Автор: Денис Аветисян
Новая модель TrajGPT-R генерирует реалистичные и разнообразные траектории городского транспорта, опираясь на передовые методы машинного обучения.
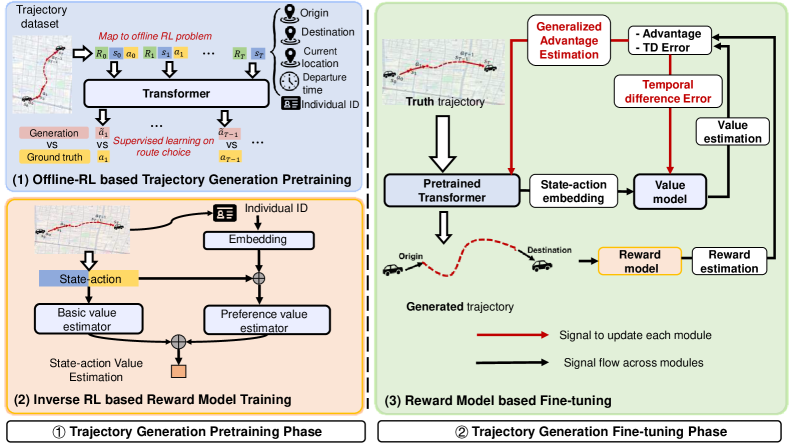
Исследователи представили фреймворк для генерации траекторий мобильности в городской среде, использующий архитектуру Transformer и обучение с подкреплением.
Несмотря на важность траекторий передвижений для понимания городской динамики, доступ к таким данным часто ограничен соображениями конфиденциальности. В данной работе представлен новый подход, ‘TrajGPT-R: Generating Urban Mobility Trajectory with Reinforcement Learning-Enhanced Generative Pre-trained Transformer’, использующий архитектуру Transformer, усиленную обучением с подкреплением и обратным обучением с подкреплением для генерации реалистичных и разнообразных траекторий передвижений в городской среде. Разработанная модель позволяет эффективно моделировать предпочтения пользователей и преодолевать сложности, связанные с разреженным вознаграждением в задачах генерации последовательностей. Не откроет ли это новые возможности для планирования городской инфраструктуры и оптимизации транспортных потоков?
Раскрытие Городского Потока: Вызов Реалистичного Моделирования
Понимание закономерностей городской мобильности на основе данных о траекториях движения — ключевой фактор развития концепции “умного города”, однако создание реалистичных моделей траекторий представляет собой сложную задачу. Данные о перемещениях граждан позволяют анализировать транспортные потоки, оптимизировать логистику и планировать развитие инфраструктуры, но точность этих анализов напрямую зависит от правдоподобия смоделированных траекторий. Существующие методы часто упрощают реальную картину, не учитывая индивидуальные особенности поведения людей, непредсказуемость дорожной обстановки и влияние различных факторов, таких как время суток или погодные условия. Поэтому разработка алгоритмов, способных генерировать траектории, максимально приближенные к реальным, является приоритетной задачей для исследователей и разработчиков в области градостроительства и транспортной инженерии.
Традиционные методы моделирования городских потоков часто оказываются неспособными в полной мере отразить сложность и разнообразие реальных траекторий движения. Существующие алгоритмы, как правило, упрощают поведение участников дорожного движения, игнорируя индивидуальные особенности, спонтанные решения и влияние внешних факторов, таких как пробки, погодные условия или дорожные работы. Это приводит к неточностям в симуляциях и прогнозах, ограничивая возможности применения этих моделей для эффективного планирования городской инфраструктуры, оптимизации транспортных потоков и повышения безопасности дорожного движения. В результате, даже самые совершенные модели, основанные на устаревших подходах, могут давать существенно отличающиеся от реальности результаты, что снижает их практическую ценность и требует разработки более адаптивных и реалистичных методов моделирования.

Трансформеры в Действии: Мощный Инструмент Генерации
Архитектура Transformer представляет собой эффективное решение для моделирования последовательных данных, таких как траектории движения. В основе ее работы лежит механизм самовнимания (self-attention), который позволяет модели оценивать взаимосвязь между различными элементами последовательности, не завися от их взаимного расположения. Этот подход позволяет учитывать долгосрочные зависимости в данных, что особенно важно для предсказания будущих состояний системы на основе прошлых наблюдений. В отличие от рекуррентных нейронных сетей (RNN), Transformer обрабатывает всю последовательность параллельно, что значительно ускоряет процесс обучения и позволяет эффективно использовать современные аппаратные средства, такие как графические процессоры (GPU).
