Автор: Денис Аветисян
Исследование демонстрирует, как комбинирование моделей машинного обучения позволяет значительно повысить точность определения соответствия текстов Целям устойчивого развития ООН.

Применение комбинаторного анализа и генеративного искусственного интеллекта для улучшения классификации текстов, связанных с Целями устойчивого развития.
Несмотря на значительный прогресс в области обработки естественного языка, классификация текстов, особенно в сложных областях, связанных с социально-экономическими целями, остается непростой задачей. В работе ‘Enhancing SDG-Text Classification with Combinatorial Fusion Analysis and Generative AI‘ предложен инновационный подход к повышению точности классификации текстов в соответствии с Целями устойчивого развития ООН. Комбинируя возможности генеративного искусственного интеллекта для создания синтетических данных и метод Combinatorial Fusion Analysis (CFA) для объединения интеллекта различных моделей, авторы добились повышения эффективности классификации до 96.73%, превзойдя результаты лучших индивидуальных моделей и продемонстрировав соответствие оценкам экспертов. Возможно ли дальнейшее совершенствование подобных систем за счет интеграции знаний из различных областей и расширения набора используемых данных?
От сложности к ясности: задача категоризации данных для целей устойчивого развития
Эффективная категоризация текстовых данных играет ключевую роль в отслеживании прогресса в достижении Целей устойчивого развития. Точное сопоставление текстов — от отчетов правительств и международных организаций до публикаций в социальных сетях и новостных статей — позволяет количественно оценить усилия, направленные на решение глобальных проблем, таких как бедность, голод, изменение климата и неравенство. Без надежной системы классификации, понимание реального воздействия различных инициатив и выявление пробелов в реализации Целей становится затруднительным. В результате, анализ больших объемов текстовой информации, необходимый для принятия обоснованных решений и эффективного распределения ресурсов, существенно усложняется, что подчеркивает важность разработки и внедрения передовых методов автоматической категоризации.
Традиционные методы категоризации текстов зачастую оказываются неэффективными при работе с реальными документами, поскольку не способны уловить всю сложность и многогранность человеческого языка. Нюансы, ирония, контекст и неоднозначность формулировок — всё это представляет серьезную проблему для алгоритмов, основанных на простых ключевых словах или шаблонах. В результате, значительная часть информации, релевантная Целям устойчивого развития, может быть упущена из виду или неправильно классифицирована. Это приводит к неточностям в мониторинге прогресса и затрудняет объективную оценку эффективности предпринимаемых усилий. Особенно остро эта проблема проявляется при анализе неструктурированных данных, таких как новостные статьи, отчеты или публикации в социальных сетях, где языковые конструкции значительно сложнее и разнообразнее.
Огромный объем текстовых данных, генерируемых ежедневно, требует применения автоматизированных решений для анализа и сопоставления с Целями устойчивого развития. Однако, автоматизация неизменно сталкивается с проблемой поддержания высокой точности. Алгоритмы, способные обрабатывать миллионы документов, часто упускают тонкие нюансы и контекст, что приводит к неверной классификации и искажению результатов. Повышение точности автоматизированных систем остаётся ключевой задачей, требующей разработки более сложных алгоритмов и использования методов машинного обучения, способных учитывать семантические особенности языка и контекстную информацию. Разработка таких систем — это не просто техническая проблема, но и важный шаг к объективной оценке прогресса в достижении глобальных целей.
Несмотря на высокую точность, ручная классификация текстовых данных становится невыполнимой задачей при анализе больших объемов информации и необходимости постоянного мониторинга. Тщательная проверка каждого документа требует значительных временных и человеческих ресурсов, что делает этот подход непрактичным для отслеживания прогресса в достижении Целей устойчивого развития в глобальном масштабе. Постоянно генерируемый поток данных, включающий отчеты, новостные статьи и публикации в социальных сетях, требует автоматизированных решений, способных эффективно обрабатывать информацию без существенной потери точности. В связи с этим, разработка и внедрение алгоритмов машинного обучения, способных к автоматической классификации текстов, становится критически важной задачей для обеспечения эффективного мониторинга и оценки прогресса в достижении поставленных целей.
