Автор: Денис Аветисян
Новое исследование ставит под сомнение идею о неограниченном экспоненциальном развитии возможностей ИИ.
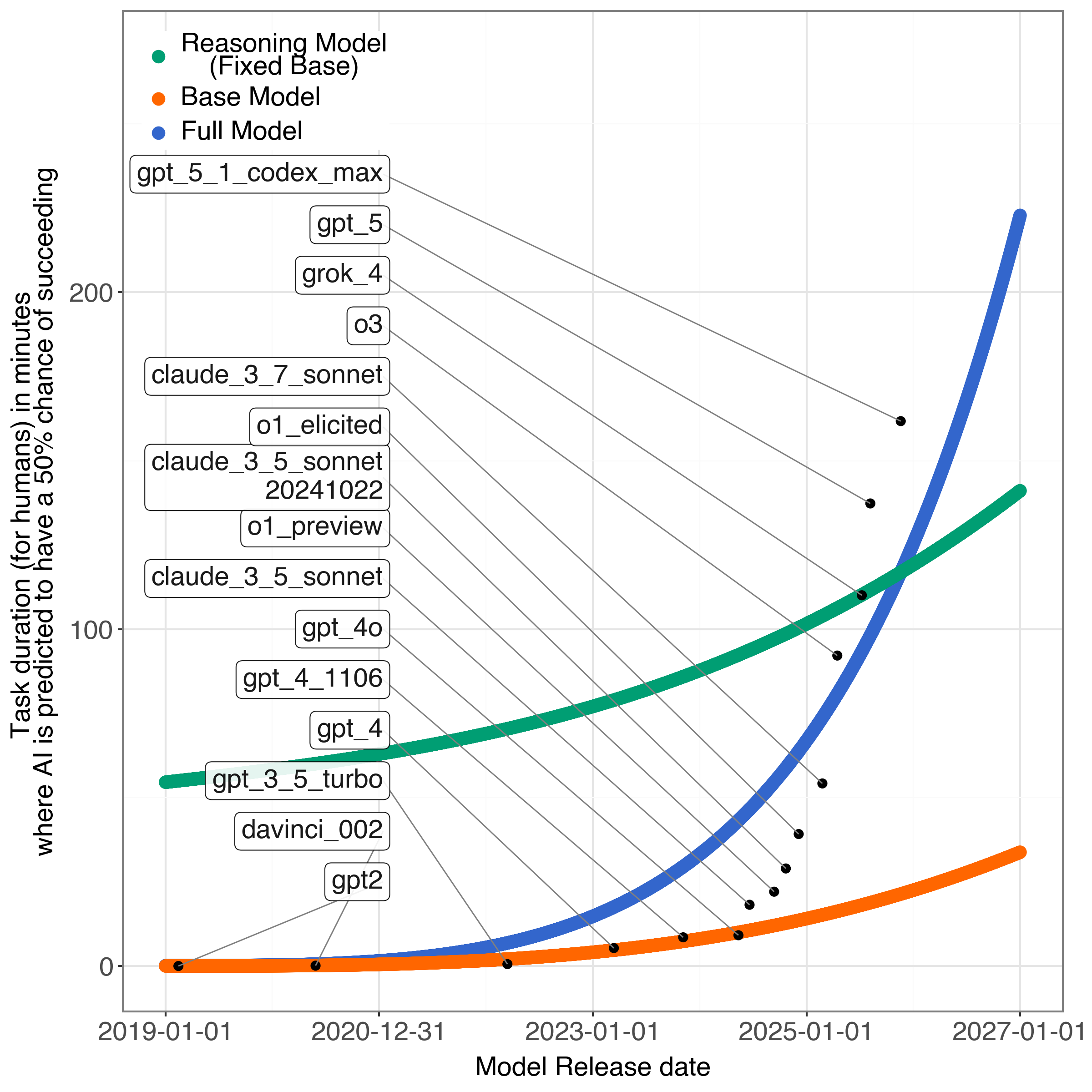
В работе предлагается альтернативная модель, учитывающая ограничения масштабирования и важность развития способности к рассуждению.
