Автор: Денис Аветисян
Новый алгоритм KLENT позволяет агентам самостоятельно осваивать сложные настольные игры, используя меньше вычислительных ресурсов, чем существующие методы.
В статье представлен алгоритм обучения с подкреплением, сочетающий регуляризацию KL и энтропии с лямбда-возвратами для повышения эффективности в настольных играх.
Несмотря на успехи методов, основанных на поиске, в обучении искусственного интеллекта для настольных игр, их высокие вычислительные требования препятствуют широкому воспроизведению результатов. В данной работе, посвященной ‘Resource-Efficient Model-Free Reinforcement Learning for Board Games’, предложен алгоритм обучения с подкреплением без модели, направленный на повышение эффективности обучения в сложных игровых средах. Ключевым результатом является демонстрация конкурентоспособной или превосходящей производительности по сравнению с традиционными методами, основанными на поиске, при значительно меньших вычислительных затратах, что достигается благодаря сочетанию регуляризации KL и энтропии с lambda-возвратами. Сможет ли предложенный подход открыть новые возможности для применения обучения с подкреплением без модели в задачах, ранее доминируемых поисковыми алгоритмами?
Сложность как Вызов: Преодолевая Ограничения в Обучении с Подкреплением
Традиционные методы обучения с подкреплением часто сталкиваются с серьезными трудностями при работе со сложными игровыми средами, характеризующимися огромным количеством возможных состояний. Этот феномен, известный как «проклятие размерности», существенно ограничивает их применимость. Алгоритмы, эффективно работающие в простых задачах, оказываются неспособными эффективно исследовать и обучаться в пространствах состояний, насчитывающих миллиарды или даже триллионы вариантов. Поиск оптимальной стратегии в таких условиях требует непомерных вычислительных ресурсов и времени, что делает традиционные подходы непрактичными для решения реальных задач, таких как современные видеоигры или управление сложными системами. В результате, необходимость в разработке новых, более эффективных алгоритмов, способных справляться с этим вызовом, становится все более актуальной.
Успешная навигация в сложных игровых пространствах требует от агентов не просто реакции на текущую ситуацию, а способности к стратегическому планированию и эффективному исследованию среды. Существующие алгоритмы, однако, испытывают значительные трудности в реализации подобного подхода. Проблема заключается в том, что традиционные методы часто оказываются неспособными эффективно оценивать долгосрочные последствия своих действий, а также оптимизировать процесс поиска оптимальной стратегии в условиях огромного количества возможных вариантов. Необходимость балансировать между изучением новых возможностей и использованием уже известных решений, особенно когда вознаграждение за действия может быть отложено во времени, представляет собой серьезную проблему для современных систем искусственного интеллекта, требующую разработки принципиально новых подходов к обучению с подкреплением.
Суть сложности обучения с подкреплением в сложных средах заключается в тонком балансе между исследованием новых возможностей и использованием уже известных стратегий. Особенно остро эта проблема проявляется в ситуациях, когда вознаграждение за действия приходит с задержкой во времени. Агент должен не просто реагировать на непосредственные стимулы, но и предвидеть отдаленные последствия своих действий, что требует умения оценивать долгосрочную ценность различных путей. Недостаточное исследование ограничивает возможности агента, не позволяя обнаружить более эффективные стратегии, а чрезмерная ориентация на использование текущих знаний может привести к застою в локальном оптимуме. Поэтому разработка алгоритмов, способных эффективно решать эту дилемму, является ключевой задачей в области искусственного интеллекта.
AlphaZero: Прорыв в Искусственном Интеллекте для Игр
Алгоритм AlphaZero использует метод Монте-Карло поиска по дереву (Monte Carlo Tree Search, MCTS) для оценки игровых позиций и выбора оптимальных ходов. В отличие от традиционных алгоритмов, AlphaZero не перебирает все возможные варианты развития игры, а фокусируется на наиболее перспективных ветвях дерева игры. Процесс MCTS включает в себя четыре основных этапа: выбор (selection), расширение (expansion), моделирование (simulation) и обратное распространение (backpropagation). Выбор осуществляется на основе статистики посещений узлов, расширение добавляет новые узлы в дерево, моделирование имитирует случайные игры до конца, а обратное распространение обновляет статистику узлов на основе результатов симуляций. Этот итеративный процесс позволяет AlphaZero эффективно исследовать пространство состояний игры и находить оптимальные стратегии, концентрируясь на наиболее вероятных и выгодных ходах.
