Автор: Денис Аветисян
Новый подход позволяет выявлять необычные паттерны в графовых данных, используя возможности больших языковых моделей и избегая необходимости в предварительной подготовке.
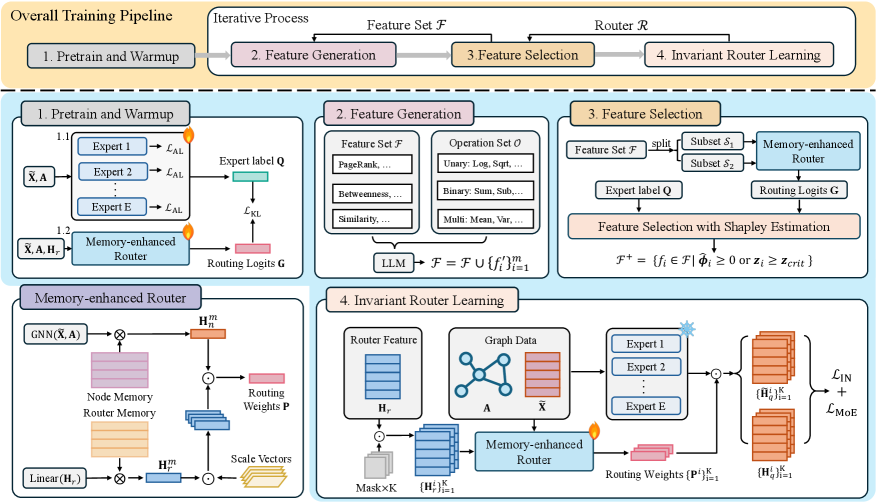
Предложена структура EvoFG, использующая эволюционный поиск для генерации информативных признаков маршрутизатора в модели «смесь экспертов» для обнаружения аномалий в графах без предварительного обучения.
Обнаружение аномалий в графах представляет собой сложную задачу, усугубляемую разнородностью структур данных и паттернов отклонений. В данной работе, посвященной ‘Evolutionary Router Feature Generation for Zero-Shot Graph Anomaly Detection with Mixture-of-Experts’, предложен новый подход, использующий архитектуру «смесь экспертов» и эволюционный механизм генерации признаков для маршрутизатора, что позволяет эффективно обнаруживать аномалии на графах, ранее не встречавшихся в процессе обучения. Ключевым нововведением является применение больших языковых моделей для создания информативных признаков маршрутизатора, повышающих обобщающую способность модели. Сможет ли предложенный подход стать основой для создания универсальных систем обнаружения аномалий в графах, способных адаптироваться к новым и сложным сценариям?
Преодолевая Границы Обобщения: Проблема Обнаружения Аномалий в Графах
Традиционные модели обнаружения аномалий в графах (GAD) часто демонстрируют ограниченную применимость в реальных сценариях из-за сложностей с обобщением на ранее не встречавшиеся структуры графов. Данное ограничение связано с тем, что эти модели склонны переобучаться на специфических особенностях обучающего набора данных, не улавливая общие, фундаментальные свойства графов. В результате, при применении к новым графам, отличающимся по структуре или характеристикам, производительность таких моделей существенно снижается, требуя дорогостоящей и трудоемкой переподготовки для каждого нового домена. Эта проблема особенно актуальна в динамичных средах, где структура графа постоянно меняется, что делает традиционные подходы неэффективными и ограничивает их практическую ценность.
Ограниченность обобщающей способности традиционных моделей обнаружения аномалий в графах часто обусловлена их чрезмерной зависимостью от специфических признаков, характерных для конкретного набора данных. Вместо того чтобы выявлять фундаментальные свойства графа, определяющие нормальное поведение, модели склонны «запоминать» паттерны, уникальные для обучающей выборки. Это приводит к тому, что при столкновении с графами, отличающимися по структуре или характеристикам, производительность резко падает. Существующие подходы нередко игнорируют ключевые инварианты графа — такие как центральность узлов, плотность связей или кластеризация — которые могли бы служить надежными индикаторами нормальности, независимо от конкретного домена применения. В результате, модели оказываются неспособными эффективно адаптироваться к новым графовым структурам и требуют значительной перенастройки или повторного обучения для каждого нового случая.