Несмотря на широкое распространение представлений об экспоненциальном росте возможностей искусственного интеллекта, эмпирические данные вызывают вопросы относительно устойчивости такой тенденции. В работе ‘Are AI Capabilities Increasing Exponentially? A Competing Hypothesis’ авторы анализируют существующие оценки и предлагают альтернативную модель, учитывающую раздельные темпы улучшения базовых и рассудочных способностей ИИ. Показано, что сигмоидальная кривая, построенная на основе имеющихся данных, уже прошла точку перегиба, что указывает на возможное замедление темпов роста в ближайшем будущем. Не является ли акцент на масштабировании базовых моделей недостаточным для дальнейшего прогресса, и какие факторы будут определять траекторию развития ИИ в долгосрочной перспективе?
Экспоненциальный рост и приближающиеся пределы ИИ
В последние годы наблюдается неоспоримый взлет возможностей искусственного интеллекта, который первоначально характеризовался экспоненциальным ростом, предсказанным исследованием METR. Данное исследование выявило, что развитие ИИ не просто линейно, а ускоряется, позволяя системам решать все более сложные задачи с возрастающей эффективностью. Этот экспоненциальный тренд проявляется в различных областях — от обработки естественного языка и компьютерного зрения до разработки автономных систем и научных открытий. Первоначальный этап развития ИИ, подтвержденный данными METR, заложил основу для текущего бурного роста, демонстрируя потенциал технологий, способных кардинально изменить многие аспекты жизни человека и промышленности.
Для количественной оценки стремительного развития искусственного интеллекта используется показатель, известный как «Горизонт 50% модели». Этот параметр отражает сложность задач, которые ИИ способен решать надежно и с приемлемым уровнем точности. Увеличение «Горизонта 50%» свидетельствует о расширении границ возможностей ИИ, демонстрируя, что системы способны успешно справляться с задачами, требующими всё более сложных когнитивных способностей и обработки информации. Фактически, данный показатель позволяет отслеживать прогресс ИИ не просто в увеличении вычислительной мощности, а в реальном улучшении способности к решению разнообразных и сложных проблем, что является ключевым индикатором приближения к более общему искусственному интеллекту.
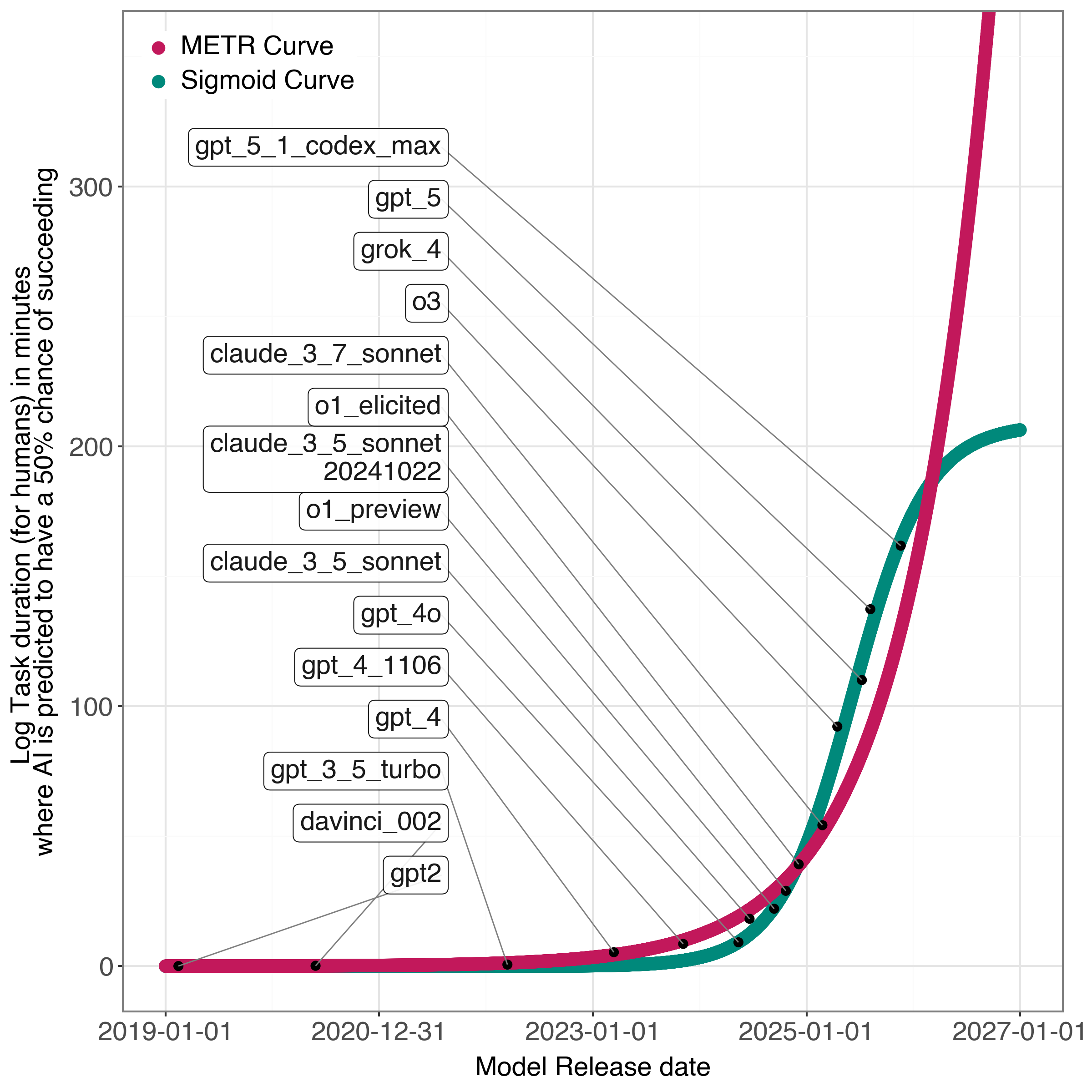
