Автор: Денис Аветисян
Новый подход к анализу ‘галлюцинаций’ в больших языковых моделях позволяет не только выявлять фактические ошибки, но и локализовать их причины и предлагать способы исправления.
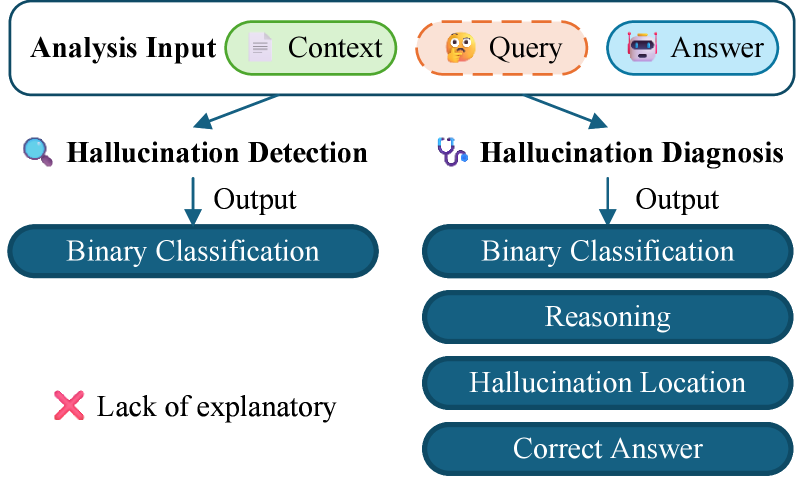
Предлагается парадигма ‘Диагностики Галлюцинаций’, включающая локализацию, объяснение и смягчение фактических ошибок, с применением синтеза данных и обучения с подкреплением для повышения эффективности моделей.
Несмотря на значительные успехи в области больших языковых моделей (LLM), проблема генерации фактических ошибок, или «галлюцинаций», остаётся ключевым препятствием для их надежного применения. В работе ‘From Detection to Diagnosis: Advancing Hallucination Analysis with Automated Data Synthesis’ предложен новый подход, смещающий акцент с простого обнаружения галлюцинаций на их диагностику — локализацию ошибок, выявление причин и последующую коррекцию. Показано, что разработанная методика автоматической генерации данных в сочетании с обучением с подкреплением позволяет 4-параметровой модели достичь конкурентоспособных результатов, сопоставимых с более крупными аналогами. Возможно ли, таким образом, создать более надёжные и заслуживающие доверия системы генеративного ИИ, эффективно справляющиеся с проблемой фактических ошибок?
Иллюзии Разума: О природе галлюцинаций в больших языковых моделях
Несмотря на впечатляющую способность к генерации текста, большие языковые модели подвержены феномену, известному как «галлюцинации». Этот термин описывает склонность моделей создавать правдоподобные, но фактически неверные утверждения, представляя их как истинные факты. Данное явление не связано с сознательным обманом, а является следствием статистической природы обучения моделей — они предсказывают наиболее вероятные последовательности слов, не всегда проверяя их соответствие реальности. В результате, даже при корректной грамматике и логичной структуре, сгенерированный текст может содержать неточности, вымышленные детали или противоречивую информацию, что представляет серьезную проблему для приложений, требующих высокой степени достоверности и надежности данных.
Несмотря на впечатляющие возможности, склонность больших языковых моделей к генерации правдоподобной, но неточной информации представляет серьезную проблему для приложений, требующих достоверности. Эта тенденция, известная как «галлюцинации», ставит под вопрос надежность систем, используемых в критически важных областях, таких как медицина, юриспруденция и научные исследования. В связи с этим, активно разрабатываются методы обнаружения и смягчения этих неточностей, включая алгоритмы проверки фактов, механизмы оценки достоверности источников и стратегии обучения моделей, направленные на повышение их способности генерировать информацию, соответствующую реальности. Решение этой задачи является ключевым для раскрытия полного потенциала больших языковых моделей и обеспечения их безопасного и эффективного применения.
Особая проблема, возникающая в больших языковых моделях, проявляется в так называемых «галлюцинациях верности», когда сгенерированный текст напрямую противоречит исходному материалу, на котором он основан. Это не просто фактическая ошибка, а именно несоответствие между представленной информацией и ее первоисточником. Например, модель, получив текст о красном яблоке, может сгенерировать описание зеленого яблока, что демонстрирует потерю связи с исходными данными. Такая неверность особенно опасна в приложениях, требующих высокой точности и надежности информации, таких как медицинские консультации или юридические исследования, поскольку вводит в заблуждение и подрывает доверие к системе. Исследователи активно разрабатывают методы обнаружения и смягчения этих галлюцинаций, чтобы повысить надежность и полезность больших языковых моделей.
