Автор: Денис Аветисян
Новый обзор посвящен применению методов искусственного интеллекта для повышения эффективности и точности инспекции критически важной городской инфраструктуры.

Исследование охватывает подходы на основе глубокого обучения, включая сегментацию дефектов, обучение с небольшим количеством данных и применение архитектуры FORTRESS для улучшения обнаружения повреждений в условиях ограниченных размеченных данных.
Недостаток размеченных данных часто становится серьезным препятствием для автоматизированного контроля состояния инженерных сооружений. В данной работе, посвященной ‘AI-Based Culvert-Sewer Inspection’, исследуются методы повышения точности сегментации дефектов в кулортах и канализационных трубах в условиях ограниченной выборки. Предложенные подходы, включающие предобработку данных, новую архитектуру FORTRESS и обучение с малым количеством примеров, позволяют значительно улучшить обнаружение дефектов и снизить вычислительные затраты. Возможно ли дальнейшее повышение эффективности подобных систем за счет комбинирования различных методов машинного обучения и разработки более адаптивных алгоритмов?
Шёпот Хаоса: Вызов Ограниченных Данных в Мониторинге Инфраструктуры
Эффективный мониторинг технического состояния инфраструктуры напрямую зависит от точного выявления дефектов, однако сбор достаточного количества размеченных данных для обучения моделей зачастую представляет собой серьезную проблему. Получение информации о повреждениях требует проведения дорогостоящих и трудоемких инспекций, а маркировка этих данных экспертами — ресурсозатратный процесс. Ограниченность доступных размеченных выборок существенно снижает возможности применения современных алгоритмов машинного обучения, особенно глубоких нейронных сетей, которые требуют больших объемов данных для достижения высокой точности и надежности. Это особенно актуально для инфраструктурных объектов, где сбор данных может быть затруднен из-за удаленности, опасности или сложности доступа к определенным участкам. Таким образом, поиск альтернативных подходов к обучению моделей при ограниченном объеме данных является ключевой задачей для обеспечения безопасности и долговечности инфраструктуры.
Традиционные методы глубокого обучения, демонстрирующие впечатляющие результаты в различных областях, зачастую требуют колоссальных объемов размеченных данных для эффективной работы. В контексте мониторинга инфраструктуры, получение таких данных сопряжено со значительными трудностями и затратами. Процесс ручной маркировки данных, особенно для выявления редких или скрытых дефектов, требует квалифицированных специалистов и значительных временных ресурсов. Кроме того, сбор данных может быть затруднен из-за труднодоступности определенных участков инфраструктуры или необходимости проведения дорогостоящих инспекций. В результате, применение стандартных моделей глубокого обучения становится непрактичным для многих реальных задач, где доступ к большим размеченным наборам данных ограничен или невозможен, что стимулирует поиск альтернативных подходов, способных эффективно работать в условиях дефицита информации.
Неравномерное распределение классов — ситуация, когда определенные типы дефектов в инфраструктуре встречаются значительно реже других — существенно усложняет задачу обучения моделей машинного обучения. В таких условиях стандартные алгоритмы склонны отдавать предпочтение более распространенным классам, игнорируя или неправильно классифицируя редкие, но потенциально критические повреждения. Это приводит к смещенной оценке производительности, когда модель демонстрирует высокую точность в целом, но не способна надежно выявлять именно те дефекты, которые представляют наибольшую угрозу для безопасности и долговечности конструкции. Таким образом, проблема дисбаланса классов требует применения специальных методов, направленных на коррекцию весов классов или генерацию синтетических данных, чтобы обеспечить более сбалансированное обучение и улучшить способность модели к обнаружению всех типов дефектов.

Малое Количество Примеров и Увеличение Данных: Преодоление Дефицита Информации
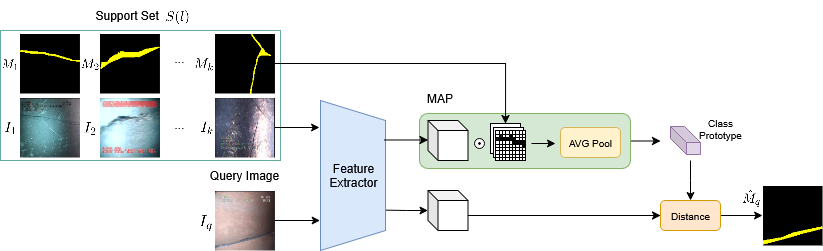
Метод обучения с малым количеством примеров (Few-Shot Learning) представляет собой перспективный подход, позволяющий моделям обобщать информацию, используя лишь небольшое количество размеченных данных. Это особенно актуально в ситуациях, когда получение большого объема аннотированной информации затруднено или экономически нецелесообразно. В отличие от традиционных методов машинного обучения, требующих сотен или тысяч примеров для каждой категории, Few-Shot Learning позволяет достичь приемлемой точности, используя всего несколько примеров на класс. Такой подход использует предварительно обученные модели и методы переноса обучения, что позволяет адаптировать знания, полученные на больших объемах данных, к новым задачам с ограниченным количеством данных.
