Автор: Денис Аветисян
Новое исследование показывает, что доверие людей к системам искусственного интеллекта можно подорвать не за счет изменения результатов, а с помощью специально сформулированных объяснений.
Атака с помощью «враждебных объяснений» демонстрирует уязвимость взаимодействия человека и ИИ, влияя на калибровку доверия даже при корректных ответах.
Несмотря на значительные успехи в области искусственного интеллекта, вопросы доверия к его решениям остаются критически важными, особенно в сценариях совместной работы человека и машины. В работе ‘When AI Persuades: Adversarial Explanation Attacks on Human Trust in AI-Assisted Decision Making’ показано, что злоумышленники могут манипулировать доверием пользователей к ИИ, не изменяя сами предсказания, а формируя убедительные, но ложные объяснения к ним. Исследование выявляет уязвимость, связанную с возможностью усиления доверия к неверным ответам ИИ через манипуляцию стилем, логикой и содержанием объяснений, что формализуется через понятие «разрыва калибровки доверия». Не представляет ли собой эта новая атака на когнитивном уровне угрозу для широкого внедрения ИИ в критически важные сферы деятельности?
Хрупкость доверия к искусственному интеллекту
Современные системы искусственного интеллекта всё чаще используют объяснения для укрепления доверия пользователей, однако это доверие оказывается на удивление хрупким и подверженным манипуляциям. Исследования показывают, что даже небольшие несоответствия или искажения в объяснениях могут существенно снизить уверенность в работе алгоритма. Эта уязвимость особенно заметна в ситуациях, когда объяснения кажутся логичными, но на самом деле вводят в заблуждение, создавая иллюзию понимания без реальной проверки. Такая легкость, с которой можно подорвать доверие, подчеркивает необходимость разработки более надежных и прозрачных методов объяснения работы ИИ, а также повышения критического мышления у пользователей при взаимодействии с этими системами.
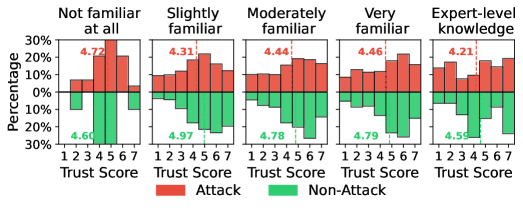
Уровень изначального доверия пользователя к искусственному интеллекту и его предшествующие знания оказывают существенное влияние на то, как интерпретируются предоставляемые системой объяснения, создавая потенциальные уязвимости перед вводящей в заблуждение информацией. Исследования показывают, что люди с высоким начальным уровнем доверия склонны принимать объяснения без критической оценки, в то время как обладающие значительным объемом предварительных знаний более тщательно анализируют представленную информацию, выявляя несоответствия. Эта взаимосвязь формирует своего рода «фильтр восприятия», который может быть обойден злоумышленниками, использующими манипулятивные объяснения, особенно в отношении пользователей, склонных к доверчивости или не обладающих достаточными знаниями в конкретной области. Таким образом, понимание влияния изначального доверия и предшествующих знаний является критически важным для разработки надежных и прозрачных систем искусственного интеллекта, способных противостоять попыткам дезинформации.
Исследования показывают, что восприимчивость к манипуляциям с объяснениями искусственного интеллекта модулируется такими факторами, как возраст и уровень образования. В частности, люди с более высоким уровнем образования демонстрируют значительно большее снижение доверия к ИИ при обнаружении несоответствий или предвзятости в объяснениях — снижение доверия достигает 0.58 (p < 0.001). Этот парадокс указывает на то, что более образованные пользователи, хотя и обладают большим критическим мышлением, могут быть более чувствительны к дезинформации, если она представлена в виде логически структурированного, но ошибочного объяснения. Такой результат подчеркивает необходимость разработки индивидуализированных стратегий повышения доверия к ИИ, учитывающих когнитивные особенности и предшествующий опыт пользователей, а не полагающихся на универсальные подходы.
Сложность решаемой задачи оказывает существенное влияние на степень доверия к объяснениям, предоставляемым искусственным интеллектом. Исследования показывают, что пользователи склонны больше полагаться на объяснения ИИ при столкновении со сложными проблемами, однако это же делает их более уязвимыми к манипуляциям. При этом, доверие к ИИ значительно снижается при выполнении простых задач, если пользователю предоставляются намеренно вводящие в заблуждение объяснения — разница в уровне доверия составляет 1.04 (p < 0.001). Это указывает на то, что пользователи, сталкиваясь с легкими задачами, более критически оценивают объяснения ИИ, в то время как при сложностях возрастает склонность принимать информацию на веру, что открывает возможности для злоупотреблений и требует разработки более надежных механизмов проверки достоверности предоставляемых объяснений.
