Автор: Денис Аветисян
Новый подход объединяет креативность человека и мощь искусственного интеллекта для поиска сложных случаев, способных раскрыть ограничения существующих методов оптимизации.
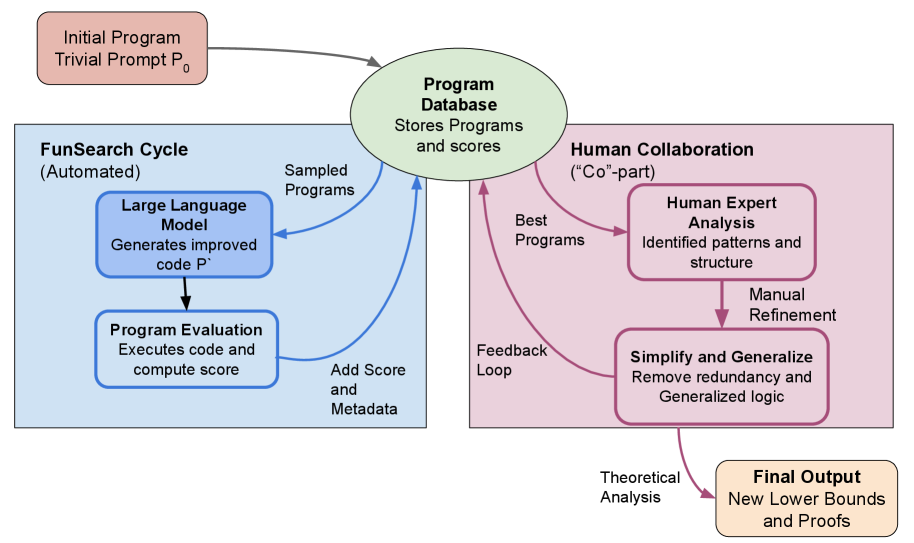
Исследование демонстрирует эффективность совместного подхода Co-FunSearch в генерации сложных экземпляров задач комбинаторной оптимизации и улучшении нижних границ.
Несмотря на значительные успехи в эвристических алгоритмах комбинаторной оптимизации, поиск примеров, демонстрирующих их пределы, остаётся сложной задачей. В работе ‘The Art of Being Difficult: Combining Human and AI Strengths to Find Adversarial Instances for Heuristics’ представлен совместный подход человека и большой языковой модели (LLM) — Co-FunSearch — для генерации сложных экземпляров задач, позволяющих выявить слабые места стандартных эвристик. Полученные результаты, включающие новые нижние оценки для задач кластеризации, упаковки и рюкзака, а также обобщения задачи Ловаша о бензине, демонстрируют, что синергия человеческой интуиции и вычислительной мощности LLM способна преодолеть многолетние барьеры. Не приведет ли это к разработке принципиально новых, более устойчивых алгоритмов комбинаторной оптимизации?
Пределы Эвристических Методов в Комбинаторной Оптимизации
Многие задачи, возникающие в реальном мире, от логистики и планирования маршрутов до распределения ресурсов и составления расписаний, относятся к классу комбинаторной оптимизации. Суть этих задач заключается в поиске наилучшего решения из огромного числа возможных комбинаций, что делает прямой перебор всех вариантов невозможным из-за экспоненциального роста вычислительных затрат. Классическим примером является так называемая «Задача о заправке», где необходимо определить оптимальную последовательность заправок для автомобиля, чтобы преодолеть заданное расстояние с минимальными затратами. Эффективное решение подобных задач требует разработки и применения специальных алгоритмов, способных быстро находить хорошие, а в идеале — оптимальные решения, несмотря на сложность и масштаб пространства поиска.
Традиционные эвристические методы, несмотря на свою скорость работы, часто демонстрируют неспособность эффективно решать сложные комбинаторные задачи. В ситуациях, когда количество возможных решений экспоненциально возрастает, эти методы могут застревать в локальных оптимумах или давать решения, далекие от оптимальных. В отличие от алгоритмов, гарантирующих нахождение наилучшего решения, эвристики полагаются на приближенные подходы и не предоставляют никаких гарантий относительно качества полученного результата. Это означает, что в критически важных приложениях, где требуется высокая точность, полагаться исключительно на эвристики может быть рискованно, и необходимо искать более надежные, хотя и вычислительно затратные, альтернативы.