Прототипические сети (Prototypical Networks) — это метод обучения, позволяющий классифицировать данные, имея лишь небольшое количество размеченных примеров. В основе подхода лежит вычисление прототипа для каждого класса, представляющего собой среднее эмбеддинг (embedding) всех образцов этого класса. Классификация новых данных происходит путем определения ближайшего прототипа в пространстве эмбеддингов, используя, например, евклидово расстояние. Такой подход позволяет эффективно обобщать знания на новые данные, даже при ограниченном объеме обучающей выборки, поскольку модель учится представлять классы через их центральные представления, а не запоминать отдельные экземпляры.
Для повышения устойчивости моделей и решения проблемы нехватки данных используются методы увеличения данных (Data Augmentation), которые позволяют искусственно расширить размер и разнообразие обучающей выборки. Эти методы включают в себя применение различных преобразований к существующим изображениям, таких как повороты, масштабирование, обрезка, изменение яркости и контрастности, а также добавление шума. В результате модель получает возможность обучаться на более широком спектре вариаций данных, что способствует улучшению её обобщающей способности и повышению производительности на невидимых данных. Использование двунаправленного обучения в сочетании с Data Augmentation позволило добиться прироста производительности примерно на 10%.
Методы увеличения данных (Data Augmentation) позволяют искусственно расширить обучающую выборку за счет генерации вариаций существующих изображений. Это способствует обучению модели более обобщенным признакам, что, в свою очередь, повышает ее производительность на невидимых ранее данных. Внедрение двунаправленного обучения (bidirectional training) в процессе увеличения данных продемонстрировало улучшение показателей производительности примерно на 10%.
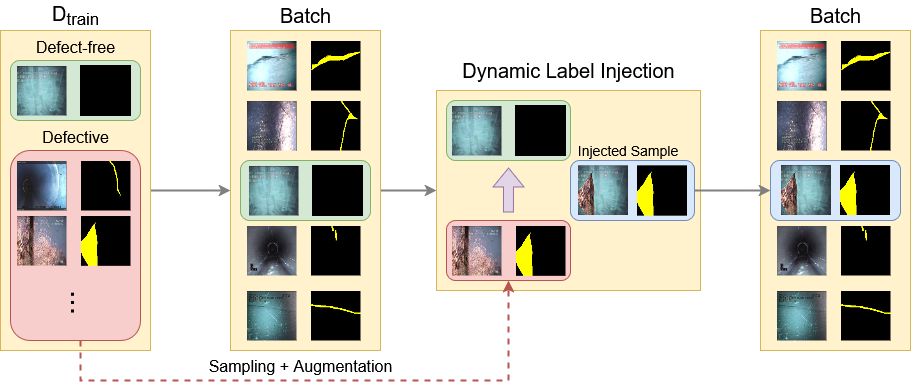
Динамическое Внедрение Метки: Целенаправленное Усиление Данных
Для решения специфических задач сегментации структурных дефектов (StructuralDefectSegmentation) предложен новый метод аугментации данных, получивший название DynamicLabelInjection. Данный подход заключается в искусственном создании новых обучающих примеров путем переноса дефектов из одного изображения в другое. В отличие от стандартных методов аугментации, DynamicLabelInjection позволяет целенаправленно увеличивать разнообразие данных и корректировать дисбаланс классов, что особенно важно при работе с редкими или трудно обнаруживаемыми дефектами.
Метод DynamicLabelInjection предполагает внедрение дефектов из одного изображения в другое, что позволяет создавать синтетические обучающие примеры. Данная техника направлена на увеличение разнообразия данных и решение проблемы дисбаланса классов в наборе данных для сегментации структурных дефектов. В процессе внедрения происходит копирование пиксельных данных, представляющих дефект, из исходного изображения и их наложение на целевое изображение, имитируя появление дефекта в различных контекстах и с различными характеристиками. Это позволяет модели обучаться на более широком спектре визуальных проявлений дефектов, повышая ее способность к обнаружению и сегментации даже незначительных аномалий.