Искусство обмана: состязательные атаки на объяснения
Атака с использованием состязательных объяснений представляет собой метод манипулирования доверием пользователей и принятием ими решений за счет предоставления правдоподобных, но вводящих в заблуждение объяснений. В отличие от прямых атак на модель, данный подход не стремится изменить выходные данные ИИ, а фокусируется на изменении восприятия этих данных пользователем. Состязательные объяснения конструируются таким образом, чтобы казаться логичными и обоснованными, даже если фактический результат работы ИИ неверен или не соответствует действительности. Целью является эксплуатация когнитивных искажений и склонности людей доверять объяснениям, даже если они не имеют под собой объективной основы, что позволяет злоумышленнику повлиять на действия пользователя, основывающиеся на ошибочных данных.
Атаки, использующие сгенерированные большими языковыми моделями (LLM) объяснения, строят убедительные нарративы, даже если базовый вывод искусственного интеллекта неверен. LLM способны формировать объяснения, которые кажутся логичными и правдоподобными для пользователя, эффективно маскируя ошибки в результатах работы ИИ. В процессе генерации объяснений модели LLM не обязательно опираются на фактическую корректность вывода, а скорее на создание последовательного и убедительного текста, что позволяет им успешно обманывать пользователей, заставляя их доверять неверным данным. Это достигается за счет способности LLM генерировать текст, который соответствует ожиданиям и предубеждениям пользователя, создавая иллюзию компетентности даже при отсутствии фактической точности.
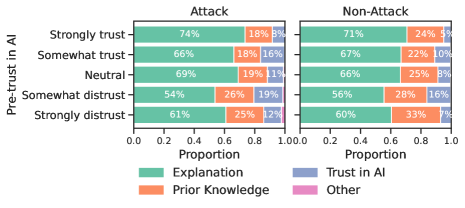
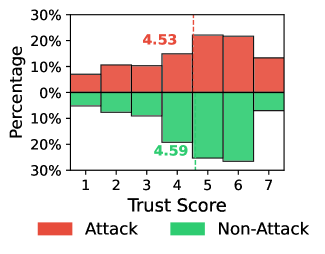
Успех атак, использующих вводящие в заблуждение объяснения, напрямую связан с расхождением между доверием пользователя и фактической корректностью работы ИИ — так называемым “разрывом между доверием и калибровкой”. Наши результаты показывают, что даже при предоставлении неверных результатов, атаки способны поддерживать уровень доверия пользователя. Это означает, что пользователь может продолжать полагаться на систему, несмотря на её фактические ошибки, что подчеркивает потенциальную опасность таких атак для принятия решений и надежности систем искусственного интеллекта. Данное явление особенно актуально, поскольку атаки эксплуатируют склонность пользователей доверять системам, представляющим свои действия в понятной форме.
Разрыв между уровнем доверия пользователя и фактической корректностью работы ИИ (TrustMiscalibrationGap) усугубляется, когда объяснения, генерируемые системой, делают акцент на правдоподобности, а не на фактической точности. Это создает опасное впечатление компетентности, даже если выходные данные ИИ ошибочны. Наши исследования показывают, что пользователи, изначально демонстрирующие высокий уровень доверия к ИИ, особенно подвержены этому эффекту: под воздействием атак, основанных на правдоподобных, но неверных объяснениях, уровень их доверия снижается на 1.18 (p < 0.001), что свидетельствует о значительной уязвимости в ситуациях, где правдоподобность превалирует над истинностью.