Создание Конвейера Диагностики Галлюцинаций
Задача диагностики галлюцинаций представляет собой комплексный подход, охватывающий четыре ключевых аспекта: обнаружение (detection) ложных утверждений, локализацию (localization) конкретных фрагментов текста, содержащих галлюцинации, объяснение (explainability) причин возникновения этих ошибок и разработку методов смягчения (mitigation) галлюцинаций в генерируемых текстах. Данный подход направлен на создание надежных и интерпретируемых систем генерации текста, способных не только создавать связные и грамматически правильные тексты, но и обеспечивать их фактическую достоверность и соответствие исходным данным. Целью является не просто выявление галлюцинаций, но и понимание механизмов их возникновения для разработки эффективных стратегий предотвращения.
В основе поставленной задачи диагностики галлюцинаций лежит HDG Pipeline — автоматизированная система, предназначенная для генерации масштабного набора данных, используемого для обучения моделей выявления галлюцинаций. В качестве источника данных используется корпус Википедии, что позволяет охватить широкий спектр тем и стилей текста. Система автоматически извлекает информацию из Википедии, формирует запросы и анализирует ответы, выявляя несоответствия и потенциальные галлюцинации. Сгенерированный набор данных состоит из примеров, включающих исходный текст, предполагаемую галлюцинацию и, при необходимости, информацию о контексте, что необходимо для обучения и оценки моделей диагностики.
В рамках HDG Pipeline для повышения качества и разнообразия генерируемых обучающих примеров используется метод Chain-of-Thought Prompting (CoT). Этот подход предполагает добавление в запрос к языковой модели последовательности промежуточных рассуждений, имитирующих процесс логического вывода. В результате, вместо прямого ответа, модель генерирует не только конечный результат, но и объяснение, как к нему пришла. Это позволяет создавать более сложные и информативные примеры, способствующие более эффективному обучению моделей обнаружения галлюцинаций и локализации неточностей в сгенерированном тексте. Использование CoT позволяет генерировать примеры, отражающие различные способы рассуждений и логических связей, что способствует повышению робастности и обобщающей способности моделей.
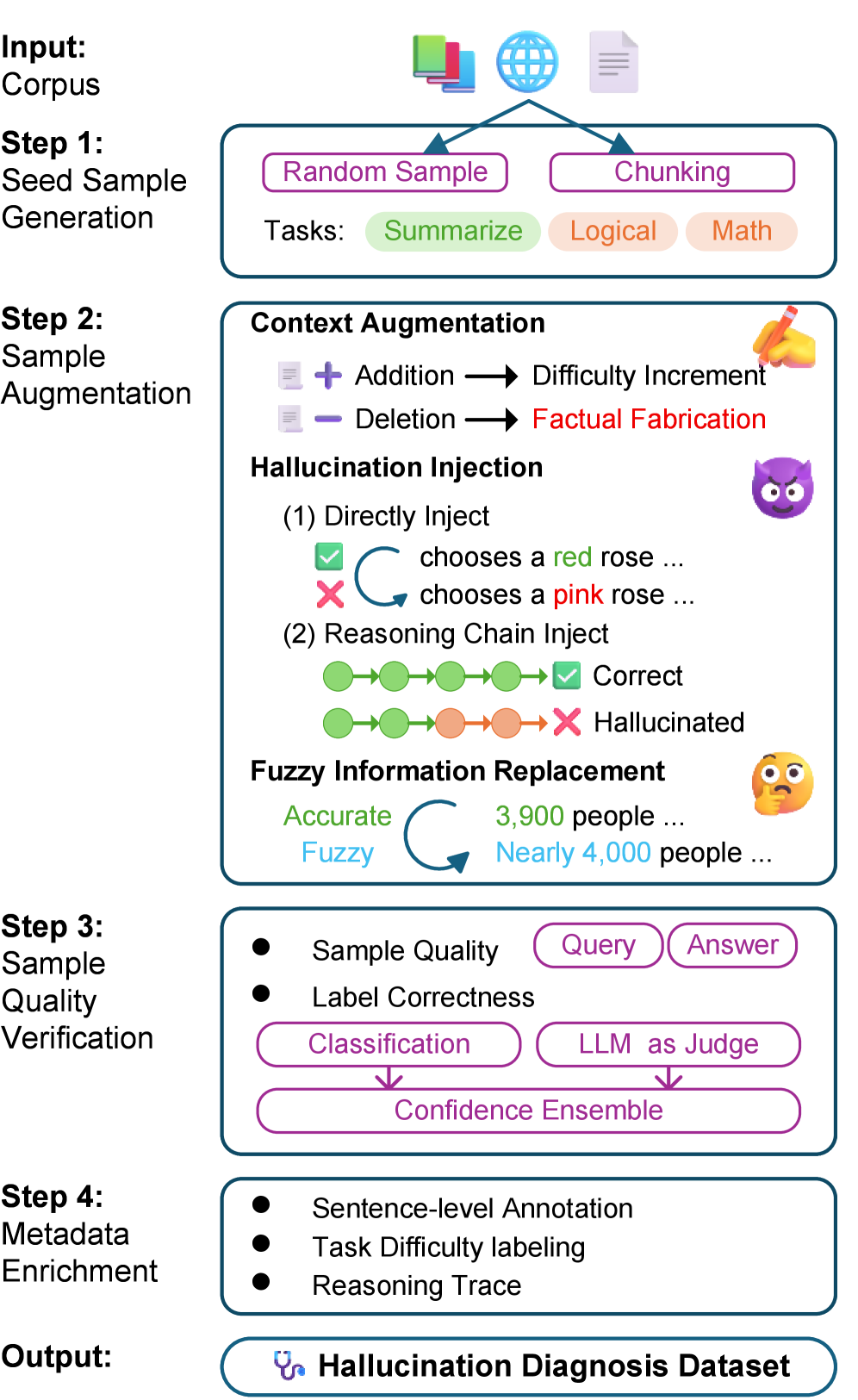
HDM-4B-RL: Модель для Диагностики Галлюцинаций
Модель HDM-4B-RL представляет собой систему диагностики галлюцинаций, состоящую из 4 миллиардов параметров. Она обучена на наборе данных, сформированном посредством HDG Pipeline, и использует в качестве базовой модели Qwen3-4B. Данная архитектура позволяет эффективно выявлять и классифицировать галлюцинации в генерируемом тексте, обеспечивая основу для последующей фильтрации и коррекции неправдивой информации.