Стратегическое внедрение дефектов в изображения позволяет модели машинного обучения расширить спектр распознаваемых аномалий. Этот процесс предполагает искусственное добавление дефектов различной формы, размера и интенсивности в тренировочные данные. В результате, модель получает возможность обучаться на более разнообразном наборе примеров, что повышает её устойчивость к вариациям в реальных данных и улучшает способность выявлять слабовыраженные дефекты, которые могли бы быть пропущены при обучении на исходном, менее разнообразном наборе данных. Данный подход особенно эффективен для обнаружения аномалий, отличающихся незначительными визуальными характеристиками.
Целенаправленный подход к увеличению объема обучающей выборки посредством внедрения синтетических дефектов, как реализовано в методе DynamicLabelInjection, демонстрирует повышенную эффективность по сравнению со стандартными методами аугментации данных. Внедрение дефектов в изображения, основанное на анализе специфических проблем сегментации структурных дефектов, позволяет модели обучаться на более разнообразном наборе данных, включающем широкий спектр вариаций внешнего вида дефектов. Это, в свою очередь, приводит к улучшению точности сегментации, особенно в случаях, когда реальные данные ограничены или наблюдается дисбаланс классов, что критически важно для задач автоматизированного контроля качества и обнаружения аномалий.
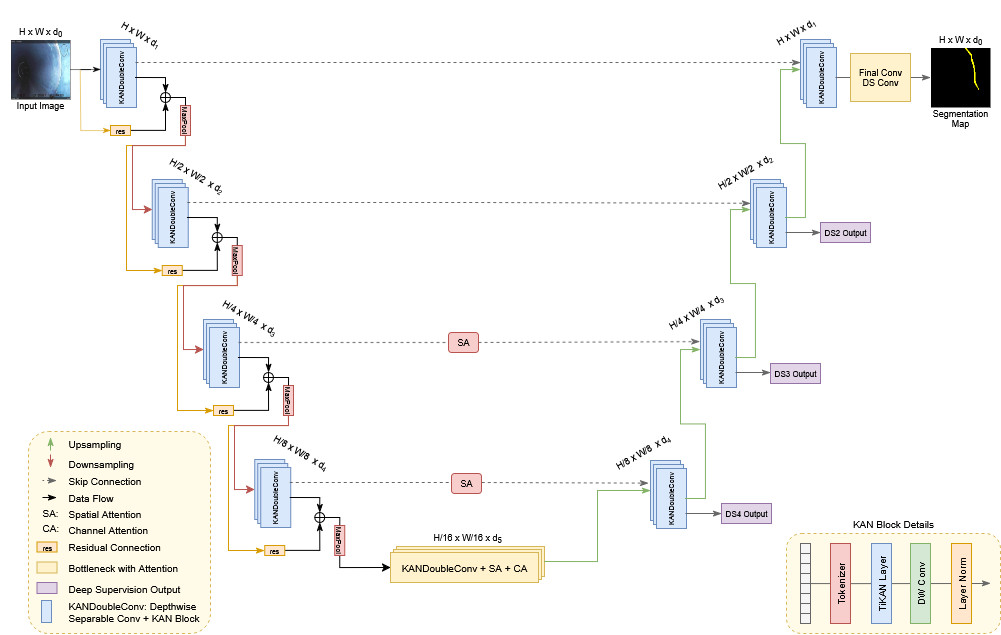
FORTRESS: Новая Архитектура для Эффективной Сегментации Дефектов
Разработана инновационная архитектура глубокого обучения под названием FORTRESS, предназначенная для эффективной и точной сегментации структурных дефектов. Данная архитектура представляет собой принципиально новый подход к задаче автоматического обнаружения и выделения дефектов на изображениях, обеспечивая высокую производительность при относительно небольшом количестве параметров. Особенностью FORTRESS является её способность к адаптации к различным типам дефектов и масштабам изображений, что позволяет достигать превосходных результатов в задачах контроля качества и технического зрения. Благодаря оптимизированной структуре и использованию передовых методов, FORTRESS демонстрирует значительное превосходство над существующими решениями в области сегментации дефектов, открывая новые возможности для автоматизации процессов и повышения надежности систем.