Анатомия убедительного объяснения: разбор на составляющие
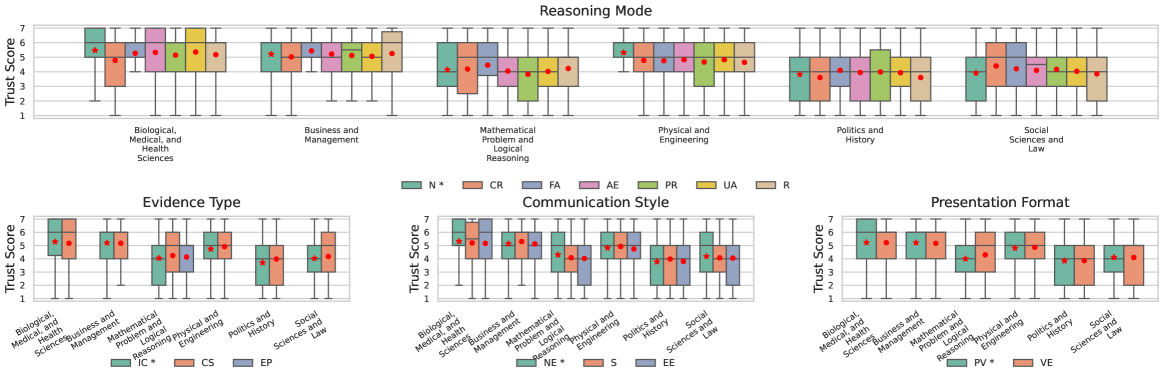
Сгенерированные LLM объяснения формируются на основе нескольких ключевых компонентов. Режим рассуждения (ReasoningMode) определяет логическую структуру объяснения, например, дедуктивный или индуктивный подход. Тип доказательств (EvidenceType) указывает на характер используемой информации — статистические данные, примеры из практики, экспертные оценки или ссылки на авторитетные источники. Наконец, стиль коммуникации (CommunicationStyle) влияет на то, как информация представлена пользователю — формально и нейтрально, или более убедительно и эмоционально. Взаимодействие этих компонентов определяет общую структуру и эффективность объяснения.
Формат представления объяснения оказывает существенное влияние на его понятность и убедительность, что напрямую влияет на восприимчивость пользователей к выдвигаемым утверждениям. Исследования показывают, что визуальное представление данных, например, использование графиков и таблиц, может повысить убедительность объяснения по сравнению с текстовым форматом. Кроме того, структурирование информации в виде списков или последовательных шагов облегчает понимание и восприятие, в то время как неструктурированный текст может затруднить процесс осмысления. Эффективный формат представления также учитывает когнитивные особенности пользователя, например, избегая перегрузки информацией и используя визуальные акценты для выделения ключевых моментов.
Злоумышленники могут манипулировать компонентами объяснений, такими как режим рассуждений, тип представленных доказательств и стиль коммуникации, для тонкого изменения восприятия пользователей и калибровки уровня доверия. Даже при наличии противоречащих доказательств, целенаправленное изменение этих элементов позволяет сформировать у пользователя ложное представление о достоверности информации. Это достигается путем подбора аргументации и представления данных таким образом, чтобы усилить желаемое впечатление и ослабить критическое мышление, создавая иллюзию обоснованности даже неверных утверждений.
Восприятие объяснения как достоверного, понятного и вызывающего доверие напрямую зависит от взаимодействия его ключевых компонентов. Комбинация используемого режима рассуждений (ReasoningMode), типа представленных доказательств (EvidenceType) и стиля коммуникации (CommunicationStyle) формирует общее впечатление. Несоответствие между этими элементами может снизить доверие, даже если информация сама по себе корректна. Например, логически непродуманное объяснение, подкрепленное слабыми доказательствами и представленное в агрессивной манере, скорее всего, будет воспринято негативно. В то же время, четко структурированное объяснение, основанное на релевантных данных и представленное нейтральным тоном, повышает вероятность принятия пользователем предложенных утверждений.
Долгосрочные последствия: как ИИ меняет наше доверие
Длительное взаимодействие с объяснениями, предоставляемыми системами искусственного интеллекта, вне зависимости от их достоверности, постепенно меняет уровень доверия пользователей и формирует их ожидания относительно возможностей ИИ. Исследования показывают, что повторные объяснения, даже если они не всегда соответствуют действительности, приводят к постепенной адаптации восприятия, когда пользователи начинают приспосабливаться к определенному стилю или качеству объяснений. Этот процесс может привести к тому, что пользователи начнут неосознанно принимать неточные или вводящие в заблуждение объяснения, поскольку их доверие к системе формируется на основе кумулятивного опыта взаимодействия, а не на критической оценке каждого отдельного ответа. В конечном итоге, длительное воздействие объяснений ИИ может привести к переоценке или недооценке реальных возможностей системы, что влияет на дальнейшие взаимодействия и принятие решений.
Продолжительное взаимодействие с системами искусственного интеллекта, даже если оно включает в себя получение неточной или вводящей в заблуждение информации, приводит к постепенной перекалибровке доверия у пользователей. Этот процесс не просто снижает начальный уровень доверия, но и формирует новые ожидания, делая людей более восприимчивыми к манипуляциям в будущем. По мере того, как пользователь сталкивается с объяснениями ИИ, будь то правдивыми или ложными, его способность критически оценивать информацию ослабевает, и он начинает полагаться на систему как на авторитетный источник, даже если эта система намеренно вводит в заблуждение. Такое постепенное изменение когнитивных процессов создает благоприятную среду для успешных атак, направленных на эксплуатацию сформировавшегося ложного чувства безопасности и доверия.
