Автор: Денис Аветисян
Исследователи предлагают эффективный метод обучения моделей на графах, распределенных между множеством устройств, с минимальным обменом данными.
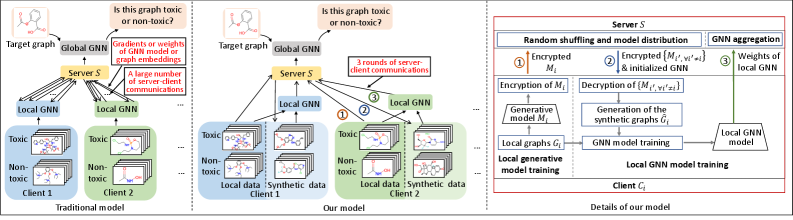
Представлен CeFGC и CeFGC*: федеративное обучение графовых нейронных сетей с использованием генеративных диффузионных моделей для повышения эффективности и конфиденциальности.
Обучение моделей графовых нейронных сетей в условиях децентрализованных данных сталкивается с проблемой высокой коммуникационной нагрузки и неоднородности данных между клиентами. В статье ‘Communication-efficient Federated Graph Classification via Generative Diffusion Modeling’ предложен новый подход CeFGC, снижающий число раундов обмена данными между сервером и клиентами до трех за счет использования генеративных диффузионных моделей. Ключевая идея заключается в генерации синтетических графов на основе локальных распределений данных, что позволяет обогатить обучающую выборку и улучшить обобщающую способность модели. Сможет ли предложенный метод стать основой для создания более эффективных и конфиденциальных систем анализа графовых данных в различных областях?
Задачи децентрализованного графового обучения: неизбежные компромиссы
Традиционные графовые нейронные сети (GNN) демонстрируют высокую эффективность при работе с централизованными данными, однако их применение в децентрализованных средах сопряжено с существенными трудностями. Основной проблемой является необходимость обмена информацией о графах между различными участниками, что влечет за собой значительные коммуникационные издержки и риски для конфиденциальности данных. Каждый узел графа может содержать чувствительную информацию, и передача полных структур графов или даже их частей может нарушить принципы защиты персональных данных. Кроме того, обмен большими объемами данных требует значительных вычислительных ресурсов и пропускной способности сети, что делает обучение GNN в децентрализованных условиях непрактичным или невозможным. Поэтому, разработка методов, позволяющих эффективно обучать GNN на децентрализованных данных, сохраняя при этом конфиденциальность и минимизируя коммуникационные затраты, является важной задачей современной науки о данных.
В современном мире данные, представленные в виде графов, всё чаще распределены между множеством независимых участников — от социальных сетей и финансовых учреждений до систем здравоохранения и логистики. Такая децентрализация создает существенные препятствия для совместного обучения моделей машинного обучения. Проблема заключается не только в необходимости обмена данными, который сопряжен с вопросами конфиденциальности и безопасности, но и в том, что стандартные алгоритмы, разработанные для централизованных графов, плохо масштабируются и неэффективны в условиях распределенных вычислений. Каждый участник владеет лишь частью общей картины, и объединение этих фрагментированных знаний для построения глобальной модели требует разработки принципиально новых подходов к обучению, учитывающих особенности распределенной структуры данных и ограниченные возможности коммуникации между участниками.
Стандартные подходы федеративного обучения, эффективно работающие с независимыми и одинаково распределёнными данными, сталкиваются с серьёзными трудностями применительно к сложным графовым структурам. Дело в том, что графы характеризуются взаимосвязанностью данных, и простое усреднение моделей, обученных на локальных графах, не позволяет эффективно использовать информацию о соседях и глобальной структуре сети. Традиционные методы не учитывают специфику графовых данных, что приводит к снижению точности и медленной сходимости. В связи с этим, для решения задачи децентрализованного обучения на графах необходимы инновационные решения, учитывающие особенности графовой структуры, такие как использование графовых сверток в рамках федеративного обучения, разработка новых алгоритмов агрегации моделей, учитывающих топологию графа, и применение методов дифференциальной приватности для защиты конфиденциальности данных на каждом клиенте.
Преодоление трудностей децентрализованного обучения на графах имеет решающее значение для раскрытия потенциала анализа распределенных графовых данных. В настоящее время значительная часть ценной информации заключена в графовых структурах, разбросанных по различным узлам и организациям, что делает централизованный подход непрактичным и нежелательным из-за проблем конфиденциальности и коммуникационных издержек. Успешная разработка эффективных и безопасных методов децентрализованного обучения позволит использовать эти ранее недоступные данные, открывая новые возможности в различных областях, от социальных сетей и рекомендательных систем до обнаружения мошенничества и разработки лекарств. Более того, возможность анализа данных непосредственно на местах, без необходимости их централизации, способствует повышению конфиденциальности пользователей и соблюдению нормативных требований, что является ключевым фактором для широкого внедрения технологий машинного обучения на графах в реальном мире.
