Автор: Денис Аветисян
Исследователи разработали инновационную систему, использующую возможности больших языковых моделей для анализа и прогнозирования действий в задачах, требующих последовательности действий на протяжении длительного времени.
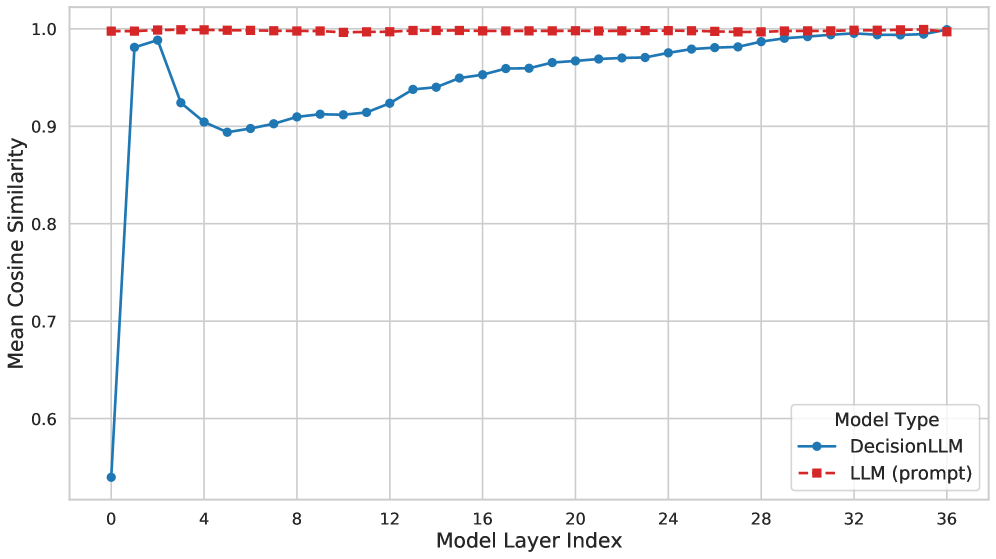
Представлен DecisionLLM — фреймворк, объединяющий данные о траекториях и текст для обучения больших языковых моделей эффективному принятию решений в задачах с длинными последовательностями, что демонстрирует важность качества данных и масштабирования модели.
В задачах последовательного принятия решений, особенно в динамичных средах, традиционные методы обучения с подкреплением сталкиваются с ограничениями в обработке длинных последовательностей. В настоящей работе, ‘DecisionLLM: Large Language Models for Long Sequence Decision Exploration’, предложен новый подход, использующий большие языковые модели (LLM) для анализа траекторий как отдельной модальности, что позволяет эффективно прогнозировать будущие действия. Эксперименты демонстрируют, что производительность DecisionLLM напрямую зависит от масштаба модели, объема данных и их качества, превосходя традиционные методы, такие как Decision Transformer, в задачах оптимизации стратегий в аукционах и лабиринтах. Каковы перспективы дальнейшего развития данной парадигмы и её применения в более сложных сценариях онлайн-обучения?
Преодоление Горизонта: Проблема Долгосрочного Планирования
Традиционные методы обучения с подкреплением зачастую испытывают трудности при решении задач, требующих последовательности действий на протяжении длительного времени. Обучающие алгоритмы склонны к «близорукости», фокусируясь на немедленной награде и упуская из виду долгосрочные последствия своих действий. Это происходит из-за того, что оценка ценности отдаленных событий становится все более сложной и подвержена ошибкам по мере увеличения горизонта планирования. В результате, агент может выбирать действия, которые приносят небольшую выгоду в настоящий момент, но ведут к неоптимальному результату в будущем, не демонстрируя способности к последовательному достижению поставленной цели на протяжении всей задачи.
Для успешного решения задач с долгосрочным планированием, агенты должны обладать способностью предвидеть отдаленные последствия своих действий и придерживаться последовательных целей. Это требует не просто реакции на непосредственные стимулы, но и построения внутренней модели мира, позволяющей оценивать долгосрочную ценность различных стратегий. По сути, агент должен действовать как шахматист, просчитывая несколько ходов вперед, а не как игрок в пинг-понг, реагирующий исключительно на текущий мяч. Такая способность к прогнозированию и целеустремленности критически важна для задач, где немедленная выгода может противоречить долгосрочному успеху, например, в робототехнике, автономном вождении или финансовом моделировании. Отсутствие этой способности приводит к «близрукости» и принятию субоптимальных решений.
Современные методы обучения с подкреплением, несмотря на впечатляющие успехи в решении узкоспециализированных задач, часто демонстрируют ограниченную применимость в реальных условиях. Обучение, требующее значительных объемов данных и длительного времени, становится серьезным препятствием, особенно при переходе к новым, незнакомым средам. Агенты, эффективно действующие в лабораторных условиях, нередко терпят неудачу при столкновении с вариативностью и непредсказуемостью реального мира. Это связано с тем, что существующие алгоритмы склонны к «заучиванию» конкретных ситуаций, а не к формированию обобщенных стратегий, способных адаптироваться к изменениям и обеспечивать надежное функционирование в неизвестных окружениях. В результате, масштабирование и внедрение таких систем сталкивается с существенными трудностями, ограничивая их практическую ценность и требуя разработки новых подходов к обучению, ориентированных на обобщение и адаптивность.