Исследование показывает, что поддержание экспоненциального роста возможностей искусственного интеллекта сталкивается с теоретическими ограничениями. В частности, анализ продемонстрировал, что использование сигмоидной функции связи в моделях прогнозирования обеспечивает более низкую среднеквадратичную ошибку MSE по сравнению с традиционными экспоненциальными моделями. Это указывает на то, что, хотя первоначальный прогресс в области ИИ действительно характеризовался экспоненциальным ростом, дальнейшее улучшение производительности может потребовать перехода к более сложным, нелинейным подходам, способным точнее моделировать реальные ограничения и паттерны данных. Полученные результаты подчеркивают важность выбора оптимальной математической модели для прогнозирования развития ИИ, учитывая, что экспоненциальная модель может оказаться неадекватной для описания долгосрочных тенденций.
Разделение возможностей: базовые навыки и рассуждения
Исследование METR предполагает, что общая способность больших языковых моделей (LLM) не является единым целым, а представляет собой комбинацию фундаментальных “Базовых Возможностей LLM”, напрямую зависящих от объема обучающих данных и масштаба модели. Эти базовые возможности включают в себя, например, способность к прогнозированию следующего токена, пониманию синтаксиса и семантики языка, а также запоминание фактов, извлеченных из обучающего корпуса. Увеличение объема данных и количества параметров модели, как правило, приводит к улучшению этих базовых возможностей, однако, согласно исследованию, это не всегда напрямую коррелирует с улучшением более сложных когнитивных функций, таких как логическое мышление и решение проблем.
Недавний прогресс в области искусственного интеллекта обусловлен не только увеличением размеров моделей и объемов данных для обучения, но и развитием так называемых “способностей к рассуждению” — умения выполнять логические выводы. Это проявляется в улучшении способности моделей решать задачи, требующие дедукции, индукции и абдукции, а также в более эффективном применении знаний к новым ситуациям. Важно отметить, что развитие способностей к рассуждению позволяет повысить производительность моделей без необходимости экспоненциального увеличения их масштаба и объема данных, что делает этот аспект особенно значимым для дальнейшего развития ИИ.