Поиск в AlphaZero направляется глубокой нейронной сетью, которая одновременно предсказывает ценность (оценку) шахматной позиции и вероятности различных возможных ходов из этой позиции. Сеть оценивает позицию, выдавая скалярное значение, отражающее ожидаемый исход игры (например, вероятность выигрыша). Одновременно, она генерирует распределение вероятностей по всем допустимым ходам, указывая, какие ходы считаются наиболее перспективными в данной ситуации. Эти прогнозы используются алгоритмом Monte Carlo Tree Search для эффективного исследования игрового дерева, позволяя AlphaZero концентрироваться на наиболее многообещающих вариантах и избегать рассмотрения заведомо невыгодных позиций.
Алгоритм AlphaZero демонстрирует сверхчеловеческую производительность в таких играх, как шахматы, го и сё, благодаря обучению исключительно посредством самообучения. В отличие от традиционных игровых ИИ, использующих базы данных и экспертные знания, AlphaZero начинает с нулевых знаний о конкретной игре. Он генерирует игровые позиции путем случайной игры против самого себя и использует полученные данные для улучшения своей стратегии посредством глубокого обучения с подкреплением. Этот процесс позволяет алгоритму открывать новые, нетривиальные стратегии, превосходящие возможности человека, без какого-либо предварительного программирования или человеческого вмешательства в процесс обучения.
Варианты AlphaZero, такие как TRPO AlphaZero и Gumbel AlphaZero, представляют собой усовершенствования базового алгоритма, направленные на повышение эффективности обучения и поиска. TRPO AlphaZero использует алгоритм Trust Region Policy Optimization (TRPO) для стабилизации процесса обучения нейронной сети, предотвращая резкие изменения параметров и обеспечивая более плавное схождение. Gumbel AlphaZero, в свою очередь, применяет технику Gumbel-Softmax для аппроксимации категориального семплирования, что позволяет проводить более эффективный поиск по дереву игры и улучшает использование вычислительных ресурсов. Обе модификации позволяют добиться более высокой производительности и скорости обучения по сравнению с оригинальным AlphaZero, сохраняя при этом способность к самообучению и достижению сверхчеловеческого уровня игры.
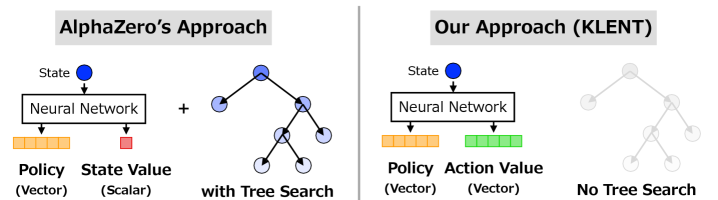
KLENT: Повышение Стабильности и Эффективности Обучения
KLENT представляет собой новый подход к обучению с подкреплением, объединяющий оптимизацию политики с использованием KL-регуляризации, регуляризации энтропии и λ-возвратов. KL-регуляризация ограничивает изменения политики на каждом шаге, предотвращая резкие отклонения и повышая стабильность обучения. Регуляризация энтропии стимулирует исследование пространства действий, что позволяет агенту находить более оптимальные стратегии в сложных средах. Использование λ-возвратов сочетает преимущества n-шаговых и Монте-Карло возвратов, обеспечивая более точную и стабильную оценку ценностной функции и, как следствие, более эффективное обучение.
KL-регуляризация в алгоритме KLENT обеспечивает постепенное обновление политики агента, предотвращая резкие изменения, которые могут дестабилизировать процесс обучения. Этот метод ограничивает отклонение новой политики от предыдущей, используя дивергенцию Кульбака-Лейблера D_{KL}(π_{old} || π_{new}) в качестве штрафа. Ограничивая величину обновления политики на каждом шаге, KL-регуляризация способствует более стабильному и предсказуемому обучению, особенно в сложных средах, где резкие изменения могут привести к потере уже приобретенных знаний и снижению производительности.