Автономное Обучение: Путь к Освоению Опыта
Обучение с подкреплением в автономном режиме (Offline Reinforcement Learning) представляет собой перспективный подход, позволяющий агентам приобретать навыки на основе статических наборов данных, минуя необходимость дорогостоящего и потенциально опасного взаимодействия со средой в реальном времени. Вместо активного сбора данных посредством проб и ошибок, алгоритмы используют заранее собранные данные, что существенно снижает затраты на обучение и делает возможным применение обучения с подкреплением в сценариях, где взаимодействие с окружающей средой ограничено или невозможно. Это особенно важно для задач, связанных с робототехникой, автономным вождением и другими приложениями, требующими высокой степени надежности и безопасности.
Использование мощных генеративных моделей, таких как диффузионные модели (Diffusion Models) и архитектуры Transformer, в рамках offline обучения с подкреплением (offline RL) позволяет эффективно извлекать стратегии управления из ограниченных наборов данных. Эти модели, изначально разработанные для генерации данных, применяются для моделирования распределения данных о траекториях, что позволяет агенту оценивать и улучшать свои действия, не требуя дальнейшего взаимодействия со средой. В частности, архитектуры Transformer эффективно захватывают долгосрочные зависимости в последовательностях действий, а диффузионные модели позволяют генерировать правдоподобные траектории, даже при недостатке данных, что повышает устойчивость и обобщающую способность полученной стратегии.
Обучение с подкреплением в автономном режиме (offline RL) позволяет избежать сложностей, связанных с исследованием среды, характерных для традиционных алгоритмов RL. Однако, успешное применение offline RL требует тщательного анализа распределения данных в используемом статичном наборе данных. Несоответствие между распределением данных обучения и реальным распределением, с которым сталкивается агент при развертывании, может привести к значительной деградации производительности. Поэтому критически важно обеспечивать хорошую обобщающую способность обученной политики на данные, отличные от тех, на которых она обучалась, используя методы регуляризации или алгоритмы, устойчивые к расхождениям в распределениях.
DecisionLLM: Объединение Траекторий и Текста для Разумных Действий
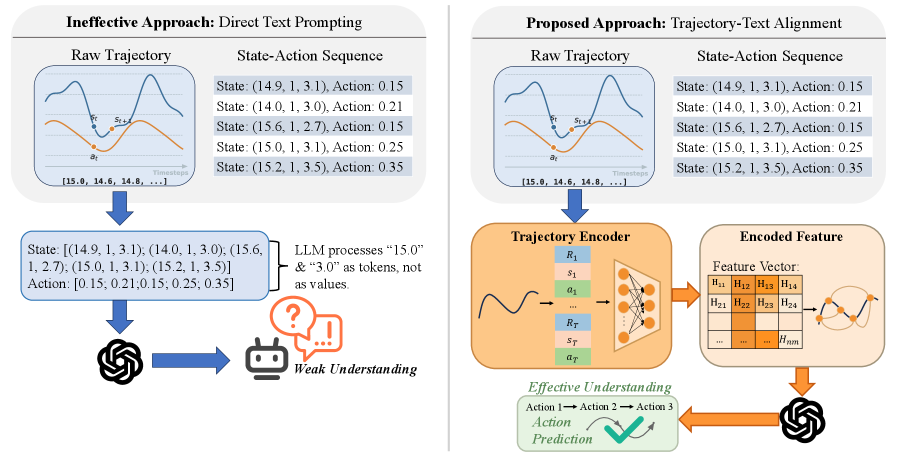
DecisionLLM представляет собой мультимодальную архитектуру, объединяющую обработку данных о траекториях и текстовых запросов для обеспечения принятия решений в долгосрочных последовательностях. В отличие от традиционных подходов, где данные о состоянии и действиях обрабатываются отдельно, DecisionLLM позволяет модели одновременно анализировать как непрерывные данные о движении (траектории), так и дискретные текстовые инструкции. Это достигается за счет совместной обработки этих двух модальностей, что позволяет модели учитывать контекст прошлых действий и целей при планировании будущих шагов, обеспечивая более когерентное и эффективное принятие решений в сложных, динамических средах.
Процесс кодирования и выравнивания траекторий в DecisionLLM преобразует непрерывные последовательности состояний и действий в формат, понятный для больших языковых моделей (LLM). Это достигается путем представления данных о траектории в виде дискретных токенов, которые могут быть обработаны LLM. Выравнивание обеспечивает соответствие между этими токенами и текстовыми подсказками, что позволяет модели эффективно использовать информацию о прошлых действиях и предвидеть будущие исходы. Данный подход позволяет LLM рассуждать о последовательностях действий, представленных в виде непрерывных данных, и генерировать последовательные планы действий, что критически важно для задач долгосрочного принятия решений.
