Автор: Денис Аветисян
Разработчики представили DeepSeek-V3.2 — открытую языковую модель, демонстрирующую впечатляющие результаты, сравнимые с закрытыми аналогами.

DeepSeek-V3.2 использует инновационные механизмы внимания, обучение с подкреплением и расширенную подготовку для решения сложных задач, требующих длительного контекста.
Несмотря на значительный прогресс в области больших языковых моделей, достижение сопоставимой производительности с закрытыми аналогами остаётся сложной задачей. В статье ‘DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models’ представлена новая открытая модель, DeepSeek-V3.2, которая демонстрирует конкурентоспособные результаты благодаря инновационным механизмам внимания, обучению с подкреплением и масштабному синтезу задач для агентов. Модель превосходит GPT-5 в некоторых областях и достигает уровня Gemini-3.0-Pro в решении сложных математических и информационных задач, включая олимпиады международного уровня. Возможно ли дальнейшее расширение возможностей открытых больших языковых моделей и их применение в решении ещё более сложных задач, требующих высокого уровня интеллекта и адаптивности?
Раскрытие Потенциала Разума: Преодоление Ограничений Традиционных Моделей
Несмотря на впечатляющие возможности, традиционные языковые модели часто демонстрируют затруднения при решении сложных задач, требующих последовательного и углубленного мышления. Они, как правило, хорошо справляются с распознаванием закономерностей и воспроизведением информации, но испытывают трудности в ситуациях, где необходимо выстраивать логические цепочки, делать выводы на основе неполных данных или учитывать множество взаимосвязанных факторов. Эта проблема проявляется в задачах, требующих планирования, креативного решения проблем или понимания контекста, выходящего за рамки непосредственно предоставленного текста. Вместо глубокого анализа и синтеза информации, модели часто полагаются на поверхностные корреляции, что приводит к ошибкам и нелогичным ответам при столкновении со сложными сценариями.
Несмотря на впечатляющий прогресс в области языковых моделей, простое увеличение их масштаба не является достаточным условием для достижения подлинного потенциала в решении сложных задач, требующих последовательного рассуждения. Исследования показывают, что дальнейшее наращивание параметров без изменения фундаментальной архитектуры приводит к закономерному снижению эффективности и увеличению вычислительных затрат. Поэтому ключевым направлением развития является переход к более экономичным и специализированным архитектурам, способным эффективно обрабатывать информацию и выполнять сложные логические операции с меньшими ресурсами. Такая смена парадигмы позволит создавать модели, которые не только демонстрируют впечатляющие результаты в отдельных задачах, но и способны к настоящему, гибкому и надежному рассуждению.
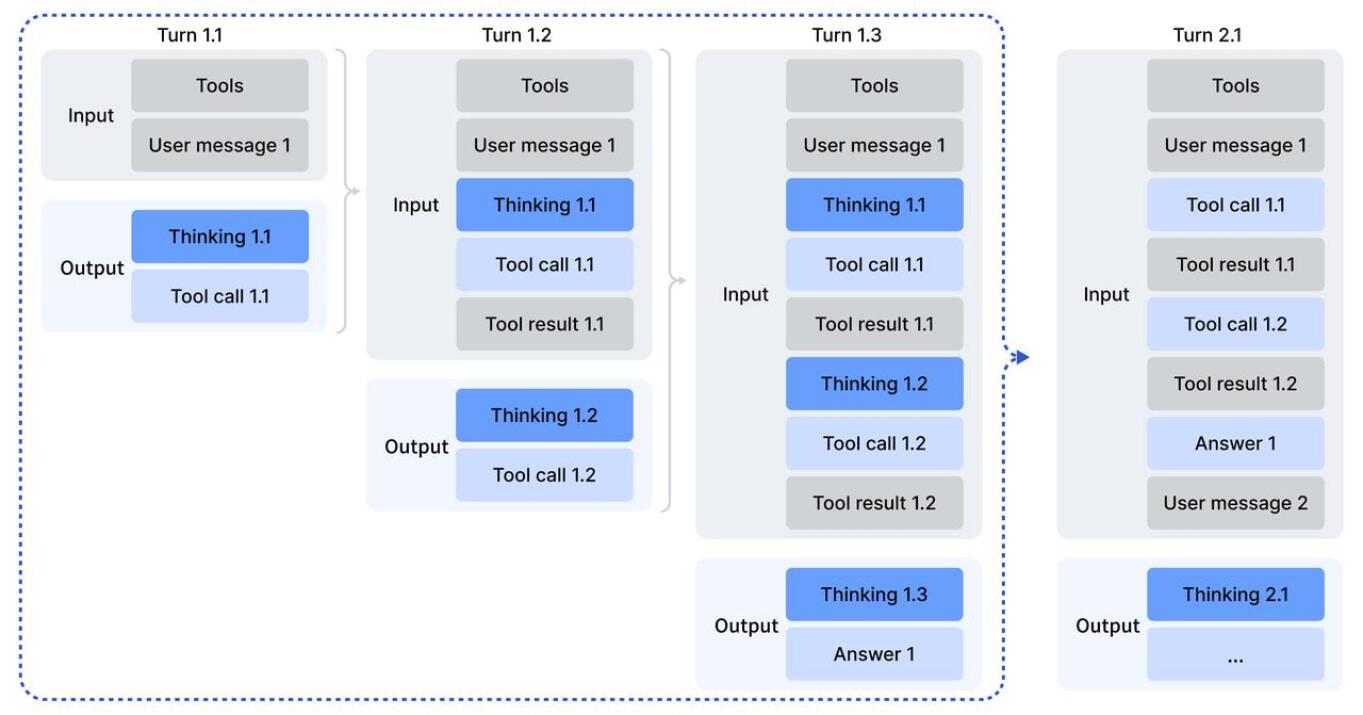
DeepSeek-V3.2: Архитектура для Продвинутого Разумного Анализа
Архитектура DeepSeek-V3.2 использует слой Mixture-of-Experts (MLA), представляющий собой механизм, при котором каждая операция обрабатывается одним или несколькими из множества «экспертных» подмоделей. Вместо использования одной большой модели, MLA позволяет распределить вычислительную нагрузку между несколькими небольшими, специализированными моделями. Это достигается путем использования «gate network», которая динамически направляет каждый входной токен к наиболее подходящим экспертам. Такая архитектура позволяет значительно повысить вычислительную эффективность и масштабируемость модели, поскольку активируются только необходимые эксперты для конкретного запроса, снижая общие затраты на вычисления и потребление памяти по сравнению с плотными моделями аналогичного размера. Количество экспертов и способ их взаимодействия являются ключевыми параметрами, влияющими на производительность и эффективность MLA.
