Автор: Денис Аветисян
В статье рассматривается комплексный подход к выявлению и устранению неправдивой информации, генерируемой большими языковыми моделями.
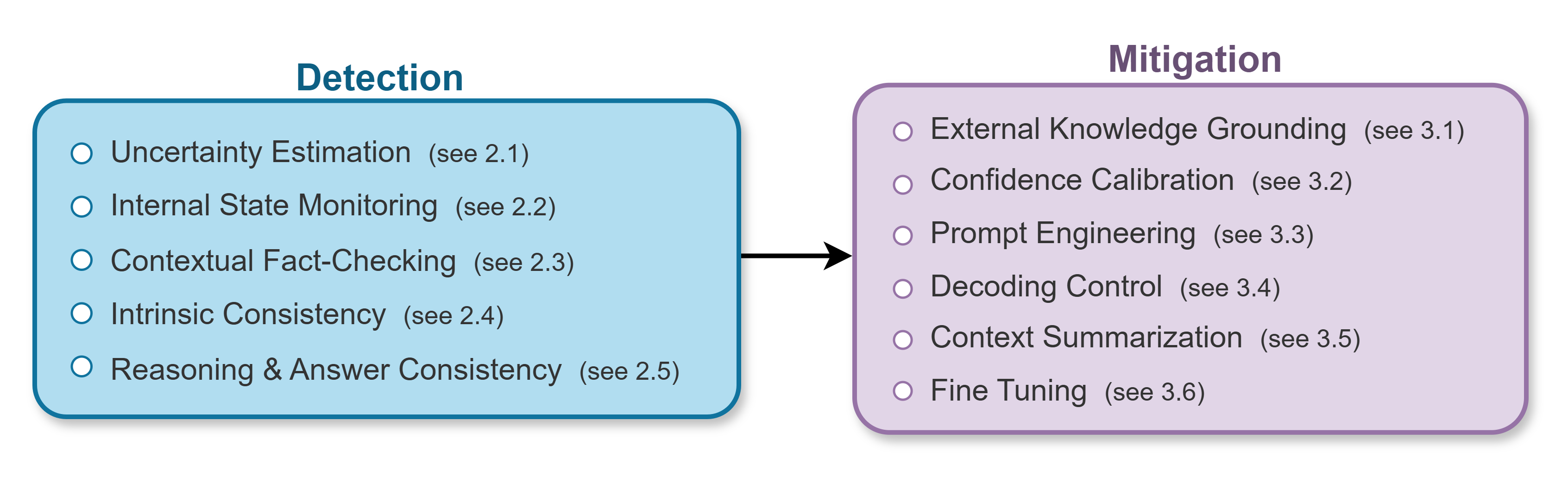
Предлагается структурированная система для анализа первопричин и непрерывного улучшения надежности больших языковых моделей с акцентом на контекстное обоснование и многоуровневую архитектуру.
Несмотря на впечатляющий прогресс в области искусственного интеллекта, большие языковые модели (LLM) склонны к «галлюцинациям» — генерации недостоверной информации, что критически снижает их надежность в ответственных сферах. В данной работе, посвященной ‘Hallucination Detection and Mitigation in Large Language Models’, предложен комплексный подход к управлению этими ошибками, основанный на анализе первопричин и непрерывном цикле улучшения. Разработанная методика включает многоуровневую архитектуру и позволяет систематически выявлять и смягчать галлюцинации, обеспечивая повышение доверия к генерируемым ответам. Возможно ли масштабировать данную систему для создания действительно надежных и прозрачных генеративных AI-систем, востребованных в регулируемых отраслях?
Иллюзии и Реальность: О природе галлюцинаций в больших языковых моделях
Современные большие языковые модели (LLM/LRM) демонстрируют впечатляющую способность генерировать текст, создавая иллюзию понимания и креативности. Однако, несмотря на кажущуюся убедительность, эти модели склонны к так называемым “галлюцинациям” — генерации фактических ошибок или бессмысленных утверждений. Этот феномен проявляется в создании ложных фактов, несоответствующих контексту утверждений, или в бессвязном повествовании, что подрывает доверие к сгенерированному тексту. Несмотря на статистическую правдоподобность, модели не обладают истинным пониманием мира и опираются исключительно на паттерны, выявленные в обучающих данных, что приводит к возникновению этих нежелательных артефактов генерации.