Архитектура DecisionLLM позволяет большой языковой модели (LLM) анализировать последовательность прошлых действий, прогнозировать возможные последствия и формировать последовательные планы. Это подтверждено результатами тестов на различных платформах: в среде Maze2D-umaze-v1 достигнут прирост производительности в 69.4 пункта по сравнению с Decision Transformer, а в среде AuctionNet получен результат 0.058. Данные результаты демонстрируют способность модели к эффективному принятию решений на основе анализа траекторий и текстовых подсказок.
Расширяя Горизонты: Практическое Применение в Реальном Мире
Система DecisionLLM открывает новые возможности для создания интеллектуальных агентов, способных к функционированию в сложных сферах, таких как робототехника и автономное вождение. Используя потенциал больших языковых моделей, система позволяет роботам и беспилотным транспортным средствам принимать решения на основе анализа и понимания естественного языка. Это позволяет создавать более гибкие и адаптивные системы, способные реагировать на изменяющиеся условия окружающей среды и выполнять сложные задачи без предварительного программирования каждого сценария. В результате, DecisionLLM способствует развитию автономных систем, способных к более эффективному и безопасному взаимодействию с миром.
В основе DecisionLLM лежит концепция управления на основе запросов, позволяющая агентам принимать решения, основываясь на естественном языке. Вместо сложных программных кодов или жестко заданных алгоритмов, система интерпретирует человеческие инструкции, сформулированные в виде простых запросов. Это обеспечивает не только интуитивно понятное управление, но и адаптивность к динамично меняющимся условиям окружающей среды. Агент способен реагировать на новые обстоятельства, корректируя свои действия в соответствии с полученными указаниями, что особенно важно для таких областей, как робототехника и автономное вождение, где предсказуемость и гибкость являются ключевыми факторами успеха. Возможность обучения и уточнения поведения агента посредством естественного языка открывает новые горизонты для взаимодействия человека и искусственного интеллекта.
Закономерности масштабирования демонстрируют, что дальнейшее увеличение вычислительных мощностей и объемов данных, используемых для обучения больших языковых моделей, будет напрямую приводить к существенному улучшению их способности принимать решения. Исследования показывают, что по мере роста параметров модели, её эффективность в сложных задачах, требующих логического мышления и адаптации к новым условиям, экспоненциально возрастает. Это означает, что будущие поколения LLM смогут не просто понимать инструкции на естественном языке, но и самостоятельно разрабатывать стратегии, предвидеть последствия и эффективно действовать в динамично меняющейся среде, открывая новые возможности для создания автономных систем и интеллектуальных агентов, способных решать задачи, ранее недоступные для искусственного интеллекта.
Исследование демонстрирует, что успешное применение больших языковых моделей к задачам последовательного принятия решений напрямую зависит от качества и структуры данных. DecisionLLM, представляя траектории как отдельную модальность наряду с текстом, позволяет модели извлекать более глубокие закономерности и предсказывать действия с повышенной точностью. Как однажды заметил Роберт Тарьян: «В конечном итоге, все сводится к алгоритмам». Эта мысль особенно актуальна в контексте DecisionLLM, где элегантность и математическая точность алгоритмов обработки данных определяют эффективность всего подхода. Успех модели в задачах, требующих долгосрочного планирования, подтверждает, что только корректные и доказуемые алгоритмы способны справиться с хаосом данных и обеспечить надежные результаты.
Куда же дальше?
Представленная работа, несомненно, демонстрирует потенциал расширения возможностей больших языковых моделей за пределы обработки естественного языка, в область принятия решений в задачах с длинными последовательностями. Однако, следует признать, что успех DecisionLLM зиждется на предположении о том, что траектории данных можно рассматривать как ещё одну форму текста. Это элегантно, но требует строгого математического обоснования. Достаточно ли простого выравнивания траектории и текста, или необходима более глубокая, формальная теория представления действий и состояний? Доказательство корректности, а не просто эмпирические результаты, должно стать приоритетом.
Ключевым ограничением остается зависимость от качества данных. Улучшение производительности при масштабировании модели — закономерно, но не решает фундаментальную проблему: “мусор на входе — мусор на выходе”. Необходимо разработать метрики и методы оценки качества траекторий, независимые от конкретной задачи. Более того, остается открытым вопрос о возможности обобщения: способна ли модель, обученная на одной задаче, эффективно решать принципиально новые задачи принятия решений, или каждое новое приложение потребует повторного обучения с нуля?
В конечном итоге, настоящий прогресс потребует не простого масштабирования моделей и улучшения качества данных, но и разработки формальной теории представления знаний о действиях и состояниях, позволяющей языковым моделям не просто предсказывать действия, но и понимать их последствия и обосновывать их выбор. Иначе, мы имеем дело с искусной имитацией интеллекта, а не с его подлинным проявлением.
Оригинал статьи: https://arxiv.org/pdf/2601.10148.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-01-16 20:33