Автор: Денис Аветисян
Новая модель AgentCPM-Explore демонстрирует впечатляющие результаты в сложных задачах, требующих стратегического мышления и адаптации к изменяющейся среде.
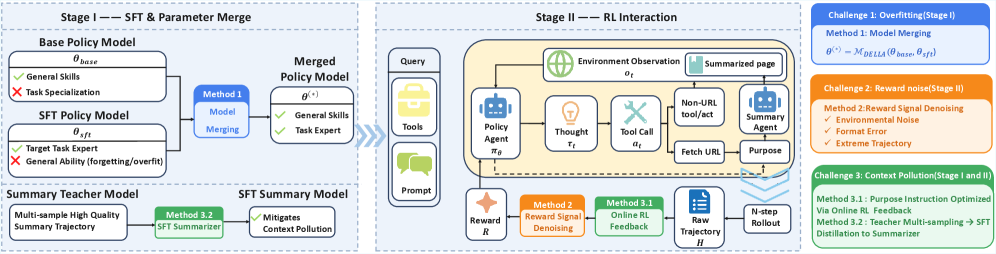
Разработана 4-параметровая языковая модель, использующая методы слияния моделей, фильтрации сигналов вознаграждения и уточнения контекстной информации для достижения передовых результатов в задачах обучения с подкреплением.
Несмотря на впечатляющий потенциал агентов на основе больших языковых моделей, их возможности на устройствах с ограниченными ресурсами остаются недостаточно изученными. В данной работе, посвященной ‘AgentCPM-Explore: Realizing Long-Horizon Deep Exploration for Edge-Scale Agents’, представлено первое систематическое исследование обучения агентов с \mathcal{N}=4 миллиардами параметров. Предложенная модель AgentCPM-Explore демонстрирует передовые результаты среди моделей аналогичного размера, превосходя или сравниваясь по эффективности с моделями в 8 раз больше, благодаря применению слияния моделей в параметрическом пространстве, подавлению шумов в сигналах вознаграждения и уточнению контекстной информации. Не является ли ограничением для моделей, работающих на периферийных устройствах, не их теоретический предел, а стабильность их работы на практике?
Вызов Долгосрочного Планирования
Традиционные системы обучения с подкреплением, такие как veRL, сталкиваются с существенными трудностями при решении задач, требующих долгосрочного планирования и отложенного вознаграждения. Суть проблемы заключается в том, что стандартные алгоритмы испытывают экспоненциальный рост сложности по мере увеличения длительности планируемой последовательности действий. Это приводит к тому, что агент теряет способность эффективно оценивать отдаленные последствия своих действий, отдавая предпочтение немедленным, но менее оптимальным решениям. В результате, даже относительно простые задачи, требующие нескольких шагов для достижения цели, становятся непосильными для таких систем, поскольку сигнал вознаграждения, поступающий лишь в конце выполнения, недостаточно силен, чтобы направить обучение в правильном направлении. Такая неспособность к долгосрочному планированию ограничивает применимость существующих методов обучения с подкреплением к широкому кругу сложных и реалистичных сценариев.
Исследования показали, что простое увеличение размера модели искусственного интеллекта не является достаточным условием для успешного решения задач, требующих долгосрочного планирования и анализа. Для эффективной навигации в сложных сценариях и получения отложенного вознаграждения, агентам необходимы надёжные механизмы сохранения контекста. В этой связи, разработка AgentCPM-Explore демонстрирует значительный прорыв, позволяя достичь передовых результатов, сопоставимых с моделями, содержащими до 30 миллиардов параметров, при этом сам AgentCPM-Explore имеет размер всего 4 миллиарда параметров. Это указывает на то, что ключевым фактором является не масштаб модели, а её архитектура и способность к эффективному управлению контекстом, открывая новые перспективы для создания более компактных и производительных интеллектуальных агентов.
AgentCPM-Explore: Новая Архитектура Агента
Агент CPM-Explore представляет собой агентную модель масштаба 4B параметров, разработанную для обеспечения высокой плотности возможностей и эффективной работы в сложных средах. Несмотря на относительно небольшой размер, модель спроектирована для достижения высокой производительности за счет оптимизации архитектуры и эффективного использования параметров. Это позволяет AgentCPM-Explore эффективно решать задачи в сложных сценариях, требующих адаптации и принятия решений, при этом минимизируя вычислительные затраты и требования к памяти.
