Автор: Денис Аветисян
Система AlphaResearch демонстрирует способность генерировать и верифицировать алгоритмы, превосходящие решения, созданные человеком.
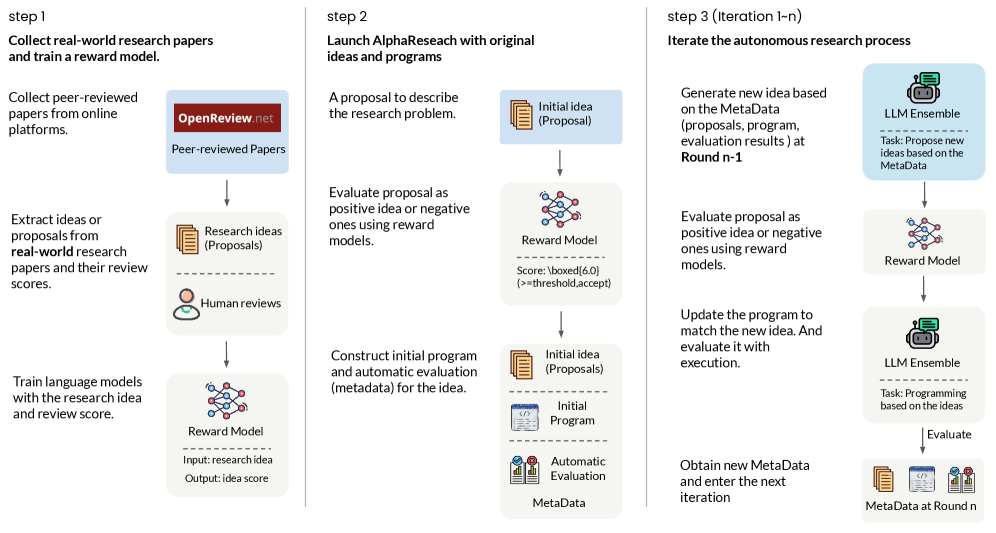
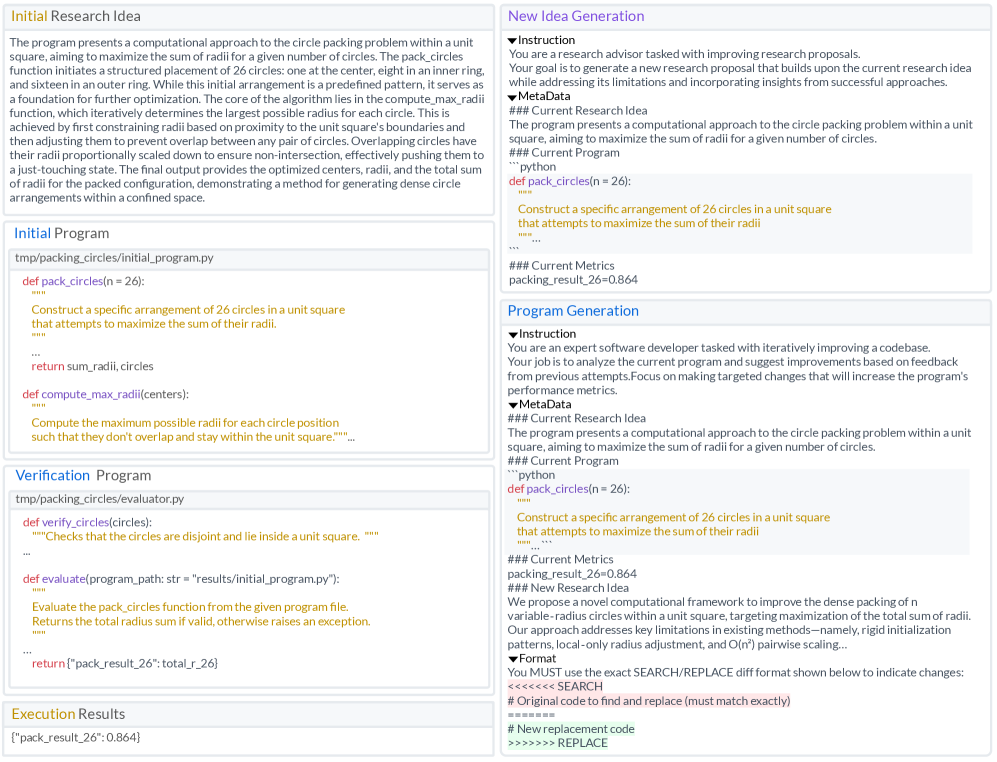
AlphaResearch – автономный агент, сочетающий генерацию идей с помощью языковых моделей, программную верификацию и симуляцию экспертной оценки, что позволяет обнаруживать новые алгоритмы.
