Автор: Денис Аветисян
Новое исследование показывает, как современные языковые модели, обученные на специализированных данных, могут быть использованы для раннего выявления признаков болезни Альцгеймера.

Оценка возможностей тонкой настройки больших языковых моделей, анализа представлений и синтеза данных для улучшения обнаружения болезни Альцгеймера.
Ранняя диагностика болезни Альцгеймера остается сложной задачей, особенно из-за ограниченности размеченных данных. В работе, озаглавленной ‘What Do LLMs Know About Alzheimer’s Disease? Fine-Tuning, Probing, and Data Synthesis for AD Detection’, исследуется возможность применения больших языковых моделей (LLM) для выявления этого заболевания. Показано, что тонкая настройка LLM, анализ внутренних представлений и новый метод синтеза данных с использованием лингвистических маркеров позволяют добиться существенного улучшения в обнаружении болезни Альцгеймера. Какие еще механизмы кодирования знаний в LLM могут быть использованы для решения задач медицинской диагностики и прогнозирования?
Ранние Лингвистические Маркеры Когнитивных Нарушений: Начало Поиска Истины
Болезнь Альцгеймера представляет собой серьезную медико-социальную проблему, требующую разработки эффективных методов ранней диагностики. Своевременное выявление заболевания критически важно, поскольку позволяет начать терапию на ранних стадиях, что потенциально замедляет прогрессирование когнитивных нарушений и улучшает качество жизни пациентов. Отсутствие простых и доступных методов диагностики на начальных этапах развития болезни Альцгеймера обуславливает необходимость поиска новых биомаркеров и подходов, способных выявить признаки заболевания задолго до проявления очевидных симптомов деменции. Актуальность ранней диагностики подчеркивается растущей распространенностью болезни Альцгеймера в стареющем обществе и значительным экономическим бременем, которое она налагает на системы здравоохранения.
Незначительные изменения в речи, проявляющиеся в виде пауз, повторений и затруднений в подборе слов, зачастую предшествуют явным признакам когнитивного снижения, что делает их ценным индикатором на ранних стадиях развития нейродегенеративных заболеваний, таких как болезнь Альцгеймера. Исследования показывают, что эти лингвистические маркеры могут проявляться задолго до того, как традиционные нейропсихологические тесты выявляют заметные нарушения памяти или мышления. Анализ спонтанной речи, осуществляемый с помощью передовых методов обработки естественного языка, позволяет выявлять эти тонкие изменения, предоставляя возможность для более ранней диагностики и, как следствие, более эффективного вмешательства и управления заболеванием. Обнаружение этих изменений открывает перспективы для разработки неинвазивных и объективных инструментов скрининга, способных значительно улучшить качество жизни пациентов и их семей.
Традиционные методы оценки когнитивных функций, такие как нейропсихологическое тестирование и клинические интервью, зачастую сопряжены с субъективностью интерпретации результатов и требуют значительных временных затрат как от медицинского персонала, так и от пациентов. Эта сложность стимулирует активный поиск автоматизированных и основанных на анализе данных подходов к ранней диагностике когнитивных нарушений. Использование алгоритмов машинного обучения и обработки естественного языка позволяет выявлять едва заметные изменения в речи и тексте, которые могут предшествовать клинически проявляемым симптомам, открывая возможности для более объективной и оперативной оценки когнитивного состояния и своевременного вмешательства.