Ключевой инновацией в архитектуре AgentCPM-Explore является применение слияния моделей в пространстве параметров. Этот подход позволяет объединить преимущества обобщения, присущего большим языковым моделям, со специализированными навыками, полученными в процессе обучения для конкретных задач. Вместо обучения отдельных моделей для каждой задачи, происходит объединение весов нескольких моделей, что позволяет AgentCPM-Explore эффективно использовать свои параметры для достижения высокой производительности в разнообразных сценариях, сохраняя при этом компактный размер и эффективность вычислений. Такой метод позволяет модели быстро адаптироваться к новым задачам и демонстрировать конкурентоспособные результаты при ограниченных вычислительных ресурсах.
Архитектура AgentCPM-Explore использует асинхронное обучение для повышения скорости обучения и эффективности использования данных. В ходе тестирования на бенчмарке GAIA, модель продемонстрировала превосходство над WebDancer (QWQ-32B) с результатом на 12.4 процентных пункта выше. Асинхронный подход позволяет параллельно выполнять задачи обучения, сокращая общее время, необходимое для достижения заданного уровня производительности, и снижая потребность в больших объемах обучающих данных.
Устойчивость благодаря Очистке Сигнала Вознаграждения
Агент CPM-Explore использует сложный конвейер шумоподавления сигнала вознаграждения для смягчения последствий неидеальных сред и неточных вознаграждений. Этот конвейер предназначен для выявления и коррекции ложных сигналов, возникающих из-за несовершенства окружения или ошибок в системе вознаграждения. Применяется фильтрация траекторий, отсеивающая нерелевантные или ошибочные последовательности действий, а также фильтрация шума окружающей среды, устраняющая случайные помехи, влияющие на оценку вознаграждения. Дополнительно, система фильтрует ошибки форматирования, обеспечивая корректную интерпретацию входных данных и стабильность работы агента в различных условиях.
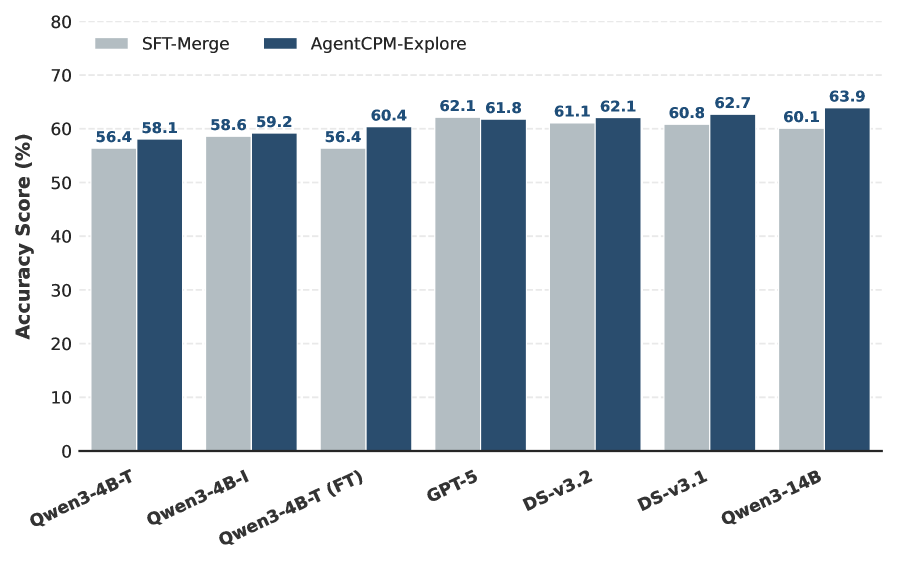
В AgentCPM-Explore применяется многоуровневая система фильтрации сигналов вознаграждения, включающая в себя экстремальную фильтрацию траекторий, фильтрацию шумов окружающей среды и фильтрацию ошибок формата. Экстремальная фильтрация траекторий направлена на исключение нереалистичных или невозможных последовательностей действий. Фильтрация шумов окружающей среды уменьшает влияние случайных помех и неточностей в данных, поступающих из окружения. Фильтрация ошибок формата корректирует несоответствия в структуре данных вознаграждения, обеспечивая корректную интерпретацию сигналов и повышая устойчивость агента к некачественным данным.