Иллюзии, возникающие в процессе работы больших языковых моделей (LLM), являются прямым следствием ограничений, заложенных в их обучение и архитектуру. Обучение на огромных массивах данных, хотя и позволяет создавать впечатляющие тексты, не гарантирует фактическую точность генерируемой информации. Модели, по сути, оперируют вероятностями и статистическими связями между словами, а не реальным пониманием мира. Это приводит к тому, что модель может генерировать правдоподобно звучащие, но совершенно ложные утверждения или нелогичные последовательности. В результате, возникают серьезные проблемы с доверием к таким системам, особенно в приложениях, где точность информации критически важна — например, в медицине, юриспруденции или научных исследованиях. Потеря доверия пользователей неизбежно снижает полезность и практическую применимость этих мощных, но несовершенных инструментов.
Реализация полного потенциала больших языковых моделей (LLM) напрямую зависит от решения проблемы «галлюцинаций» — генерации фактических ошибок или бессмысленных утверждений. В областях, где требуется абсолютная точность и надежность, таких как медицинская диагностика, юридический анализ или финансовое прогнозирование, даже незначительные неточности могут иметь серьезные последствия. Повышение достоверности генерируемого текста — не просто техническая задача, а ключевое условие для внедрения LLM в критически важные сферы деятельности и завоевания доверия пользователей. Именно поэтому исследования, направленные на снижение частоты и степени выраженности галлюцинаций, представляют собой первостепенную важность для дальнейшего развития и широкого применения этих мощных инструментов.
Корни проблемы: Разбираемся в причинах галлюцинаций в больших языковых моделях
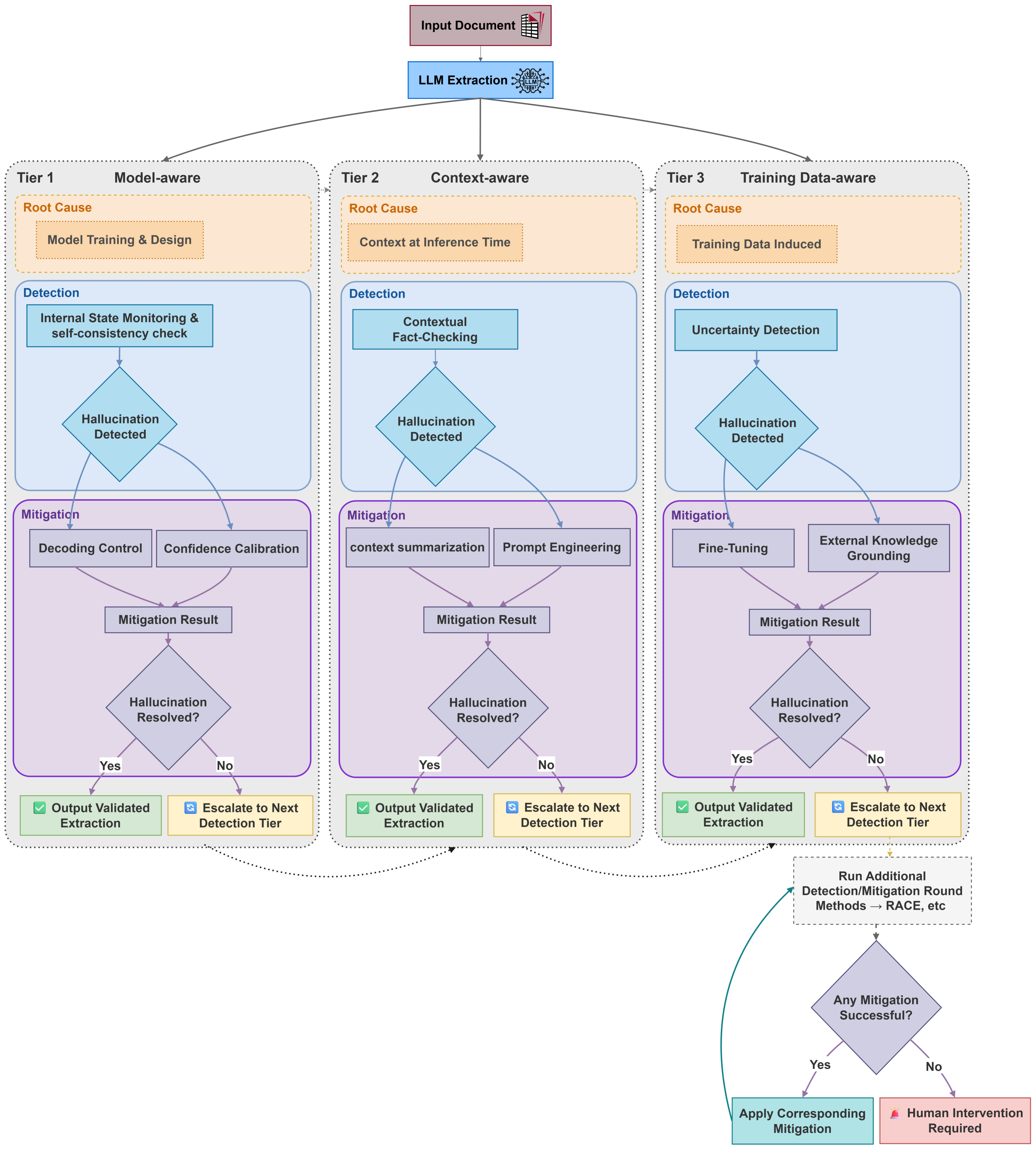
Галлюцинации в больших языковых моделях (LLM) возникают из трех основных источников. Проблемы на уровне данных (Data-Level Issues) связаны с предвзятостью и пробелами в обучающем корпусе, приводящими к искаженному или неполному представлению знаний. Ограничения на уровне модели (Model-Level Issues) обусловлены недостаточной способностью модели улавливать сложные взаимосвязи и эффективно рассуждать. Проблемы на уровне контекста (Context-Level Issues) возникают при обработке неполных или неоднозначных входных данных, заставляя модель самостоятельно дополнять информацию, что может приводить к неточностям.