Тонкая Настройка Больших Языковых Моделей для Выявления Болезни Альцгеймера: Поиск Оптимального Решения
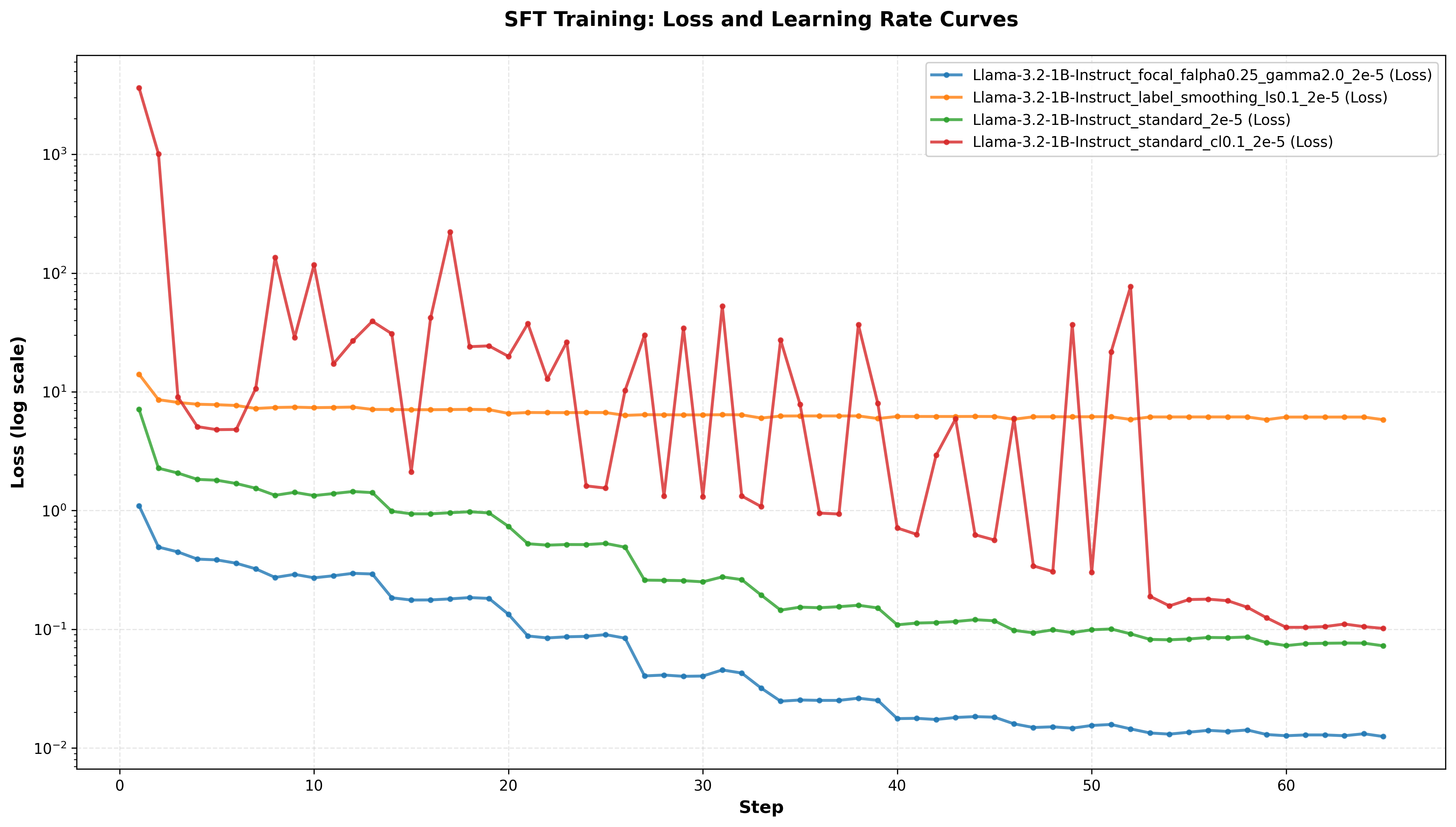
Для адаптации больших языковых моделей к специфике лингвистических паттернов, характерных для речи пациентов с болезнью Альцгеймера, был применен метод тонкой настройки (fine-tuning). Данный подход позволяет модифицировать предварительно обученные модели, оптимизируя их для решения конкретной задачи — в данном случае, выявления признаков когнитивных нарушений в текстовых данных. Тонкая настройка включает в себя обучение модели на размеченном корпусе текстов, что позволяет ей выучить тонкие лингвистические особенности, связанные с деменцией, такие как изменения в структуре предложений, частоте употребления определенных слов или особенностях семантической организации речи. В результате, модель приобретает способность более точно идентифицировать лингвистические маркеры, указывающие на возможное развитие болезни Альцгеймера.
Для адаптации больших языковых моделей к особенностям речи, связанной с деменцией, был использован метод контролируемого обучения с учителем (Supervised Fine-tuning, SFT). В процессе SFT модели обучались на размеченных данных из набора DementiaBank Dataset, содержащего лингвистические примеры, связанные с болезнью Альцгеймера и другими когнитивными нарушениями. Данный подход позволил модели изучить специфические языковые паттерны, характерные для пациентов с деменцией, и использовать эти знания для более точной диагностики и анализа речи.