Автоматизированные подходы: ландшафт методов классификации
Для автоматической классификации текстов используются разнообразные методы машинного обучения. Модели на основе BERT (Bidirectional Encoder Representations from Transformers) применяют механизм внимания для понимания контекста слов, обеспечивая высокую точность. Сверточные нейронные сети (Convolutional Neural Networks, CNN) эффективно выявляют локальные закономерности в тексте, что полезно для определения ключевых фраз. Случайный лес (Random Forest) использует ансамбль решающих деревьев, повышая устойчивость и обобщающую способность. Специализированная модель SDG Classy разработана для классификации текстов в соответствии с Целями устойчивого развития (ЦУР), используя предварительно обученные модели и адаптированные алгоритмы для повышения релевантности результатов.
Методы тематического моделирования и большие языковые модели, такие как ChatGPT, расширяют возможности автоматизированной классификации текстов. Тематическое моделирование позволяет выявлять скрытые темы и закономерности в больших объемах данных, что способствует более глубокому пониманию содержания. Большие языковые модели, обученные на обширных текстовых корпусах, способны генерировать синтетические данные, полезные для расширения обучающих выборок и повышения точности классификации, особенно в случаях недостатка размеченных данных. Кроме того, они позволяют осуществлять более нюансированный анализ текстов, учитывая контекст и семантические связи между словами и фразами.
В настоящее время большинство методов автоматизированной классификации текстов, таких как BERT, CNN или Random Forest, функционируют независимо друг от друга. Это означает, что каждый метод анализирует документ, выделяя отдельные темы или категории, без учета взаимосвязей между ними. В результате, при работе со сложными документами, охватывающими несколько пересекающихся областей знаний, важные перекрестные связи и зависимости могут быть упущены. Отсутствие интеграции между различными методами классификации снижает точность и полноту анализа, особенно применительно к задачам, требующим комплексного понимания взаимосвязанных тем.
Многоме́тная классификация́ представляет собой продвинутый подход, позволяющий отразить взаимосвязанность Целей устойчивого развития (ЦУР), однако её эффективное применение требует надежной интеграции. В отличие от традиционной одноме́тной классификации, где каждый документ относится только к одной категории, многоме́тная классификация позволяет назначать документу несколько соответствующих ЦУР, что более точно отражает их взаимозависимость и комплексный характер. Реализация многоме́тной классификации требует использования алгоритмов, способных обрабатывать и учитывать корреляции между метками, а также тщательной разработки системы оценки и валидации, учитывающей сложность многоме́тных данных и потенциальные дисбалансы классов. Отсутствие надежной интеграции и валидации может привести к снижению точности и интерпретируемости результатов.
За пределами отдельных моделей: сила объединения
Объединение моделей (Model Fusion) представляет собой перспективную стратегию повышения точности и устойчивости классификации за счет использования сильных сторон различных алгоритмов. Вместо полагания на единую модель, данный подход комбинирует прогнозы нескольких моделей, что позволяет компенсировать недостатки каждой из них и добиться более надежных результатов. Разные модели могут быть обучены на различных подмножествах данных, использовать различные алгоритмы или иметь разные архитектуры, что обеспечивает разнообразие в процессе классификации и повышает общую производительность системы. Такой подход особенно эффективен в задачах, где данные сложны и неоднозначны, и где ни одна модель не может обеспечить достаточную точность самостоятельно.
