Автор: Денис Аветисян
Новый подход к использованию больших языковых моделей в телекоммуникациях позволяет повысить точность ответов и снизить вероятность ошибок.
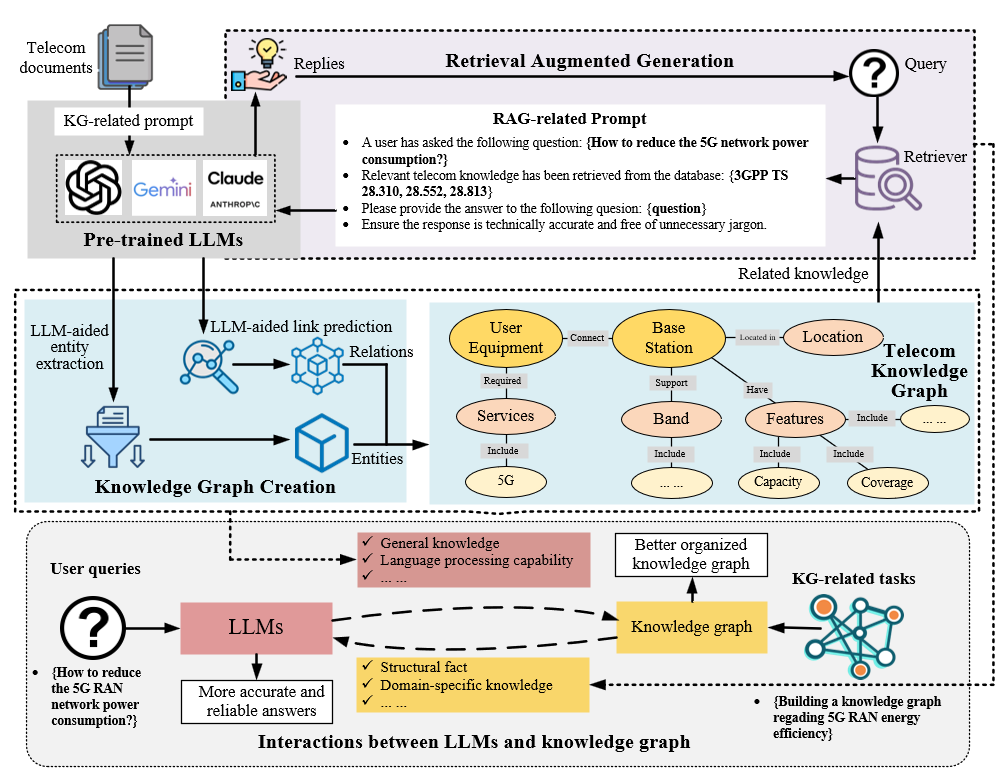
В статье рассматривается фреймворк KG-RAG, объединяющий графы знаний и генерацию с расширенным поиском для повышения надежности и прозрачности работы LLM в телеком-сфере.
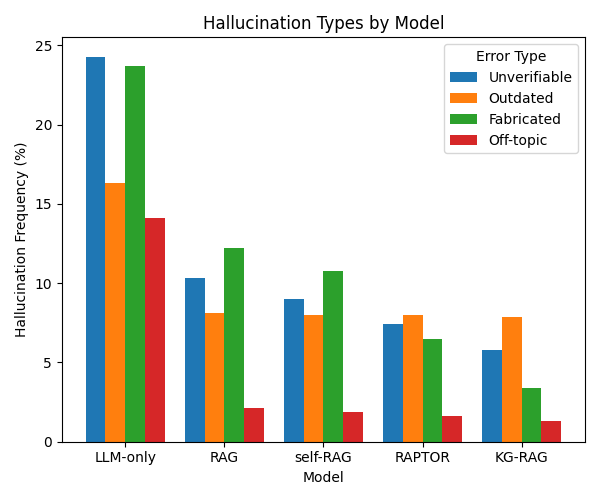
Несмотря на впечатляющий прогресс больших языковых моделей (LLM), их применение в телекоммуникационной сфере затруднено из-за сложности предметной области и постоянно меняющихся стандартов. В данной работе, посвященной ‘Enhancing Large Language Models (LLMs) for Telecom using Dynamic Knowledge Graphs and Explainable Retrieval-Augmented Generation’, предложен фреймворк KG-RAG, объединяющий графы знаний и генерацию с поисковым расширением для повышения точности и надежности LLM в телекоммуникационных задачах. Эксперименты демонстрируют, что KG-RAG превосходит как LLM без дополнительных знаний, так и стандартные RAG-системы, снижая вероятность галлюцинаций и обеспечивая соответствие отраслевым спецификациям. Сможет ли данный подход стать основой для создания интеллектуальных систем поддержки принятия решений в динамичной телекоммуникационной отрасли?