Несмотря на значительный прогресс в решении сложных задач, большие языковые модели (LLM) всё ещё испытывают трудности в области самостоятельных научных открытий. В данной работе представлена система ‘AlphaResearch: Accelerating New Algorithm Discovery with Language Models’, автономный агент, предназначенный для поиска новых алгоритмов в условиях открытых задач, сочетающий генерацию идей LLM с программной верификацией и симуляцией экспертной оценки. AlphaResearch продемонстрировала способность находить алгоритмы, превосходящие результаты, полученные человеком, на ряде задач, включая достижение лучших показателей в задаче упаковки окружностей по сравнению с существующими решениями и алгоритмом AlphaEvolve. Какие ещё ограничения необходимо преодолеть для создания полностью автономных систем, способных к настоящим научным прорывам?
Автоматизация Научного Поиска: Преодолевая Ограничения Человеческого Разума
Традиционный научный прогресс часто сдерживается когнитивными искажениями и масштабом задач. Существующие методы могут оказаться неэффективными в работе со сложными системами и огромными пространствами решений. Современные исследования требуют методологий, систематически исследующих алгоритмы и решения. Автоматизированные подходы, обходящие ограничения человеческого восприятия, становятся всё более актуальными. Такой подход позволяет увидеть закономерности, проявляющиеся не в результате сознательного поиска, а как побочный эффект беспристрастного исследования – не диагностику, а вскрытие чёрного ящика.
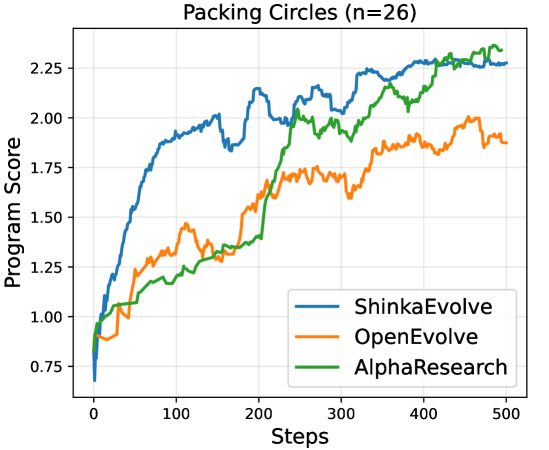
AlphaResearch: Автономный Агент Научных Открытий
AlphaResearch – это автономный агент, генерирующий, проверяющий и оценивающий исследовательские предложения без участия человека. В отличие от традиционных систем, полагающихся на ручную оценку, AlphaResearch автоматизирует весь процесс – от формирования гипотез до оценки их значимости. Ключевым компонентом является LLM Idea Generation для формулирования гипотез, включающее генерацию и предварительную фильтрацию идей. Затем гипотезы подвергаются Program-Based Verification для обеспечения логической непротиворечивости и соответствия научным принципам. Для обеспечения объективной оценки используется Peer Review Simulation, эмулирующая процесс рецензирования, оценивая гипотезы по новизне, значимости и методологической строгости.