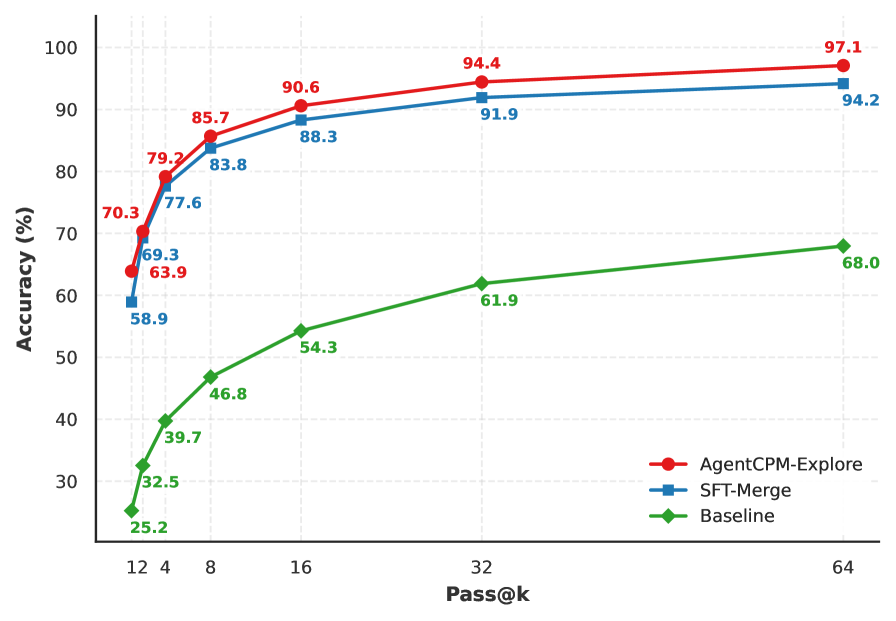
Улучшение качества входных данных за счет уточнения контекстной информации повышает способность агента к пониманию окружающей среды. В рамках системы AgentCPM-Explore реализован процесс, направленный на повышение точности интерпретации получаемых данных. Результаты тестирования на бенчмарке GAIA с использованием методики Pass@64 демонстрируют достижение уровня точности в 97.09%, что свидетельствует об эффективности предложенного подхода к обработке и анализу контекстной информации.
Оркестровка Агентов и Валидация Производительности
Инфраструктура AgentDock обеспечивает основу для оркестровки контейнеров, унифицированной маршрутизации и выполнения инструментов, значительно упрощая развертывание AgentCPM-Explore. Эта система позволяет эффективно управлять ресурсами и процессами, необходимыми для работы агента, автоматизируя многие рутинные задачи, связанные с настройкой и масштабированием. Благодаря AgentDock, разработчики могут сосредоточиться на совершенствовании логики агента, а не на сложностях инфраструктуры. Унифицированная маршрутизация обеспечивает гибкость и адаптивность системы, позволяя легко интегрировать новые инструменты и сервисы. В результате, AgentCPM-Explore может быть развернут и запущен с минимальными усилиями, обеспечивая высокую производительность и надежность.
Для оценки возможностей AgentCPM-Explore в решении сложных задач, требующих обработки большого объема информации, использовались эталонные тесты GAIA и HLE. Результаты показали, что AgentCPM-Explore демонстрирует впечатляющую производительность, особенно в сценариях, связанных с логическим выводом и анализом контекста. В частности, на бенчмарке FRAMES агент достиг показателя в 82.7%, что на 8.2 процентных пункта превосходит результат ASearcher-32B и на 11.7 процентных пункта — IterResearch-30B. Данные результаты подтверждают эффективность AgentCPM-Explore в задачах, требующих глубокого понимания и анализа информации, и подчеркивают его потенциал для применения в различных областях, где важна способность к сложному рассуждению.