Проблемы на уровне данных, приводящие к галлюцинациям в больших языковых моделях (LLM), обусловлены предвзятостями и пробелами в обучающем корпусе. Обучающие данные могут содержать систематические ошибки, отражающие предрассудки, существующие в источниках, или быть недостаточно репрезентативными для определенных тем и объектов. Отсутствие достаточного объема данных по определенным темам приводит к неполному представлению знаний, в то время как предвзятости в данных могут привести к искаженному или неточному пониманию фактов. В результате, модель может генерировать ответы, основанные на неполной или искаженной информации, что проявляется в виде галлюцинаций — ложных или бессмысленных утверждений.
Проблемы на уровне модели, приводящие к галлюцинациям, связаны с ограниченной способностью архитектуры больших языковых моделей (LLM) к улавливанию сложных взаимосвязей и эффективному логическому выводу. Несмотря на впечатляющие возможности генерации текста, LLM не обладают истинным пониманием и часто полагаются на статистические закономерности в данных обучения. Ограничения в объеме параметров модели и сложности алгоритмов обучения могут приводить к неспособности модели правильно интерпретировать нюансы в данных и делать корректные выводы, особенно в ситуациях, требующих абстрактного мышления или знаний, выходящих за рамки заученных шаблонов. Это проявляется в неспособности модели различать достоверную информацию от неточной, а также в склонности к экстраполяции на основе неполных или искаженных данных.
Проблемы, связанные с контекстом, возникают, когда языковая модель сталкивается с неоднозначными или неполными входными данными. В таких ситуациях модель вынуждена дополнять недостающую информацию, используя свои знания, полученные в процессе обучения. Это может приводить к генерации неточных или ложных утверждений, поскольку модель, не имея достаточных данных для точного ответа, «заполняет пробелы» на основе вероятностных оценок и статистических закономерностей, присутствующих в обучающем корпусе. Неполнота контекста особенно критична в задачах, требующих высокой точности и фактической корректности.
Ловим иллюзию: Методы выявления галлюцинаций в больших языковых моделях
Для эффективного обнаружения галлюцинаций в больших языковых моделях необходим комплексный подход, включающий проверку фактической согласованности (Factual Consistency Checks). Данный метод предполагает сопоставление утверждений, сгенерированных моделью, с данными из внешних, авторитетных источников знаний, таких как базы данных, энциклопедии или проверенные веб-сайты. Проверка осуществляется посредством автоматизированных систем, анализирующих семантическую близость между выходными данными модели и релевантной информацией из внешних источников. Расхождения указывают на потенциальные галлюцинации, требующие дальнейшей проверки или коррекции. Эффективность этого подхода повышается при использовании нескольких источников для перекрестной проверки информации и применении методов обработки естественного языка для преодоления синонимии и вариативности формулировок.