CeFGC: генеративный подход к федеративному обучению
CeFGC представляет собой новую структуру федеративного обучения, использующую генеративные диффузионные модели (Generative Diffusion Models) для снижения затрат на коммуникацию и повышения производительности на не-IID (неоднородных) данных. В отличие от традиционных подходов, где клиенты обмениваются сырыми данными графов, CeFGC позволяет клиентам обмениваться обновлениями моделей, основанными на выученном общем распределении данных. Это значительно уменьшает объем передаваемой информации и, как следствие, коммуникационные издержки.
В рамках CeFGC, обучение общей модели распределения данных позволяет клиентам обмениваться лишь обновлениями модели, а не исходными данными графа. Это значительно снижает коммуникационную нагрузку, обеспечивая сокращение объема передаваемой информации в 33-102 раза по сравнению с базовыми методами федеративного обучения. Вместо передачи полных графовых структур, клиенты обмениваются компактными обновлениями параметров модели, что особенно критично в сценариях с ограниченной пропускной способностью сети и большим объемом данных.
В основе CeFGC лежит принцип итеративного уточнения, позволяющий клиентам совместно улучшать глобальную модель без раскрытия локальных данных. Каждый клиент локально обучает модель на своих данных, после чего обменивается только параметрами модели, а не самими данными. Эти обновления агрегируются на сервере для формирования новой глобальной модели, которая затем возвращается клиентам для следующей итерации обучения. Повторение этого процесса позволяет постепенно улучшать общую производительность модели, сохраняя при этом конфиденциальность данных каждого участника, поскольку прямая передача данных отсутствует. Такой подход позволяет снизить коммуникационные издержки и обеспечить масштабируемость системы в условиях децентрализованных графовых сред.
В условиях децентрализованных графовых сред, CeFGC демонстрирует значительное сокращение количества раундов коммуникации по сравнению с базовыми методами федеративного обучения. Традиционные подходы зачастую требуют более 102 раундов для достижения сходимости, в то время как CeFGC эффективно решает задачу всего за 3 раунда. Это существенное уменьшение достигается за счет использования генеративных диффузионных моделей и обмена обновлениями моделей, а не исходными данными графа, что минимизирует коммуникационные издержки и повышает эффективность обучения в условиях неоднородного распределения данных между клиентами.
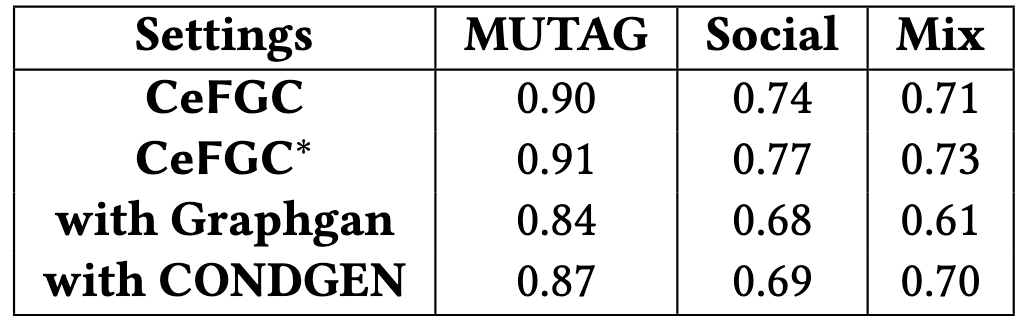
Экспериментальное подтверждение и прирост производительности
Для оценки производительности CeFGC были проведены эксперименты в трех различных настройках: на одном наборе данных, между наборами данных и между доменами. Использование различных наборов данных и доменов позволяет продемонстрировать универсальность предложенного подхода и его способность к обобщению. Эксперименты на одном наборе данных служат базовой линией для оценки производительности, в то время как эксперименты между наборами данных и доменами проверяют способность CeFGC адаптироваться к новым, ранее не встречавшимся данным и задачам. Такой подход к валидации обеспечивает всестороннюю оценку возможностей CeFGC в различных сценариях децентрализованного обучения на графах.
В ходе экспериментов CeFGC демонстрирует стабильное превосходство над базовыми методами по метрике AUC, даже при ограниченном количестве раундов коммуникации между участниками. В частности, на наборе данных IMDB-M зафиксировано улучшение до 23.1% по сравнению с существующими подходами. Данный результат свидетельствует о высокой эффективности CeFGC в задачах децентрализованного обучения на графах, позволяя достичь значительного прироста точности при ограниченных ресурсах на коммуникацию.
Для повышения устойчивости и обобщающей способности модели CeFGC используется аугментация обучающих данных посредством генерации синтетических графов. Этот подход позволяет расширить тренировочный набор, создавая искусственные графы, которые дополняют существующие данные и способствуют более эффективному обучению модели. Внедрение синтетических графов позволяет CeFGC лучше справляться с новыми, ранее не встречавшимися графами, и демонстрирует повышенную устойчивость к шуму и неполноте данных, что подтверждается результатами экспериментов на различных наборах данных.