Обучение модели HDM-4B-RL осуществлялось с использованием алгоритма Group Relative Policy Optimization (GRPO), передового метода обучения с подкреплением. GRPO позволяет оптимизировать политику модели, группируя схожие состояния и действия, что повышает эффективность обучения и стабильность. В отличие от стандартных алгоритмов обучения с подкреплением, GRPO учитывает относительное изменение политики внутри каждой группы, что снижает дисперсию и ускоряет сходимость к оптимальному решению. Данный подход особенно полезен при обучении больших языковых моделей, где пространство состояний и действий чрезвычайно велико, а стандартные алгоритмы могут быть неэффективными или нестабильными.
Модель HDM-4B-RL демонстрирует высокую эффективность в обнаружении галлюцинаций, достигая показателя F1 Score в 79.65. Данный результат превосходит показатели GPT-4.1 (75.37) и приближается к эффективности более крупной модели Qwen3-32B (81.70). Это свидетельствует о способности HDM-4B-RL эффективно выявлять неточности и несоответствия в генерируемом тексте, несмотря на относительно небольшой размер модели, составляющий 4 миллиарда параметров.
Модель HDM-4B-RL продемонстрировала точность в 84.54% при оценке на бенчмарке FinanceBench, что превышает результат предыдущего лидера, модели Lynx, на 2.4 процентных пункта. Данный показатель свидетельствует о высокой эффективности HDM-4B-RL в задачах, связанных с финансовыми данными и анализом, и подтверждает её конкурентоспособность по сравнению с другими моделями в данной области.
Результаты, представленные в Таблице 5, демонстрируют, что модель HDM-4B-RL достигает сопоставимых показателей с более крупными моделями в задачах локализации галлюцинаций (Hit Rate) и их смягчения (AlignScore). Это указывает на эффективность предложенного подхода к диагностике галлюцинаций, позволяющего достигать высокой производительности при значительно меньшем размере модели, что особенно важно для практического применения в условиях ограниченных вычислительных ресурсов.
Модель HDM-4B-RL демонстрирует значительное преимущество в скорости работы по сравнению с более крупными моделями, использующими 32B параметров. Время выполнения HDM-4B-RL составляет 1x, в то время как аналогичный процесс с использованием 32B модели занимает 4.9x больше времени. Это указывает на повышенную эффективность и возможность более быстрого получения результатов при использовании HDM-4B-RL, что делает ее привлекательной для приложений, требующих низкой задержки и высокой пропускной способности.