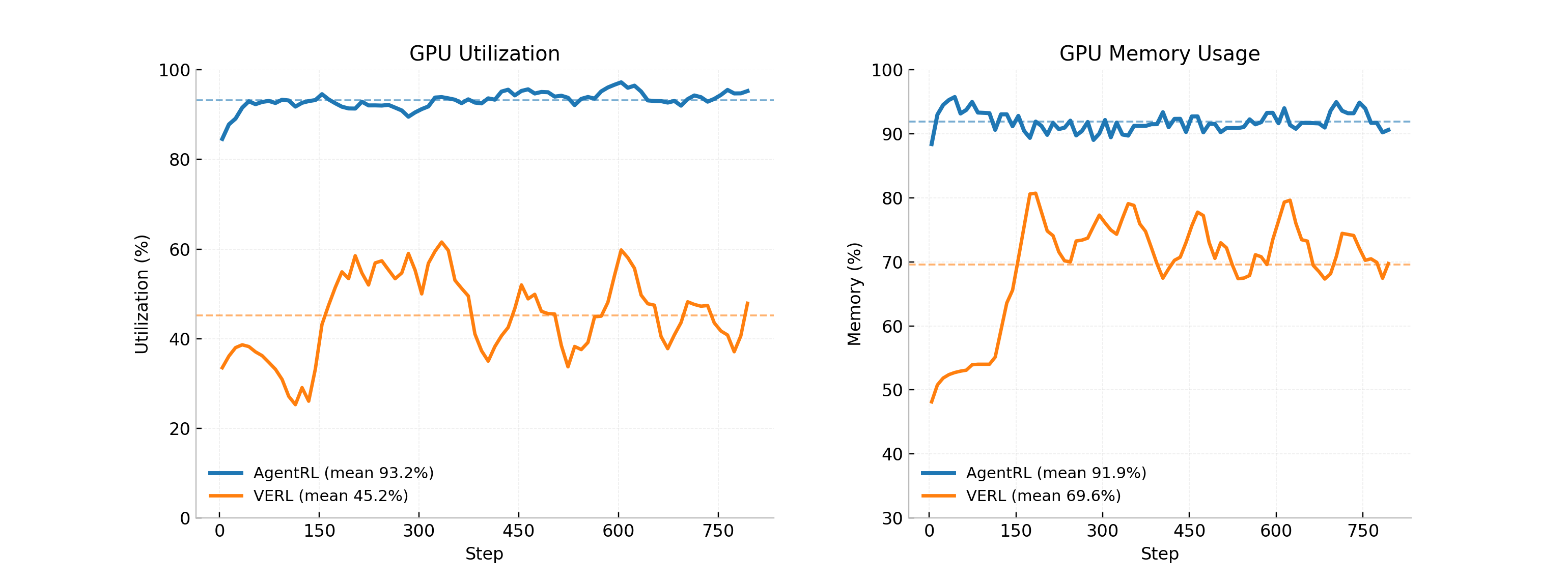
Для дальнейшей оптимизации производительности агента была разработана среда AgentRL, использующая асинхронное обучение. Этот подход позволяет значительно повысить эффективность использования графических процессоров — в ходе тестирования достигнута утилизация GPU на уровне 93.2%, что существенно превосходит показатели veRL (45.2%). Кроме того, AgentRL демонстрирует более эффективное использование памяти GPU (91.9% против 69.6% у veRL), что позволяет проводить обучение более сложных моделей и работать с большими объемами данных, обеспечивая тем самым значительное улучшение общей производительности агента в различных сценариях.