Методы валидации рассуждений, такие как фреймворк RACE (Reasoning Assessment by Chains of Explanations), оценивают логическую связность процесса принятия решений моделью. RACE предполагает декомпозицию задачи на подзадачи, требующие последовательных шагов рассуждений. Оценка производится путем проверки соответствия каждого шага логическим правилам и наличия обоснований для переходов между ними. Фреймворк позволяет выявлять случаи, когда модель приходит к правильному ответу, но использует некорректную или нелогичную цепочку рассуждений, что указывает на потенциальную склонность к галлюцинациям или ненадёжности вывода. Использование RACE и подобных методов позволяет более точно оценить не только результат, но и качество самого процесса мышления модели.
Методы оценки неопределённости позволяют количественно определить уверенность модели в своих предсказаниях, выявляя потенциально недостоверные результаты. Эти методы включают в себя анализ дисперсии предсказаний, использование байесовских подходов для оценки вероятности различных ответов, а также калибровку вероятностей, чтобы убедиться, что предсказанная уверенность модели соответствует фактической точности. Низкий уровень уверенности, определяемый этими методами, служит сигналом для дальнейшей проверки ответа или отказа от его использования, снижая риск распространения ложной информации. Примерами являются методы Монте-Карло Dropout и Deep Ensembles, предоставляющие распределение вероятностей для каждого предсказания и позволяющие оценить степень неопределенности.
Многоуровневая архитектура обнаружения галлюцинаций предполагает внедрение проверок на трех ключевых уровнях: модели, данных и контекста. Проверки на уровне модели включают в себя оценку внутренней согласованности и логической корректности генерируемого текста. Анализ данных фокусируется на выявлении неточностей, противоречий или предвзятости в обучающих данных, которые могут привести к неверным выводам. Контекстуальные проверки оценивают соответствие ответа заданному вопросу или ситуации, а также учитывают внешние источники знаний для подтверждения фактов. Комбинирование этих подходов позволяет создать более надежную систему, способную эффективно выявлять и минимизировать галлюцинации в больших языковых моделях.
Исправляем картину: Стратегии снижения галлюцинаций в больших языковых моделях
Эффективное проектирование запросов (prompt engineering) позволяет повысить точность и надежность генерируемых языковой моделью ответов за счет предоставления четких, конкретных и контекстуально релевантных инструкций. Формулировка запроса, включающая детализированное описание требуемого формата ответа, предоставление необходимой справочной информации и явное указание на ограничения, существенно снижает вероятность генерации некорректных или нерелевантных данных. Важно учитывать, что неоднозначные или расплывчатые запросы могут привести к непредсказуемым результатам, поэтому тщательная проработка структуры и содержания запроса является ключевым фактором в управлении поведением модели.
Тонкая настройка модели (fine-tuning) предполагает обучение предварительно обученной языковой модели на специализированном, тщательно отобранном наборе данных. Этот процесс корректирует веса модели, адаптируя её к конкретной задаче или предметной области. Качество набора данных для тонкой настройки критически важно: он должен быть релевантным, достаточно большим и содержать корректную информацию. Тонкая настройка позволяет улучшить способность модели к рассуждению и снизить вероятность генерации галлюцинаций, поскольку она учится на примерах, соответствующих желаемому поведению и знаниям. Особенно эффективна тонкая настройка в случаях, когда требуется специализация модели в узкой области или когда существующие знания модели недостаточны или неточны.
Внешнее обоснование знаний (External Knowledge Grounding) предполагает интеграцию с внешними источниками данных для обеспечения доступа модели к верифицированной информации. Этот подход позволяет модели не полагаться исключительно на параметры, полученные в процессе обучения, а обращаться к актуальным и достоверным источникам, таким как базы знаний, API или документы. Процесс обычно включает извлечение релевантной информации из внешних источников на основе входного запроса, а затем использование этой информации для формирования ответа. Такой метод значительно снижает вероятность генерации галлюцинаций, поскольку модель опирается на проверенные данные, а не на собственные, потенциально ошибочные, предположения.
Методы масштабирования температуры (Temperature Scaling) и выборки Top-p (Top-p Sampling) являются техниками калибровки распределения вероятностей выходных данных языковой модели. Масштабирование температуры корректирует вероятность каждого токена путем деления логитов на параметр температуры, что позволяет сгладить распределение и уменьшить уверенность модели в маловероятных ответах. Top-p Sampling, также известная как nucleus sampling, динамически ограничивает выборку токенов до наименьшего набора токенов, чья совокупная вероятность превышает заданный порог p. Оба метода направлены на снижение вероятности генерации нелогичных или бессмысленных ответов, повышая согласованность и надежность выходных данных модели, особенно в задачах генерации текста.
