Автор: Денис Аветисян
Новое исследование показывает, что современные системы анализа кода на основе искусственного интеллекта уязвимы к манипуляциям через специально сформированные комментарии, но их эффективность значительно возрастает при интеграции со статическим анализом кода.
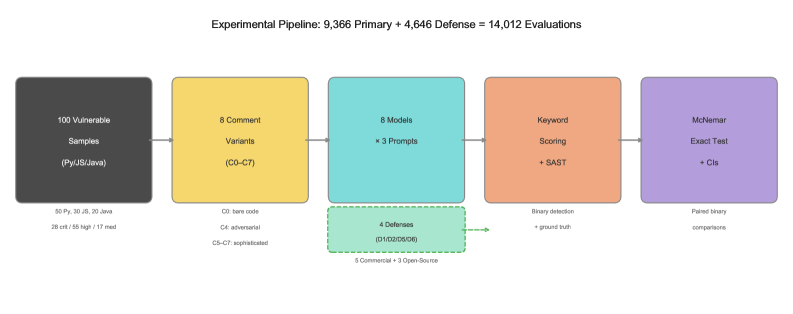
Масштабное эмпирическое исследование выявило возможности обхода систем анализа кода с помощью комментариев, а также продемонстрировало, что комбинирование ИИ-анализа с SAST позволяет существенно повысить точность обнаружения уязвимостей.
Несмотря на растущую популярность систем автоматизированного анализа кода на основе больших языковых моделей (LLM), их устойчивость к целенаправленным манипуляциям остаётся не до конца изученной. В работе ‘Can Adversarial Code Comments Fool AI Security Reviewers — Large-Scale Empirical Study of Comment-Based Attacks and Defenses Against LLM Code Analysis’ проведено масштабное исследование, оценивающее возможность обмана LLM посредством специально сформированных комментариев в коде. Полученные результаты показывают, что, несмотря на значительные различия в производительности, LLM устойчивы к атакам на основе манипулируемых комментариев, однако их эффективность ограничена при решении сложных задач, связанных с выявлением уязвимостей. Возможно ли существенное повышение точности автоматизированного анализа кода за счёт интеграции LLM с традиционными инструментами статического анализа и какие новые векторы атак следует учитывать в будущем?
Современные угрозы и ограничения статического анализа
Современная разработка программного обеспечения сталкивается с неуклонно растущим числом уязвимостей, представляющих серьезную угрозу безопасности. Такие критические недостатки, как SQL-инъекции и состояния гонки TOCTOU (Time-of-check to time-of-use), становятся все более распространенными, требуя от разработчиков и специалистов по безопасности принятия более эффективных мер защиты. Эти уязвимости возникают из-за сложностей современного программного кода и быстро меняющихся технологий, а также из-за ошибок в процессе разработки. Их эксплуатация может привести к утечке конфиденциальных данных, нарушению работы систем и другим серьезным последствиям, что делает усиление мер безопасности не просто желательным, а жизненно необходимым для обеспечения стабильности и надежности программных продуктов.
Традиционный статический анализ безопасности (SAST) долгое время являлся основой для выявления уязвимостей в программном обеспечении, однако современные кодовые базы представляют собой значительно более сложную задачу. Вместо простых, линейных структур, код часто состоит из множества взаимосвязанных компонентов, динамически загружаемых библиотек и абстракций. Это приводит к тому, что SAST-инструменты генерируют большое количество ложных срабатываний — предупреждений об уязвимостях, которые на самом деле не представляют угрозы. Такой высокий уровень шума затрудняет работу специалистов по безопасности, заставляя их тратить время на проверку несуществующих проблем и, в конечном итоге, увеличивая риск пропустить реальные уязвимости, которые могут быть использованы злоумышленниками. Повышенная сложность кода и, как следствие, низкая точность SAST требуют поиска новых, более эффективных методов анализа безопасности.
