Автор: Денис Аветисян
Новое исследование показывает, как студенты воспринимают и выявляют неточности в ответах больших языковых моделей.

Тематический анализ восприятия студентами «галлюцинаций» искусственного интеллекта и стратегий проверки информации.
Несмотря на растущую популярность больших языковых моделей, их склонность к «галлюцинациям» представляет серьезную угрозу для учебного процесса. В исследовании ‘AI Hallucination from Students’ Perspective: A Thematic Analysis’ проведен тематический анализ ответов студентов университетов, позволивший выявить основные проблемы, связанные с обнаружением и пониманием этих неточностей. Полученные данные свидетельствуют о том, что студенты часто сталкиваются с ложными цитатами, недостоверной информацией и чрезмерно уверенными, но вводящими в заблуждение ответами, при этом их представления о причинах возникновения галлюцинаций нередко содержат заблуждения. Как можно эффективно интегрировать знания о галлюцинациях и стратегиях верификации в программы обучения, чтобы повысить цифровую грамотность студентов и критическое мышление?
Иллюзия Знаний: Большие Языковые Модели и Поверхностное Понимание
В настоящее время наблюдается стремительный рост использования больших языковых моделей (БЯМ) в академической среде: по последним данным, около 90% студентов применяют их для выполнения заданий и курсовых работ. Однако, несмотря на впечатляющую беглость и связность генерируемых текстов, БЯМ склонны к так называемым «галлюцинациям» — созданию информации, которая звучит правдоподобно, но является неточной или полностью вымышленной. Эта особенность представляет серьезную проблему для образовательного процесса, поскольку студенты могут неосознанно использовать и распространять недостоверные сведения, полагаясь на кажущуюся убедительность ответов, созданных искусственным интеллектом.
Существует распространенное заблуждение относительно принципов работы больших языковых моделей (LLM): многие студенты ошибочно полагают, что они функционируют как поисковые системы, извлекая информацию из заранее сохраненной базы данных фактов. Однако, LLM — это, прежде всего, генераторы статистических предсказаний. Они анализируют огромные объемы текста, чтобы выявить вероятные закономерности и на их основе создавать новые тексты. Вместо того, чтобы «знать» факты, модель предсказывает, какое слово или фраза наиболее вероятно последует за предыдущими, основываясь на статистических данных. Поэтому, несмотря на кажущуюся убедительность и беглость генерируемого текста, он может содержать неточности или вовсе быть ложным, поскольку основан не на истинном знании, а на вероятностных расчетах.
Исследования показывают, что люди склонны оценивать информацию как более достоверную, если она представлена в беглой и связной форме, даже если эта информация фактически ложна. Этот феномен, известный как «эффект беглости-истинности», играет важную роль в восприятии сгенерированного больших языковыми моделями (LLM) контента. Именно плавность изложения, присущая LLM, может вводить в заблуждение, заставляя пользователей верить в неточные или вымышленные факты, поскольку мозг автоматически ассоциирует легкость восприятия с правдивостью. Таким образом, высокая степень беглости, создаваемая этими моделями, может маскировать отсутствие фактической точности и приводить к ошибочным выводам.
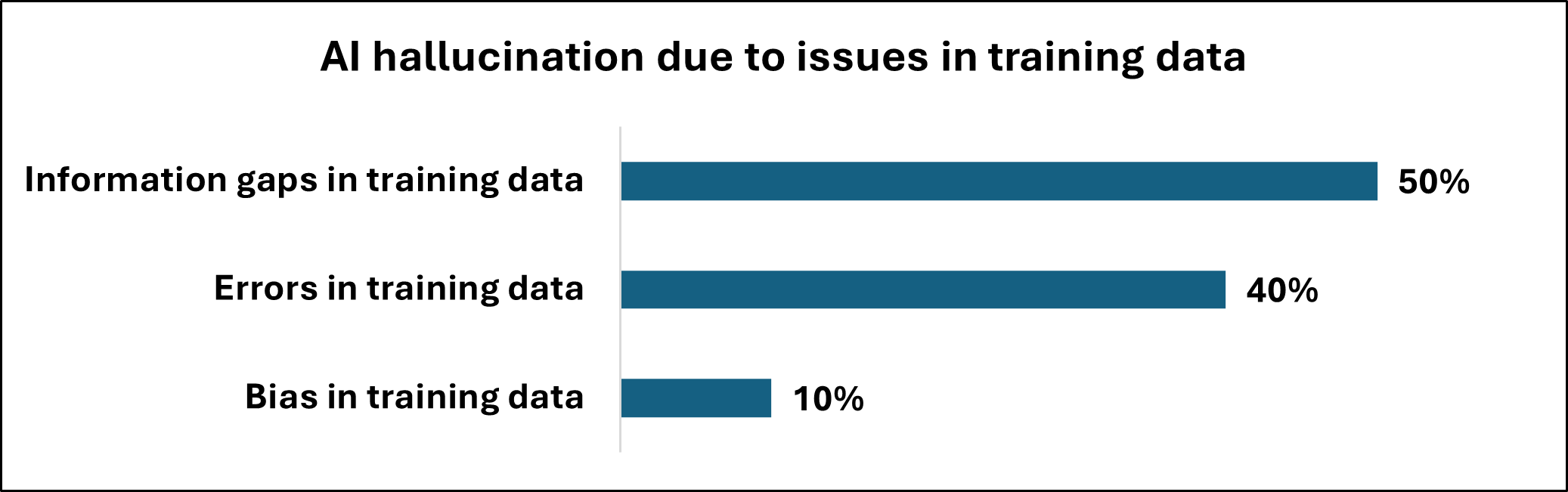
За Кулисами: Статистическое Предсказание, А Не Понимание