Преодоление Информационного Узкого Места в Телекоммуникациях
Стремительное развитие телекоммуникационной отрасли предъявляет постоянно растущие требования к объему и скорости обновления знаний. Традиционные методы обучения и распространения информации, такие как учебные пособия и краткосрочные тренинги, уже не успевают за лавинообразным ростом новых технологий, протоколов и архитектур сетей. Этот разрыв между потребностью в актуальных знаниях и возможностями их получения становится серьезным препятствием для внедрения инноваций, оптимизации существующих систем и эффективного решения возникающих проблем. В результате, специалисты испытывают трудности с освоением новых инструментов и технологий, что замедляет процесс цифровой трансформации и снижает конкурентоспособность компаний в отрасли.
Современные подходы к обработке и применению знаний в телекоммуникационной сфере сталкиваются с серьезными трудностями, обусловленными экспоненциальным ростом сложности и масштаба отраслевых спецификаций и сетевых архитектур. Традиционные методы, такие как ручное кодирование правил или ограниченные базы данных, оказываются неспособными эффективно обрабатывать огромное количество информации, включающее в себя постоянно обновляющиеся стандарты, протоколы и конфигурации оборудования. Разветвленные сети, включающие в себя гетерогенные технологии и сложные взаимосвязи, требуют не просто хранения данных, но и глубокого понимания контекста и взаимозависимостей. Это создает значительные препятствия для автоматизации процессов, оптимизации работы сети и, как следствие, для своевременного внедрения инновационных технологий, таких как 5G и будущие поколения мобильной связи.
Недостаток актуальных и доступных знаний в сфере телекоммуникаций серьезно замедляет внедрение автоматизации и оптимизации сетевых процессов. Сложность современных телекоммуникационных стандартов и архитектур требует глубокой экспертизы, дефицит которой препятствует эффективному управлению сетями и развертыванию инновационных технологий, таких как 5G и последующих поколений связи. Отсутствие возможности быстро и точно извлекать необходимую информацию из огромного объема спецификаций и документации приводит к увеличению затрат, снижению производительности и задержкам в реализации новых сервисов, что, в конечном итоге, сдерживает развитие всей отрасли. Таким образом, преодоление этого информационного барьера является ключевым фактором для обеспечения конкурентоспособности и успешного развития телекоммуникационных систем.
