Автор: Денис Аветисян
В статье представлена инновационная платформа, объединяющая семантический каталог и возможности больших языковых моделей для более эффективной и точной работы с графовыми данными.
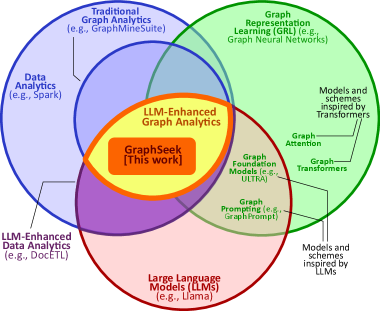
Представлен GraphSeek — фреймворк, сочетающий семантический каталог с не-LLM исполняемым планом для масштабируемого и эффективного LLM-усиленного графового анализа.
Несмотря на широкое распространение графов как фундаментальной структуры данных, их эффективное использование требует высокой квалификации. В данной работе, посвященной разработке системы ‘GraphSeek: Next-Generation Graph Analytics with LLMs’, предложен новый подход к анализу графов, сочетающий возможности больших языковых моделей (LLM) с семантическим каталогом и детерминированным выполнением запросов. Это позволяет значительно повысить точность и эффективность анализа сложных, динамически меняющихся графов, обеспечивая масштабируемость и доступность. Какие перспективы открывает интеграция LLM с традиционными системами управления базами данных для решения задач анализа графовых данных в различных областях?
Масштабируемость графового анализа: вызов, который нельзя игнорировать
Традиционные методы анализа графов часто сталкиваются с серьезными трудностями при работе с реальными наборами данных, характеризующимися огромным объемом и сложностью взаимосвязей. Это приводит к значительному замедлению скорости обработки запросов и, как следствие, к ограниченности получаемых результатов. Причины кроются в алгоритмической сложности многих операций над графами, которая экспоненциально возрастает с увеличением числа вершин и ребер. Например, поиск кратчайших путей или выявление сообществ в больших графах требует значительных вычислительных ресурсов и времени. В результате, анализ данных становится неэффективным, а возможность извлечения ценной информации — ограниченной, что препятствует принятию обоснованных решений на основе сетевых данных.
Существующие методы анализа графов зачастую требуют значительных затрат времени и ресурсов на предварительную обработку данных, что становится критичным препятствием при работе с постоянно меняющимися информационными потоками. Традиционные подходы, ориентированные на статические структуры, плохо приспособлены к динамическим графам, где узлы и связи регулярно добавляются, удаляются или модифицируются. Это приводит к необходимости повторной обработки данных и существенному снижению производительности. Кроме того, жесткая привязка к определенной схеме данных ограничивает возможности адаптации к новым типам связей или атрибутам, что затрудняет извлечение полезной информации из развивающихся графовых структур и снижает эффективность анализа в реальном времени.
Современные данные всё чаще представлены в виде взаимосвязанных графов, отражающих сложные отношения между объектами. Однако извлечение ценной информации из таких графов требует аналитических инструментов, способных эффективно масштабироваться для обработки огромных объемов данных. Необходимость в масштабируемом анализе графов обусловлена тем, что традиционные методы часто оказываются неспособными справиться с растущей сложностью и динамичностью реальных сетей. Адаптируемость к изменениям в структуре данных и возможность быстрого реагирования на новые запросы также критически важны. Интуитивно понятные инструменты, позволяющие пользователям легко исследовать и визуализировать графовые данные, открывают новые возможности для принятия решений в различных областях, от социальных сетей и финансовых рынков до биоинформатики и кибербезопасности. В конечном итоге, способность эффективно анализировать взаимосвязанные данные является ключевым фактором для получения конкурентных преимуществ и инноваций.