Регуляризация энтропии в KLENT способствует исследованию пространства действий агентом, что особенно важно в сложных средах. Путем добавления члена, пропорционального энтропии распределения действий, в целевую функцию, алгоритм стимулирует агента к выбору более разнообразных действий, даже если они кажутся менее перспективными на текущем этапе обучения. Это позволяет избежать застревания в локальных оптимумах и способствует обнаружению оптимальных стратегий, которые могли бы быть упущены при жадном выборе действий. Увеличение энтропии в процессе обучения приводит к более эффективному исследованию и, как следствие, к улучшению общей производительности агента в задачах, требующих адаптации к сложным и неопределенным условиям.
Использование λ-возвратов (λ-returns) в KLENT объединяет преимущества n-шаговых возвратов и возвратов Монте-Карло для повышения точности и стабильности обучения функции ценности. N-шаговые возвраты обеспечивают смещение, позволяя агенту быстро обучаться, но могут быть неточными при большом количестве шагов. Возвраты Монте-Карло, напротив, не имеют смещения, но требуют полного эпизода для расчета, что замедляет обучение. λ-возврат представляет собой взвешенную сумму этих двух подходов, где параметр λ (от 0 до 1) контролирует вклад каждого метода. При λ=0 используется только возврат Монте-Карло, при λ=1 — n-шаговый возврат. Оптимальное значение λ позволяет эффективно сочетать преимущества обоих подходов, снижая дисперсию и смещение, что приводит к более стабильному и быстрому обучению.
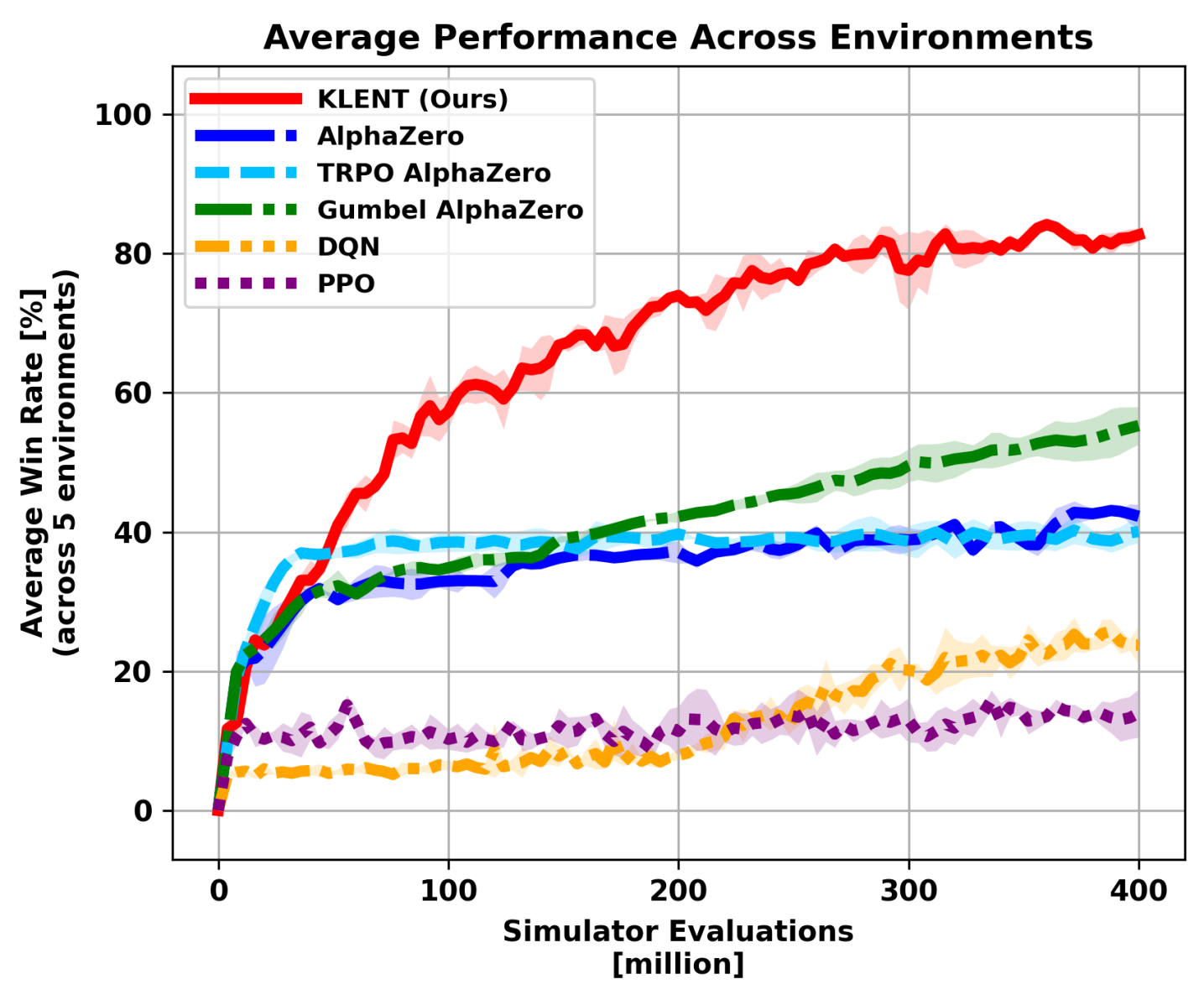
В ходе экспериментов KLENT продемонстрировал значительное повышение эффективности обучения по сравнению с существующими методами в пяти различных игровых средах. В частности, KLENT потребовалось в четыре раза меньше симуляций для достижения сопоставимых результатов с Gumbel AlphaZero — 300 миллионов против 75 миллионов. Кроме того, алгоритм KLENT успешно применился к обучению в игре Го (19×19), достигнув конкурентоспособных показателей. Подтверждена обобщающая способность метода на примерах таких игр, как Animal Shogi, Gardner Chess, Hex и Othello.
