Автор: Денис Аветисян
Новое исследование показывает, что существующие инструменты для обнаружения изображений, сгенерированных искусственным интеллектом, часто оказываются недостаточно надежными и подвержены значительным колебаниям в производительности.
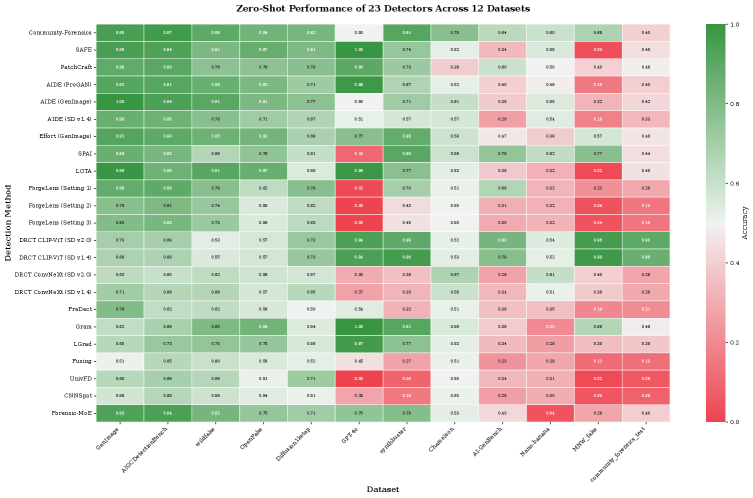
Комплексный анализ существующих моделей выявил критическую зависимость от данных, на которых они обучались, и значительные расхождения в эффективности обнаружения изображений, созданных разными генеративными моделями.
Растущее распространение изображений, сгенерированных искусственным интеллектом, ставит под угрозу достоверность цифрового контента и требует надежных методов их обнаружения. В работе, озаглавленной ‘How well are open sourced AI-generated image detection models out-of-the-box: A comprehensive benchmark study’, представлен первый всесторонний анализ производительности 16 современных детекторов в условиях «из коробки» на 12 разнообразных наборах данных, включающих около 2.6 миллионов изображений. Полученные результаты показывают значительную нестабильность оценок детекторов, существенные различия в их точности (до 37 процентных пунктов) и критическую зависимость от соответствия данных обучения реальным условиям. Возможно ли создание универсального детектора, или же специалистам необходимо тщательно подбирать инструменты в зависимости от специфики решаемой задачи?
Растущая Угроза: Синтетические Медиа и Кризис Доверия
Современные генеративные модели искусственного интеллекта демонстрируют беспрецедентный прогресс в создании фотореалистичных изображений и дипфейков, стирая границы между аутентичным и синтетическим контентом. Эти системы, опираясь на сложные алгоритмы машинного обучения, способны генерировать визуальные данные, практически неотличимые от реальных, что создает новые вызовы для верификации информации. Развитие генеративного ИИ не ограничивается простой имитацией; модели способны к творческому переосмыслению, комбинируя различные элементы и создавая совершенно новые изображения, что делает обнаружение подделок всё более сложной задачей. Данный технологический скачок открывает широкие возможности в сфере искусства и развлечений, но одновременно требует разработки эффективных механизмов защиты от злоупотреблений и распространения дезинформации.
Распространение синтетических медиа представляет собой серьезную угрозу доверию к цифровому контенту, что имеет далеко идущие последствия для информационного поля и стабильности общества. По мере совершенствования технологий создания реалистичных изображений и видеороликов, отличить подлинный контент от сгенерированного искусственным интеллектом становится все сложнее. Это открывает широкие возможности для распространения дезинформации, манипулирования общественным мнением и подрыва доверия к институтам. Утрата веры в достоверность визуальной информации может привести к поляризации общества, усилению конфликтов и даже к подрыву демократических процессов. Поэтому, вопрос обеспечения подлинности цифрового контента приобретает критическое значение для сохранения социальной стабильности и предотвращения негативных последствий распространения ложной информации.