Результаты экспериментов демонстрируют, что CeFGC является эффективным решением для децентрализованного обучения на графах. В частности, на наборе данных MUTAG, CeFGC достигает точности до 0.91, что подтверждает его высокую производительность и применимость в задачах, требующих распределенной обработки графовых данных. Данный показатель свидетельствует о способности CeFGC к эффективному обучению и обобщению в условиях децентрализованной архитектуры, что делает его перспективным инструментом для решения широкого спектра задач анализа графов.
CeFGC*: повышение производительности за счет интеграции меток
CeFGC* расширяет функциональность базового фреймворка CeFGC путем интеграции в генеративную диффузионную модель Графического Канала Метки (Graph Label Channel). Этот канал обеспечивает передачу информации о метках узлов и ребер графа непосредственно в процесс генерации данных. Внедрение данной структуры позволяет модели учитывать контекстную информацию, связанную с каждым элементом графа, что приводит к более точной и осмысленной генерации данных, особенно в случаях, когда структура графа является сложной и требует учета взаимосвязей между элементами. По сути, канал метки выступает в качестве дополнительного источника информации для диффузионной модели, направляя процесс генерации и обеспечивая соответствие с предопределенными метками.
Интеграция информации о метках в CeFGC* позволяет добиться значительного повышения производительности, особенно при работе со сложными графовыми структурами. В ситуациях, когда связи между узлами графа нелинейны и многогранны, использование метки каждого узла как дополнительного входного сигнала для генеративной диффузионной модели позволяет более точно моделировать распределение данных. Это приводит к улучшению качества сгенерированных графов и повышению точности выполнения задач, связанных с анализом и обработкой графовых данных, по сравнению со стандартными моделями CeFGC, не использующими информацию о метках.
Интеграция методов обучения с учетом меток (label-aware learning) с генеративными моделями, как продемонстрировано в CeFGC*, позволяет значительно повысить качество генерируемых данных и улучшить производительность модели. Применение информации о метках в процессе генерации позволяет модели более эффективно учитывать структуру и особенности данных, что особенно важно для сложных графовых структур. Данный подход позволяет преодолеть ограничения традиционных генеративных моделей, не учитывающих явную информацию о классах или категориях данных, и способствует созданию более точных и релевантных результатов. Повышение производительности достигается за счет более эффективного использования имеющихся данных и снижения неопределенности в процессе генерации.
CeFGC использует гомоморфное шифрование для повышения конфиденциальности данных в процессе обновления модели. Данная технология позволяет выполнять вычисления над зашифрованными данными, не прибегая к их расшифровке. Это обеспечивает сохранение конфиденциальности пользовательских данных, используемых для обучения и обновления модели, поскольку параметры модели обновляются на основе зашифрованных данных, что исключает возможность несанкционированного доступа к исходной информации. Внедрение гомоморфного шифрования в CeFGC соответствует растущим требованиям к защите данных и позволяет развертывать модель в средах, где конфиденциальность является критически важным фактором.
Исследование демонстрирует, что даже самые изящные теоретические конструкции, такие как генеративные диффузионные модели, рано или поздно сталкиваются с суровой реальностью распределенных данных и ограниченной пропускной способности. Авторы предлагают CeFGC и CeFGC*, стремясь обойти неизбежные проблемы не-IID данных, но это лишь отсрочка неизбежного. Как метко заметил Бертран Рассел: «Всякое большое достижение науки начинается с вопроса». В данном случае, вопрос о коммуникационной эффективности в федеративном обучении графовых нейронных сетей привел к интересному, хотя и временному, решению. В конечном счете, любой «революционный» подход станет просто еще одним элементом технического долга, который рано или поздно придется выплачивать.
Что дальше?
Предложенный подход, несомненно, демонстрирует снижение нагрузки на канал связи. Однако, если система стабильно падает под нагрузкой не-IID данных, значит, она хотя бы последовательна. Вопрос в том, сколько ещё слоёв абстракции потребуется, чтобы скрыть фундаментальную несовместимость локальных моделей. “Cloud-native” генеративные модели, обучающиеся на “федеративных” графах — звучит красиво, но по сути это всё те же самые графы, только дороже.
Наиболее вероятный сценарий развития — гонка вооружений между методами повышения эффективности и методами усложнения моделей. Вместо решения проблемы не-IID данных, будет предложено всё больше и больше “умных” алгоритмов агрегации, которые, вероятно, просто перенесут сложность в другой слой. И не забудем про приватность — каждое новое “улучшение” будет требовать ещё больше вычислительных ресурсов и, следовательно, ещё больше энергии.
В конечном итоге, это не научная работа, а просто комментарии для будущих археологов, пытающихся понять, зачем мы усложняли простые вещи. Похоже, что вместо создания действительно распределённого интеллекта, мы просто создаём сложную систему распределённых проблем. Будущие поколения, вероятно, найдут более элегантные решения, или просто откажутся от этой затеи.
Оригинал статьи: https://arxiv.org/pdf/2601.15722.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-25 23:36