Ограничения, с которыми сталкиваются традиционные эвристические методы в задачах комбинаторной оптимизации, подчеркивают необходимость разработки подходов, способных к систематическому исследованию пространства решений. Вместо случайного поиска или приближенных оценок, требуется алгоритмы, гарантирующие нахождение оптимального или, как минимум, близкого к оптимальному решения. Это достигается за счет более полного перебора возможных комбинаций, использования методов точного поиска, таких как ветви и границы, или применения сложных алгоритмов локального поиска, способных эффективно «прочесывать» пространство решений и избегать застревания в локальных оптимумах. Такой подход позволяет значительно повысить надежность и качество получаемых решений, особенно в задачах, где даже небольшое улучшение может привести к существенным экономическим или практическим выгодам.
FunSearch: LLM как Генератор Состязательных Примеров
FunSearch представляет собой новый подход к тестированию алгоритмов, использующий большие языковые модели (LLM) для генерации состязательных примеров — входных данных, специально разработанных для выявления слабых мест в эвристиках. В отличие от традиционных методов, полагающихся на случайные или созданные вручную входные данные, FunSearch использует LLM для итеративной генерации и уточнения примеров, нацеленных на максимизацию вероятности обнаружения ошибок или неоптимального поведения в тестируемой эвристике. Этот метод позволяет систематически исследовать граничные условия и скрытые уязвимости алгоритма, повышая надежность и эффективность его работы.
В FunSearch итеративное уточнение сгенерированных экземпляров является ключевым механизмом для эффективного исследования границ производительности эвристических алгоритмов. На каждом шаге, LLM генерирует входные данные, а затем, на основе результатов работы эвристики, эти данные модифицируются для усиления выявленных слабых мест. Этот процесс повторяется до тех пор, пока не будут обнаружены скрытые уязвимости или не будет достигнута оптимальная производительность эвристики. В результате, FunSearch позволяет систематически находить входные данные, которые наиболее эффективно выявляют недостатки алгоритма, в отличие от случайных или заранее заданных тестов.
В отличие от традиционных методов тестирования алгоритмов, которые часто полагаются на случайную генерацию входных данных или на создание тестов вручную, FunSearch предлагает более систематический подход к оценке. Случайные тесты могут не охватить все граничные случаи и слабые места эвристики, а ручное создание требует значительных усилий и не гарантирует полноты. FunSearch, используя LLM для генерации состязательных примеров, итеративно исследует пространство входных данных, целенаправленно выявляя ситуации, в которых эвристика работает неоптимально, что позволяет проводить более глубокий и всесторонний анализ производительности.
CoFunSearch: Совместная Работа Человека и LLM для Повышения Надежности
CoFunSearch представляет собой расширение подхода FunSearch, включающее в себя взаимодействие с экспертами-людьми на этапе генерации состязательных примеров. В отличие от полностью автоматизированного поиска, CoFunSearch позволяет людям корректировать примеры, предложенные языковой моделью, обеспечивая их сложность и содержательность. Этот процесс направлен на выявление более информативных тестовых случаев, недоступных при исключительно автоматическом поиске, и позволяет получить более глубокое понимание поведения используемых эвристик.
В CoFunSearch взаимодействие с человеком используется для улучшения качества генерируемых LLM (большой языковой моделью) тестовых примеров. Люди осуществляют проверку и доработку предложенных LLM экземпляров, обеспечивая их сложность и релевантность для оценки производительности модели. Этот процесс позволяет отсеивать тривиальные или нерепрезентативные примеры, фокусируя поиск на более информативных и сложных тестовых случаях, что способствует более глубокому анализу поведения эвристик и выявлению потенциальных уязвимостей.
Совместный подход CoFunSearch позволяет получить более глубокое понимание поведения эвристических алгоритмов и выявить потенциальные направления для их улучшения. В процессе генерации состязательных примеров, взаимодействие человека и языковой модели способствует обнаружению случаев, в которых эвристика демонстрирует неоптимальное поведение, что позволяет целенаправленно модифицировать алгоритм. Более того, данный подход обеспечивает идентификацию множества Парето — набора решений, среди которых невозможно улучшить одно значение без ухудшения другого, что является ключевым для оценки компромиссов между различными параметрами и оптимизацией производительности эвристики в различных сценариях.
В CoFunSearch для оценки качества решений и эффективного направления поиска используются нижние границы. В частности, применительно к задаче упаковки в контейнеры (Bin Packing Problem) удалось повысить нижнюю границу с 1.3 до 1.5. Это означает, что алгоритм способен более точно оценивать оптимальность найденных решений и, следовательно, эффективнее искать более качественные варианты. Повышение нижней границы является важным показателем улучшения производительности и надежности алгоритма в контексте задач оптимизации.