Традиционные методы криминалистической экспертизы цифрового контента, такие как анализ метаданных и выявление несоответствий в освещении или перспективе, всё чаще оказываются неэффективными перед лицом стремительно развивающихся технологий синтетических медиа. Создаваемые генеративным искусственным интеллектом изображения и видеоролики демонстрируют поразительную реалистичность, успешно обходя стандартные алгоритмы обнаружения подделок. В связи с этим, возникает острая необходимость в разработке принципиально новых подходов к верификации цифрового контента, основанных на анализе микроскопических артефактов, оставленных алгоритмами генерации, или на использовании методов машинного обучения для выявления закономерностей, отличающих синтетические изображения от реальных. Исследования в области «цифровой криминалистики» смещаются в сторону анализа нейронных сетей, создающих контент, и выявления уязвимостей в их работе, что позволяет разрабатывать более устойчивые к подделкам методы аутентификации.
Методы Распознавания: Разбор Детекторов Подделок
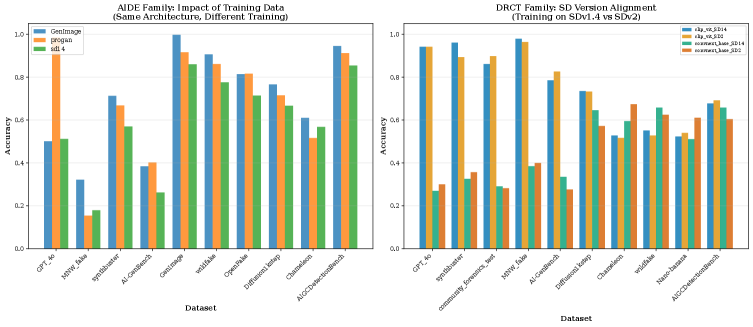
В настоящее время исследуется ряд методов обнаружения подделок изображений. Одним из подходов является PatchCraft, который анализирует текстуру изображения на уровне отдельных фрагментов (патчей), позволяя выявлять несоответствия, вызванные манипуляциями. Параллельно разрабатывается DRCT — метод, основанный на архитектуре Transformer и использующий предварительно обученные модели CLIP-ViT и ConvNeXt для извлечения признаков и классификации изображений. Использование Transformer-архитектур позволяет эффективно учитывать контекст и взаимосвязи между различными областями изображения, повышая точность обнаружения.
AIDE представляет собой гибкую платформу для обнаружения подделок, обученную на разнообразных наборах данных, сгенерированных с использованием алгоритмов ProGAN, Stable Diffusion и GenImage. Использование данных, созданных различными генеративными моделями, критически важно для повышения обобщающей способности детектора и его устойчивости к новым, ранее не встречавшимся типам подделок. Разнообразие обучающих данных позволяет AIDE эффективно выявлять артефакты и несоответствия, характерные для различных методов генерации изображений, что повышает точность и надежность системы обнаружения.
Система Community-Forensics использует ансамблевые методы, объединяя результаты работы нескольких детекторов для повышения надежности и точности выявления поддельных изображений. Такой подход позволяет компенсировать недостатки отдельных детекторов и добиться более устойчивых результатов при анализе разнообразных типов артефактов, создаваемых генеративными моделями. В результате, Community-Forensics устанавливает современный стандарт производительности (state-of-the-art benchmark) в области обнаружения сгенерированных изображений и предоставляет платформу для дальнейших исследований и сравнения различных методов.
Оценка Обобщающей Способности: Бенчмарки и Статистическая Строгость
Для объективной оценки производительности детекторов, необходимых для выявления сгенерированных ИИ изображений, используются стандартизированные оценочные наборы данных и бенчмарки. В частности, AIGCDetectionBench предоставляет унифицированную платформу для сравнения различных детекторов, а набор данных MNW_fake содержит изображения, созданные различными методами генерации, что позволяет оценить их устойчивость к различным типам подделок. Использование этих наборов данных обеспечивает воспроизводимость результатов и позволяет сравнивать эффективность различных детекторов на единой основе, что критически важно для разработки надежных систем обнаружения.
Для оценки согласованности ранжирования детекторов между различными наборами данных использовались статистические методы, такие как корреляция рангов Спирмена и тест Фридмана. Тест Фридмана выявил статистически значимые различия в производительности детекторов (p-value < 10-16), что указывает на существенные расхождения в их способности правильно классифицировать изображения на разных данных. Применение этих методов позволяет количественно оценить стабильность работы детекторов и выявить, насколько их эффективность зависит от специфики используемого набора данных.
