Автор: Денис Аветисян
Новое исследование показывает, что надежность объяснений, основанных на контрфактах, подвержена влиянию различных видов неопределенности, присущих моделям машинного обучения.
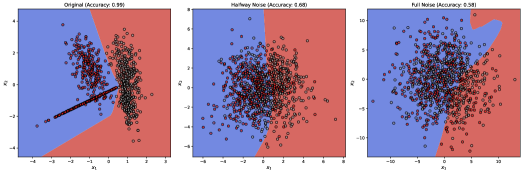
Работа демонстрирует, что как алеаторная, так и эпистемическая неопределенность в моделях машинного обучения существенно влияют на устойчивость контрфактических объяснений, и не существует универсальной комбинации модели и метода генерации объяснений, обеспечивающей максимальную надежность.
Несмотря на широкое распространение, интерпретируемость моделей машинного обучения часто страдает от недостаточной устойчивости к неопределенности данных и моделей. В работе, посвященной ‘The Impact of Machine Learning Uncertainty on the Robustness of Counterfactual Explanations’, исследуется влияние как алеаторной, так и эпистемической неопределенности на надежность контрфактических объяснений — инструментов, позволяющих понять, какие минимальные изменения входных признаков способны изменить решение модели. Полученные результаты показывают, что даже незначительное снижение точности модели, вызванное шумом или неполнотой данных, может привести к существенным изменениям в генерируемых контрфактических объяснениях. Какие методы позволят создавать более надежные и устойчивые объяснения в условиях реальной изменчивости данных и моделей машинного обучения?
Пределы Прогнозирования: За Точность и Понимание
Часто при создании моделей машинного обучения основное внимание уделяется достижению максимальной прогностической точности, в то время как вопросы объяснимости и устойчивости остаются за кадром. Такой подход может привести к созданию “черных ящиков”, способных выдавать точные прогнозы, но не позволяющих понять, каким образом принимаются решения, и как модель поведет себя в нестандартных или меняющихся условиях. Игнорирование этих аспектов создает риски, особенно в критически важных областях, где требуется не только предсказание, но и понимание причинно-следственных связей, а также гарантия надежности и предсказуемости работы системы. В результате, модели, ориентированные исключительно на точность, могут оказаться уязвимыми к незначительным изменениям входных данных или новым, не учтенным сценариям, что снижает их практическую ценность и надежность в реальных условиях эксплуатации.
Исследования показывают, что оценка моделей машинного обучения исключительно по общей точности может скрывать существенные недостатки в конкретных ситуациях. Анализ таких сложных наборов данных, как “German Credit Dataset”, “Adult Income Dataset” и “Give Me Some Credit Dataset”, выявил, что даже незначительные изменения во входных данных способны приводить к непропорциональному увеличению расстояния до контрфактического объяснения. В некоторых случаях, дистанция до объяснения изменялась более чем на 20% при снижении общей точности модели менее чем на 5%. Этот факт подчеркивает, что высокая точность не гарантирует стабильности и надежности модели в различных сценариях, и требует более глубокого анализа ее поведения в критических точках.
Современные модели машинного обучения часто стремятся к максимальной точности прогнозов, упуская из виду фундаментальную роль неопределенности. Существует два основных типа неопределенности, влияющих на надежность моделей в реальных условиях. Алеаторическая неопределенность возникает из-за присущего шума в данных — случайных ошибок измерений или неполноты информации, которые невозможно устранить даже при наличии большего объема данных. В то же время, эпистемическая неопределенность обусловлена ограниченностью данных, используемых для обучения модели — незнанием распределения вероятностей, которое могло бы быть раскрыто при изучении большего количества примеров. Игнорирование этих видов неопределенности приводит к завышенной оценке надежности прогнозов и может привести к серьезным последствиям в критически важных приложениях, где необходимо учитывать не только предсказанное значение, но и уверенность в нем.