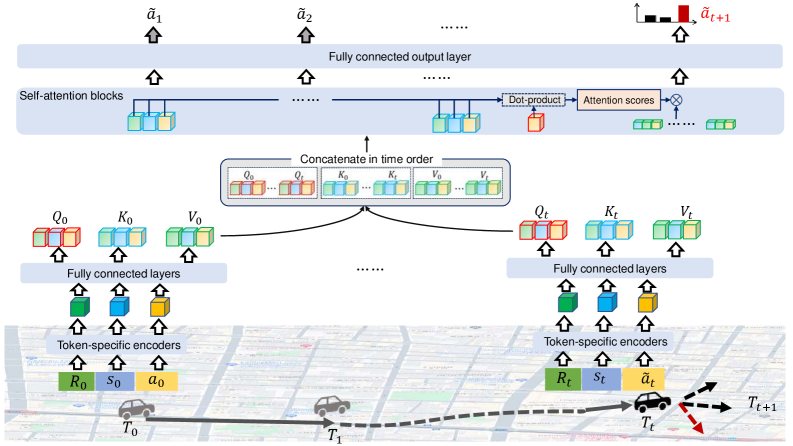
Модели, такие как BERT и Decision Transformer, используют архитектуру Transformer для генерации траекторий, рассматривая задачу как задачу последовательного моделирования. Вместо непосредственного предсказания координат, эти модели обучаются предсказывать будущие положения агента, основываясь на последовательности прошлых состояний и действий. По сути, они рассматривают траекторию как последовательность токенов, и используют механизм самовнимания (self-attention) для определения взаимосвязей между различными моментами времени в этой последовательности. Это позволяет моделям учитывать контекст прошлых движений при прогнозировании будущих, что значительно повышает точность и реалистичность генерируемых траекторий.
Для эффективной обработки траекторий движения моделями на основе архитектуры Transformer необходима их токенизация — представление в виде дискретных единиц. Данный процесс включает в себя три основных типа токенов: токен состояния (State Token), кодирующий текущее положение и характеристики агента; токен действия (Action Token), представляющий выполненное действие; и токен возврата к цели (Return-to-Go Token), указывающий оставшееся расстояние до заданной цели. Использование этих токенов позволяет Transformer-моделям воспринимать траекторию как последовательность дискретных событий, что необходимо для прогнозирования будущих позиций и планирования движения. Эффективность токенизации напрямую влияет на производительность модели в задачах генерации траекторий.
Проверка Реальности: Метрики и Наборы Данных
Оценка сгенерированных траекторий требует использования метрик, выходящих за рамки простой точности достижения конечной точки. Помимо базовых показателей, для оценки разнообразия и реалистичности применяются BLEU Score, Jaccard Similarity, Cosine Similarity, а также метрики энтропии униграмм и биграмм. BLEU Score измеряет степень совпадения сгенерированных траекторий с эталонными данными, Jaccard Similarity определяет степень перекрытия между сгенерированными и эталонными наборами точек, а Cosine Similarity оценивает угловое сходство между векторами, представляющими траектории. Метрики энтропии, в свою очередь, позволяют оценить разнообразие и непредсказуемость сгенерированных траекторий, что является важным показателем реалистичности.
Оценка сгенерированных траекторий проводится с использованием данных из различных источников, включая датасет Toyota, содержащий информацию о вождении автомобилей в реальных условиях, датасет T-Drive, охватывающий данные о такси в Пекине, и датасет Porto Taxi, предоставляющий данные о такси в Порту. Использование этих разнородных источников позволяет провести всестороннюю оценку реалистичности и разнообразия сгенерированных траекторий, учитывая различные стили вождения, городские условия и плотность дорожного движения. Комбинация данных из разных городов и типов транспортных средств обеспечивает более надежную и обобщенную оценку производительности алгоритмов генерации траекторий.
Последние достижения в области генерации траекторий, в частности модель TrajGPT-R, демонстрируют следующие результаты при оценке на наборе данных Toyota Dataset: индекс Жаккара (Jaccard Similarity) составляет 0.524, косинусное сходство (Cosine Similarity) — 0.575, а оценка BLEU — 0.383. Кроме того, модель показывает высокую производительность в метриках энтропии, достигая значения энтропии униграмм (Unigram Entropy) равного 14.85 и энтропии биграмм (Bigram Entropy) — 14.82, что свидетельствует о разнообразии и реалистичности генерируемых траекторий.
Повышение качества генерируемых траекторий достигается за счет использования модели вознаграждения (Reward Modeling) и сигнала вознаграждения, рассчитанного для всей траектории (Trajectory-wise Reward). В данном подходе, модель вознаграждения оценивает сгенерированную траекторию как единое целое, а не отдельные точки, что позволяет учитывать глобальные характеристики, такие как плавность, реалистичность и соответствие дорожной сети. Сигнал вознаграждения, полученный от модели, используется для корректировки процесса генерации, направляя его к созданию более качественных и правдоподобных траекторий. Это позволяет оптимизировать генеративный процесс, фокусируясь на общих характеристиках траектории, а не только на локальной точности.