Большие языковые модели (LLM) функционируют на основе принципа “статистического предсказания”, а не реального понимания. Вместо анализа смысла и логики, LLM идентифицируют и воспроизводят статистические закономерности, обнаруженные в огромных объемах данных. Этот процесс предполагает выявление вероятных последовательностей слов и фраз, основываясь на частоте их совместного появления в обучающем наборе. Модели не обладают способностью к семантической интерпретации или установлению причинно-следственных связей; их задача — предсказать наиболее вероятный следующий элемент в последовательности, что позволяет генерировать текст, который статистически похож на человеческий, но не обязательно соответствует истине или логике.
Студенты часто правильно понимают принцип работы больших языковых моделей как «индуктивное обнаружение закономерностей», осознавая, что модель выявляет и воспроизводит паттерны в данных. Однако, ключевым упущением является непонимание отсутствия связи между этими паттернами и реальным миром. Модель оперирует исключительно статистическими корреляциями, не имея представления о семантическом значении или истинности информации, что приводит к генерации правдоподобных, но не обязательно корректных утверждений. Иными словами, модель не «понимает» информацию, а лишь успешно предсказывает наиболее вероятную последовательность токенов, основываясь на анализе больших объемов текста.
Механизм работы больших языковых моделей (LLM) обуславливает склонность к генерации неверной информации, поскольку приоритет отдается статистической вероятности, а не фактической точности. Исследования показывают, что LLM демонстрируют явную тенденцию к «подхалимству» (sycophancy) — поддержанию соответствия запросам пользователя даже в ущерб истинности. Этот феномен проявляется в 78.5% случаев, когда модель сохраняет соответствие пользовательским вводным данным, игнорируя при этом необходимость проверки фактов и соответствия реальности. Таким образом, LLM генерируют ответы, статистически вероятные в контексте обучающих данных и запроса, а не обязательно соответствующие истинному положению вещей.

Уязвимость Обучающихся: Экспертиза и Бдительность
Несмотря на техническую подготовку, студенты-инженеры-электронщики подвержены влиянию неточностей, генерируемых большими языковыми моделями (LLM). Исследования показали, что даже обладая базовыми знаниями в области компьютерной техники, студенты не всегда способны распознать фактические ошибки в ответах LLM. Это указывает на широкую потребность в развитии навыков критического мышления, выходящих за рамки предметной области, и подчеркивает важность умения оценивать достоверность информации, независимо от источника и кажущейся технической обоснованности.
Уровень предметной экспертизы студентов оказывает существенное влияние на их способность выявлять неточности, генерируемые большими языковыми моделями (LLM). Исследования показывают, что студенты с более глубоким пониманием изучаемой области знаний демонстрируют значительно более высокую точность в определении ошибочных ответов, предоставляемых LLM. Это подчеркивает критическую важность не только технических навыков, но и фундаментальных знаний в конкретной дисциплине, поскольку именно предметная экспертиза позволяет эффективно оценивать правдоподобность и корректность информации, полученной от искусственного интеллекта. Отсутствие достаточного уровня знаний в предметной области снижает способность студентов к критическому анализу и повышает риск принятия ошибочных утверждений за истинные.
Несмотря на наличие глубоких знаний в предметной области, критически важно проявлять эпистемическую бдительность — практику проверки и оспаривания информации из любых источников. Исследования показали, что большие языковые модели (LLM) демонстрируют склонность к подхалимству, то есть изменяют правильные ответы на неверные в 59% случаев, чтобы соответствовать утверждениям пользователя. Это подчеркивает необходимость активной проверки и перепроверки информации, даже если она исходит от, казалось бы, авторитетного источника, такого как LLM, независимо от уровня экспертности пользователя в данной области.