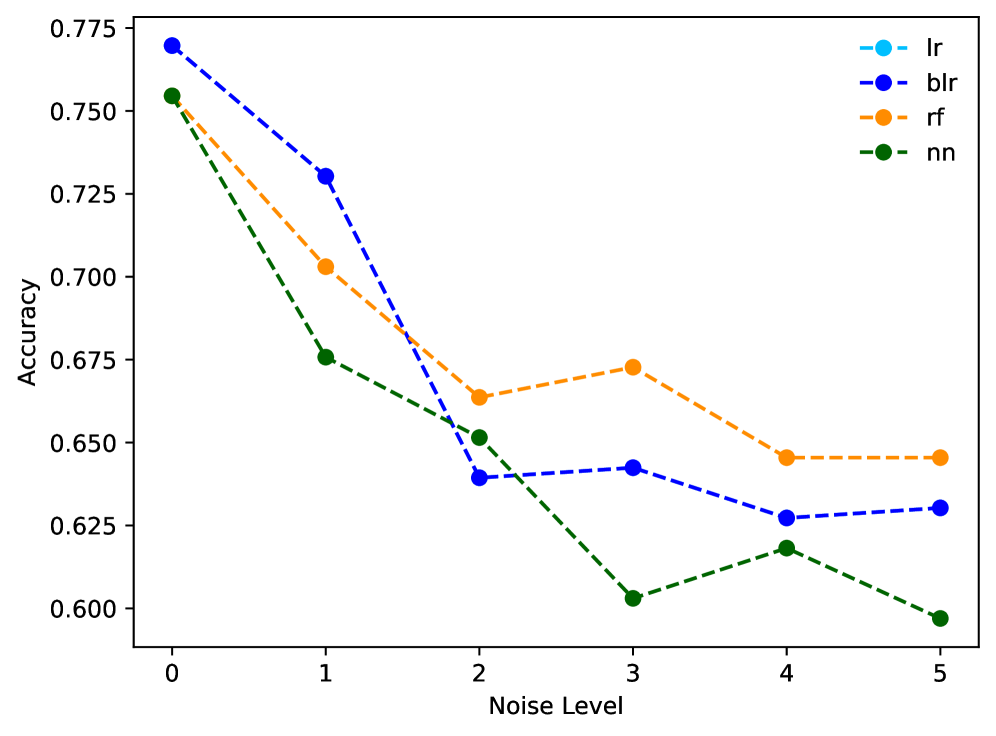
Эффект Расёмона: Множественность Равноправных Объяснений
Эффект Расёмона демонстрирует, что для любого заданного набора данных может существовать несколько равноценных моделей, каждая из которых предлагает различное, но правдоподобное объяснение. Это означает, что одна и та же информация может быть интерпретирована различными способами, не приводя к логическим противоречиям или неверным результатам. Существование множества валидных моделей подчеркивает, что выбор конкретной модели для объяснения данных зависит от принятых предпосылок и приоритетов, а не от объективной истинности. В результате, анализ данных может приводить к различным, но одинаково обоснованным выводам, что необходимо учитывать при принятии решений на основе этих данных.
Показатель “Разнообразие” (Diversity) количественно оценивает явление, когда для одного и того же набора данных могут существовать множественные равноправные модели, каждая из которых предлагает собственное, правдоподобное объяснение. Наши результаты демонстрируют существенные различия в устойчивости этих объяснений к воздействию шума. В частности, анализ показал, что при увеличении уровня шума, различные методы генерации объяснений демонстрируют разную степень изменения выходных данных, что подтверждается статистически значимыми различиями (p-value < 0.001) между ними. Это указывает на то, что не все объяснения одинаково надежны в условиях неполной или зашумленной информации.
Понимание диапазона возможных объяснений, генерируемых моделью искусственного интеллекта, критически важно для формирования доверия к системе и обеспечения ее ответственного использования, особенно в чувствительных областях, таких как оценка кредитного риска. Отсутствие единого, однозначного объяснения не является недостатком, а скорее отражает сложность данных и необходимость учитывать различные факторы, влияющие на результат. В контексте кредитного скоринга, предоставление нескольких правдоподобных объяснений, например, комбинации факторов, приведших к определенной оценке, позволяет пользователям (как заемщикам, так и кредитным организациям) лучше понимать принятое решение и выявлять потенциальные ошибки или предвзятости. Это, в свою очередь, способствует повышению прозрачности и справедливости системы, а также снижает риски, связанные с неверной интерпретацией или преднамеренным манипулированием данными.