В ходе экспериментов было установлено, что KLENT демонстрирует в четыре раза более высокую эффективность обучения по сравнению с Gumbel AlphaZero. Для достижения сопоставимых результатов KLENT потребовалось всего 300 миллионов симуляций, в то время как Gumbel AlphaZero потребовалось 750 миллионов. Данный показатель свидетельствует о значительном снижении вычислительных затрат и ускорении процесса обучения при использовании KLENT.
Эффективность KLENT была подтверждена на широком спектре настольных игр, включая Animal Shogi, Gardner Chess, Go, Hex и Othello. Данное разнообразие игровых сред демонстрирует способность алгоритма к обобщению и адаптации к различным задачам, не требуя существенной перенастройки параметров. Успешная работа KLENT в этих играх подтверждает, что предложенный подход к обучению с подкреплением не является специфичным для какой-либо конкретной задачи, а может быть применен к широкому классу проблем, требующих поиска оптимальной стратегии.

Влияние и Перспективы: Расширение Горизонтов Искусственного Интеллекта
Принципы, лежащие в основе алгоритмов KLENT и AlphaZero, а именно сочетание поиска с глубоким обучением, акцент на стабильность обучения и стимулирование исследования, обладают широкой применимостью за пределами игровой среды. Данный подход позволяет создавать системы, способные эффективно решать сложные задачи в различных областях. Например, в робототехнике это может привести к разработке более адаптивных и автономных роботов, способных к планированию и принятию решений в реальном времени. В сфере автономного вождения комбинирование поиска и обучения с подкреплением позволит создавать более безопасные и эффективные системы управления транспортными средствами. Принципы KLENT и AlphaZero также применимы к задачам управления ресурсами, оптимизации логистических цепочек и даже к финансовому трейдингу, где требуется прогнозирование рыночных тенденций и принятие быстрых решений в условиях неопределенности. Гибкость и эффективность этих алгоритмов открывают новые возможности для решения широкого спектра практических задач.