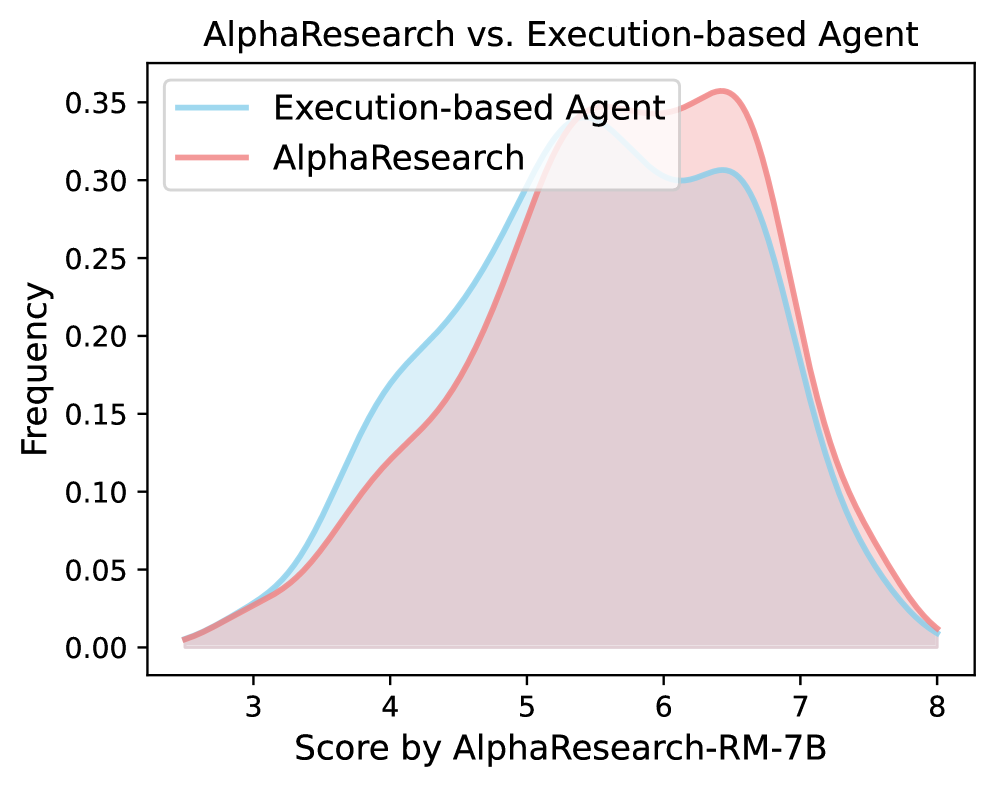
Симуляция Экспертизы: Модель Вознаграждения
Симуляция экспертной оценки строится на использовании Модели Вознаграждения (AlphaResearch-RM-7B), обученной на реальных данных экспертных оценок, что обеспечивает высокую достоверность результатов. Эта модель автоматизирует оценку научных работ, имитируя поведение экспертов. Программное вознаграждение, основанное на успешном выполнении кода, служит объективным дополнением к субъективным оценкам. Успешное выполнение кода подтверждает работоспособность и корректность подхода, снижая предвзятость. Двойной подход – симулированное рецензирование и автоматизированная валидация – минимизирует предвзятость и максимизирует надёжность оценки.

Новые Алгоритмы и Эталонные Результаты: Взлом Ограничений
AlphaResearch разработал новый алгоритм упаковки кругов, превосходящий существующие решения. Алгоритм демонстрирует способность превосходить человеческие возможности в определенных задачах, подтверждаясь результатами тестирования на стандартных наборах данных. В число решенных задач входят как классическая задача упаковки кругов, так и решение неравенства третьей автокорреляции. Алгоритм использует подход, основанный на вознаграждении за исполнение, эффективно находя оптимальные решения в сложных пространствах поиска. Результаты указывают на новую парадигму в разработке алгоритмов – автоматизированный подход, превосходящий человеческую экспертизу.