Разделение базовых возможностей и способностей к рассуждению имеет принципиальное значение, поскольку развитие последних предоставляет возможность повышения производительности искусственного интеллекта без необходимости неограниченного увеличения объемов обучающих данных и количества параметров модели. Традиционно, улучшение показателей больших языковых моделей (LLM) связывалось исключительно с масштабированием, однако появление способностей к логическому выводу демонстрирует альтернативный путь развития, позволяющий достигать более высоких результатов при фиксированных вычислительных ресурсах и объемах данных. Это означает, что дальнейший прогресс в области ИИ может быть достигнут не только за счет увеличения размера моделей, но и за счет совершенствования алгоритмов и методов, обеспечивающих более эффективное использование имеющихся ресурсов.
Мультипликативная модель: когда рассуждения усиливают возможности
Мультипликативная модель предполагает, что общая производительность ИИ определяется не суммой базовых возможностей языковой модели (LLM) и способностей к рассуждению, а их произведением. В отличие от аддитивных моделей, где улучшение одного компонента линейно увеличивает общую производительность, мультипликативная модель утверждает, что способности к рассуждению выступают в роли усилителя, умножая эффективность базовой LLM. Это означает, что даже небольшое улучшение в способностях к рассуждению может привести к значительному увеличению общей производительности ИИ, если базовая LLM уже обладает определенным уровнем возможностей. Математически это можно представить как: ОбщаяПроизводительность = БазоваяLLM * Рассуждение, где каждая переменная представляет собой количественную оценку соответствующей способности.
Наблюдения показывают, что возможности логического вывода и рассуждений способны значительно усиливать эффективность базовых языковых моделей. Этот эффект проявляется в том, что улучшение способности ИИ к логическому мышлению приводит к непропорционально большему увеличению общей производительности, чем простое увеличение размера или параметров языковой модели. Фактически, способность к рассуждению выступает в роли катализатора, позволяя языковым моделям более эффективно использовать имеющиеся знания и данные для решения сложных задач и генерации более точных и осмысленных ответов. Эмпирические данные демонстрируют, что даже небольшие улучшения в способности к рассуждению могут приводить к существенному повышению точности и надежности ИИ-систем.
Для подгонки мультипликативной модели к эмпирическим данным используются передовые статистические методы, включая линейную регрессию и функции B-сплайнов. В качестве эталонного показателя эффективности применялась METR экспоненциальная регрессия, которая демонстрирует коэффициент детерминации R^2 равный 0.98. Высокое значение R^2 указывает на то, что модель хорошо описывает наблюдаемые данные и позволяет с высокой точностью прогнозировать общую производительность ИИ, учитывая как базовые возможности языковых моделей, так и их способность к рассуждениям.
Эмпирическая проверка и разнообразие задач
Исследование METR использует разнообразные семейства задач — ‘HCAST’, ‘RE-Bench’ и ‘SWAA’ — для всесторонней оценки производительности ИИ в различных областях. Семейство ‘HCAST’ включает задачи, связанные с безопасностью и анализом угроз, требующие от моделей способности к обнаружению аномалий и реагированию на кибератаки. ‘RE-Bench’ охватывает задачи, связанные с повторным использованием кода и рефакторингом, оценивая способность моделей понимать и модифицировать существующий программный код. Наконец, ‘SWAA’ фокусируется на задачах, связанных с анализом и автоматизацией программного обеспечения, включая обнаружение уязвимостей и генерацию тестовых примеров. Использование этих различных семейств задач позволяет получить более полную и репрезентативную оценку возможностей ИИ, чем при использовании только одного типа задач.
Набор задач, используемый в исследовании METR, охватывает широкий спектр компетенций, включая задачи из области кибербезопасности и разработки программного обеспечения. Такое разнообразие позволяет оценить производительность ИИ не в рамках узкой специализации, а в более реалистичном и представительном контексте, имитирующем широкий спектр практических приложений. Оценка проводится по различным типам задач, что позволяет выявить сильные и слабые стороны моделей ИИ в различных областях и обеспечить более объективную оценку их общей эффективности.
Статистическая оценка модели, основанная на метрике логарифмической вероятности (Log-Likelihood), использовалась для определения наилучшего соответствия мультипликативной модели наблюдаемым данным. Для оценки качества соответствия применялась функция потерь среднеквадратичной ошибки (Mean Squared Error), при этом минимальное значение MSE было достигнуто при использовании сигмоидной функции связи. MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2, где y_i — наблюдаемое значение, а \hat{y}_i — прогнозируемое значение.