Перспективы применения алгоритмов, подобных KLENT и AlphaZero, выходят далеко за рамки игровых задач. Эти методы, основанные на сочетании поиска и глубокого обучения, демонстрируют значительный потенциал в различных областях. В робототехнике они могут обеспечить более адаптивное и эффективное управление сложными механизмами. В сфере автономного вождения — повысить безопасность и надежность систем принятия решений. В области управления ресурсами — оптимизировать распределение и использование ограниченных активов. И, наконец, в финансовой торговле — разрабатывать более точные и прибыльные стратегии. Успешная реализация этих алгоритмов в перечисленных областях требует дальнейших исследований и адаптации к специфическим требованиям каждой из них, однако уже сейчас прослеживается четкая тенденция к их широкому внедрению и практическому применению.
Перспективные исследования направлены на расширение возможностей представленных алгоритмов, в частности, на их адаптацию к более сложным и реалистичным средам. Особое внимание уделяется повышению эффективности обучения, чтобы алгоритмы могли достигать высоких результатов, используя меньшее количество данных. Разработка методов переноса обучения — ключевая задача, позволяющая использовать знания, полученные в одной среде, для решения задач в другой, что значительно ускоряет процесс обучения и снижает потребность в больших объемах данных для каждой новой задачи. Успешная реализация этих направлений откроет путь к созданию более гибких и универсальных систем искусственного интеллекта, способных решать широкий спектр задач в различных областях.
Дальнейшее развитие искусственного интеллекта неразрывно связано с интеграцией подходов, подобных KLENT и AlphaZero, с другими передовыми методами машинного обучения. В частности, синергия с обучением подражанию позволит алгоритмам быстрее осваивать сложные задачи, перенимая опыт у экспертов, а мета-обучение предоставит возможность адаптироваться к новым, ранее не встречавшимся ситуациям с минимальными затратами ресурсов. Такое объединение потенциально способно создать системы, обладающие не только способностью к глубокому поиску и обучению с подкреплением, но и к обобщению знаний и быстрой адаптации, что приведет к созданию действительно интеллектуальных агентов, способных решать широкий спектр задач с уровнем гибкости и эффективности, приближающимся к человеческому.
Представленная работа демонстрирует стремление к лаконичности и эффективности в алгоритмах обучения с подкреплением. Как отмечал Тим Бернерс-Ли: «Простота — высшая степень изысканности». KLENT, представленный в статье, воплощает этот принцип, используя регуляризацию KL и энтропии для оптимизации политики и снижения вычислительных затрат. Алгоритм достигает конкурентоспособных результатов в настольных играх, при этом требуя меньше ресурсов, чем традиционные методы поиска. Это подтверждает, что совершенство достигается не за счет усложнения, а за счет устранения избыточности и фокусировки на ключевых принципах, что соответствует философии автора.
Что дальше?
Представленная работа, хотя и демонстрирует эффективность алгоритма KLENT в обучении без модели для настольных игр, лишь слегка приоткрывает завесу над истинной сложностью проблемы. Достижение конкурентоспособности требует не только утонченных методов регуляризации, но и критического переосмысления самой парадигмы поиска. Иллюзия “интеллекта”, порождаемая успешной игрой, часто маскирует фундаментальную неспособность к обобщению. Необходимо сместить фокус с достижения локального оптимума в конкретной игре на создание алгоритмов, способных адаптироваться к принципиально новым правилам, к непредсказуемым изменениям ландшафта.
Ограничения, связанные с вычислительными ресурсами, остаются доминирующим фактором. Поиск действительно плотных представлений знания, минимизирующих потребность в “сырой” вычислительной мощности, представляется более плодотворной задачей, чем дальнейшая оптимизация существующих алгоритмов. Иначе говоря, вместо того чтобы пытаться выжать максимум из ограниченного, необходимо стремиться к принципиально новым архитектурам, основанным на минимализме и эффективности. Ненужное — это насилие над вниманием, а плотность смысла — новый минимализм.
В конечном счете, истинный прогресс в области обучения с подкреплением без модели будет достигнут не за счет усложнения алгоритмов, а за счет их упрощения. Сложность — это тщеславие; ясность — милосердие. Совершенство достигается не когда нечего добавить, а когда нечего убрать.
Оригинал статьи: https://arxiv.org/pdf/2602.10894.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-12 15:38