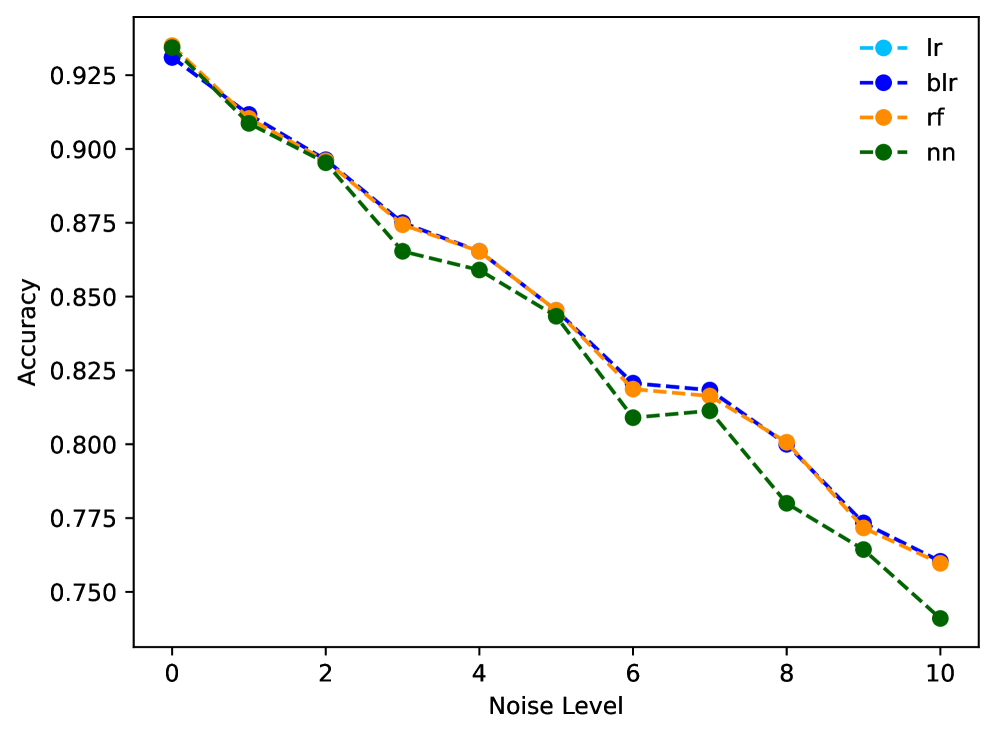
Правдоподобие Контрфактических Примеров: Измерение Близости к Реальности
Оценка “близости” контрфактических примеров к исходной точке данных критически важна для определения их правдоподобия и практической значимости. Чем ближе контрфактический пример к исходному, тем выше вероятность того, что предложенное изменение является реалистичным и осуществимым в контексте данных. Эта близость позволяет оценить, насколько незначительное изменение признаков может привести к изменению предсказания модели, и, следовательно, выявить наиболее информативные и полезные контрфактические объяснения. Отсутствие оценки близости может привести к генерации контрфактических примеров, которые, хотя и изменяют предсказание, не имеют практической ценности из-за своей нереалистичности или чрезмерной удаленности от исходных данных.
Для оценки расстояния между исходной точкой данных и контрфактическим примером, особенно при работе с категориальными признаками, эффективно использовать L_1-норму (манхэттенское расстояние). В отличие от евклидова расстояния, которое может быть неинформативным для категориальных данных, L_1-норма суммирует абсолютные разницы между значениями признаков, обеспечивая более надежную меру различия. Это особенно важно, поскольку евклидово расстояние предполагает упорядоченность категорий, что часто не соответствует действительности. Использование L_1-нормы позволяет избежать искажений, связанных с некорректным применением евклидова расстояния к категориальным данным, и обеспечивает более точную оценку близости контрфактических примеров.
Представление категориальных признаков в виде ‘Data Polytopes’ (политопов данных) позволяет оценивать близость контрфактических примеров, основываясь на геометрических свойствах. Вместо использования евклидова расстояния, которое не всегда применимо к категориальным данным, каждый экземпляр представляется как многомерный политоп, границы которого определяются значениями признаков. Близость между контрфактическим и исходным примером определяется как расстояние между соответствующими политопами, что позволяет более точно измерить изменение признаков и их влияние на результат модели. Этот подход особенно полезен при анализе данных высокой размерности и позволяет выявлять контрфактические примеры, которые наиболее правдоподобны и релевантны для практического применения, учитывая дискретный характер категориальных признаков.