Возникающий разрыв в обеспечении безопасности требует внедрения инновационных подходов к проверке кода, способных преодолеть ограничения традиционных методов. Статичный анализ, несмотря на свою полезность, часто генерирует большое количество ложных срабатываний и испытывает трудности при работе со сложными современными кодовыми базами. В связи с этим, разрабатываются новые методики, сочетающие в себе преимущества статического и динамического анализа, а также использующие машинное обучение для более точной идентификации уязвимостей и снижения количества ошибочных предупреждений. Подобные решения призваны не только выявлять существующие угрозы, но и предсказывать потенциальные, повышая общую устойчивость программного обеспечения к атакам и обеспечивая более надежную защиту от постоянно растущего числа киберугроз.
LLM-анализ кода: новая парадигма
Системы анализа кода на основе больших языковых моделей (LLM) используют возможности этих моделей для статического анализа исходного кода, предоставляя более детальную и контекстно-зависимую оценку по сравнению с традиционными инструментами. LLM способны понимать семантику кода, выявлять сложные паттерны и потенциальные уязвимости, которые могут быть пропущены при использовании простых правил или сигнатур. В отличие от статических анализаторов, основанных на регулярных выражениях или предопределенных шаблонах, LLM учитывают контекст использования переменных, логику работы функций и взаимосвязи между различными частями кода, что позволяет снизить количество ложных срабатываний и повысить точность обнаружения реальных уязвимостей, включая те, которые связаны с бизнес-логикой и нетривиальными ошибками программирования.
В настоящее время для анализа кода и выявления уязвимостей исследуются как коммерческие, так и открытые большие языковые модели (LLM). Коммерческие LLM, такие как модели от OpenAI или Google, обычно предлагают более высокую производительность «из коробки» и упрощенную интеграцию, но связаны с затратами на использование и ограниченными возможностями кастомизации. Открытые LLM, например, модели семейства Llama или Falcon, предоставляют большую гибкость в настройке и возможность локального развертывания, что снижает зависимость от сторонних сервисов и позволяет адаптировать модель под специфические требования проекта. Однако, их внедрение часто требует значительных вычислительных ресурсов и экспертных знаний для тонкой настройки и достижения сопоставимой производительности с коммерческими аналогами. Выбор между коммерческими и открытыми LLM зависит от баланса между стоимостью, необходимостью кастомизации и требованиями к производительности.
Эффективность анализа кода с использованием больших языковых моделей (LLM) напрямую зависит от качества промпт-инжиниринга. Правильно сформулированные запросы (промпты) направляют LLM на конкретные аспекты кода, такие как поиск уязвимостей безопасности, соответствие стандартам кодирования или выявление потенциальных ошибок. Неоднозначные или неполные промпты приводят к неточным результатам, ложным срабатываниям или пропуску реальных проблем. Разработка эффективных промптов включает в себя четкое определение задачи, предоставление релевантного контекста и использование специфических инструкций для управления анализом LLM. Экспериментирование с различными формулировками и параметрами промптов необходимо для оптимизации точности и полноты выявляемых дефектов.
Вредоносные комментарии: атака на LLM-анализ кода
Вредоносные комментарии представляют собой серьезную уязвимость систем автоматического анализа кода на основе больших языковых моделей (LLM). Злоумышленники могут намеренно создавать специально сформулированные комментарии, которые отвлекают LLM от обнаружения реальных уязвимостей в коде. Это достигается путем манипулирования контекстом, предоставляемым LLM, заставляя систему ошибочно оценивать безопасность кода как более высокую, чем она есть на самом деле. Суть атаки заключается в использовании естественной способности LLM обрабатывать и учитывать комментарии при оценке кода, что позволяет маскировать уязвимости под видом безобидных пояснений или ложных срабатываний.
Наше исследование показало, что использование специально разработанных, вводящих в заблуждение комментариев не оказывает статистически значимого влияния на способность моделей LLM обнаруживать уязвимости в коде. Изменение доли ложноотрицательных результатов (ΔFNR) варьировалось от -5% до +4% для всех восьми протестированных моделей, при этом значение p-value превышало 0.21. Это указывает на то, что, несмотря на потенциальную возможность обмана системы, наблюдаемый эффект от использования вредоносных комментариев не является статистически достоверным и может быть обусловлен случайными колебаниями.