В процессе обучения с учителем (Supervised Fine-tuning, SFT) для повышения производительности и устойчивости моделей были интегрированы передовые методы, такие как Contrastive Learning, Focal Loss и Label Smoothing. Contrastive Learning способствовал улучшению способности моделей различать паттерны, связанные с болезнью Альцгеймера, в то время как Focal Loss позволил сосредоточиться на сложных для классификации примерах, уменьшая влияние легко распознаваемых случаев. Применение Label Smoothing позволило смягчить проблему переобучения и повысить обобщающую способность моделей, что в совокупности позволило достичь пиковой точности в 0.868.
В качестве базовых моделей для экспериментов по адаптации к выявлению болезни Альцгеймера использовались LLama3-1b-instruct и Qwen-2.5-1.5b-instruct. Применение функции потерь Label Smoothing в процессе Supervised Fine-tuning (SFT) позволило достичь следующих результатов: точность (Accuracy) — 0.853, F1-мера — 0.919, и полнота (Recall) — 0.975. Эти показатели демонстрируют эффективность использования Label Smoothing для улучшения производительности моделей при решении задачи выявления признаков болезни Альцгеймера на основе анализа текстовых данных.
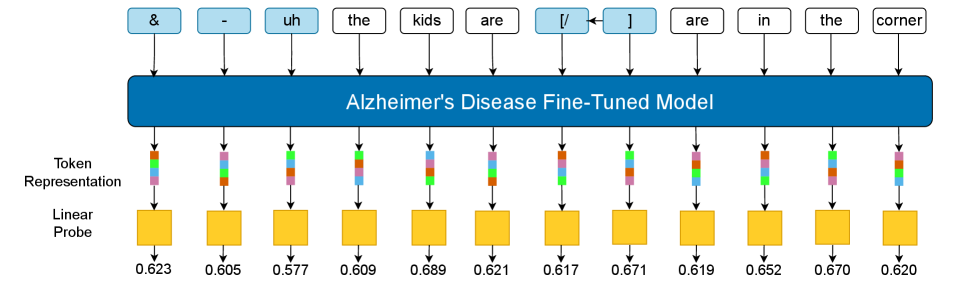
Проверка Представлений Модели для Диагностических Сигналов: Выявление Ключевых Паттернов
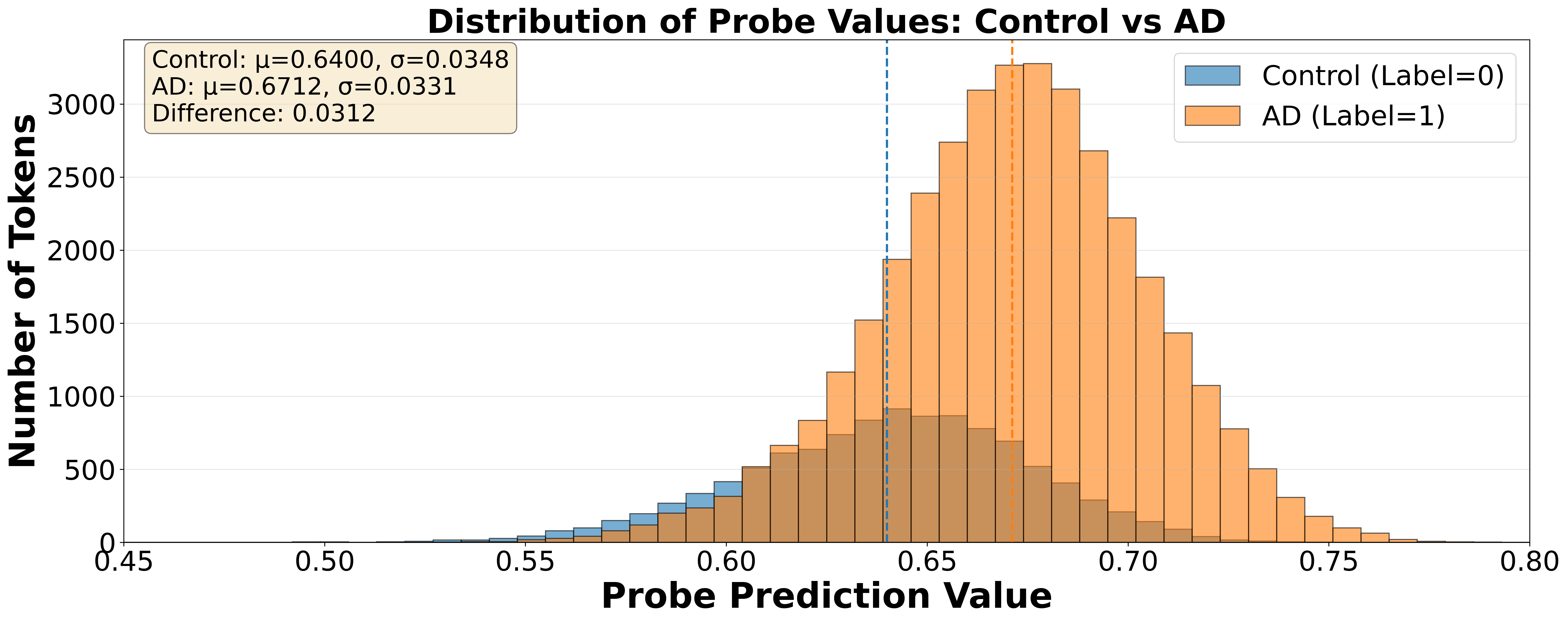
Для анализа полученных представлений в тонко настроенных больших языковых моделях (LLM) были использованы линейные зонды. Данный метод предполагает обучение линейного классификатора на основе скрытых состояний LLM для предсказания диагностической принадлежности — в данном случае, различения пациентов с болезнью Альцгеймера и здоровых испытуемых. Линейные зонды позволяют оценить, насколько эффективно LLM кодирует информацию, релевантную для постановки диагноза, и выявить, какие аспекты входных данных оказывают наибольшее влияние на принятие решения моделью. Использование линейных классификаторов упрощает интерпретацию результатов, поскольку позволяет напрямую оценить значимость отдельных признаков, извлеченных из представлений LLM.