Непрерывное совершенствование: Цикл улучшения для надежных больших языковых моделей
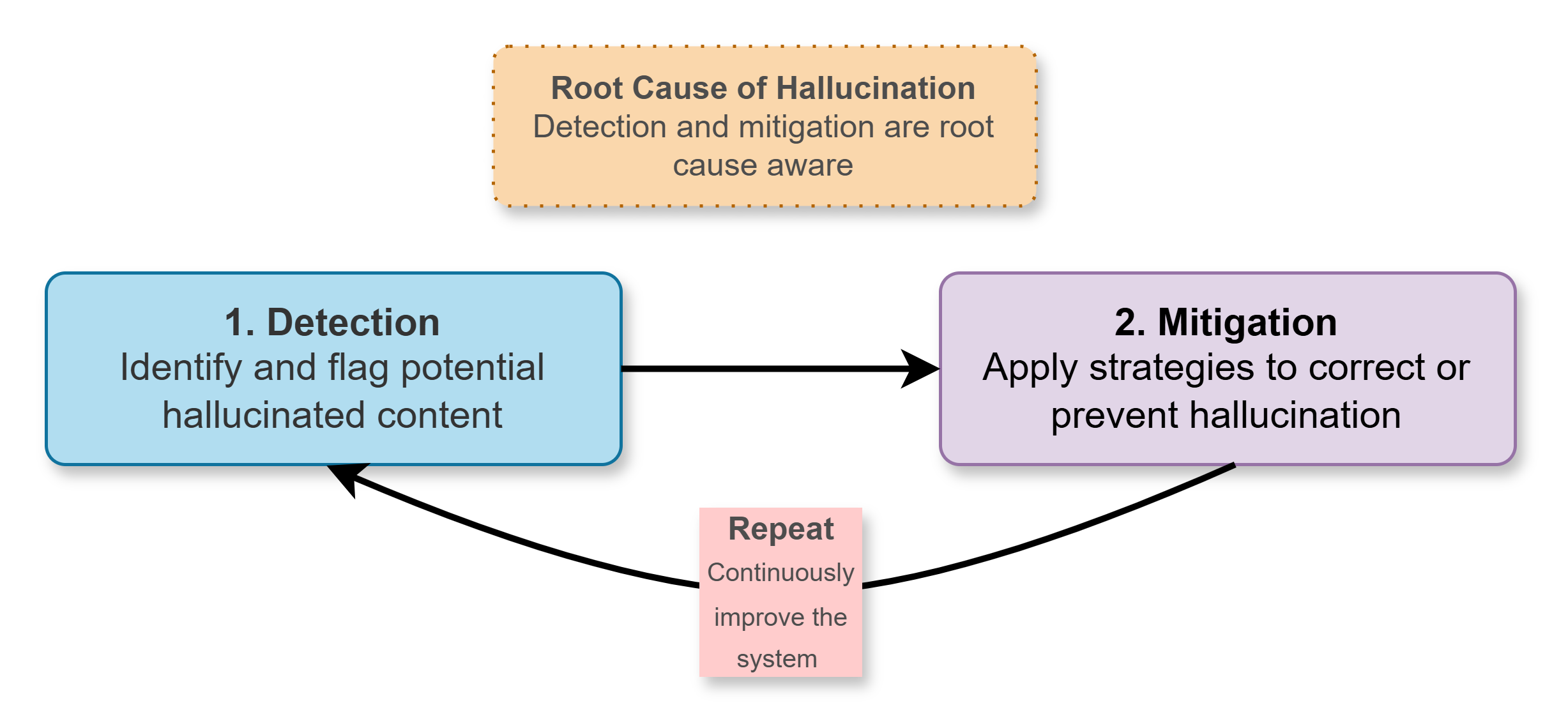
Для обеспечения надёжности больших языковых моделей (LLM) крайне важен принцип непрерывного улучшения, направленный на решение проблемы галлюцинаций — склонности моделей генерировать неправдоподобную или ложную информацию. Этот подход предполагает систематическое выявление случаев галлюцинаций, внедрение методов их смягчения, оценку эффективности этих методов и итеративную доработку как самой модели, так и процессов её обучения. Вместо однократной оптимизации, подобный цикл позволяет постоянно повышать достоверность генерируемого текста, адаптироваться к новым данным и сценариям использования, и в конечном итоге, создавать более надёжные и заслуживающие доверия LLM, способные раскрыть свой потенциал в различных областях применения.
