Автор: Денис Аветисян
Новый метод позволяет выявлять и анализировать предвзятость в предсказаниях нейронных сетей, используя искусственно созданные наборы данных.
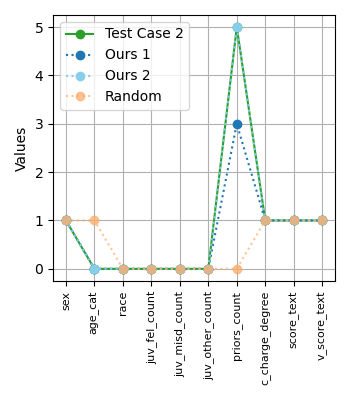
Исследование предлагает подход к аудиту нейронных сетей на предмет смещения меток, основанный на генерации контрфактических данных с использованием линейной регрессии и оценки схожести активаций нейронов.
Оценка справедливости предсказаний нейронных сетей остается сложной задачей, особенно в контексте скрытых смещений в обучающих данных. В работе ‘Analyzing Fairness of Neural Network Prediction via Counterfactual Dataset Generation’ предложен новый подход, основанный на генерации контрфактических наборов данных, позволяющий выявить влияние смещенных меток на процесс обучения и итоговые предсказания модели. Метод эффективно находит ближайший альтернативный набор данных, отличающийся от исходного лишь небольшим числом измененных меток, и позволяет оценить, насколько сильно изменение этих меток влияет на предсказания сети для конкретных тестовых примеров. Возможно ли с помощью данного подхода не только выявить, но и устранить предвзятость в обучающих данных, повысив тем самым справедливость и надежность нейронных сетей?
Скрытые Слабости Машинного Обучения
Несмотря на значительные успехи в области машинного обучения, особенно в разработке нейронных сетей, эти системы проявляют уязвимость к предвзятостям, содержащимся в данных, используемых для их обучения. Эти предвзятости, часто отражающие исторические или социальные неравенства, могут незаметно внедряться в алгоритмы, приводя к неточным или несправедливым прогнозам. Происходит это потому, что модели машинного обучения, по сути, учатся на примерах, и если эти примеры отражают существующие искажения, модель будет их воспроизводить и даже усиливать. Таким образом, даже самые передовые алгоритмы могут выдавать предсказуемо необъективные результаты, что подчеркивает необходимость критического анализа и тщательной подготовки обучающих данных для обеспечения справедливости и надежности систем искусственного интеллекта.
Предвзятость, заложенная в обучающие данные, может приводить к несправедливым или неточным прогнозам, оказывая существенное влияние на практическое применение машинного обучения. Например, алгоритмы распознавания лиц, обученные преимущественно на изображениях людей одной этнической группы, демонстрируют значительно худшую точность при анализе лиц других групп. Аналогичные проблемы возникают в системах оценки кредитоспособности, где исторические данные, отражающие существующее социальное неравенство, могут приводить к дискриминационным решениям. Такие ошибки не просто снижают эффективность алгоритмов, но и могут усиливать существующие предубеждения, приводя к серьезным последствиям в сферах от трудоустройства до правосудия. Поэтому, критически важно тщательно анализировать данные и разрабатывать методы смягчения предвзятости для обеспечения справедливости и надежности систем искусственного интеллекта.
Понимание источников предвзятости в данных является ключевым фактором для создания надежных систем искусственного интеллекта. Изначально, машинное обучение опирается на закономерности, выявленные в обучающих выборках, и любые систематические ошибки или необъективность, присутствующие в этих данных, неизбежно отражаются в принимаемых решениях. Эти предвзятости могут возникать из-за исторических предубеждений, недостаточной представленности определенных групп населения в данных, или даже из-за субъективных оценок, использованных при создании обучающих выборок. Идентификация этих источников — будь то ошибки в сборе данных, предвзятость алгоритмов отбора признаков или нерепрезентативность выборки — позволяет разработать стратегии для смягчения их влияния, такие как увеличение разнообразия данных, применение алгоритмов, устойчивых к предвзятостям, или использование методов аудита и оценки справедливости. Только путем осознанного подхода к данным и алгоритмам можно построить системы, которые будут не только эффективными, но и этичными и справедливыми.
Контрфактический Анализ: Выявление Влияния Данных
Для оценки влияния смещения меток (label bias) используется создание контрфактических наборов данных (counterfactual datasets) посредством контролируемого изменения меток. Данный подход заключается в искусственном изменении меток в исходном наборе данных, что позволяет оценить, как незначительные изменения в разметке влияют на прогнозы модели. Контролируемые изменения меток выполняются целенаправленно, позволяя исследователям изолировать и количественно оценить чувствительность модели к конкретным меткам и выявить потенциальные источники предвзятости. Процесс включает в себя создание нескольких версий набора данных, отличающихся только измененными метками, что обеспечивает возможность сравнительного анализа результатов работы модели на исходном и контрфактических данных.