К Надежному Разуму: Перспективы развития языковых моделей
Способность модели HDM-4B-RL диагностировать галлюцинации — обнаруживать, локализовать и объяснять их — представляет собой важный прорыв в создании более надежных языковых моделей. В отличие от простого выявления неточностей, данная система способна не только указать на проблему, но и определить, в какой части генерируемого текста она возникла, и предложить возможное объяснение причин её появления. Это позволяет не просто исправить ошибку, но и понять, какие аспекты работы модели нуждаются в улучшении, что существенно повышает её прозрачность и способствует построению систем, которым можно доверять в критически важных приложениях. Диагностика галлюцинаций открывает путь к созданию языковых моделей, способных не только генерировать текст, но и обосновывать его достоверность.
Интеграция различных режимов рассуждений в систему диагностики языковых моделей позволяет глубже понять причины возникновения неточностей и галлюцинаций. Вместо простого обнаружения ошибок, подобный подход направлен на выявление когнитивных процессов, которые привели к их возникновению — например, неверные логические выводы, недостаточная проверка фактов или ошибочные ассоциации. Анализ режимов рассуждений, таких как дедукция, индукция или абдукция, позволяет не только локализовать источник неточности, но и определить, какой тип логической ошибки был допущен моделью. Это, в свою очередь, открывает возможности для разработки более эффективных методов коррекции и обучения, направленных на устранение конкретных когнитивных слабостей и повышение надежности генерируемых текстов. Таким образом, диагностика, основанная на анализе режимов рассуждений, представляет собой важный шаг к созданию более прозрачных и предсказуемых языковых моделей.
В основе повышения надежности языковых моделей лежит их способность опираться на проверенные источники знаний. В данном исследовании особое внимание уделяется использованию Википедии (версия 20231101.en) в качестве основного источника данных. Такой подход позволяет значительно улучшить «заземление» модели, то есть её связь с общепринятыми фактами и сведениями. Использование структурированной и постоянно обновляемой базы данных Википедии способствует снижению вероятности генерации неправдоподобной или ложной информации, поскольку модель имеет возможность сопоставлять свои ответы с авторитетными источниками. Это, в свою очередь, повышает доверие к генерируемому тексту и делает языковую модель более полезной и надежной в различных приложениях.
Для выявления несоответствий между исходным текстом и сгенерированным, применяются методы логического вывода на естественном языке. Данный подход позволяет установить взаимосвязь между утверждениями в обоих текстах, определяя, следует ли одно из другого, противоречит ли оно, или же является независимым. По сути, модель оценивает, является ли сгенерированный текст логическим следствием предоставленного источника, что позволяет эффективно обнаруживать галлюцинации и фактические ошибки. Использование таких техник способствует повышению надежности языковых моделей, гарантируя, что генерируемый контент не только грамматически корректен, но и логически обоснован и соответствует исходным данным.
Исследование, представленное в данной работе, подчеркивает необходимость перехода от простого обнаружения галлюцинаций в больших языковых моделях к их диагностике, локализации и смягчению. Авторы демонстрируют, что даже относительно небольшая модель, используя инновационный конвейер синтеза данных и обучение с подкреплением, способна достичь конкурентоспособных результатов. В этом контексте, слова Винтона Серфа представляются особенно актуальными: «Если вы не можете измерить, вы не можете улучшить». Именно акцент на измеримости и автоматизированном синтезе данных позволяет не только выявлять недостатки, но и целенаправленно улучшать модели, приближаясь к созданию более надежных и правдивых систем.
Что дальше?
Представленная работа, стремясь не просто обнаружить, но и диагностировать «галлюцинации» больших языковых моделей, открывает ящик Пандоры. Каждая новая архитектура обещает свободу от ошибок, пока не потребует жертвоприношений в виде сложности отладки и верификации. Идея автоматического синтеза данных — шаг в верном направлении, но за каждым сгенерированным фактом скрывается призрак предвзятости, заложенной в алгоритме генерации. Попытка «вырастить» достоверность, а не «построить» ее, не избавляет от необходимости признать, что порядок — это просто временный кэш между сбоями.
Следующим этапом видится не столько повышение точности моделей, сколько разработка инструментов для оценки степени галлюцинаций. Не все ошибки одинаково вредны; важно понимать, где модель «творчески интерпретирует» реальность, а где совершает критическую фактическую ошибку. Иными словами, необходимо перейти от бинарной оценки «правда/ложь» к более тонкой градации, учитывающей контекст и потенциальный вред.
Системы — это не инструменты, а экосистемы. Настоящий вызов — не в создании модели, которая «никогда не ошибается», а в разработке инфраструктуры, способной быстро обнаруживать, локализовать и смягчать последствия неизбежных ошибок. Ведь даже самая совершенная модель — лишь отражение несовершенства мира, в котором она существует.
Оригинал статьи: https://arxiv.org/pdf/2601.09734.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-01-16 19:05