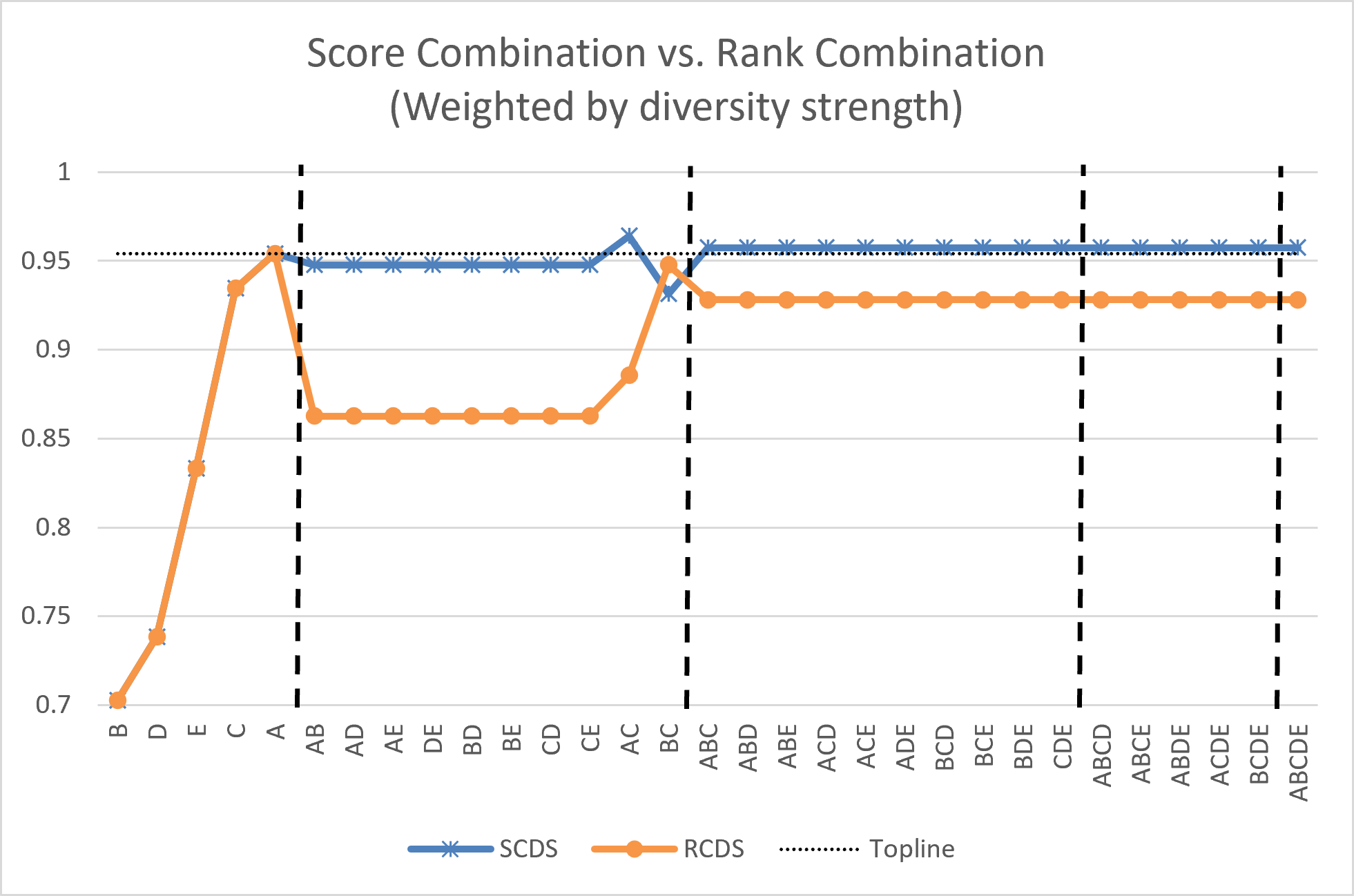
Комбинаторный анализ слияния (Combinatorial Fusion Analysis) представляет собой методологию, в которой ключевым фактором повышения производительности является когнитивное разнообразие — степень несхожести систем оценки, используемых базовыми моделями. Вместо простого усреднения результатов, данный подход направлен на выявление и использование различий в способах, которыми отдельные модели оценивают данные. Предполагается, что модели, демонстрирующие различные паттерны ошибок и использующие разные подходы к классификации, в совокупности способны обеспечить более надежные и точные результаты, чем любая из них по отдельности. Максимизация когнитивного разнообразия достигается путем выбора моделей с различными архитектурами, обучающих данными и принципами работы.