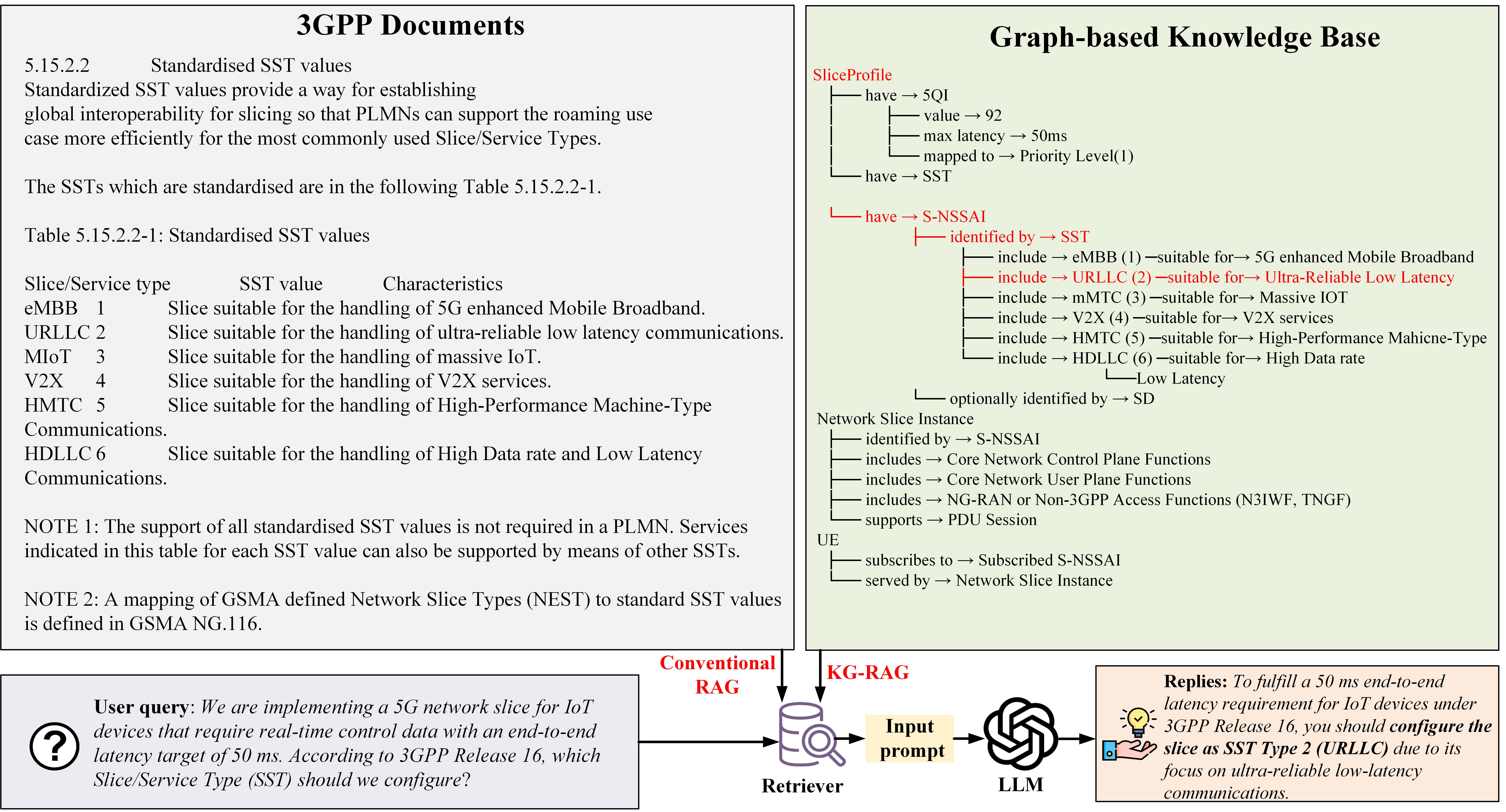
Построение Базы Знаний для Телекоммуникаций
Предлагаемый фреймворк KG-RAG объединяет преимущества графов знаний (Knowledge Graphs) и генеративных моделей, дополненных поиском (Retrieval-Augmented Generation), для повышения качества понимания и обработки информации. В основе лежит использование структурированного представления знаний в виде графа, позволяющего моделировать связи между сущностями и эффективно извлекать релевантный контекст. Комбинация структурированных знаний из графа и возможностей генерации текста позволяет создавать более точные, обоснованные и контекстно-зависимые ответы и решения, превосходящие возможности традиционных генеративных моделей, работающих без доступа к внешним базам знаний.
В основе системы лежит надежный граф знаний, функционирующий как централизованное хранилище информации в телекоммуникационной области. Этот граф структурирует данные, представляя ключевые сущности (например, абоненты, услуги, оборудование, сети) и взаимосвязи между ними (например, абонент использует услугу, оборудование подключено к сети). Структурированное представление позволяет эффективно моделировать сложные взаимосвязи в телекоммуникационной инфраструктуре и обеспечивает возможность логического вывода и анализа, недоступные при работе с неструктурированными данными. Граф знаний поддерживает как статические данные (например, характеристики оборудования), так и динамические (например, текущий статус сервиса), что необходимо для оперативного принятия решений и автоматизации процессов.
Для обеспечения актуальности и полноты данных, граф знаний пополняется и обновляется с использованием методов, таких как Stream2Graph. Данный подход предполагает автоматическое извлечение сущностей и связей из потоковых данных, поступающих из различных источников телекоммуникационной отрасли, включая журналы сетевого оборудования, данные о клиентских взаимодействиях и информацию о сервисах. Stream2Graph позволяет в режиме реального времени добавлять новые узлы и ребра в граф знаний, а также корректировать существующие, отражая изменения в телекоммуникационной среде и обеспечивая его соответствие текущему состоянию дел. Это позволяет поддерживать граф знаний в актуальном состоянии, что критически важно для точности и надежности системы генерации ответов.