Модель DeepSeek-V3.2 использует механизм DeepSeek Sparse Attention (DSA) для снижения вычислительной сложности обработки длинных последовательностей. DSA позволяет выборочно учитывать связи между элементами последовательности, отбрасывая несущественные для текущего контекста, что снижает потребность в памяти и вычислительных ресурсах. В отличие от традиционного Multi-Head Attention (MHA), требующего вычисления внимания между всеми парами токенов, DSA фокусируется на наиболее релевантных связях, сохраняя при этом производительность и точность модели при обработке длинных текстов. Эффективность DSA обусловлена применением разреженных матриц, снижающих количество операций при вычислении $Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V$, где $d_k$ — размерность ключей.
В архитектуре DeepSeek-V3.2 многоголовое внимание (MHA) и многозапросное внимание (MQA) интегрированы в структуру Mixture-of-Experts (MLA) для оптимизации процессов обучения и декодирования. MHA позволяет модели параллельно обрабатывать различные представления входных данных, улучшая способность к улавливанию сложных зависимостей. В свою очередь, MQA, используя общий набор ключей и значений для всех голов внимания, снижает вычислительные затраты во время декодирования, особенно при генерации длинных последовательностей, без существенной потери качества. Комбинация MHA и MQA внутри MLA позволяет добиться баланса между выразительностью модели и эффективностью вычислений, что критически важно для задач, требующих продвинутого рассуждения и обработки больших объемов данных.

Усиление Интеллекта: Обучение для Агентных Способностей
DeepSeek-V3.2 обучается с акцентом на развитие агентных способностей посредством использования автоматически сгенерированных синтетических задач (Synthetic Agentic Tasks). Этот подход предполагает создание большого набора разнообразных задач, имитирующих реальные сценарии взаимодействия агента с окружающей средой. Автоматическая генерация позволяет масштабировать процесс обучения, создавая задачи, охватывающие широкий спектр ситуаций и требующих различных стратегий решения. Данный метод позволяет модели освоить навыки планирования, принятия решений и выполнения сложных задач без непосредственного участия человека в создании обучающих данных.
Обучение с подкреплением (Reinforcement Learning, RL) в DeepSeek-V3.2 осуществлялось с выделенным бюджетом, превышающим 10% от стоимости предварительного обучения модели. Данный этап был направлен на совершенствование способности модели к принятию решений и формированию последовательных действий. Значительный финансовый ресурс позволил провести обширные эксперименты и оптимизировать алгоритмы RL для достижения более высокой эффективности в задачах, требующих планирования и адаптации к изменяющимся условиям. Использование RL позволило улучшить способность модели к решению сложных задач, требующих последовательности действий и долгосрочного планирования, а также к эффективному взаимодействию со средой.