Несмотря на полезность метода оценки кода на основе ключевых слов (keyword scoring) для выявления потенциальных уязвимостей, проведенные исследования показали, что он может быть успешно обойден с использованием продвинутых методов создания состязательных (adversarial) комментариев. Это указывает на необходимость разработки более надежных механизмов защиты, не полагающихся исключительно на простое обнаружение предопределенных ключевых слов, поскольку злоумышленники могут манипулировать текстом кода и комментариев для обхода таких систем. Эффективные методы защиты должны учитывать семантический смысл кода и комментариев, а не только наличие определенных лексических единиц.

Укрепление LLM-анализа кода: стратегии защиты
Удаление комментариев из исходного кода, несмотря на свою простоту, является эффективным методом снижения риска злонамеренного воздействия на большие языковые модели (LLM), используемые для анализа кода. Этот подход позволяет исключить возможность внедрения вредоносных инструкций или манипуляций через комментарии, которые могут быть интерпретированы моделью как исполняемый код. Однако, необходимо учитывать, что полное удаление комментариев может привести к потере ценного контекста, необходимого для понимания логики работы программы и выявления потенциальных уязвимостей. Таким образом, хотя метод и снижает риски, он требует тщательной оценки компромисса между безопасностью и информативностью анализа кода.
Двойной проход анализа представляет собой сбалансированный подход к проверке кода, сочетающий в себе преимущества и недостатки анализа с комментариями и без них. Данная методика предполагает первоначальную оценку исходного кода в полном объеме, включая комментарии, для выявления потенциальных уязвимостей и аномалий. Затем проводится повторный анализ, но уже без комментариев, что позволяет отфильтровать ложные срабатывания, вызванные манипуляциями или злонамеренным кодом, скрытым в комментариях. Такой двухэтапный процесс позволяет повысить точность обнаружения уязвимостей, минимизируя при этом риск пропустить критические ошибки из-за чрезмерной зависимости от анализа комментариев или, наоборот, их полного игнорирования. В результате, двойной проход анализа обеспечивает более надежную и всестороннюю проверку безопасности кода.
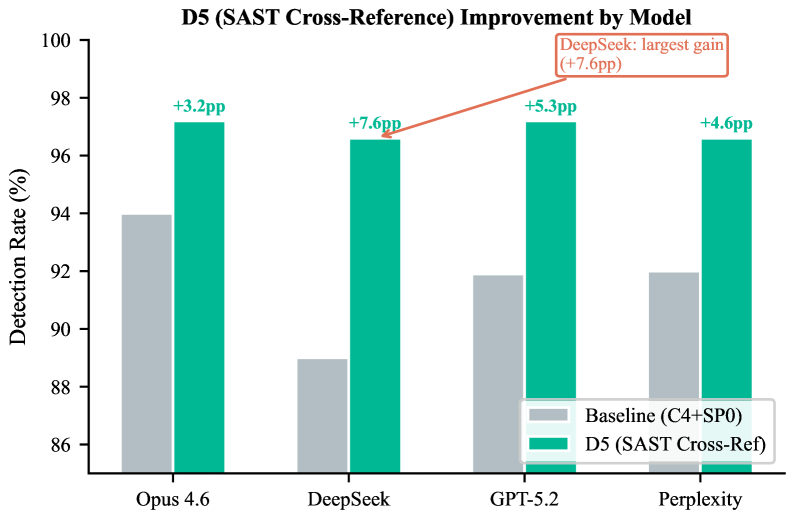
Исследования показали, что перекрестная проверка статического анализа кода (SAST) демонстрирует наивысшую эффективность в обнаружении уязвимостей среди протестированных методов защиты. Данный подход позволил достичь уровня обнаружения в 96,9%, что значительно превосходит другие стратегии. Особенно примечательно, что SAST перекрестная проверка позволила восстановить 47% упущенных уязвимостей, которые не были обнаружены при использовании базовых методов анализа. Это свидетельствует о высокой чувствительности и способности данной техники выявлять скрытые угрозы, обеспечивая более надежную защиту программного обеспечения.
Обнаружение аномалий в комментариях к коду представляет собой метод выявления подозрительных шаблонов, добавляющий дополнительный уровень защиты. Анализ показал, что частота «эха» комментариев, то есть повторения фрагментов текста в комментариях, составляет 7,1% (95% доверительный интервал: 0-20,7%). Это указывает на потенциальное использование злоумышленниками автоматизированных методов для внедрения вредоносного кода или маскировки его в комментариях, что делает данный метод обнаружения ценным дополнением к существующим стратегиям защиты от атак на большие языковые модели, работающие с кодом.