Архитектура FORTRESS использует глубинные разделяемые свёртки (Depthwise Separable Convolutions) для значительного снижения вычислительных затрат и объёма модели, не жертвуя при этом точностью сегментации дефектов. В отличие от стандартных свёрточных операций, которые выполняют свёртку и объединение в одном шаге, данный подход разделяет их на два отдельных этапа. Сначала применяется глубинная свёртка, обрабатывающая каждый входной канал независимо, а затем — точечная свёртка, объединяющая полученные признаки. Такое разделение позволяет существенно уменьшить количество параметров и операций, сохраняя при этом способность модели эффективно извлекать и представлять сложные признаки, необходимые для точной идентификации структурных дефектов. В результате достигается более высокая скорость обработки и меньшее потребление памяти, что особенно важно для применения в условиях ограниченных вычислительных ресурсов.
Архитектура FORTRESS использует модуль KAN (Kernel Attention Network) для создания эффективного и точного представления функций, что значительно улучшает способность модели распознавать сложные дефекты. KAN позволяет сети фокусироваться на наиболее релевантных признаках, игнорируя несущественные детали, и тем самым выделять даже незначительные отклонения от нормы. Этот подход позволяет модели более эффективно улавливать взаимосвязи между различными элементами изображения и формировать более полное представление о дефектах, что приводит к повышению точности сегментации и обнаружению дефектов, которые могли бы быть пропущены другими методами. В результате, KAN играет ключевую роль в способности FORTRESS к детальному анализу и надежному определению структурных дефектов.
Архитектура FORTRESS демонстрирует превосходную способность к обнаружению дефектов различного размера благодаря использованию механизма многомасштабного внимания. Этот подход позволяет модели учитывать взаимосвязи между признаками на разных уровнях детализации, что особенно важно для выявления как незначительных, едва заметных дефектов, так и крупных, выраженных повреждений. В результате, FORTRESS достигает показателя F1 в 0.771 и Mean IoU в 0.643, превосходя существующие аналоги. При этом, модель отличается высокой эффективностью и компактностью: с 2.89 миллионами параметров, она содержит на 63% меньше параметров, чем вторая по эффективности модель, и требует всего 1.17 GFLOPS вычислительных ресурсов, что делает её перспективным решением для задач сегментации дефектов в условиях ограниченных ресурсов.
Исследование, посвящённое автоматизированному поиску дефектов в канализационных коллекторах, закономерно сталкивается с проблемой нехватки размеченных данных. Авторы предлагают интересные решения в области аугментации и использования архитектуры FORTRESS, но за всем этим стоит вечная истина: любая модель — это лишь заклинание, работающее до первого столкновения с реальными данными. Как однажды заметил Ян ЛеКюн: «Искусственный интеллект — это просто способ заставить компьютеры делать вещи, которые мы не можем или не хотим делать сами». И в данном случае, задача автоматической сегментации дефектов — яркий пример того, где даже небольшое улучшение в точности может существенно снизить затраты на ручную проверку инфраструктуры. Ведь, как известно, всё, что не нормализовано, всё ещё дышит — и в данном контексте, это относится к потенциальным рискам, скрывающимся в некачественных данных.
Что дальше?
Исследование, представленное в данной работе, лишь слегка приоткрывает завесу над хаосом, скрывающимся в изображениях канализационных коллекторов. Архитектура FORTRESS и методы few-shot обучения — это, скорее, красивые заклинания, призванные упорядочить шум, нежели истинное понимание дефектов. Конечно, сегментация улучшилась, но данные всегда правы — пока не попадут в реальные условия эксплуатации, где свет, вода и сама жизнь вносят свои коррективы.
Основным узким местом остаётся зависимость от размеченных данных, а их получение — это всегда компромисс между желаемой точностью и доступными ресурсами. Kolmogorov-Arnold Networks (KAN) — многообещающий инструмент, но их потенциал в контексте структурного контроля требует дальнейшего изучения. Вместо погони за идеальной точностью, возможно, стоит сосредоточиться на разработке систем, способных оценивать вероятность дефекта, а не констатировать его наличие.
Будущие исследования должны быть направлены на создание робастных моделей, устойчивых к вариациям освещения, углов обзора и степени загрязнения. И, возможно, самое главное — признать, что любая модель — это лишь приближение к реальности, а истина всегда ускользает, как вода сквозь пальцы. Искусство не в том, чтобы украшать хаос, а в том, чтобы научиться с ним жить.
Оригинал статьи: https://arxiv.org/pdf/2601.15366.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-24 22:05