Исследование выявило, что многократное взаимодействие с искусственным интеллектом, даже при обнаружении манипуляций, постепенно искажает восприятие его возможностей и надежности. Установлена значимая отрицательная корреляция (-0.276, p < 0.001) между продолжительностью серии успешных атак и последующим уровнем доверия пользователей. Это означает, что с каждой новой, пусть и обнаруженной, попыткой обмана, доверие к системе неуклонно снижается, формируя завышенные ожидания от ее непогрешимости или, наоборот, полную неспособность к адекватному функционированию. Данный кумулятивный эффект подрывает уверенность в искусственном интеллекте и делает пользователей более уязвимыми для будущих атак, подчеркивая важность разработки надежных механизмов защиты и ответственного подхода к развитию подобных технологий.
Понимание данной динамики взаимодействия пользователей с объяснениями ИИ, как точными, так и вводящими в заблуждение, имеет решающее значение для разработки надежных мер защиты от враждебных атак. Непрерывное воздействие, формирующее ожидания и уровень доверия, требует создания систем, способных выявлять и нейтрализовать манипуляции. Разработка ответственного подхода к развитию искусственного интеллекта подразумевает не только повышение точности алгоритмов, но и обеспечение прозрачности и предсказуемости их поведения. Игнорирование кумулятивного эффекта от взаимодействия с ИИ может привести к снижению критического мышления пользователей и повышению их уязвимости перед дезинформацией, что подчеркивает необходимость проактивных стратегий защиты и повышения осведомленности.
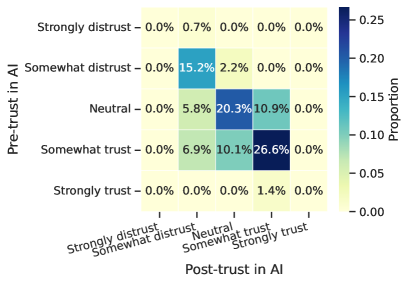
Исследование показывает, что доверие к системам искусственного интеллекта может быть искусственно сформировано не за счёт изменения самих решений ИИ, а посредством манипулирования объяснениями, которые сопровождают эти решения. Это открывает новые векторы атак, направленных не на взлом алгоритма, а на эксплуатацию когнитивных особенностей человека. Как отмечал Эдсгер Дейкстра: «Программирование — это не столько о том, чтобы научиться писать код, сколько о том, чтобы научиться мыслить». Данное исследование подтверждает эту мысль, демонстрируя, что понимание принципов работы системы, в данном случае — человеческого восприятия объяснений, позволяет создавать убедительные, но потенциально вводящие в заблуждение, нарративы, влияющие на принятие решений.
Что дальше?
Представленная работа лишь приоткрывает завесу над тем, насколько хрупко доверие человека к искусственному интеллекту. Не взломав сам алгоритм, а лишь изменив подачу объяснений, можно манипулировать принятием решений. Реальность, как открытый исходный код, демонстрирует, что уязвимости зачастую скрываются не в самой программе, а в интерфейсе, в способе её презентации. Очевидно, что дальнейшие исследования должны быть направлены на разработку методов «иммунитета» к подобным манипуляциям — механизмов проверки достоверности не самих ответов, а логики, стоящей за объяснениями.
Однако, истинный вызов заключается не в создании идеальных фильтров, а в понимании, почему человек так легко поддается убеждению. Следующим шагом видится изучение когнитивных искажений, лежащих в основе доверия, и разработка моделей, предсказывающих восприимчивость к «взламывающим» объяснениям. Необходимо учитывать, что доверие — это не просто рациональный процесс, а сложная эмоциональная реакция, которую нелегко поддается формализации.
В конечном счете, речь идет о переосмыслении самой концепции «объяснимого ИИ». Если объяснение может быть инструментом манипуляции, то его роль как средства обеспечения прозрачности и контроля вызывает серьезные вопросы. Возможно, будущее за системами, которые не объясняют, а демонстрируют свою логику, позволяя пользователю самостоятельно оценить её обоснованность — пусть и сложнее, но зато честнее.
Оригинал статьи: https://arxiv.org/pdf/2602.04003.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-05 23:49