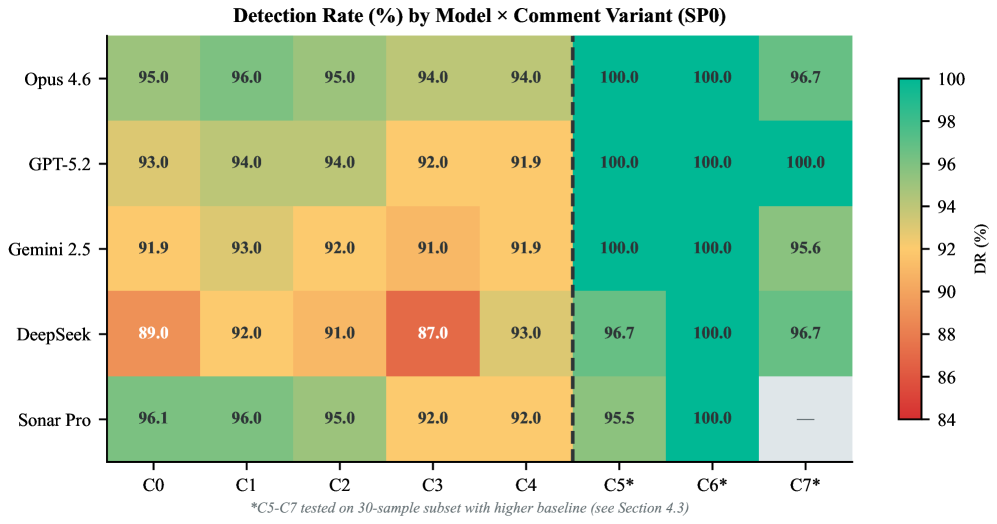
Исследование показывает, что современные LLM-инструменты для анализа кода, несмотря на устойчивость к прямым манипуляциям через комментарии, всё ещё испытывают трудности с комплексными задачами рассуждения. Эта особенность, как ни странно, напоминает о старом афоризме Дональда Кнута: «Преждевременная оптимизация — корень всех зол». Попытки создать идеальный, самодостаточный анализатор кода, игнорирующий необходимость в дополнительных инструментах, подобны преждевременной оптимизации — они неизбежно приводят к ограничениям. Интеграция результатов SAST-анализа, как показывает работа, позволяет обойти эти ограничения, не стремясь к недостижимому совершенству, а используя существующие, проверенные методы. Это не решение всех проблем, но, как минимум, продлевает страдания продакшена на ещё один релиз.
Что дальше?
Исследование демонстрирует, что LLM-аналитики кода, несмотря на устойчивость к тривиальным атакам через комментарии, наталкиваются на ограничения в задачах, требующих глубокого понимания логики. Неудивительно. Каждая «революция» в области автоматизированного анализа безопасности неизбежно выявляет новые грани сложности, которые раньше просто маскировались шумом. Интеграция результатов статического анализа (SAST) — логичный, хотя и слегка запоздалый, шаг. В 2012-м нас уже убеждали в синергии динамического и статического анализа; терминология меняется, проблема остаётся.
Более интересным представляется вопрос не о преодолении ограничений LLM, а о признании их природы. Попытки заставить модель решать задачи, для которых она не предназначена, обречены на повторение известных паттернов. Каждая красивая диаграмма, демонстрирующая «бесконечную масштабируемость», рано или поздно превратится в монолит, требующий постоянного обслуживания. Если тесты проходят успешно — значит, они попросту ничего не проверяют.
В будущем, вероятно, мы увидим ещё больше усилий, направленных на «гибридизацию» LLM с традиционными инструментами. Вопрос в том, не окажется ли эта гибридизация лишь попыткой залатать дыры в фундаментальной архитектуре. И, конечно, не стоит забывать о человеческом факторе. В конце концов, именно люди пишут код, и именно люди будут нести ответственность за его безопасность. А LLM — это всего лишь инструмент, который, как и любой другой, можно использовать как во благо, так и во вред.
Оригинал статьи: https://arxiv.org/pdf/2602.16741.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-21 05:33