Эффективное обнаружение аномалий требует от моделей способности адаптироваться к различным графовым доменам без необходимости обширного переобучения. Существующие подходы часто сталкиваются с трудностями при переносе знаний между графами, поскольку они сильно зависят от специфических характеристик обучающего набора данных. Модели, способные выделять и использовать общие графовые свойства, такие как паттерны связности или структурные роли узлов, демонстрируют повышенную устойчивость и обобщающую способность. Это позволяет им успешно идентифицировать аномалии в новых, ранее не встречавшихся графах, минимизируя потребность в дорогостоящей и трудоемкой повторной настройке для каждого конкретного домена. Разработка таких адаптивных моделей является ключевой задачей для расширения практического применения методов обнаружения аномалий в графах.
Существующие методы обнаружения аномалий в графах часто не используют в полной мере потенциал их структуры для создания устойчивых и переносимых оценок. Вместо того чтобы анализировать глобальные паттерны связей и иерархии в графе, многие подходы фокусируются на локальных характеристиках узлов или ребер, что приводит к чувствительности к специфическим особенностям конкретного графа. Это ограничивает способность моделей обобщать результаты на новые, ранее не встречавшиеся графовые структуры, поскольку они не способны выделять инвариантные признаки, определяющие аномальное поведение независимо от контекста. В результате, даже незначительные изменения в графе могут существенно повлиять на точность обнаружения аномалий, что требует постоянной перенастройки и адаптации моделей к каждому новому графовому домену.
EvoFG: Смесь Экспертов для Обнаружения Аномалий без Адаптации
В основе EvoFG лежит архитектура Mixture-of-Experts (MoE), представляющая собой комбинацию нескольких специализированных графовых нейронных сетей (GNN Experts). Каждый GNN Expert обучен для эффективной обработки определенных типов графов или выявления специфических аномалий. Вместо использования одной универсальной модели, MoE позволяет распределить вычислительную нагрузку и оптимизировать производительность за счет параллельной обработки данных различными экспертами. Это повышает способность модели к обобщению и адаптации к новым, ранее не встречавшимся графовым структурам, что особенно важно для задач обнаружения аномалий в графах (GAD) в условиях нулевой адаптации (zero-shot GAD).
Ключевым компонентом EvoFG является маршрутизатор с расширенной памятью, который динамически направляет входные данные к наиболее подходящему GNN эксперту на основе выученных весов маршрутизации. Этот маршрутизатор использует механизм памяти для хранения информации о предыдущих входных данных и соответствующих им экспертах, что позволяет ему более эффективно определять оптимального эксперта для каждого нового графа. Веса маршрутизации обновляются в процессе обучения с использованием алгоритма обратного распространения ошибки, что обеспечивает адаптацию маршрутизатора к различным характеристикам входных графов и повышение точности обнаружения аномалий. Маршрутизатор эффективно распределяет вычислительную нагрузку между экспертами, максимизируя производительность и масштабируемость модели.
Архитектура EvoFG позволяет учитывать разнообразие характеристик графов благодаря использованию нескольких специализированных экспертов — графовых нейронных сетей (GNN). Различные GNN-эксперты специализируются на обнаружении аномалий в графах с различными свойствами, такими как структура, атрибуты узлов и ребер. Это позволяет модели эффективно адаптироваться к данным из разных доменов, где графы могут значительно отличаться по своим характеристикам, и успешно решать задачу обнаружения аномалий в условиях отсутствия размеченных данных для конкретного домена (zero-shot GAD). Способность модели обобщать знания, полученные на одном типе графов, на другие типы графов является ключевым преимуществом EvoFG.