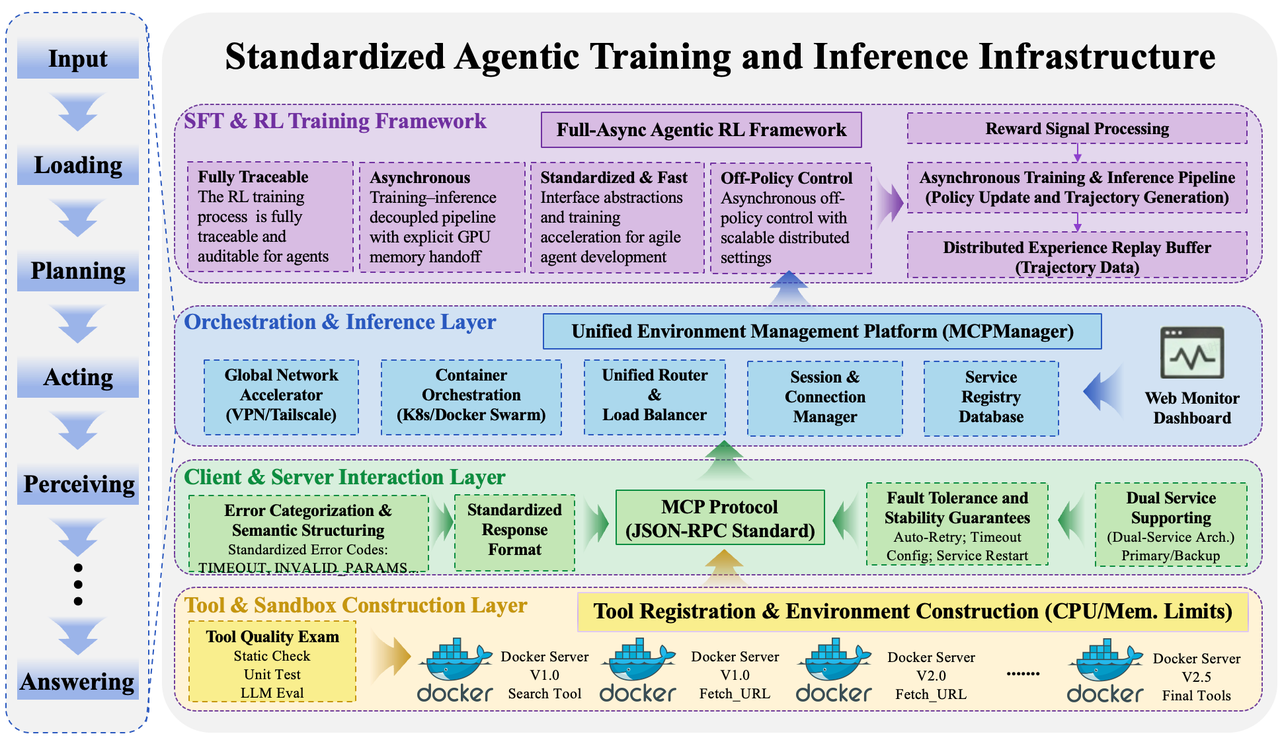
Исследование демонстрирует, что даже относительно небольшие языковые модели, такие как AgentCPM-Explore, способны достигать передовых результатов в задачах, требующих долгосрочного планирования и взаимодействия со средой. Подобно тому, как математик ищет элегантные решения сложных задач, авторы работы используют методы слияния моделей и очистки сигнала вознаграждения, чтобы оптимизировать производительность. Карл Фридрих Гаусс однажды сказал: «Я не знаю, как я кажусь миру, но мне кажется, что я подобен ребёнку, играющему с морскими ракушками, в то время как другие находят могущественные камни». Этот подход к исследованию, когда из простых элементов создается нечто мощное, полностью соответствует философии, лежащей в основе AgentCPM-Explore, особенно в части повышения эффективности и параметризации больших моделей.
Куда же дальше?
Представленная работа, безусловно, демонстрирует изящный способ выжать максимум из ограниченных ресурсов. Слияние моделей, очистка сигналов вознаграждения, утончение контекста — все это, конечно, инструменты, но инструменты всегда задают вопрос: а что дальше? Очевидно, что борьба за параметрическую эффективность — это лишь один фланг. Истинный вызов — в создании систем, способных не просто выполнять задачи, но и адаптироваться к непредсказуемости реального мира, к его намеренному хаосу.
Проблема, как обычно, не в самих моделях, а в сигналах, которые они получают. Очистка шума — это хорошо, но что, если сам шум — это и есть информация, которую система должна научиться фильтровать и интерпретировать? И если мы говорим о «агентах», то не стоит ли пересмотреть саму концепцию вознаграждения? Не слишком ли мы полагаемся на примитивные стимулы, вместо того чтобы дать системе возможность самостоятельно формировать свои цели и ценности?
В конечном итоге, AgentCPM-Explore — это ещё один шаг в долгой игре. Игра, в которой правила постоянно меняются, а победа заключается не в достижении поставленной цели, а в способности постоянно переосмысливать саму концепцию игры. И, как всегда, самые интересные открытия ждут тех, кто готов сломать систему, чтобы понять, как она работает.
Оригинал статьи: https://arxiv.org/pdf/2602.06485.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-10 03:03