Обучение моделей на специально созданных альтернативных наборах данных позволяет количественно оценить чувствительность предсказаний к изменениям в метках. Изменяя метки в исходных данных контролируемым образом, мы получаем наборы данных, отличные от исходного, и сравниваем предсказания моделей, обученных на этих наборах. Разница в предсказаниях, вызванная изменением метки, служит мерой чувствительности модели к этой конкретной метке. Этот метод позволяет определить, насколько сильно изменение одной метки влияет на общий результат, и выявить наиболее влиятельные данные, определяющие поведение модели.
Применяемый подход позволяет выявлять потенциально проблемные точки данных, непропорционально влияющие на поведение модели. В ходе экспериментов на небольших наборах данных удалось успешно сгенерировать контрфактические датасеты (CFD) для 16-30% входных тестовых примеров. Это указывает на наличие значительной доли данных, изменение меток которых может существенно повлиять на прогнозы модели, что позволяет провести более глубокий анализ чувствительности и потенциальной предвзятости.
Функции Влияния: Определение Воздействия Данных
Функции влияния представляют собой мощный инструмент для оценки влияния отдельных точек обучающих данных на прогнозы модели. Они позволяют приближенно определить, как изменение конкретной точки данных в обучающем наборе повлияет на выходные данные модели для заданного примера. Математически, функция влияния выражается как градиент выходных данных модели по отношению к обучающим данным, вычисленный в точке, соответствующей конкретному примеру, для которого оценивается влияние. По сути, это мера чувствительности прогноза модели к изменению конкретной обучающей точки, что позволяет выявить наиболее значимые данные для обучения и потенциального исправления ошибок разметки. Вычисление точных функций влияния может быть вычислительно сложным, поэтому используются различные приближенные методы для эффективной оценки.
Для эффективного вычисления оценок влияния отдельных точек обучающей выборки на прогнозы модели используются различные приближения, такие как Explicit Influence, Conjugate Gradients, LiSSA и Arnoldi. Explicit Influence напрямую оценивает влияние каждой точки, что может быть вычислительно затратно. Методы Conjugate Gradients и Arnoldi представляют собой итеративные подходы, позволяющие снизить вычислительную сложность за счет приближения решения. LiSSA (Locally Linear Stochastic Shape Approximation) использует локальные линейные аппроксимации для более быстрой оценки влияния. Выбор конкретного метода зависит от компромисса между точностью и скоростью вычислений, а также от размера обучающей выборки и сложности модели.
Методы вычисления влияния (influence functions) позволяют выявлять наиболее значимые точки обучающей выборки, оказывающие существенное воздействие на прогнозы модели. Это дает возможность приоритизировать данные для проверки и исправления меток, снижая влияние смещения в обучающей выборке. В частности, разработанный нами метод позволяет идентифицировать большее количество критических точек данных (CFDs) уже на первой итерации, что демонстрирует эффективную ранжировку влиятельных обучающих меток и, следовательно, более быструю диагностику потенциальных проблем в данных.
Оценка влияния отдельных точек обучающих данных может быть уточнена с использованием схожести активаций нейронов. Данный подход заключается в измерении корреляции между активациями нейронов, вызванными анализируемой точкой данных, и активациями, полученными на других точках. Высокая степень схожести активаций указывает на то, что изменение метки анализируемой точки данных окажет более значительное влияние на выходные значения модели для других точек данных, что позволяет более точно ранжировать точки данных по степени их важности и выявлять потенциально ошибочно размеченные образцы. Использование схожести активаций нейронов позволяет дополнить существующие методы оценки влияния, такие как Explicit Influence, и повысить эффективность выявления критически важных точек обучающих данных.
К Надежным и Справедливым Машинным Обучению
Сочетание контрфактического анализа и методов анализа влияния позволяет получить глубокое понимание поведения моделей машинного обучения и их зависимости от данных. Контрфактический анализ исследует, какие минимальные изменения во входных данных привели бы к другому предсказанию модели, выявляя чувствительность к конкретным признакам. В свою очередь, анализ влияния определяет, какие обучающие примеры оказывают наибольшее влияние на предсказание для конкретного входного объекта. Комбинируя эти подходы, исследователи могут не только выявить ключевые факторы, определяющие решения модели, но и оценить, насколько стабильны эти решения при небольших изменениях входных данных или в обучающей выборке. Такой комплексный анализ способствует созданию более надежных и интерпретируемых моделей, способных адекватно реагировать на различные сценарии и обеспечивать предсказуемые результаты.
Понимание взаимосвязи между данными и поведением модели имеет первостепенное значение для создания устойчивых и справедливых систем машинного обучения. Использование методов контрафакторного анализа и функций влияния позволяет выявить тонкие зависимости, определяющие решения модели, и оценить, как незначительные изменения во входных данных могут привести к различным результатам. Это знание позволяет разработчикам не только повысить устойчивость модели к нежелательным отклонениям и шуму, но и гарантировать, что она не будет предвзято относиться к определенным группам пользователей. В конечном итоге, способность анализировать и понимать “причины” решений модели является ключевым фактором для построения доверия к системам искусственного интеллекта и обеспечения их ответственного использования в различных областях.