Рангово-оценочная функция (Rank-Score Function) является ключевым элементом анализа, позволяющим детально представить поведение базовых моделей при оценке данных. Вместо простого усреднения оценок, функция учитывает ранги, которые каждая модель присваивает различным вариантам, и выражает это в виде числового значения. Такой подход позволяет выявить не только абсолютную величину оценки, но и степень уверенности модели в конкретном результате, а также различия в ее приоритетах по сравнению с другими моделями. Это особенно важно при комбинировании моделей с различными архитектурами и принципами работы, поскольку позволяет учитывать их индивидуальные особенности и максимизировать общую точность классификации.
Стратегическое объединение результатов работы моделей, таких как SDG Classy, LinkedSDG, SDG Mapper, Convolutional Neural Network и Random Forest, позволяет достичь более высокой точности классификации. В ходе экспериментов предложенный подход продемонстрировал среднюю точность (average precision) в 0.9673. Это превосходит показатели, полученные при использовании тонко настроенной модели BERT (0.9446), и значительно опережает точность, демонстрируемую отдельными моделями — 62.89% скомбинированных моделей превосходили их хотя бы в одной группе ЦУР (SDG).
Результаты экспериментов показали, что предложенный подход, основанный на комбинировании моделей, демонстрирует превосходство над индивидуальными моделями и моделью BERT, прошедшей тонкую настройку. В частности, точность (precision) комбинированной системы составила 0.9673, в то время как точность тонко настроенной модели BERT составила 0.9446. Более того, 62.89% комбинированных моделей превзошли соответствующие индивидуальные модели как минимум в одной группе целей устойчивого развития (SDG), что свидетельствует о синергетическом эффекте от объединения различных подходов к классификации.
Усиление устойчивости: синтетические данные и будущее классификации ЦУР
Генерация синтетических данных, использующая возможности больших языковых моделей, таких как ChatGPT, представляет собой перспективное решение проблемы нехватки размеченных данных, часто препятствующей эффективной классификации Целей устойчивого развития (ЦУР). Вместо того чтобы полагаться исключительно на ограниченные и дорогостоящие наборы данных, алгоритмы способны создавать искусственные примеры текстов, имитирующие реальные документы, относящиеся к различным ЦУР. Этот подход не только увеличивает объем обучающих данных, но и позволяет модели лучше обобщать информацию, выявляя скрытые закономерности и повышая устойчивость к новым, ранее не встречавшимся текстам. Благодаря синтетическим данным, классификация ЦУР становится более точной и надежной, особенно в тех областях, где доступ к реальным данным ограничен или отсутствует.
Использование синтетических данных, полученных с помощью современных языковых моделей, в сочетании с передовыми методами ансамблирования моделей, значительно повышает точность и надежность классификации текстов по Целям устойчивого развития (ЦУР). Такой подход позволяет преодолеть ограничения, связанные с недостатком размеченных данных, и обеспечивает более устойчивые результаты. Комбинирование нескольких моделей, обученных на синтетических и реальных данных, позволяет нивелировать индивидуальные ошибки и повысить общую производительность системы. В результате достигается не только более точная классификация, но и повышение устойчивости к изменениям в данных, что критически важно для долгосрочного мониторинга прогресса в достижении ЦУР.