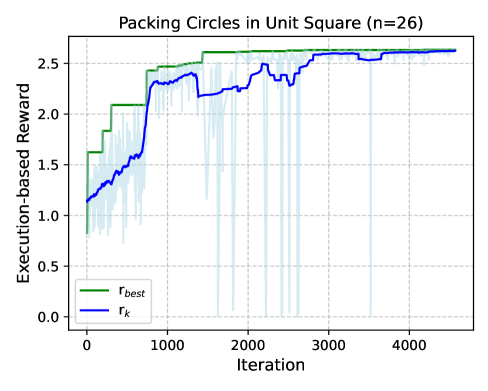
Будущее Автоматизированных Научных Открытий: Расширяя Границы Знания
Данная работа демонстрирует потенциал полностью автоматизированного научного открытия, ускоряя инновации в различных дисциплинах. Система AlphaResearch способна самостоятельно формулировать гипотезы, проектировать эксперименты и анализировать данные, минимизируя необходимость участия человека. Будущие исследования будут сосредоточены на масштабировании AlphaResearch для решения более сложных проблем и интеграции с существующей научной инфраструктурой. Особое внимание будет уделено улучшению способности системы к обобщению знаний и адаптации к новым областям. Планируется разработка интерфейсов для эффективного взаимодействия с учеными, позволяющих им совместно работать над сложными задачами.
В конечном итоге, предполагается создание будущего, в котором агенты искусственного интеллекта сотрудничают с учеными, расширяя границы знания и решая мировые проблемы. Разработка подобных систем требует не только продвинутых алгоритмов, но и глубокого понимания научного процесса и критического мышления.
Исследование, представленное в AlphaResearch, демонстрирует, как искусственный интеллект способен не просто обрабатывать информацию, но и создавать принципиально новые алгоритмы, превосходящие человеческие решения в определенных задачах. Это подтверждает мысль Карла Фридриха Гаусса: «Если бы кто-нибудь спросил меня, в чём заключается самое важное, что я узнал в математике, я бы сказал: не бойтесь трудностей, а смело идите к ним». AlphaResearch, используя комбинацию языковых моделей и программной верификации, эффективно обходит традиционные ограничения, подобно тому, как Гаусс решал сложнейшие математические задачи. Система, имитируя процесс рецензирования, подтверждает свою состоятельность и открывает перспективы для автоматизированных научных открытий, где ключевым элементом является преодоление препятствий и поиск новых решений.
Что дальше?
Представленная работа, по сути, лишь первый шаг к созданию системы, способной не просто имитировать научный поиск, но и превосходить его. Очевидно, что текущие ограничения языковых моделей, их склонность к галлюцинациям и неспособность к истинному пониманию, требуют дальнейшего преодоления. Однако, именно эти недостатки и открывают наиболее интересные направления для развития. Вместо попыток создания «идеального» ИИ-учёного, представляется более перспективным исследование методов контролируемого хаоса, позволяющих использовать ошибки и неточности в качестве источника новых гипотез.
Следующим этапом, вероятно, станет разработка более надёжных механизмов верификации алгоритмов, не полагающихся исключительно на симуляцию рецензирования. Реальное тестирование в разнообразных, непредсказуемых условиях, а также интеграция с физическими системами, станет настоящим испытанием для созданных алгоритмов. Возникает вопрос: способна ли такая система самостоятельно определить границы своей компетентности, и, главное, признать собственную неправоту?
В конечном итоге, успех подобных исследований зависит не столько от создания «умных» алгоритмов, сколько от понимания природы интеллекта как такового. Попытка автоматизировать научный поиск – это, по сути, попытка реверс-инжиниринга самой реальности. И, как показывает опыт, наиболее интересные открытия случаются тогда, когда правила перестают работать.
Оригинал статьи: https://arxiv.org/pdf/2511.08522.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2025-11-12 12:44