Предложенные методы позволяют проводить всестороннее тестирование моделей машинного обучения на предмет справедливости. Они обеспечивают возможность выявления случаев, когда модель несправедливо различает людей, схожих по своим характеристикам, что особенно важно для приложений, влияющих на жизненные возможности. Анализируя, как незначительные изменения во входных данных влияют на предсказания модели, можно точно определить, какие факторы приводят к дискриминации и разработать стратегии для ее устранения. Такой подход гарантирует, что модели будут оценивать людей на основе релевантных критериев, а не на основе предвзятых данных или алгоритмических ошибок, способствуя построению более надежных и этичных систем искусственного интеллекта.
Анализ контрфактических данных, полученный с использованием предложенного подхода, предоставляет ценные сведения для оптимизации стратегий курирования обучающих наборов данных. Исследование показывает, что большинство выявленных контрфактических примеров не обнаруживаются стандартными методами, такими как случайная выборка или оценка на основе евклидова расстояния L_2. Это подчеркивает эффективность предложенной методики в выявлении тонких зависимостей в данных, которые могут влиять на поведение модели. Использование этих сведений позволяет целенаправленно улучшать качество обучающих данных, удаляя или корректируя проблемные экземпляры, что, в свою очередь, способствует созданию более надежных и справедливых систем машинного обучения.
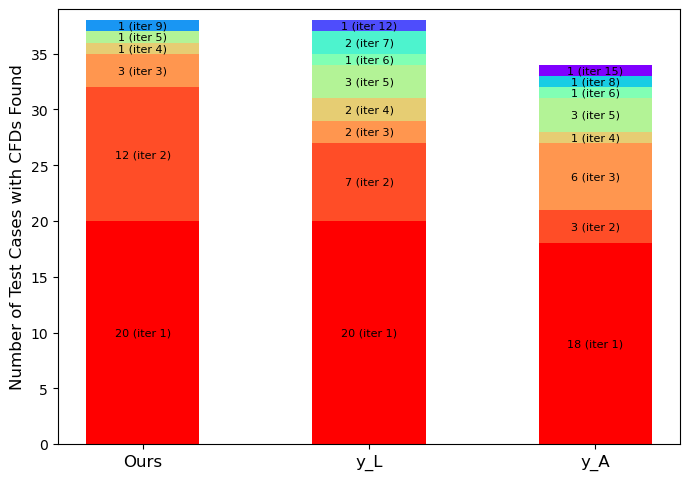
Исследование, представленное в данной работе, затрагивает фундаментальную проблему предвзятости в системах машинного обучения. Авторы предлагают метод генерации контрфактических данных, позволяющий выявить влияние отдельных обучающих примеров на прогнозы нейронных сетей. Этот подход, основанный на сочетании линейной регрессии и анализа схожести активаций нейронов, позволяет не просто констатировать наличие предвзятости, но и понять, какие именно данные её порождают. Как заметил однажды Карл Фридрих Гаусс: «Математика — это наука о бесконечности». Подобно этому, и поиск справедливости в алгоритмах — бесконечный процесс, требующий постоянного анализа и совершенствования систем, чтобы обеспечить их устойчивость и надежность в долгосрочной перспективе. Важно не стремиться к мгновенному устранению всех несовершенств, а скорее научиться понимать динамику системы и адаптироваться к изменениям.
Что дальше?
Представленная работа, стремясь выявить предвзятость в нейронных сетях посредством генерации контрфактических данных, лишь обнажает глубину проблемы. Ведь любое вмешательство в обучающую выборку — это не устранение, а отсрочка неизбежного. Система стареет не из-за ошибок, а из-за неизбежности времени, и рано или поздно проявится та самая предвзятость, замаскированная под «исправлением». Важно осознавать, что поиск «справедливых» меток — это, по сути, попытка построить идеальную модель реальности, а реальность, как известно, всегда несовершенна.
Перспективы дальнейших исследований лежат не столько в усовершенствовании алгоритмов генерации контрфактов, сколько в переосмыслении самой концепции «справедливости». Следует задаться вопросом: а возможно ли вообще создать систему, свободную от субъективных оценок, заложенных в исходных данных? И не является ли стремление к абсолютной объективности лишь очередной иллюзией, обреченной на провал? Иногда стабильность — это лишь задержка катастрофы, а кажущаяся «справедливость» — всего лишь маскировка более глубоких проблем.
Будущие работы, вероятно, должны сосредоточиться на разработке методов оценки устойчивости моделей к предвзятости, а не на её полном устранении. Необходимо научиться понимать, как предвзятость проявляется в различных контекстах, и как минимизировать её негативные последствия. И, возможно, пришло время признать, что идеальной модели не существует, и что любое решение, принимаемое нейронной сетью, всегда будет нести на себе отпечаток субъективности.
Оригинал статьи: https://arxiv.org/pdf/2602.10457.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-12 13:59