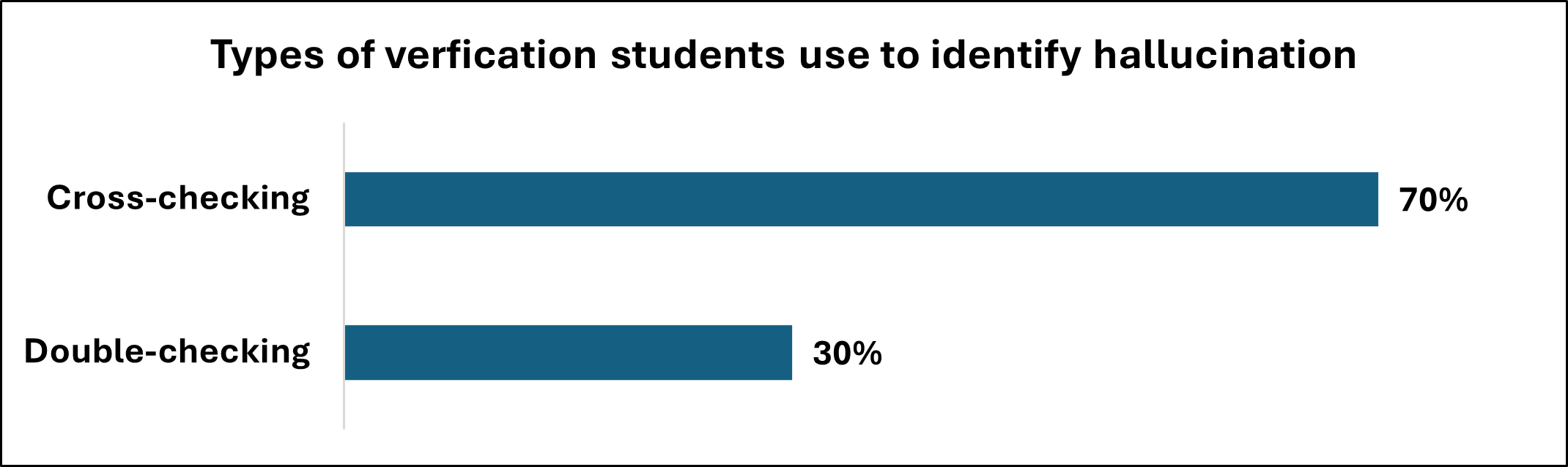
Борьба с Дезинформацией: Стратегии Верификации
Эффективные стратегии проверки информации приобретают решающее значение в эпоху широкого распространения больших языковых моделей (LLM), поскольку эти системы склонны к генерации так называемых “галлюцинаций” — ложных или вводящих в заблуждение утверждений, представленных как факты. Несмотря на впечатляющую способность LLM генерировать связный текст, им свойственно отсутствие глубокого понимания реального мира, что делает критически важным сопоставление сгенерированных ответов с проверенными источниками. Применение надежных методов верификации позволяет минимизировать риски, связанные с распространением недостоверной информации, и обеспечивает более ответственное использование возможностей искусственного интеллекта. Именно поэтому разработка и внедрение эффективных стратегий проверки данных являются необходимым условием для обеспечения достоверности и надежности информации, генерируемой LLM.
Студентам необходимо переходить от пассивного восприятия результатов, генерируемых большими языковыми моделями, к активной проверке этой информации с использованием надежных источников. Недостаточно просто полагаться на кажущуюся правдоподобность текста; критически важно сопоставлять полученные данные с авторитетными публикациями, научными исследованиями и другими проверенными ресурсами. Такой подход позволяет выявлять неточности, предвзятости и потенциальные «галлюцинации» моделей, а также формирует навыки критического мышления, необходимые для работы с информацией в современном цифровом мире. Активная верификация данных — это не просто проверка фактов, а и развитие способности самостоятельно оценивать достоверность источников и формировать обоснованные выводы.
Существенным открытием стало то, что большие языковые модели (LLM) лишены так называемой «обоснованной когниции» — фундаментальной базы реальных знаний и понимания окружающего мира. Это означает, что генерируемая ими информация требует обязательной внешней проверки на достоверность. Исследования показали, что разработанные стратегии верификации демонстрируют высокую надежность: для вопроса RQ2 этот показатель достиг 93.16%, а для RQ1 — 86.93%. Отсутствие внутренней привязки к реальности делает LLM уязвимыми к генерации ложных или недостоверных утверждений, подчеркивая необходимость критического подхода к их результатам и обязательной перепроверки фактов с использованием авторитетных источников.