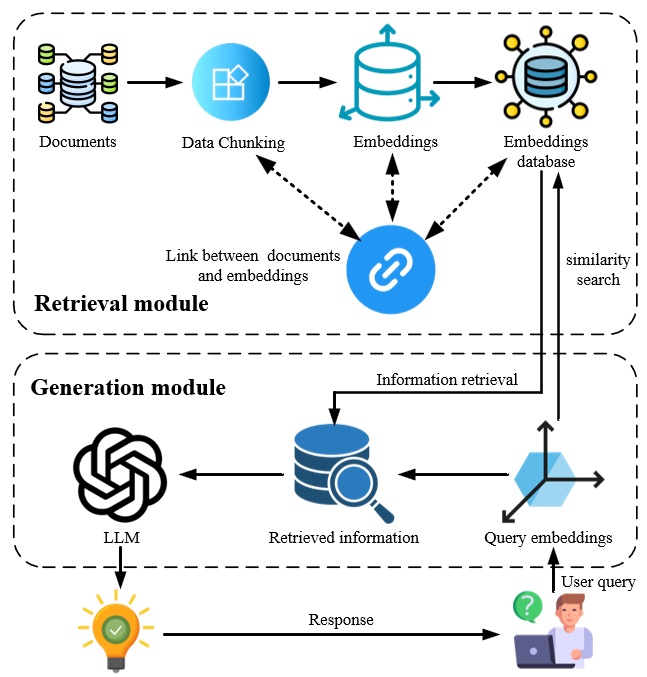
Извлечение Знаний: От Текста к Структурированным Данным
Эффективное извлечение сущностей является ключевым этапом для наполнения графа знаний, осуществляемого с помощью различных подходов. К ним относятся предварительно обученные языковые модели (LLM), обеспечивающие высокую точность распознавания именованных сущностей; методы, основанные на правилах, использующие заранее определенные шаблоны и регулярные выражения для идентификации сущностей; и подходы машинного обучения, включающие в себя алгоритмы, такие как условные случайные поля (CRF) и нейронные сети, которые обучаются на размеченных данных для автоматического извлечения сущностей из текста. Комбинация этих методов позволяет добиться максимальной эффективности и полноты при формировании структурированной информации в графе знаний.
Построение связей между сущностями в графе знаний осуществляется посредством методов предсказания связей (Link Prediction). К ним относятся трансляционные модели расстояний (Translational Distance Models), такие как DistMult и ComplEx, которые представляют связи как смещения в пространстве вложений. Семантическое сопоставление (Semantic Matching Models) оценивает вероятность связи на основе семантической близости сущностей, используя методы, основанные на тензорных разложениях. Нейронные сети (Neural Network-Based Methods), включая Graph Neural Networks (GNN), позволяют моделировать сложные зависимости и контекст для более точного предсказания связей, используя многослойные архитектуры и функции активации для обучения на графовых данных.
Преобразование неструктурированных данных телекоммуникаций в структурированную, взаимосвязанную базу знаний осуществляется посредством извлечения сущностей и построения связей между ними. Используемые методы, такие как модели предсказанного расстояния (translational distance models) и семантического сопоставления, позволяют идентифицировать ключевые элементы данных (например, абонентов, устройства, услуги) и определять отношения между ними (например, «абонент использует услугу», «устройство принадлежит абоненту»). В результате формируется графовая база знаний, в которой данные представлены в виде узлов (сущностей) и ребер (связей), что обеспечивает возможность эффективного анализа и извлечения ценной информации из больших объемов неструктурированных телекоммуникационных данных.