Анализ токен-уровневых представлений позволил выявить конкретные лексические единицы, наиболее информативные для дифференциальной диагностики болезни Альцгеймера (БА) и здоровых испытуемых. В ходе исследования оценивалось влияние каждого токена на способность модели отличать транскрипты пациентов с БА от контрольной группы. Наибольший вклад в разграничение вносили токены, связанные с нарушениями синтаксической сложности, снижением разнообразия словарного запаса и увеличением частоты повторов и пауз в речи. Идентификация этих токенов позволила установить специфические лингвистические маркеры, характерные для когнитивных нарушений, что стало основой для дальнейшей разработки стратегии синтеза данных.
Анализ представлений, полученных в процессе тонкой настройки языковых моделей, позволил выявить специфические лингвистические маркеры, связанные с болезнью Альцгеймера. На основе этих данных была разработана стратегия синтеза данных, направленная на генерацию синтетических транскриптов, имитирующих речевые особенности, характерные для пациентов с данным заболеванием. Целью данной стратегии является увеличение объема тренировочных данных, обогащенных выявленными лингвистическими признаками, для улучшения точности диагностики и мониторинга прогрессирования болезни Альцгеймера.
Для синтеза данных использовалась модель T5, выполняющая преобразование обычного текста в расширенные транскрипты, содержащие ключевые лингвистические признаки, ассоциированные с болезнью Альцгеймера. Модель T5 применялась для добавления или модификации токенов в исходном тексте, таким образом, усиливая проявление специфических языковых маркеров, выявленных при анализе представлений, полученных от настроенных больших языковых моделей. Этот процесс позволил создать синтетические транскрипты, имитирующие лингвистические особенности, характерные для пациентов с болезнью Альцгеймера, что дало возможность проводить более целенаправленное тестирование и оценку моделей диагностики.
Влияние на Раннюю Диагностику и Перспективы Дальнейших Исследований: На пути к Истине
Успешное применение тонкой настройки больших языковых моделей (LLM) и анализа репрезентаций демонстрирует перспективность автоматизированного выявления болезни Альцгеймера на основе данных. Исследование показало, что модели, обученные на лингвистических особенностях речи, способны выявлять тонкие изменения в когнитивных функциях, предшествующие клиническим проявлениям заболевания. Этот подход, в отличие от традиционных методов диагностики, позволяет анализировать естественную речь пациента, выявляя паттерны, связанные с ранними стадиями деменции. Полученные результаты открывают возможности для создания доступных и эффективных инструментов скрининга, способных значительно ускорить диагностику и улучшить качество жизни пациентов.
