание этих двух подходов позволяет модели одновременно использовать информацию о связях между данными и сложные нелинейные зависимости внутри самих данных, что приводит к повышению точности прогнозирования по сравнению с моделями, использующими только один из этих типов анализа.
Для реализации градиентного бустинга в предложенной гибридной модели используется библиотека LightGBM, обеспечивающая высокую скорость обучения и масштабируемость. LightGBM использует алгоритм градиентного бустинга на основе деревьев решений с оптимизированной структурой данных и алгоритмами распараллеливания, что позволяет значительно сократить время обучения по сравнению с традиционными реализациями градиентного бустинга. Эффективная обработка больших объемов данных и возможность распараллеливания вычислений делают LightGBM подходящим инструментом для работы с задачами, требующими высокой производительности и масштабируемости, такими как анализ рисков и прогнозирование.
Эффективность предложенной гибридной модели была тщательно оценена с использованием метрик ROC-AUC и PR-AUC на наборе данных Home Credit Default Risk. Полученные результаты демонстрируют ROC-AUC в 0.7816 и PR-AUC в 0.2807. Данные показатели представляют собой значительное улучшение по сравнению с сильными табличными базовыми моделями, такими как LightGBM, которая на том же наборе данных достигла PR-AUC в 0.2540. Это подтверждает превосходство предложенного подхода в задачах прогнозирования дефолта.
Ответственный Искусственный Интеллект: Справедливость и Объяснимость
Проводится тщательный анализ справедливости, направленный на выявление и смягчение потенциальных предубеждений в прогнозах гибридной модели. Этот аудит включает в себя оценку различий в производительности для различных демографических групп, что позволяет обеспечить равноправные результаты для всех пользователей. Особое внимание уделяется выявлению систематических ошибок, которые могут приводить к несправедливому или дискриминационному отношению к определенным группам населения. Применяемые методы включают статистический анализ, оценку дисперсии и другие инструменты, позволяющие количественно оценить степень предвзятости и разработать стратегии для ее минимизации. Результаты аудита используются для корректировки модели и обеспечения ее соответствия принципам справедливости и недискриминации.
В рамках оценки справедливости проводится детальный анализ различий в производительности гибридной модели для различных демографических групп. Исследование направлено на выявление и устранение потенциальных смещений, которые могут привести к неравным результатам для отдельных категорий населения. Особое внимание уделяется обеспечению того, чтобы модель демонстрировала сопоставимую точность и надежность для всех групп, независимо от их демографических характеристик. Такой подход позволяет гарантировать, что решения, принимаемые моделью, будут справедливыми и не приведут к дискриминации, что особенно важно при использовании в финансовых приложениях, где последствия ошибок могут быть значительными.
Для повышения доверия и прозрачности гибридной модели применяются методы анализа объяснимости. Эти методы позволяют детально изучить процесс принятия решений, выявляя факторы, оказывающие наибольшее влияние на прогнозы. В ходе анализа не просто фиксируется результат, но и раскрывается логика, лежащая в основе каждого решения, что позволяет оценить обоснованность и надежность модели. Понимание внутренней работы алгоритма критически важно для выявления потенциальных ошибок и смещений, а также для обеспечения соответствия модели этическим нормам и регуляторным требованиям в сфере финансовых приложений. Таким образом, анализ объяснимости способствует не только повышению качества модели, но и укреплению доверия пользователей и заинтересованных сторон.
Применение гибридной модели в реальных финансовых приложениях требует строгого соблюдения принципов ответственного искусственного интеллекта. Недостаточно просто создать эффективный алгоритм; необходимо гарантировать его справедливость и прозрачность для всех пользователей. Отсутствие предвзятости в прогнозах и возможность понимания логики принятия решений — ключевые факторы для завоевания доверия и обеспечения бесперебойной работы системы в условиях высокой финансовой ответственности. Внедрение данных практик позволяет избежать дискриминации, снизить риски, связанные с неверными прогнозами, и обеспечить соответствие модели нормативным требованиям, что критически важно для успешного и этичного использования в финансовой сфере.
Исследование демонстрирует, что без четкого определения задачи прогнозирования кредитного дефолта, любые предложенные модели становятся лишь источником шума. Авторы справедливо подчеркивают важность объединения графовых нейронных сетей с ансамблевым обучением для повышения точности предсказаний, однако при этом акцентируют внимание на необходимости обеспечения справедливости и интерпретируемости моделей. Как однажды заметил Карл Фридрих Гаусс: «Если мы не знаем, чего хотим, то любое решение — это отклонение от цели». Этот принцип применим и к построению моделей кредитного риска: недостаточно просто добиться высокой точности, необходимо учитывать этические аспекты и понимать, как модель принимает решения, чтобы избежать дискриминации и обеспечить прозрачность.
Что Дальше?
Представленная работа, хотя и демонстрирует улучшение предсказательной силы моделей оценки кредитного риска за счет использования графовых нейронных сетей и ансамблевых методов, лишь обнажает глубину нерешенных вопросов. Идея о представлении заемщиков и их взаимосвязей в виде графа, безусловно, элегантна, однако истинная проверка — не в достижении нескольких процентов прироста точности, а в математической доказуемости устойчивости модели к искажениям данных и непредсказуемым изменениям в экономической среде.
Особое внимание следует уделить проблеме справедливости. Простое увеличение точности предсказаний не оправдывает, если модель систематически ущемляет права определенных групп заемщиков. Алгоритм должен быть не просто «рабочим», но и непротиворечивым с точки зрения этики и права. Необходимо разработать строгие метрики для оценки предвзятости и методы для ее смягчения, которые не снижают общую предсказательную силу.
В будущем, вероятно, потребуется переход от «черных ящиков» к более интерпретируемым моделям, способным объяснить логику своих решений. Истинная элегантность не в сложности, а в ясности и предсказуемости. Успех в этой области будет зависеть не от изобретения новых алгоритмов, а от строгого анализа существующих и доказательства их математической корректности.
Оригинал статьи: https://arxiv.org/pdf/2601.14633.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- Золото прогноз
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- OM/USD
2026-01-22 21:32