Использование подхода Mixture-of-Experts (MoE) в EvoFG позволяет достичь баланса между специализацией и обобщением, что критически важно для задачи обнаружения аномалий на графах (GAD) в условиях нулевой обучаемости (zero-shot). Вместо использования одной универсальной модели, EvoFG применяет несколько специализированных Graph Neural Networks (GNN Experts), каждая из которых обучена на определенных типах графов или аномалий. Механизм динамической маршрутизации направляет входящие графы к наиболее подходящему эксперту, максимизируя эффективность обнаружения аномалий в новых, ранее не встречавшихся доменах. Такой подход позволяет модели эффективно использовать накопленные знания, одновременно адаптируясь к новым данным без необходимости переобучения, что обеспечивает высокую производительность в условиях zero-shot GAD.
Усиление Представления Признаков с Помощью Больших Языковых Моделей
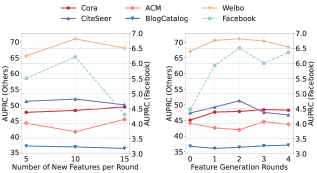
EvoFG использует генерацию признаков на основе больших языковых моделей (LLM) для создания новых, информативных признаков маршрутизации. Вместо использования традиционных, разработанных вручную признаков, EvoFG применяет LLM для анализа данных графа и выявления скрытых закономерностей, которые затем преобразуются в числовые признаки. Этот подход позволяет автоматически расширять набор признаков, адаптируясь к специфике данных и повышая эффективность процесса выбора экспертов. Генерация признаков с помощью LLM позволяет учитывать контекстную информацию внутри графовых структур, что приводит к созданию более релевантных и информативных признаков для маршрутизации.
Выбор маршрутизирующих признаков в EvoFG осуществляется посредством оценки по Шейпли (Shapley Value Estimation), позволяющей определить наиболее влиятельные признаки для выбора экспертов. Метод Шейпли, происходящий из теории кооперативных игр, позволяет оценить вклад каждого признака в общую производительность модели, учитывая все возможные комбинации признаков. Это обеспечивает объективную оценку важности каждого признака, а не просто корреляцию с целевой переменной. Полученные значения Шейпли используются для ранжирования признаков, после чего выбирается подмножество наиболее значимых, что способствует повышению эффективности и интерпретируемости модели.
В отличие от традиционных методов, полагающихся на разработанные вручную признаки, EvoFG позволяет обнаруживать более устойчивые и переносимые закономерности в данных. Использование автоматизированного процесса поиска признаков, не ограничивающегося априорными знаниями экспертов, обеспечивает адаптацию модели к различным графовым структурам и наборам данных. Это приводит к повышению обобщающей способности модели и снижению зависимости от специфических характеристик конкретного набора данных, что особенно важно при работе с задачами, где данные могут меняться или быть недостаточно представлены.
Интеграция больших языковых моделей (LLM) в EvoFG позволяет использовать контекстную информацию, содержащуюся в структуре графа, для улучшения представления признаков. LLM анализируют взаимосвязи между узлами и ребрами графа, выявляя зависимости и паттерны, которые невозможно обнаружить с помощью традиционных методов анализа графов или ручной разработки признаков. Это позволяет EvoFG генерировать признаки, учитывающие не только атрибуты отдельных узлов, но и их положение и связи в общей структуре графа, что повышает точность и обобщающую способность модели при решении различных задач анализа графов.
Инвариантное Обучение для Надежного Обобщения
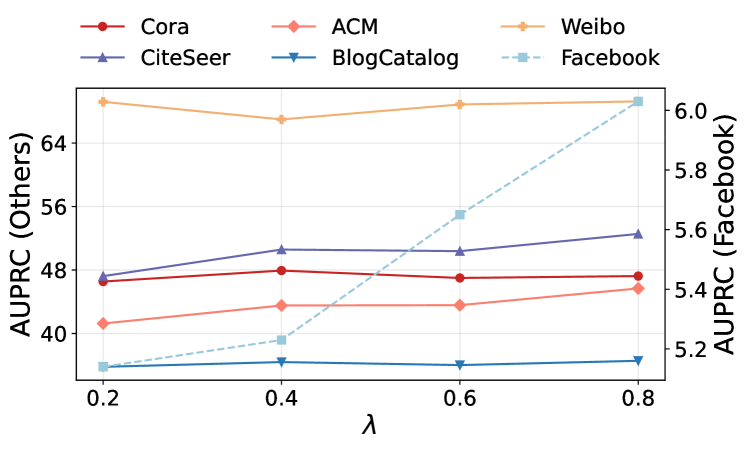
В основе EvoFG лежит принцип инвариантного обучения, направленный на формирование у маршрутизатора стабильных шаблонов обработки данных. Этот подход позволяет минимизировать колебания в принятии решений при переходе между различными графовыми средами. Вместо запоминания специфических характеристик каждого графа, система учится выделять общие, инвариантные признаки, что обеспечивает устойчивость и обобщающую способность. Такой механизм позволяет маршрутизатору сохранять надежность и точность, даже при работе с ранее не встречавшимися данными, существенно повышая адаптивность и применимость системы в реальных условиях.