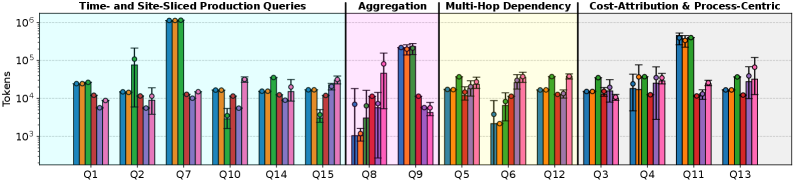
GraphSeek: объединение возможностей LLM и детерминированных графов
GraphSeek представляет собой новую структуру, в которой семантическое понимание запросов пользователя обрабатывается большими языковыми моделями (LLM), а детерминированное выполнение этих запросов — специализированным графовым движком. Такое разделение позволяет использовать сильные стороны обеих парадигм: гибкость LLM в интерпретации естественного языка и эффективность графовых движков в обработке структурированных данных. LLM отвечает за извлечение намерения из запроса, в то время как графовый движок гарантирует точное и предсказуемое выполнение операций над графом знаний, исключая неточности, характерные для исключительно LLM-ориентированных систем.
Разделение семантического понимания запроса и его детерминированного выполнения позволяет эффективно комбинировать сильные стороны больших языковых моделей (LLM) и графовых движков. LLM обеспечивают гибкую интерпретацию естественного языка, позволяя пользователям формулировать запросы в свободной форме. Графовые движки, в свою очередь, гарантируют эффективную и надежную обработку запросов на основе структурированных данных, представленных в виде графа. Такое разделение позволяет LLM сосредоточиться на понимании намерения пользователя, в то время как графовый движок отвечает за точное и быстрое извлечение и обработку данных, что повышает общую производительность и надежность системы.
Архитектура GraphSeek состоит из трех основных компонентов. LLM Agent отвечает за понимание запросов на естественном языке и преобразование их в промежуточное представление. Non-LLM Executor, используя движок графовых баз данных, выполняет детерминированное исполнение запросов, основываясь на этом представлении. Semantic Catalog служит мостом между языком и структурой графа, обеспечивая привязку лингвистических элементов к элементам схемы графа, что позволяет LLM Agent корректно интерпретировать запросы и генерировать валидные инструкции для Executor.
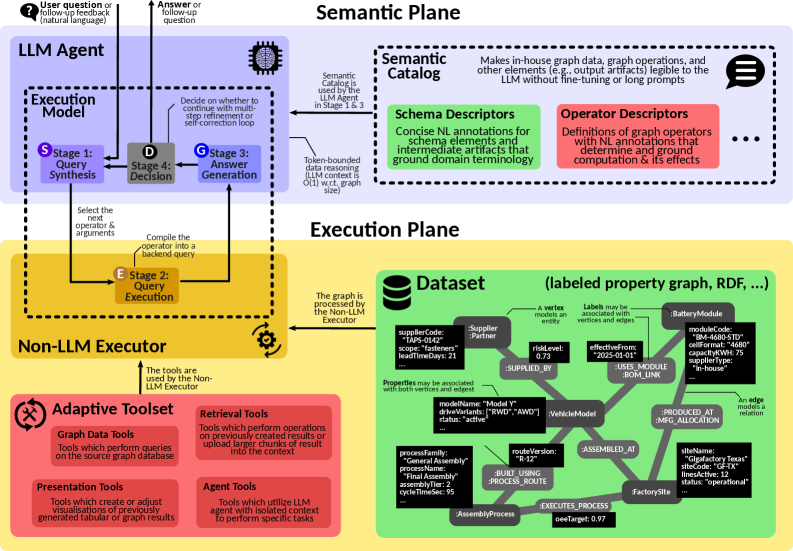
Масштабируемость и адаптивность: как GraphSeek обеспечивает эффективный анализ
Агент на основе большой языковой модели (LLM) использует методы обработки естественного языка (NLP) и привязку к схемам данных (Schema Grounding) для преобразования запросов, сформулированных на естественном языке, в исполняемые запросы к графовым базам данных. Процесс начинается с анализа запроса на естественном языке с использованием NLP для извлечения намерения пользователя и ключевых сущностей. Затем, механизм привязки к схемам данных сопоставляет эти сущности с элементами схемы графовой базы данных — узлами и ребрами — определяя, как запрос может быть представлен в виде графового запроса. Этот процесс обеспечивает точность и однозначность перевода, позволяя агенту эффективно извлекать и обрабатывать информацию из графовых данных, даже при неоднозначных или неполных запросах.