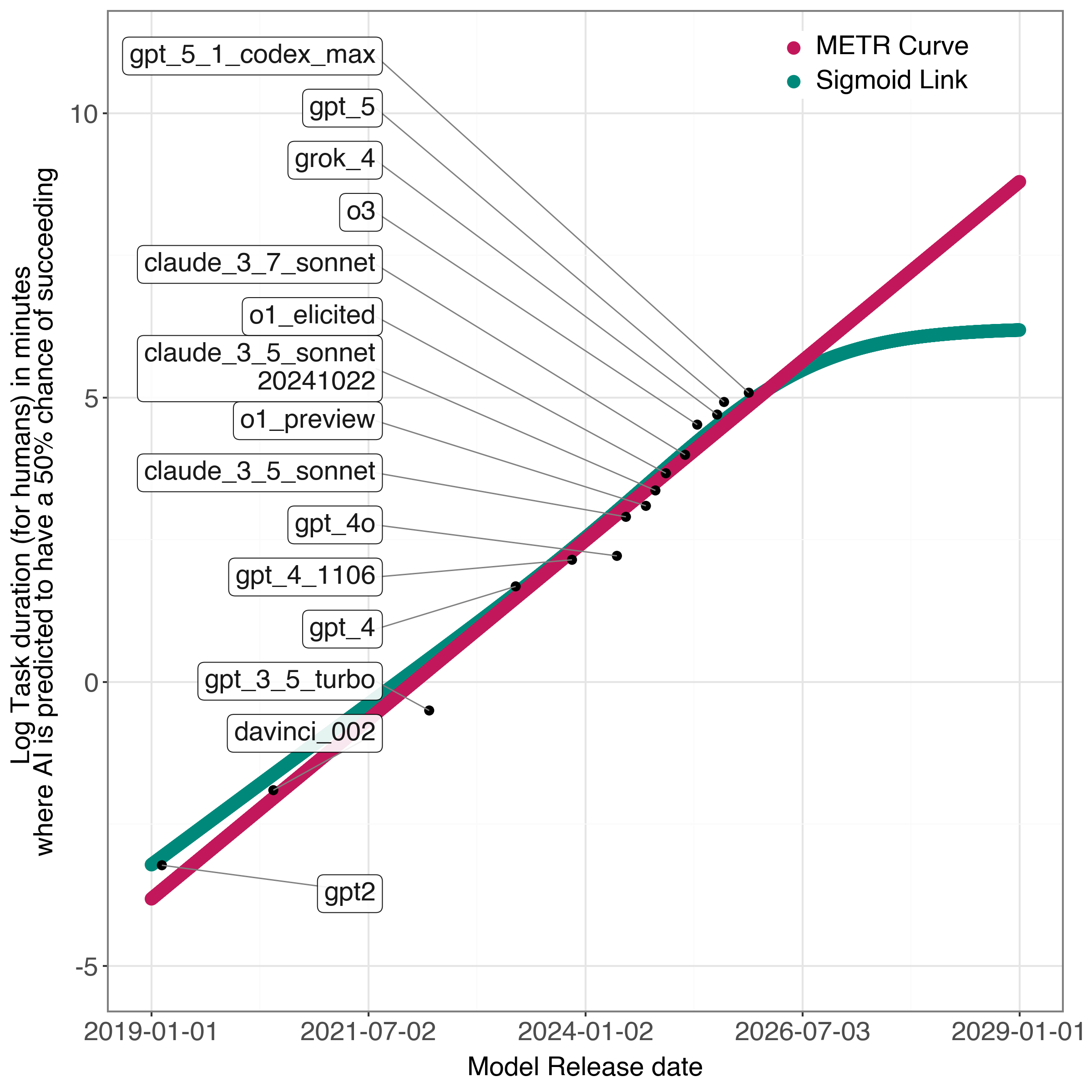
Последствия для будущего развития ИИ
Если мультипликативная модель окажется верной, дальнейший прогресс в области искусственного интеллекта будет определяться не столько увеличением объемов данных и масштаба моделей, сколько совершенствованием способностей к рассуждению. Данное предположение указывает на то, что простое наращивание вычислительных мощностей и данных может столкнуться с закономерным пределом, в то время как акцент на разработке более эффективных алгоритмов логического вывода и анализа позволит добиться существенного качественного скачка. Исследования в этом направлении подразумевают поиск новых архитектур и методов, позволяющих ИИ не просто распознавать закономерности в данных, но и делать обоснованные выводы, планировать действия и решать сложные задачи, требующие абстрактного мышления и критической оценки информации.