Обеспечение стабильности процесса принятия решений маршрутизатором, даже при столкновении с ранее не встречавшимися данными, является ключевым аспектом разработанной методики. Это достигается за счет акцента на инвариантном обучении, которое способствует формированию устойчивых паттернов в работе маршрутизатора. В результате, система демонстрирует предсказуемое поведение в различных графовых средах, не подвергаясь значительным колебаниям в производительности при изменении входных данных. Такая надежность особенно важна для применения в реальных сценариях, где адаптация к новым условиям и обеспечение постоянной точности являются критическими требованиями, а стабильный алгоритм маршрутизации позволяет избежать непредсказуемых ошибок и повысить общую эффективность системы обнаружения аномалий.
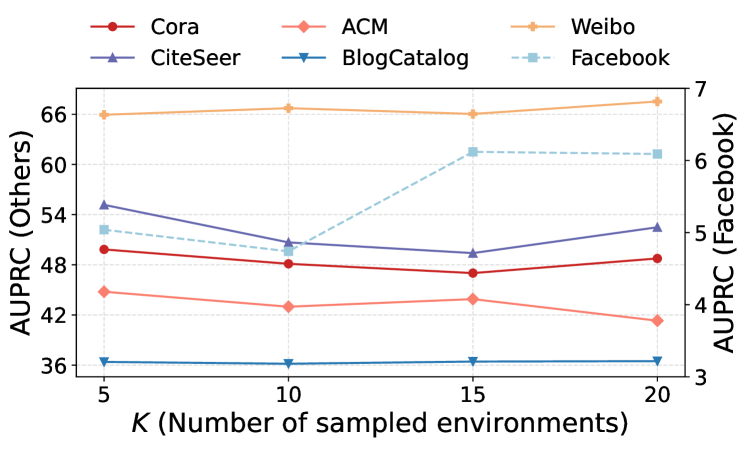
Проведена всесторонняя оценка способности EvoFG к обобщению на ранее невиданных данных посредством кросс-датасетной валидации. Результаты демонстрируют значительное превосходство разработанного подхода над базовыми моделями, в частности, на датасете BlogCatalog достигнута точность в 92% по метрике AUROC. Такое достижение подтверждает устойчивость и адаптивность EvoFG к различным графовым средам, что позволяет эффективно применять его для решения задач обнаружения аномалий даже при отсутствии предварительной подготовки на целевом датасете. Данный результат свидетельствует о перспективности использования Invariant Learning для создания робастных и обобщающих моделей графового машинного обучения.