За Пределами Диффузии: К Эффективной Генерации Траекторий
Диффузионные модели, несмотря на свою впечатляющую способность генерировать реалистичные траектории, сталкиваются с существенными вычислительными трудностями при масштабировании. Этот недостаток обусловлен итеративным процессом, требующим множества шагов для создания каждой траектории, что значительно увеличивает время и ресурсы, необходимые для обработки больших объемов данных или симуляций. В результате, применение диффузионных моделей в задачах, требующих генерации огромного количества траекторий, таких как моделирование транспортных потоков в масштабе города или разработка систем автономного вождения, может оказаться непрактичным из-за непомерных затрат и времени ожидания. Поэтому поиск альтернативных подходов, способных сохранить высокую точность генерации, но при этом снизить вычислительную сложность, является актуальной задачей в области моделирования траекторий.
Исследователи активно используют возможности трансформаторных моделей для создания реалистичных и эффективных симуляций траекторий движения. В отличие от традиционных методов, требующих больших вычислительных затрат, трансформаторы позволяют моделировать сложные зависимости в данных и генерировать правдоподобные сценарии. Для обеспечения достоверности результатов, особое внимание уделяется тщательной оценке сгенерированных траекторий с помощью разнообразных метрик и на различных наборах данных. Такой подход позволяет не только повысить точность симуляций, но и значительно ускорить процесс генерации траекторий, открывая новые возможности для применения в областях, таких как управление транспортными потоками, городское планирование и разработка автономных транспортных средств.
Усовершенствованные модели траекторий открывают широкие перспективы для оптимизации транспортных потоков и повышения эффективности городского планирования. Возможность реалистично симулировать поведение участников дорожного движения позволяет разрабатывать интеллектуальные системы управления трафиком, снижая заторы и повышая безопасность на дорогах. Кроме того, точное моделирование пешеходных и транспортных потоков становится незаменимым инструментом при проектировании новых городских пространств и оценке влияния инфраструктурных изменений. В контексте развития автономного транспорта, усовершенствованные модели траекторий необходимы для создания надежных и безопасных систем навигации, способных предсказывать поведение других участников дорожного движения и принимать обоснованные решения в сложных ситуациях. Таким образом, данное направление исследований способствует не только улучшению транспортной инфраструктуры, но и созданию более умных и устойчивых городов будущего.
Исследование TrajGPT-R демонстрирует стремление к пониманию и воспроизведению сложных систем — в данном случае, паттернов городского движения. Как отмечал Марвин Минский: «Лучший способ понять — это создать». Создавая модель, способную генерировать правдоподобные траектории, авторы не просто имитируют реальность, но и раскрывают её внутреннюю логику. Использование обратного обучения с подкреплением для моделирования вознаграждений позволяет системе не просто предсказывать действия, но и понимать мотивацию, стоящую за ними, что соответствует стремлению к реверс-инжинирингу реальности. Эта работа, подобно эксплойту, начинается с вопроса: как работает эта система, и как её можно заставить действовать иначе?
Куда Ведет Дорога?
Представленный подход, TrajGPT-R, безусловно, демонстрирует возможности генерации траекторий городского движения, но следует помнить: любая модель — это лишь упрощение реальности, своего рода «тень пещеры». Вопрос не в том, насколько правдоподобно машина имитирует поведение, а в том, какие закономерности остаются невыявленными, какие «баги» в системе координат городского пространства она упускает из виду. Успешное применение обратного обучения с подкреплением подразумевает наличие четко определенной функции вознаграждения, однако, действительно ли эта функция отражает все нюансы принятия решений человеком — или же мы лишь кодифицируем собственные предубеждения, создавая самоисполняющееся пророчество?
Дальнейшее развитие неизбежно связано с преодолением ограничений, связанных с масштабируемостью и обобщением. Модель, обученная на данных одного города, может оказаться бесполезной в другой среде. Истинный вызов — не в создании все более совершенных генераторов траекторий, а в разработке систем, способных адаптироваться к непредсказуемости городского ландшафта, к спонтанным изменениям в поведении участников движения. Попытки включить в модель понятия «креативности» или «интуиции» могут оказаться плодотворными, но и сопряжены с риском создания алгоритмов, которые воспроизводят непредсказуемость, но не понимание.
В конечном счете, исследование TrajGPT-R — это не просто инженерная задача, а попытка понять, как работает город, как функционирует его невидимая логика. И в этом смысле, каждый «баг» в модели — это не ошибка, а признание в собственной неполноте, приглашение к дальнейшему исследованию, к взлому системы изнутри.
Оригинал статьи: https://arxiv.org/pdf/2602.20643.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-02-26 01:14