Для повышения надежности оценки контрфактических примеров использовались синтетические данные. Анализ показал, что для некоторых методов полнота покрытия (CE completeness) устойчиво снижается ниже 10% при увеличении уровня шума в данных. Это указывает на нестабильность данных методов в условиях возмущений и необходимость разработки более робастных метрик для оценки правдоподобия контрфактических примеров, особенно при работе с зашумленными данными.
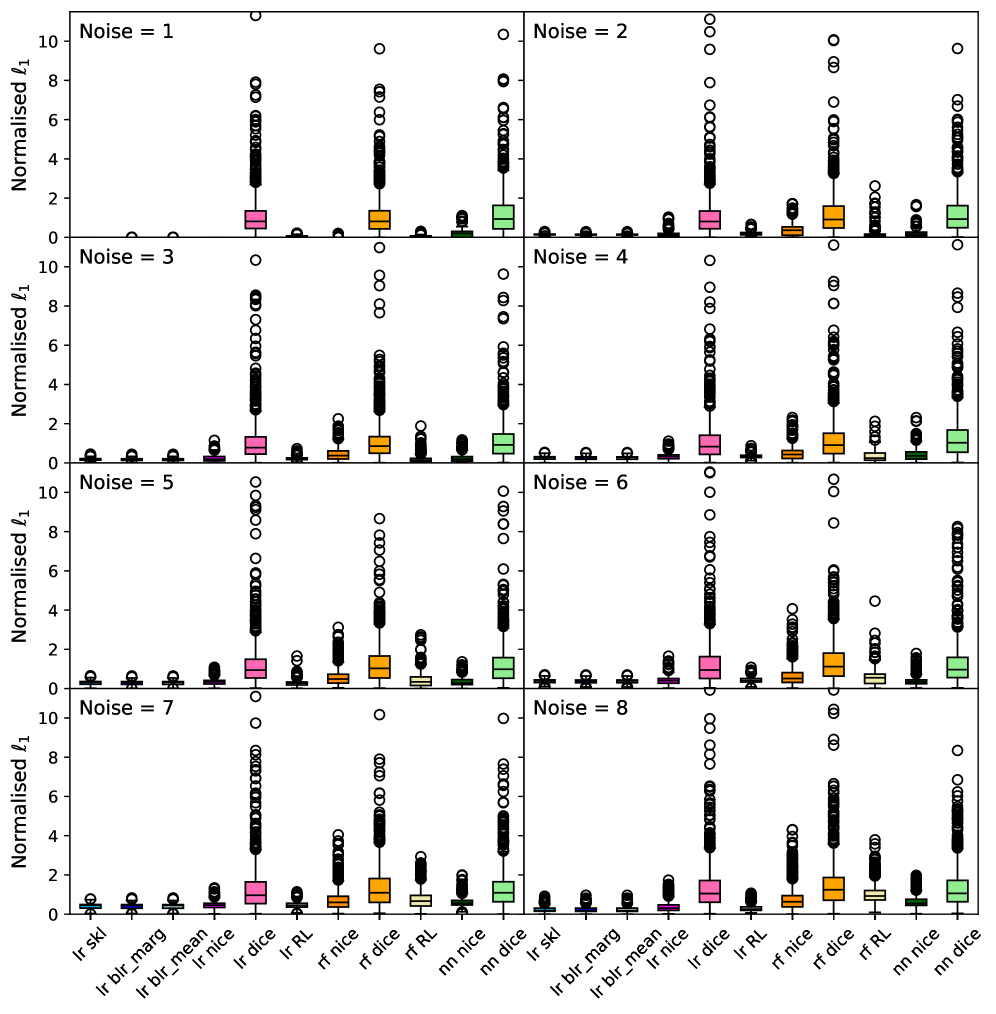
За Пределами Точности: К Надежному и Объяснимому ИИ
В настоящее время наблюдается переход от стремления к максимальной точности моделей искусственного интеллекта к пониманию и смягчению неопределенностей, которые неизбежно возникают в процессе их работы. Эта неопределенность подразделяется на два основных типа: алеаторическую и эпистемическую. Алеаторическая неопределенность обусловлена случайностью самих данных, то есть шумом или неполнотой информации, которую модель получает на вход. Эпистемическая же неопределенность связана с недостатком знаний у самой модели, то есть с тем, что она не располагает достаточными данными для уверенного прогнозирования. Понимание и учет обоих типов неопределенности является ключевым для создания надежных и заслуживающих доверия систем искусственного интеллекта, способных не только выдавать точные прогнозы, но и оценивать степень своей уверенности в этих прогнозах, а также предоставлять информацию о возможных альтернативных решениях.