Не-LLM исполнитель в GraphSeek использует языки запросов к графам (например, Cypher, Gremlin) для детерминированной обработки запросов, преобразованных из естественного языка. В отличие от LLM, этот компонент обеспечивает предсказуемые и воспроизводимые результаты, обращаясь непосредственно к данным, хранящимся в графовых базах данных. Такой подход позволяет избежать непредсказуемости, свойственной генеративным моделям, и обеспечивает надежную и эффективную обработку запросов, что критически важно для аналитических задач, требующих точности и стабильности.
Адаптивный инструментарий и плоскость исполнения в GraphSeek обеспечивают динамические обновления и оптимизации в процессе инференса. Это достигается за счет способности системы изменять план выполнения запроса на основе промежуточных результатов и характеристик графовой базы данных. В частности, система может переключаться между различными стратегиями обхода графа, применять фильтры и предикаты для уменьшения объема обрабатываемых данных, а также использовать специализированные инструменты для выполнения конкретных операций. Такой подход позволяет значительно повысить производительность и эффективность обработки запросов, особенно в условиях меняющихся данных или сложных запросов, требующих адаптации стратегии выполнения.
В ходе тестирования система GraphSeek продемонстрировала 86%-ный уровень успешной обработки запросов, что значительно превосходит показатели улучшенной версии LangChain. При этом, медианное потребление токенов на один запрос составило 29.7 тысяч токенов, а медианная задержка обработки — 2-3 секунды при использовании специализированных инструментов. Данные показатели позволяют говорить о высокой эффективности и масштабируемости системы GraphSeek при решении задач аналитики.
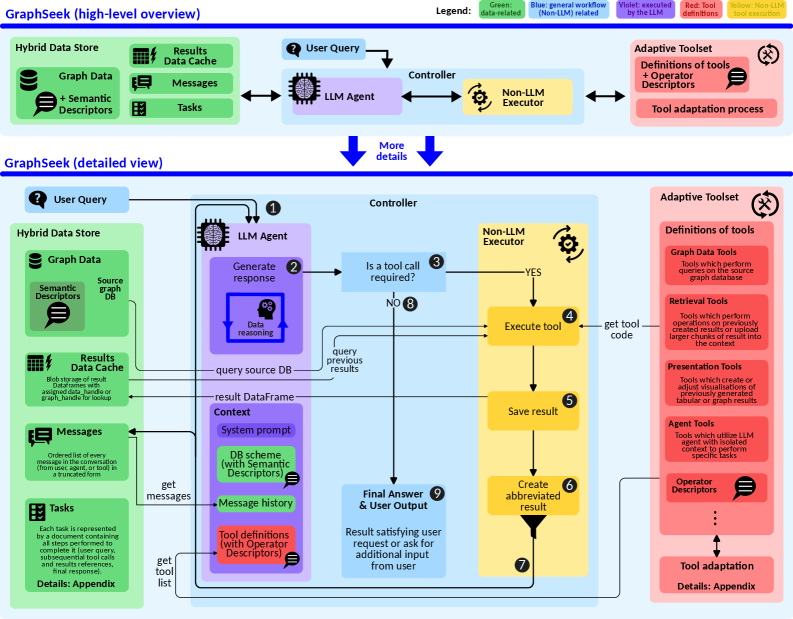
Промышленная ценность: от производства электромобилей и далее
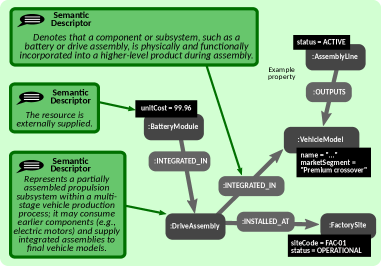
Возможности GraphSeek непосредственно направлены на решение задач в области промышленной аналитики графов, особенно актуальных для производства электромобилей. Сложность современных производственных процессов, включающих взаимодействие тысяч компонентов и операций, требует эффективных инструментов для анализа взаимосвязей. GraphSeek позволяет моделировать эти связи в виде графов свойств, что обеспечивает детальное понимание структуры и динамики производственной системы. Это, в свою очередь, позволяет оптимизировать цепочки поставок, выявлять узкие места и прогнозировать потенциальные сбои, что критически важно для повышения эффективности и снижения затрат в производстве электромобилей, где скорость и надежность играют ключевую роль.