Предполагаемый переход к насыщению базовых возможностей искусственного интеллекта обуславливает необходимость переориентации исследований на разработку более эффективных и устойчивых алгоритмов рассуждений. Вместо дальнейшего увеличения масштабов данных и моделей, акцент смещается на оптимизацию процессов логического вывода, анализа и принятия решений. Разработка таких алгоритмов позволит ИИ не просто обрабатывать огромные объемы информации, но и извлекать из них значимые закономерности, делать обоснованные прогнозы и решать сложные задачи, требующие гибкости и адаптивности. Это предполагает поиск новых архитектурных подходов, направленных на повышение эффективности рассуждений, что, в свою очередь, может обеспечить дальнейший прогресс в области искусственного интеллекта даже при ограниченных ресурсах.
В свете прогнозируемого замедления темпов развития базовых возможностей искусственного интеллекта, дальнейший прогресс, вероятно, будет зависеть от поиска новых архитектурных решений, ориентированных на повышение эффективности рассуждений. Анализ данных указывает на потенциальную точку перегиба в развитии базовых способностей, ожидаемую к 21 ноября 2024 года, после которой простое увеличение масштаба моделей и объемов данных может принести все меньше пользы. Более того, предполагается, что критическим станет развитие именно способности к логическим умозаключениям и анализу, с прогнозируемой датой перегиба для этой функциональности — 6 июня 2026 года. В связи с этим, акцент исследований смещается в сторону алгоритмов, способных эффективно обрабатывать информацию и делать обоснованные выводы, а не только запоминать и воспроизводить паттерны.
Исследование ставит под сомнение распространённое мнение о неограниченном экспоненциальном росте возможностей искусственного интеллекта. Авторы предлагают взглянуть на текущую ситуацию сквозь призму сигмоидной кривой, указывая на неизбежность достижения плато. Это напоминает о том, что любые технологические прорывы имеют свои пределы, и слепое масштабирование моделей не является панацеей. Как заметил Карл Фридрих Гаусс: «Если бы математики могли придумать, что делать с бесконечностью, то они бы это сделали». Действительно, бесконечный рост в реальности невозможен, и важно фокусироваться на качественных улучшениях, таких как развитие способности к рассуждению, которое, согласно исследованию, играет ключевую роль в последних достижениях в области больших языковых моделей.
Что дальше?
Представленные рассуждения о сигмоидальной природе прогресса в области ИИ, вероятно, вызовут у многих приступы ностальгии по временам, когда каждая новая модель была “революцией”. Однако, скорее всего, сейчас это назовут “AI” и получат инвестиции, игнорируя неизбежность насыщения. Важно помнить, что за каждым графиком экспоненциального роста скрывается куча технического долга — тот самый, что когда-то был простым bash-скриптом, а теперь требует команды инженеров. Особый интерес представляет акцент на рассуждениях как ключевом факторе, ведь, судя по всему, простое масштабирование моделей достигло своего предела.
Очевидно, что реальный прогресс потребует не только увеличения количества параметров, но и фундаментальных прорывов в архитектуре и алгоритмах обучения. Попытки обойти ограничения, связанные с «горизонтом модели», могут привести к появлению новых, ещё более хрупких конструкций, которые сломаются в самый неподходящий момент. Документация, как всегда, соврет, а ответственность переложат на пользователя.
Начинают подозревать, что все эти разговоры об «общем искусственном интеллекте» — просто способ оправдать бесконечное потребление вычислительных ресурсов. В конечном итоге, технологический долг — это просто эмоциональный долг с коммитами. И когда-нибудь, когда всё сломается, кто-то вспомнит об этой статье с циничной усмешкой.
Оригинал статьи: https://arxiv.org/pdf/2602.04836.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-05 13:43