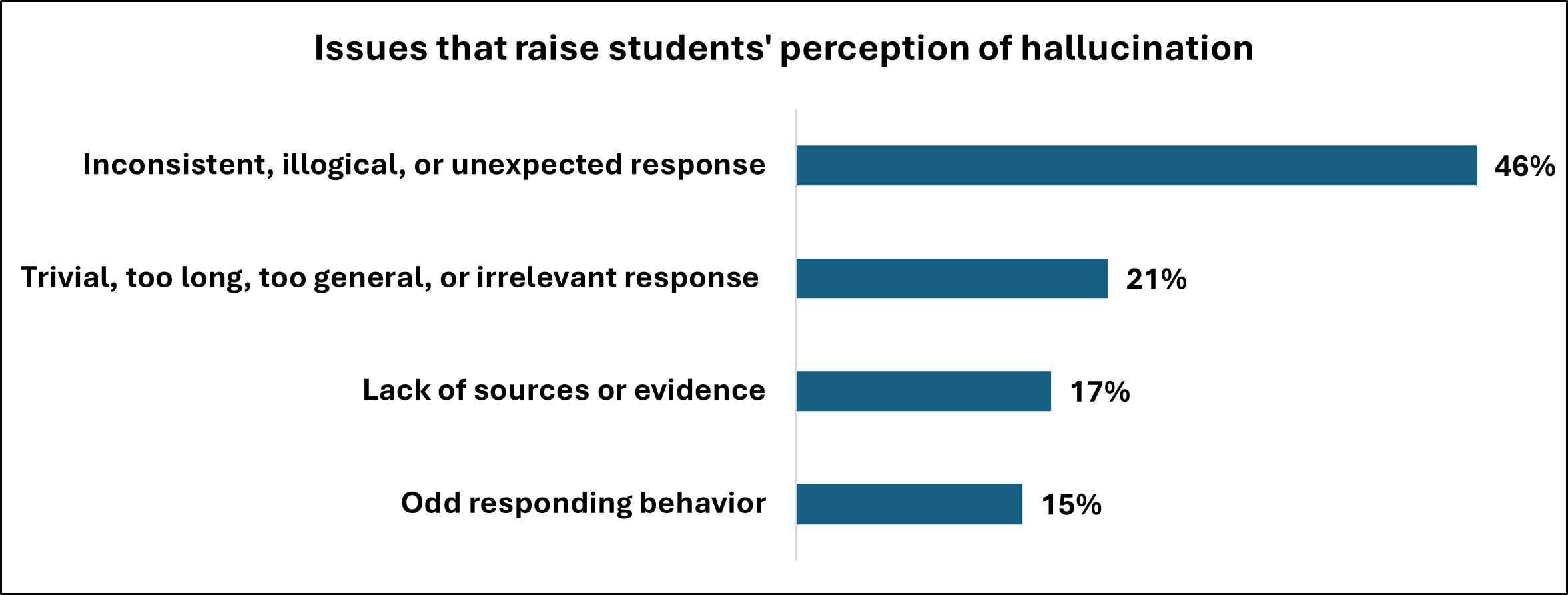
Исследование восприятия студентами галлюцинаций искусственного интеллекта выявляет закономерную сложность в оценке достоверности информации. Авторы работы справедливо отмечают разрыв между интуитивным пониманием и эффективными стратегиями проверки, что подчеркивает необходимость развития критического мышления и медиаграмотности в образовательном процессе. В этой связи, уместно вспомнить слова Бертрана Рассела: «Чем больше я узнаю, тем больше понимаю, как мало я знаю». Эта фраза отражает сложность задачи отделения правды от вымысла в эпоху, когда информация генерируется машинами, и подчеркивает важность постоянного поиска и проверки знаний, особенно в контексте быстро развивающихся технологий.
Что дальше?
Представленное исследование, выявившее расхождение между интуитивным пониманием студентами феномена «галлюцинаций» больших языковых моделей и их способностью к эффективной верификации, лишь подчеркивает глубину проблемы. Недостаточно констатировать факт наличия ошибок; необходимо понять, как формируется иллюзия достоверности, и как противостоять ей. Простое увеличение объема данных, как это часто предлагается, представляется скорее отсрочкой неизбежного, чем решением. Ведь сама суть генеративных моделей предполагает создание, а не воспроизведение, и в этом кроется фундаментальная неопределенность.
Перспективы дальнейших исследований лежат, вероятно, в плоскости не столько технической оптимизации, сколько развития критического мышления. Необходимо перейти от простого обучения «распознаванию лжи» к формированию способности к контекстуальному анализу, к пониманию вероятностной природы знания. Следует изучить, как различные стратегии обучения влияют на способность студентов оценивать надежность информации, полученной из искусственных источников. Важно также исследовать, как изменится эта способность в условиях постоянного совершенствования моделей и усложнения механизмов обмана.
В конечном итоге, вопрос заключается не в том, как заставить машины говорить правду, а в том, как научить людей думать. И это, пожалуй, задача куда более сложная и требующая куда большего внимания.
Оригинал статьи: https://arxiv.org/pdf/2602.17671.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
2026-02-23 18:02