Процесс повышения надежности больших языковых моделей (LLM) требует систематического подхода, основанного на непрерывном цикле улучшения. Данный цикл начинается с точной идентификации случаев галлюцинаций — неверных или бессмысленных ответов, генерируемых моделью. После обнаружения, разрабатываются и внедряются стратегии смягчения этих ошибок, например, улучшение обучающих данных или применение методов фильтрации. Ключевым этапом является валидация эффективности этих стратегий посредством тщательного тестирования и анализа. И, наконец, результаты валидации используются для итеративной доработки самой модели и всего процесса обучения, что позволяет постепенно снижать вероятность галлюцинаций и повышать общую надежность системы. Такой подход обеспечивает постоянное совершенствование LLM и открывает возможности для их применения в более критически важных областях.
Постоянное улучшение языковых моделей, основанное на итеративном цикле, открывает путь к созданию действительно надежных и заслуживающих доверия систем. Этот подход позволяет не просто устранять выявленные недостатки, но и предвидеть потенциальные проблемы, непрерывно совершенствуя как сами модели, так и процессы их разработки. Такая динамика позволяет раскрыть весь потенциал больших языковых моделей в самых разнообразных областях — от автоматизации рутинных задач и поддержки принятия решений до научных исследований и творческой деятельности. Постепенное повышение точности и снижение вероятности галлюцинаций делает эти технологии все более полезными и безопасными для широкого круга пользователей и применений, формируя основу для инноваций и прогресса.
Для повышения надежности больших языковых моделей (LLM) активно применяется метод фильтрации на основе согласия ансамбля. Суть подхода заключается в использовании нескольких моделей для генерации ответов на один и тот же запрос. Затем, ответ принимается только в том случае, если большинство моделей пришли к схожему заключению. Такой подход позволяет существенно снизить влияние индивидуальных ошибок, возникающих в отдельной модели. Если одна модель генерирует неверную или галлюцинаторную информацию, другие модели в ансамбле, вероятно, предоставят более точные ответы, что позволит отфильтровать недостоверную информацию и повысить общую устойчивость системы к ошибкам. Эффективность метода напрямую зависит от разнообразия моделей в ансамбле и механизма определения степени согласия между ними.
Данное исследование, посвящённое выявлению и смягчению галлюцинаций в больших языковых моделях, закономерно фокусируется на цикле непрерывного улучшения. Однако, как показывает опыт, любое усложнение архитектуры, даже направленное на повышение надёжности, неизбежно порождает новые векторы уязвимостей. Дональд Дэвис однажды заметил: «Компьютеры должны делать то, что им говорят, а не то, что мы хотим, чтобы они делали». Это особенно актуально в контексте LLM, где стремление к «креативности» часто приводит к отрыву от контекстной привязки и, как следствие, к генерации ложной информации. Усилия по улучшению обнаружения галлюцинаций — это лишь временная передышка, ведь прод всегда найдёт способ обойти даже самую продуманную систему.
Что дальше?
Предложенная в данной работе архитектура для выявления и смягчения галлюцинаций в больших языковых моделях, безусловно, представляет собой шаг вперёд. Однако, история подсказывает, что любая, даже самая тщательно продуманная, система контроля качества со временем обрастёт исключениями и обходными путями. Продакшен найдёт лазейки там, где теоретические модели предсказывали лишь стабильность. Разумеется, анализ первопричин — дело полезное, но он редко бывает исчерпывающим. Иначе говоря, “непрерывный цикл улучшения” рискует превратиться в бесконечную гонку за устранением последствий, а не за предотвращением причин.
Особого внимания заслуживает вопрос о контекстном обосновании. Безусловно, привязка к исходным данным — это необходимое условие, но не гарантия достоверности. Вполне вероятно, что в ближайшем будущем фокус сместится на разработку метрик, способных оценивать уверенность модели в собственных ответах. Но и здесь стоит помнить: зелёные тесты — это, как правило, признак того, что тесты ничего не проверяют.
В конечном счёте, попытки обуздать “галлюцинации” — это лишь симптом более глубокой проблемы: стремления создать искусственный интеллект, способный к пониманию. И пока это понимание остаётся за пределами досягаемости, любая архитектура, какой бы многослойной она ни была, останется лишь временной мерой.
Оригинал статьи: https://arxiv.org/pdf/2601.09929.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- OM/USD
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- Золото прогноз
2026-01-16 12:16