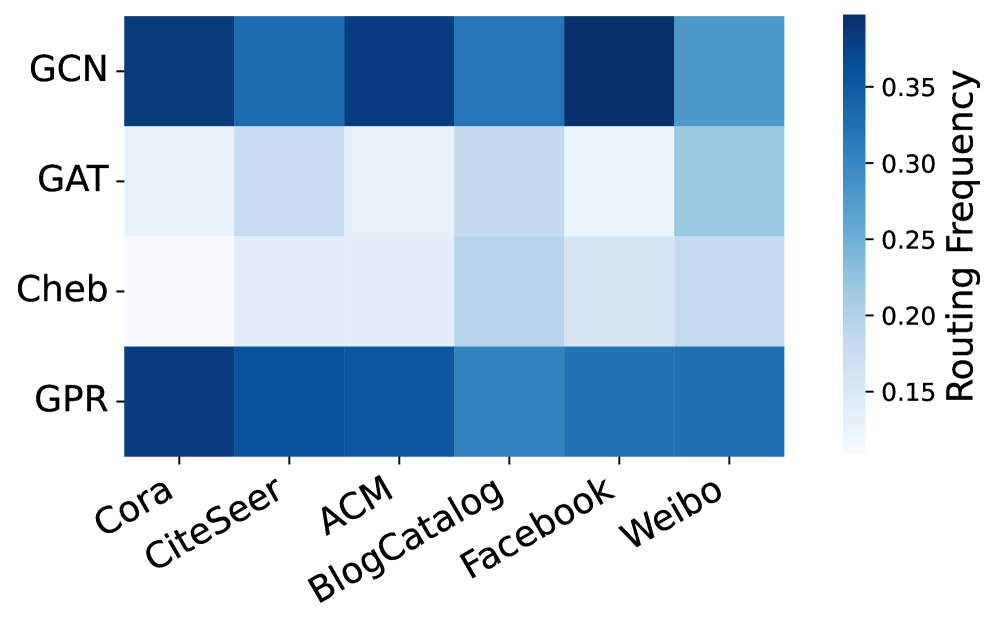
Разработанная система демонстрирует повышенную точность выявления аномалий, достигая показателя AUPRC до 90% при тестировании на различных наборах данных, что значительно расширяет возможности применения графовых аномальных детекторов (GAD) в более широком спектре практических задач. Визуализация посредством тепловых карт подтверждает, что механизм маршрутизации эффективно избегает «коллапса экспертов» — ситуации, когда система полагается лишь на ограниченное число специализированных модулей, — обеспечивая адаптивный выбор экспертов в зависимости от характеристик входных данных и, тем самым, повышая устойчивость и надежность обнаружения аномалий в сложных и динамичных графовых структурах.
Исследование демонстрирует, что эффективное обнаружение аномалий в графах требует не просто идентификации отклонений, но и способности адаптироваться к новым, ранее невиданным графовым структурам. Авторы предлагают EvoFG — систему, использующую большие языковые модели для генерации признаков маршрутизации, которые позволяют модели экспертов эффективно обобщать знания между различными графовыми доменами. Это перекликается с мыслями Анри Пуанкаре: «Наука не состоит из набора фактов, а из методов их организации». В данном случае, EvoFG представляет собой именно такой метод — способ организовать информацию о графе для повышения эффективности обнаружения аномалий, подчеркивая важность не самих данных, а способа их представления и обработки.
Куда дальше?
Представленный подход, генерируя признаки маршрутизации через большие языковые модели, демонстрирует не просто улучшение обнаружения аномалий в графах, но и сдвиг парадигмы. Система, способная адаптироваться к новым графовым доменам без переобучения, — это не просто алгоритм, это попытка реверс-инжиниринга самой концепции «аномалии». Однако, стоит признать, что каждый эксплойт начинается с вопроса, а не с намерения. Текущая архитектура, полагаясь на LLM, унаследовала присущие им ограничения: предвзятость, вычислительные затраты и не всегда прозрачную логику принятия решений. Поиск инвариантных представлений — это, конечно, прогресс, но настоящая проверка — в столкновении с данными, намеренно искажёнными для обхода защиты.
Дальнейшие исследования, вероятно, сосредоточатся на снижении зависимости от внешних LLM, возможно, через разработку более компактных и специализированных моделей, обученных на синтетических графовых данных. Интересным направлением представляется исследование возможностей самообучения: система, способная самостоятельно генерировать и анализировать аномальные сценарии, станет по-настоящему автономной. Важно помнить, что «обнаружение» — это лишь одна сторона медали; не менее важна способность системы объяснить причину возникновения аномалии, раскрыть лежащий в её основе механизм.
В конечном счете, задача не в создании идеального алгоритма, а в понимании границ применимости любых моделей. Иллюзия «общего» решения всегда разбивается о реальность, и каждый новый домен графов станет новым полигоном для проверки. Именно в этих столкновениях и рождается настоящее знание.
Оригинал статьи: https://arxiv.org/pdf/2602.11622.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-14 21:38