Признание эффекта Расёмона, заключающегося в возможности множества равноправных интерпретаций одного и того же явления, приобретает ключевое значение в контексте искусственного интеллекта. Исследования показывают, что современные модели часто предлагают различные, но одинаково обоснованные объяснения своих решений, что требует от разработчиков не просто достижения высокой точности, но и количественной оценки разнообразия этих объяснений. Определение и измерение этой «разнородности» ответов позволяет повысить прозрачность работы систем ИИ, облегчая понимание процесса принятия решений и выявление потенциальных предвзятостей. Количественная оценка разнообразия объяснений является необходимым условием для построения подотчетных систем, способных обосновать свои выводы и обеспечить надежность в критически важных приложениях.
Приоритет правдоподобных контрфактических объяснений становится ключевым фактором в создании не только точных, но и устойчивых к возмущениям и заслуживающих доверия систем искусственного интеллекта. Исследования показывают, что способность модели объяснить, «что должно было произойти иначе», для заданного результата, существенно повышает ее надежность. Оценка правдоподобия контрфактов осуществляется с помощью метрик, таких как “близость” (Proximity) — отражающая минимальное изменение входных данных для получения альтернативного исхода — и норма ℓ_1 — измеряющая разреженность изменений. Эти показатели позволяют количественно оценить, насколько реалистично и правдоподобно предложенное моделью альтернативное объяснение, что, в свою очередь, способствует повышению прозрачности и возможности верификации принимаемых ею решений.
Проблема ложноположительных и ложноотрицательных результатов становится значительно сложнее при учете неопределенности модели и необходимости объяснения её решений. Исследование показало, что подходы к генерации контрафактических объяснений, основанные на близости к исходным данным, демонстрируют существенную нестабильность. Не существует единого метода, который бы стабильно обеспечивал наиболее надежные результаты, что подчеркивает важность разработки более устойчивых и интерпретируемых методов объяснения решений искусственного интеллекта. Поиск стабильных контрафактических объяснений требует учета не только близости к исходной точке в пространстве признаков, но и общей надежности модели в условиях неопределенности, что открывает новые направления для исследований в области доверенного и объяснимого ИИ.