Исследования показали, что комбинированные модели, использующие синтетические данные, демонстрируют значительное превосходство над отдельными моделями при классификации Целей устойчивого развития (ЦУР). В 92.19% случаев, ансамбли моделей превосходят средний показатель эффективности отдельных моделей по всем ЦУР. Более того, в 47.12% случаев, точность комбинированных моделей оказалась равной или выше, чем у лучшей из индивидуальных моделей, что указывает на существенное улучшение способности к точному определению и анализу данных, необходимых для мониторинга прогресса в достижении устойчивого будущего. Данный результат подтверждает эффективность подхода, основанного на объединении моделей и использовании синтетических данных, для повышения надежности и точности классификации.
Разработанная система представляет собой мощный инструмент для обработки больших объемов текстовой информации, позволяющий извлекать ценные сведения для лиц, принимающих решения. Она способна эффективно анализировать разнообразные источники данных — от отчетов международных организаций до публикаций в социальных сетях — и выявлять ключевые тенденции, связанные с достижением Целей устойчивого развития. Благодаря высокой скорости обработки и точности анализа, система предоставляет своевременную и релевантную информацию, необходимую для разработки эффективных стратегий и мониторинга прогресса в области устойчивого развития. Полученные результаты позволяют не только оценивать текущую ситуацию, но и прогнозировать будущие изменения, что открывает новые возможности для проактивного управления и принятия обоснованных решений.
Данный подход к классификации Целей устойчивого развития (ЦУР) выходит за рамки простого отнесения текстов к определенным категориям. Вместо этого, система представляет собой динамически адаптируемый инструмент, способный отслеживать прогресс в достижении этих целей в режиме реального времени. Благодаря использованию синтетических данных и методов ансамблевого обучения, она не только повышает точность анализа, но и позволяет учитывать меняющиеся контексты и новые тенденции. Это создает возможность для формирования более эффективных стратегий и принятия обоснованных решений, направленных на обеспечение устойчивого будущего, и обеспечивает постоянную оценку эффективности предпринимаемых мер.
Исследование демонстрирует стремление к оптимизации классификации текстов, связанных с Целями устойчивого развития. Авторы, подобно тем, кто ищет наиболее лаконичное выражение истины, применяют Combinatorial Fusion Analysis для объединения моделей машинного обучения. Этот подход позволяет достичь большей точности, приближаясь к экспертным оценкам. Как однажды заметил Блез Паскаль: «Все великие вещи требуют времени». И в данном случае, сочетание различных моделей и генерация синтетических данных — это инвестиция времени, приводящая к более надежным результатам в области классификации текстов, что, в свою очередь, способствует более эффективному достижению Целей устойчивого развития.
Что дальше?
Представленная работа, стремясь к уточнению классификации текстов, связанных с Целями устойчивого развития, лишь обнажила фундаментальную сложность задачи. Улучшение метрик — это, конечно, полезно, но само по себе не является ответом. Истинный вопрос заключается не в том, как классифицировать больше текстов, а в том, действительно ли классификация — это подходящий инструмент. Ведь любое упрощение, любая категоризация — это неизбежное искажение смысла. Система, требующая подробных инструкций для понимания своей цели, уже проиграла.
Дальнейшие исследования должны сосредоточиться не на усложнении моделей, а на их очищении. Генерирование синтетических данных — это временное решение, подобное затычке в прохудившемся корпусе. Гораздо важнее понять, какие именно знания необходимы модели для принятия обоснованных решений, и как эти знания можно передать наиболее лаконичным образом. Понятность — это вежливость, и алгоритм, не способный объяснить свою логику, не заслуживает доверия.
Настоящий прогресс не измеряется в процентах точности, а в способности отказаться от излишнего. Идеальная модель — это не та, которая содержит все возможные параметры, а та, от которой можно избавиться без потери смысла. Стремление к совершенству — это не накопление, а вычитание.
Оригинал статьи: https://arxiv.org/pdf/2602.11168.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-13 18:39