Для эффективной обработки длинных контекстов в DeepSeek-V3.2 применяются методы управления контекстом, направленные на расширение лимита токенов. Эти методы включают в себя оптимизацию алгоритмов внимания и использование техник сжатия контекста без существенной потери информации. Расширенный лимит токенов позволяет модели учитывать значительно больший объем входных данных, что критически важно для решения сложных задач, требующих анализа обширного объема информации, таких как анализ документов, сложные рассуждения и взаимодействие с длинными диалогами. Реализация этих техник позволила увеличить эффективную длину контекста, обрабатываемого моделью, по сравнению с традиционными подходами.

Подтверждение Эффективности: Бенчмаркинг DeepSeek-V3.2
Модель DeepSeek-V3.2 демонстрирует сопоставимый уровень рассуждений с GPT-5, что знаменует собой существенный прогресс в области открытых больших языковых моделей. В задачах, требующих автономного планирования и выполнения действий — так называемых «агентских» задачах — разрыв в производительности между открытыми и закрытыми моделями значительно сократился. Это позволяет предположить, что DeepSeek-V3.2 представляет собой значительный шаг вперед в создании доступных и эффективных интеллектуальных систем, способных решать сложные задачи без необходимости полагаться на проприетарные технологии. Результаты показывают, что открытые модели могут достигать конкурентоспособных результатов в сложных сценариях, ранее доступных лишь в рамках закрытых экосистем.
Модель DeepSeek-V3.2 демонстрирует выдающиеся результаты в задачах, требующих поиска и анализа информации в сети. В частности, при использовании стратегии “Discard-all” в рамках теста BrowseComp, модель достигла точности в 67.6%. Это свидетельствует о её способности эффективно извлекать релевантные данные из различных источников, отфильтровывать ненужную информацию и предоставлять точные ответы на сложные вопросы, требующие доступа к актуальным знаниям из интернета. Данный показатель подтверждает потенциал модели для использования в задачах, связанных с автоматизированным поиском, анализом и обобщением информации, а также для создания интеллектуальных агентов, способных самостоятельно находить решения в информационном пространстве.
Модель DeepSeek-V3.2-Speciale продемонстрировала выдающиеся способности в решении сложных олимпиадных задач, завоевав золотые медали в престижных международных соревнованиях, таких как Международная олимпиада по информатике (IOI), финал Международного студенческого программистского конкурса (ICPC), Международная математическая олимпиада (IMO) и Канадская математическая олимпиада (CMO). Примечательно, что этот успех был достигнут без какой-либо специализированной подготовки или тонкой настройки модели под конкретные олимпиадные задачи, что подчеркивает её универсальные возможности в области рассуждений, логического мышления и решения проблем, а также её потенциал для применения в различных областях, требующих высокого уровня интеллектуальной деятельности.

Исследование, представленное в данной работе, демонстрирует стремление к созданию детерминированных и предсказуемых систем. Модель DeepSeek-V3.2, с ее акцентом на оптимизацию внимания и обучение на задачах, требующих последовательных действий, подчеркивает важность проверяемости алгоритмов. Как однажды заметил Пол Эрдеш: «Математика — это искусство открывать закономерности, которые скрыты от глаз». Данное утверждение находит отражение в работе над DeepSeek-V3.2, ведь целью является не просто достижение высокой производительности, но и обеспечение возможности точного анализа и воспроизведения результатов, что особенно важно при работе с большими языковыми моделями и задачами, требующими высокой степени надежности.
Куда Далее?
Без четкого определения критериев «интеллекта» любое улучшение производительности — лишь шум в информационном пространстве. Представленная работа демонстрирует техническую возможность создания открытой языковой модели, сопоставимой с закрытыми аналогами, но фундаментальный вопрос — что означает «понимание» — остается без ответа. Увеличение контекстного окна и совершенствование механизмов внимания — необходимые, но недостаточные условия для достижения истинного интеллекта.
Следующим этапом представляется не просто увеличение числа параметров, а разработка формальной логики, позволяющей верифицировать корректность рассуждений модели. Необходимо перейти от эмпирической оценки на тестовых примерах к доказательству алгоритмической состоятельности. Особенно остро стоит проблема обобщения: модель, хорошо работающая на заданном наборе задач, часто терпит неудачу при незначительном изменении условий.
Перспективы связаны с формализацией здравого смысла и разработкой алгоритмов, способных к дедуктивным рассуждениям. В конечном счете, ценность модели определяется не ее способностью имитировать человеческий язык, а способностью решать задачи, требующие логического мышления и доказательства корректности решения. Любое другое — иллюзия прогресса.
Оригинал статьи: https://arxiv.org/pdf/2512.02556.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
2025-12-03 17:42