Эффективность детекторов сгенерированного контента напрямую зависит от степени соответствия характеристик обучающей выборки анализируемым изображениям. Проведенное исследование продемонстрировало значительные различия в производительности между различными детекторами, варьирующиеся от 37.5% (AIGCDetectBenchmark_CNNSpot) до 75.0% (Community-Forensics), что составляет разницу в 37 процентных пунктов. Данный диапазон указывает на существенное влияние состава обучающей выборки на способность детектора к корректному определению сгенерированного контента и подчеркивает необходимость учета данного фактора при оценке и сравнении различных методов.
Анализ ранжирования детекторов искусственно сгенерированного контента (AIGC) показал значительную нестабильность между различными наборами данных. Коэффициент корреляции Спирмена варьировался от 0.01 до 0.87, что указывает на расхождения в оценках производительности детекторов в зависимости от используемого датасета. Несмотря на эту нестабильность, был обнаружен большой размер эффекта (Kendall’s W = 0.524), свидетельствующий о существенном согласии в общем порядке ранжирования детекторов, даже если абсолютные значения производительности отличаются между наборами данных. Это указывает на то, что хотя конкретные показатели могут меняться, общая иерархия эффективности детекторов остается относительно стабильной.
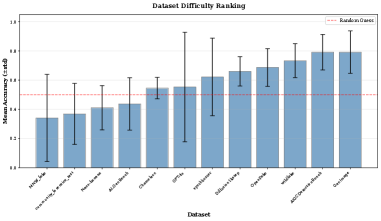
Исследование демонстрирует, что надежность детекторов изображений, сгенерированных искусственным интеллектом, крайне нестабильна при оценке на данных, отличных от тех, на которых они обучались. Эта зависимость от соответствия данных обучения и данных тестирования подчеркивает фундаментальную проблему: алгоритм, неспособный к воспроизводимым результатам, теряет свою ценность. Как однажды заметил Дэвид Марр: «Проблема состоит не в том, чтобы получить что-то работающее, а в том, чтобы понять, почему это работает». Эта фраза отражает суть представленной работы — выявление причин низкой обобщающей способности детекторов и необходимость построения более надежных, детерминированных систем, способных к корректной работе в различных условиях. Без понимания базовых принципов работы алгоритма, любое решение остаётся хрупким и ненадежным.
Куда же дальше?
Представленное исследование, тщательно задокументировав несостоятельность существующих детекторов изображений, сгенерированных искусственным интеллектом, в условиях, отличных от обучающих, лишь подтверждает давнюю истину: эвристики — это удобство, а не надежность. Выявленный разброс в производительности между различными моделями — не просто статистическая флуктуация, а симптом фундаментальной проблемы: недостаточного понимания принципов, лежащих в основе генеративных моделей и методов их обнаружения. Полагаться на эмпирические наблюдения, игнорируя математическую строгость, — все равно что строить небоскреб на песке.
Очевидно, что будущее исследований лежит в плоскости не простого увеличения размеров обучающих наборов данных, а в разработке принципиально новых подходов к обучению детекторов. Необходимо стремиться к созданию моделей, инвариантных к изменениям в стиле и содержании изображений, а не просто запоминающих особенности конкретных наборов данных. В частности, перспективным направлением представляется разработка методов, основанных на анализе фундаментальных статистических свойств изображений, а не на поиске специфических артефактов, которые могут быть легко устранены при дальнейшем совершенствовании генеративных моделей.
В конечном счете, задача обнаружения изображений, сгенерированных искусственным интеллектом, — это не просто техническая проблема, а философский вызов. Это вопрос о границах между реальностью и симуляцией, о природе творчества и о том, что значит быть человеком в эпоху искусственного интеллекта. И, как показывает данное исследование, путь к истине лежит через строгость и математическую красоту, а не через эмпирические уловки.
Оригинал статьи: https://arxiv.org/pdf/2602.07814.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-10 13:14