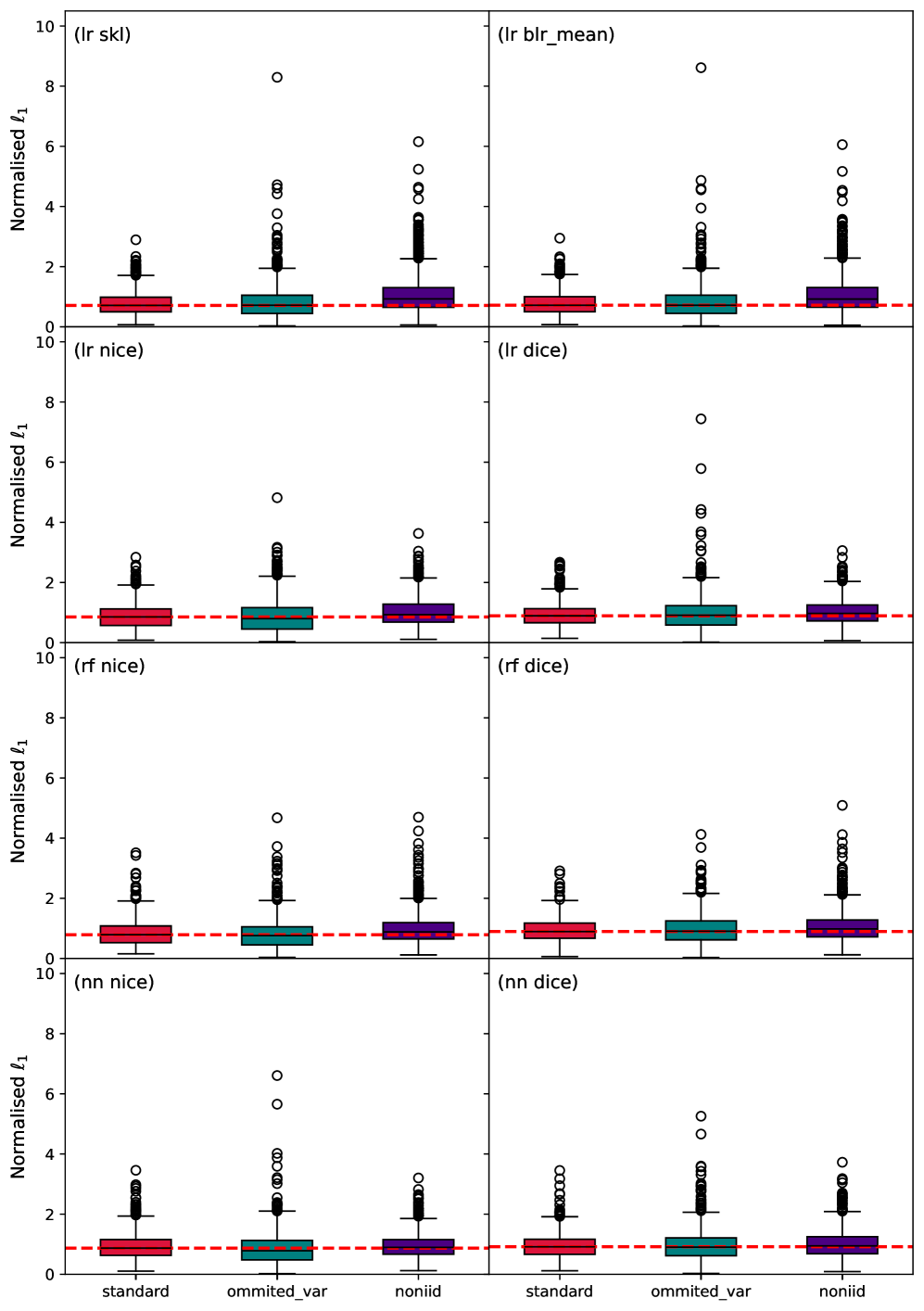
Исследование показывает, что надежность контрфактических объяснений (КЭ) напрямую зависит от неопределенности в моделях машинного обучения, будь то алеаторная или эпистемическая. Подобная взаимосвязь подчеркивает важность целостного подхода к проектированию систем искусственного интеллекта. Как заметил Анри Пуанкаре: «Не существует задач в физике, которые можно было бы решить, не зная математики». Эта фраза отражает суть представленной работы: понимание природы неопределенности в моделях (особенно в контексте сдвига данных) необходимо для создания надежных и интерпретируемых объяснений. Простота и ясность структуры модели, в конечном итоге, определяют надежность и предсказуемость ее поведения.
Куда Далее?
Представленное исследование, демонстрируя зависимость надёжности контрфактических объяснений от неопределённости в моделях машинного обучения, поднимает вопрос: что именно мы оптимизируем? Не просто точность предсказания, но и устойчивость самого объяснения к незначительным изменениям в данных или структуре модели. Очевидно, что универсального решения не существует, и наилучшая комбинация модели и метода генерации контрфактических объяснений зависит от конкретного контекста и целей анализа. Простота здесь — не минимализм, а чёткое разграничение необходимого и случайного в сложном ландшафте интерпретируемости.
Необходимо сместить фокус с поиска «идеального» алгоритма на разработку методов оценки и смягчения влияния неопределённости. Актуальным представляется исследование способов калибровки моделей, позволяющих более адекватно оценивать уверенность в своих предсказаниях и, соответственно, генерировать более надёжные объяснения. Особое внимание следует уделить влиянию смещения данных (data drift) на стабильность контрфактических объяснений, ведь модель, хорошо работающая сегодня, может дать совершенно иные объяснения завтра.
В конечном итоге, задача интерпретируемости машинного обучения — это не просто поиск ответов на вопросы «что?» и «почему?», но и оценка границ применимости этих ответов. Необходимо помнить, что любая модель — это упрощение реальности, а любое объяснение — лишь приближение к истине. И элегантность системы проявляется не в её сложности, а в её способности сохранять устойчивость и ясность даже в условиях неопределённости.
Оригинал статьи: https://arxiv.org/pdf/2602.00063.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-02-03 19:40