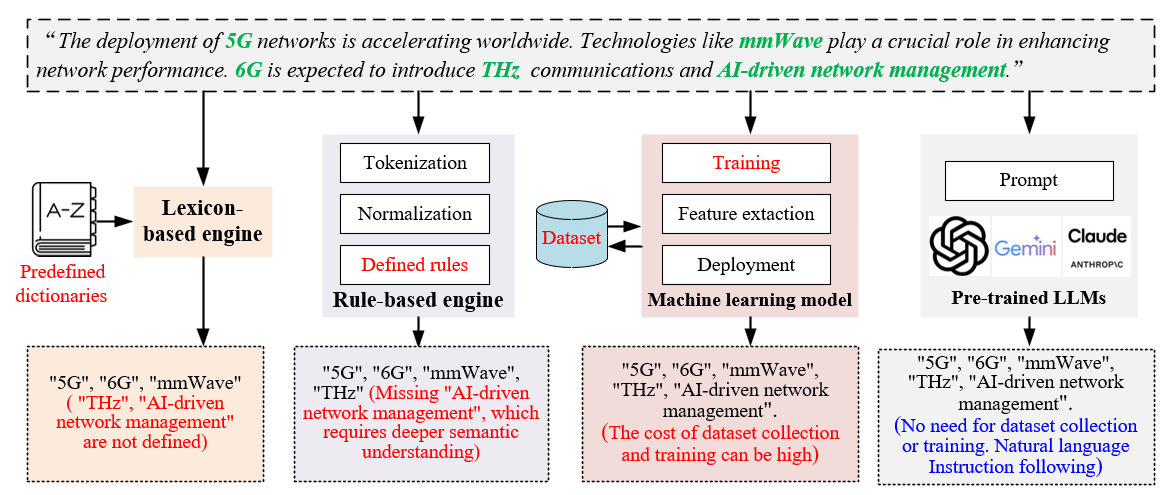
KG-RAG в Действии: Углубленное Понимание в Телекоммуникациях
В основе системы KG-RAG лежит концепция Retrieval-Augmented Generation, усиленная применением Knowledge Graph — графа знаний, структурированно представляющего информацию о телекоммуникационной сфере. Этот подход позволяет системе не просто генерировать ответы, но и извлекать релевантные данные из графа знаний, обеспечивая высокую точность и контекстуальную согласованность. Вместо слепого воспроизведения информации, KG-RAG сначала ищет наиболее подходящие фрагменты знаний в графе, а затем использует их для формирования ответа, что значительно повышает надежность и полезность предоставляемой информации. Такая архитектура особенно важна при обработке сложных запросов в телекоммуникационной отрасли, где требуется глубокое понимание специфической терминологии и взаимосвязей между различными компонентами и технологиями.
Для повышения точности извлечения информации из графа знаний используются методы двойного кодирования и фильтрации с учетом онтологии. Двойное кодирование позволяет эффективно представлять как запросы, так и узлы графа знаний в векторном пространстве, облегчая поиск наиболее релевантных фрагментов. В свою очередь, фильтрация с учетом онтологии использует структуру и взаимосвязи внутри графа знаний для отсеивания нерелевантной информации и фокусировки на наиболее значимых концепциях и отношениях. Такой подход позволяет значительно улучшить качество генерируемых ответов, предоставляя более точные, полные и контекстуально обоснованные результаты, что особенно важно при работе со сложными запросами в телекоммуникационной сфере.
Предложенный подход демонстрирует превосходство над традиционными методами при ответах на сложные запросы в сфере телекоммуникаций. Это подтверждается результатами оценок на специализированных наборах данных, таких как TeleQnA, SPEC5G, Tspec-LLM и ORAN-Bench-13K. В ходе тестирования была достигнута передовая производительность по ключевым показателям оценки суммирования — ROUGE-1, ROUGE-2 и ROUGE-L — а также значительно повышена точность ответов на вопросы. Полученные результаты свидетельствуют о способности системы эффективно извлекать и синтезировать информацию, предоставляя более полные и релевантные ответы по сравнению с существующими решениями в области телекоммуникаций.
Динамическая структура KG-RAG демонстрирует существенное повышение точности ответов на вопросы после внесения изменений в данные — до 84.0%, что значительно превосходит показатель в 72.1%, достигнутый при использовании статического графа знаний. Важно отметить, что удалось существенно снизить долю устаревшей информации — с 37.8% до 11.4%. Это означает, что система способна оперативно адаптироваться к новым данным, предоставляя пользователям актуальные и достоверные ответы, что особенно критично в динамично меняющейся сфере телекоммуникаций. Подобное улучшение точности и актуальности данных свидетельствует об эффективности подхода, основанного на динамическом обновлении графа знаний.
В ходе тестирования динамической системы KG-RAG было установлено, что среднее время от момента поступления запроса, связанного с изменениями в телекоммуникационной сети, до получения ответа составляет 5.2 секунды. Этот показатель позволяет использовать систему в интерактивных сценариях, где оперативность ответа критически важна для поддержки принятия решений и решения возникающих проблем. Полученное время отклика демонстрирует, что, несмотря на сложность обработки информации и постоянное обновление базы знаний, система способна предоставлять актуальные ответы с приемлемой скоростью, обеспечивая эффективное взаимодействие с пользователем и поддерживая высокую производительность телекоммуникационной инфраструктуры.