Оценка Производительности Алгоритмов и Понимание Компромиссов
Применение алгоритмов CoFunSearch и FunSearch к задачам, таким как задача о размещении предметов в контейнерах (Bin Packing Problem), позволяет детально изучить характеристики производительности эвристик, например, эвристики наилучшего соответствия (Best-Fit Heuristic). Исследования показали, что эффективность данной эвристики существенно зависит от порядка представления входных данных, что подчеркивает важность анализа различных сценариев в рамках случайной модели (Random Order Model). Анализ производительности в различных конфигурациях позволяет выявить сильные и слабые стороны алгоритма, а также оптимизировать его применение в практических задачах, где требуется быстрое и эффективное решение для большого объема данных. Полученные результаты способствуют более глубокому пониманию принципов работы эвристических алгоритмов и позволяют разрабатывать более эффективные стратегии для решения сложных оптимизационных задач.
Исследования эвристики наилучшего соответствия (Best-Fit Heuristic) демонстрируют её высокую чувствительность к порядку входных данных. В частности, при решении задач, таких как упаковка контейнеров (Bin Packing Problem), производительность алгоритма может значительно варьироваться в зависимости от того, в какой последовательности рассматриваются элементы. Это подчеркивает необходимость анализа алгоритма в различных сценариях, что и достигается использованием модели случайного порядка (Random Order Model). В рамках этой модели рассматривается усредненное поведение алгоритма по множеству случайных перестановок входных данных, что позволяет получить более надежную оценку его эффективности и выявить потенциальные «узкие места», связанные с определенными последовательностями входных данных. Такой подход позволяет избежать предвзятости, возникающей при оценке алгоритма на единственном, возможно, нерепрезентативном наборе данных.
Применение алгоритмов CoFunSearch и FunSearch к задаче kk-медианной кластеризации позволило установить «цену иерархии» — нижнюю границу, равную приблизительно 1.618, что соответствует золотому сечению φ. Данный результат опровергает ранее существовавшую гипотезу о полиномиальном времени работы эвристики Немузера-Ульмана, указывая на более сложную структуру оптимальных решений и необходимость разработки новых подходов к оценке качества кластеризации. Полученная нижняя граница демонстрирует, что даже при использовании эвристических методов, стоимость построения иерархических кластеров может существенно превышать оптимальное значение, что имеет важные последствия для практических приложений, требующих высокой точности и эффективности.
Исследование, представленное в данной работе, демонстрирует поиск устойчивых решений в задачах комбинаторной оптимизации, что созвучно глубокой вере Грейс Хоппер в необходимость математической точности. Она однажды сказала: «Лучший способ предсказать будущее — это создать его». Аналогично, Co-FunSearch не просто пытается найти оптимальные решения, а активно конструирует сложные, «атакующие» примеры, чтобы проверить надежность существующих эвристик. Этот подход, подобно стремлению Хоппер к созданию будущего, позволяет не только улучшить нижние границы, но и получить более глубокое понимание фундаментальных ограничений алгоритмов, особенно когда N стремится к бесконечности — что останется устойчивым? Поиск таких устойчивых элементов является ключом к созданию действительно надежных и эффективных систем.
Куда Ведет Эта Затейливая Игра?
Представленная работа, несомненно, демонстрирует элегантность симбиоза человеческого интеллекта и вычислительной мощи больших языковых моделей. Однако, следует признать, что генерация «трудных» экземпляров для эвристик — это лишь частный случай более общей задачи: верификации и улучшения алгоритмов. Истинная проверка алгоритма требует не просто поиска контрпримеров, но и доказательства его корректности или, в случае эвристик, установления границ применимости. Современные языковые модели, обладая впечатляющими возможностями в манипуляции символами, пока не способны на формальную верификацию. Следовательно, дальнейшее развитие потребует интеграции методов формальной логики и автоматического доказательства теорем.
Особый интерес представляет вопрос о масштабируемости предложенного подхода. С ростом сложности решаемых задач, пространство возможных экземпляров растет экспоненциально. Простое увеличение вычислительных ресурсов не является решением. Необходимо разрабатывать более эффективные стратегии поиска, возможно, основанные на принципах теории информации и минимаксимизации. В противном случае, мы рискуем утонуть в море «трудных» экземпляров, не получив глубокого понимания природы оптимизации.
В конечном счете, ценность предложенного метода не в самом поиске «трудных» случаев, а в углублении нашего понимания принципов, лежащих в основе эвристических алгоритмов. Настоящая элегантность заключается не в создании более сложных алгоритмов, а в поиске простых и эффективных решений. И, возможно, ключ к этому лежит в умении задавать правильные вопросы.
Оригинал статьи: https://arxiv.org/pdf/2601.16849.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-26 09:37