В основе эффективного анализа промышленных данных лежит возможность моделирования сложных взаимосвязей между компонентами и производственными процессами. Использование графов свойств позволяет представить эти связи в виде узлов и ребер, где каждый узел представляет собой элемент системы, а ребра — отношения между ними. Такой подход обеспечивает гибкость и выразительность, позволяя детально описывать сложные производственные цепочки, зависимости между деталями и этапами сборки. В отличие от традиционных реляционных баз данных, графы свойств позволяют осуществлять быстрый и интуитивно понятный поиск и анализ информации, выявляя скрытые закономерности и оптимизируя производственные процессы. Это особенно важно в таких отраслях, как производство электромобилей, где взаимодействие большого количества компонентов требует детального понимания и эффективного управления.
В рамках данной разработки реализована возможность многошагового обхода графа, что позволяет получать информацию, недоступную при использовании традиционных методов анализа. Такой подход позволяет исследовать сложные взаимосвязи между компонентами и процессами, выявляя скрытые закономерности и зависимости, которые ранее оставались незамеченными. Например, можно проследить влияние дефекта конкретной детали на всю производственную линию, или определить оптимальную последовательность операций для повышения эффективности. Благодаря этому, аналитики получают возможность не просто констатировать факты, но и прогнозировать возможные проблемы и находить решения, оптимизируя производственные процессы и повышая качество продукции. Многошаговый обход графа значительно расширяет возможности анализа данных, открывая новые перспективы для повышения эффективности и конкурентоспособности в промышленности.
Исследования показали, что GraphSeek демонстрирует заметно более низкие затраты на обработку токенов по сравнению с базовыми решениями на основе LangChain при анализе графов, используя большие языковые модели. В ходе тестирования на наборе из тридцати различных запросов, GraphSeek обеспечил более эффективное использование ресурсов, что делает его привлекательным вариантом для компаний, стремящихся оптимизировать затраты на аналитику сложных промышленных данных. Такая экономия достигается за счет оптимизированной архитектуры и алгоритмов, позволяющих извлекать необходимую информацию из графовых структур с меньшими вычислительными издержками, что особенно важно при работе с крупномасштабными графами в производстве электромобилей и других отраслях.
Представленный подход GraphSeek, объединяющий семантический каталог и не-LLM исполнительный план, закономерно вызывает скепсис. Авторы стремятся повысить точность и эффективность анализа графов с помощью больших языковых моделей, но эта цель неизбежно столкнется с суровой реальностью эксплуатации. Как заметил Марвин Минский: «Лучший способ предсказать будущее — это создать его». Однако, в контексте разработки программного обеспечения, любое «созданное» будущее быстро обрастает техническим долгом. Данная работа, стремясь к масштабируемости LLM-улучшенного анализа графов, неминуемо станет очередным сложным компонентом, требующим поддержки и оптимизации. В конечном счете, элегантность архитектуры — лишь иллюзия, пока к ней не прикоснется продакшен.
Куда же это всё ведёт?
Представленный фреймворк GraphSeek, безусловно, элегантен в своей попытке примирить семантический каталог с не-LLM вычислительной базой. Однако, история учит: каждая «революция» в анализе данных неизбежно порождает новые уровни технического долга. Не стоит обольщаться: масштабируемость, достигнутая сегодня, завтра потребует ещё более изощрённых решений. Вопрос не в том, возможно ли это, а в том, сколько ресурсов будет потрачено на поддержание иллюзии управляемого хаоса.
Основная проблема остаётся нерешённой: как обеспечить достоверность знаний, извлекаемых из графов, особенно когда LLM выступает в роли интерпретатора? Багтрекер, в конечном итоге, лишь дневник боли, фиксирующий несоответствия между моделью и реальностью. Недостаточно просто «отпускать» запросы в графовую базу; необходимо понимать, что каждое новое знание — это потенциальный источник ошибок, который требует постоянной валидации.
Вместо погони за всеобщей моделью «разумного графа», вероятно, более продуктивным будет сосредоточиться на создании специализированных, доменно-ориентированных решений. Универсального лекарства не существует, и попытки его найти обречены на провал. В конечном счёте, важно помнить: у нас не DevOps-культура, у нас культ DevOops. И это, к сожалению, закономерность.
Оригинал статьи: https://arxiv.org/pdf/2602.11052.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-12 22:30