Перспективы Развития: Интеллектуальные Телекоммуникационные Сети
В основе интеллектуальной автоматизации и оптимизации телекоммуникационных сетей лежит разработанный KG-RAG фреймворк, использующий возможности модели GPT-4o-mini. Данная архитектура позволяет эффективно обрабатывать и анализировать огромные объемы данных, генерируя решения для сложных задач управления сетью. Фреймворк, объединяя знания из графа знаний (Knowledge Graph) и возможности генерации ответов GPT-4o-mini, обеспечивает более гибкое и адаптивное управление ресурсами, а также позволяет оперативно реагировать на изменения в сетевой среде. Это открывает перспективы для автоматизации рутинных операций, повышения эффективности использования пропускной способности и улучшения качества предоставляемых услуг, что в конечном итоге ведет к существенному снижению эксплуатационных расходов и повышению конкурентоспособности телекоммуникационных компаний.
Перспективные исследования направлены на интеграцию потоковых данных в реальном времени непосредственно в структуру базы знаний. Это позволит базе знаний не просто хранить информацию, но и постоянно адаптироваться к меняющимся условиям сети, обеспечивая актуальность и точность предоставляемых сведений. Подобный динамический подход к обновлению информации критически важен для оперативного реагирования на сбои, оптимизации распределения ресурсов и прогнозирования потребностей сети. Внедрение таких механизмов самообучения и адаптации значительно повысит эффективность автоматизации и интеллектуального управления телекоммуникационными сетями, открывая возможности для проактивного решения проблем и улучшения качества обслуживания.
Ожидается, что данная технология откроет новые возможности в области планирования телекоммуникационных сетей, оптимизируя распределение ресурсов и повышая качество предоставляемых услуг. Благодаря автоматизации и интеллектуальному анализу, операторы связи смогут более эффективно реагировать на изменяющиеся потребности пользователей и адаптироваться к новым вызовам, таким как рост трафика и появление инновационных сервисов. В перспективе это приведет к созданию более гибких, надежных и масштабируемых сетей, способных поддерживать широкий спектр приложений, от высокоскоростного мобильного интернета до сервисов виртуальной и дополненной реальности, формируя будущее телекоммуникационной отрасли.
Исследование демонстрирует, что интеграция динамических графов знаний с генеративными моделями, дополненными поиском, значительно повышает точность и снижает склонность к галлюцинациям в телекоммуникационных приложениях. Этот подход позволяет не просто предоставлять ответы, но и объяснять логику, лежащую в основе этих ответов. Как однажды заметил Марвин Минский: «Лучший способ понять — это создать». Данное исследование воплощает эту идею, создавая систему, которая не только генерирует информацию, но и делает процесс ее получения прозрачным и понятным, что критически важно для доверия к автоматизированным решениям в сложной области телекоммуникаций.
Что дальше?
Предложенная в данной работе интеграция графов знаний и генерации с поисковым дополнением (RAG) для телекоммуникационной отрасли, безусловно, представляет собой шаг к более надежным и объяснимым системам. Однако, подобно любому элегантному решению, оно обнажает новые сложности. Динамическое обновление графа знаний — процесс, требующий постоянного баланса между полнотой информации и вычислительной стоимостью. Каждая новая зависимость, каждая добавленная связь — это скрытая цена свободы от галлюцинаций, и необходимо тщательно оценивать, не приведет ли стремление к абсолютной точности к непомерной сложности.
Настоящим вызовом представляется не просто автоматизация обновления графа знаний, а развитие механизмов самокритики и адаптации системы. Важно понимать, что структура графа знаний определяет не только поведение системы, но и ее предрасположенность к определенным ошибкам. Будущие исследования должны быть направлены на создание систем, способных выявлять и исправлять структурные недостатки, а не только реагировать на симптомы.
В конечном счете, успех данного подхода зависит от способности выйти за рамки простого улучшения точности и перейти к созданию систем, способных к истинному пониманию и рассуждению. Иначе говоря, речь идет не о создании более сложного инструмента, а о приближении к более простой и ясной модели мира.
Оригинал статьи: https://arxiv.org/pdf/2602.17529.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-21 23:45