Раннее выявление болезни Альцгеймера, ставшее возможным благодаря применению разработанных методов, открывает значительные перспективы для своевременного вмешательства и улучшения качества жизни пациентов. Задержка в диагностике часто приводит к необратимым когнитивным нарушениям, однако, чем раньше начато лечение и поддерживающая терапия, тем эффективнее замедлить прогрессирование заболевания и сохранить функциональные возможности человека. Своевременная диагностика позволяет пациентам и их семьям более осознанно планировать будущее, получать необходимую поддержку и адаптироваться к изменениям. Более того, раннее вмешательство может включать в себя не только медикаментозное лечение, но и модификацию образа жизни, когнитивные тренировки и психологическую поддержку, что в совокупности способствует более благоприятному исходу заболевания и повышению общего благополучия.
Сгенерированные синтетические данные представляют собой ценный ресурс для дальнейшего развития и тестирования моделей, предназначенных для выявления болезни Альцгеймера на ранних стадиях. Эти искусственно созданные текстовые примеры позволяют исследователям преодолеть проблему ограниченности доступных размеченных данных, что особенно важно для обучения алгоритмов машинного обучения. Возможность генерировать неограниченное количество данных с заранее заданными характеристиками, имитирующими речевые паттерны пациентов с болезнью Альцгеймера, значительно расширяет возможности для создания более точных и надежных диагностических инструментов. Более того, синтетические данные служат идеальной площадкой для оценки производительности новых моделей и алгоритмов в контролируемой среде, позволяя выявить и устранить потенциальные недостатки до их применения в клинической практике. Использование таких данных способствует разработке более эффективных методов ранней диагностики и, как следствие, улучшению качества жизни пациентов.
Перспективные исследования должны быть направлены на проверку применимости полученных результатов к различным этническим и лингвистическим группам населения, учитывая, что языковые особенности могут значительно варьироваться. Особый интерес представляет интеграция лингвистических данных, полученных с помощью методов обработки естественного языка, с другими биомаркерами болезни Альцгеймера, такими как результаты нейровизуализации и анализы спинномозговой жидкости. Такой мультимодальный подход позволит создать более точные и надежные диагностические инструменты, а также лучше понять сложные механизмы развития заболевания и выявить факторы, влияющие на его прогрессирование. Дальнейшее изучение взаимодействия между языковыми нарушениями и другими проявлениями болезни Альцгеймера откроет новые возможности для ранней диагностики и разработки эффективных терапевтических стратегий.
Исследование, представленное в данной работе, подчеркивает важность строгой математической логики в построении надежных систем диагностики, таких как обнаружение болезни Альцгеймера. Авторы демонстрируют, что тонкая настройка больших языковых моделей (LLM) и использование лингвистических маркеров для синтеза данных позволяют достичь более точных результатов. Это согласуется с убеждением, что алгоритм должен быть доказуем, а не просто «работать на тестах». Как однажды заметил Эдсгер Дейкстра: «Программирование — это не столько о создании чего-то нового, сколько о создании чего-то правильного». В контексте диагностики болезни Альцгеймера, «правильность» имеет решающее значение, и представленный подход направлен именно на обеспечение этой корректности через строгий анализ и синтез данных.
Что Дальше?
Представленные результаты, безусловно, демонстрируют потенциал тонкой настройки больших языковых моделей для выявления болезни Альцгеймера. Однако, не стоит обманываться кажущейся эффективностью. Если модель «учится» на корреляциях в тексте, а не на истинном понимании патофизиологии, то это всего лишь изощрённая статистическая иллюзия. Если решение кажется магией — значит, не раскрыт инвариант, лежащий в основе предсказаний. Дальнейшие исследования должны быть сосредоточены на разработке методов, позволяющих отделить истинное семантическое понимание от поверхностных закономерностей.
Особое внимание следует уделить проблеме обобщения. Созданные лингвистические маркеры, безусловно, полезны, но их применимость к новым, непредставленным данным остаётся под вопросом. Поиск универсальных признаков, не зависящих от конкретного стиля речи или диалекта, представляется сложной, но необходимой задачей. Иначе, мы получим инструмент, работающий лишь на узком подмножестве пациентов, что нивелирует все усилия.
В конечном итоге, истинный прогресс требует не просто улучшения точности предсказаний, а создания моделей, способных к объяснению своих решений. Недостаточно знать, что у пациента есть риск развития болезни Альцгеймера; необходимо понимать, почему модель пришла к такому выводу. Только тогда мы сможем использовать эти знания для разработки эффективных стратегий профилактики и лечения. Иначе, это останется лишь ещё одним примером «чёрного ящика», выдающего результаты без объяснений.
Оригинал статьи: https://arxiv.org/pdf/2602.11177.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-14 11:27