Автор: Денис Аветисян
В статье рассматриваются новые методы машинного обучения для разработки механизмов коллективного принятия решений и обеспечения их соответствия предпочтениям людей.
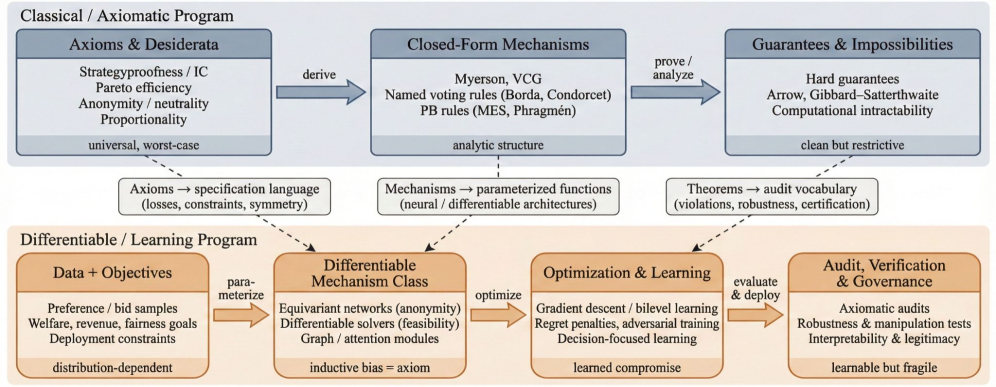
Обзор современных подходов в области дифференцируемого социального выбора, включая проектирование механизмов, обратное обучение с подкреплением и проблемы манипулирования.
Несмотря на кажущуюся абстрактность теории общественного выбора, она все чаще становится основой современных систем машинного обучения. В работе «Методы и открытые проблемы в дифференцируемом социальном выборе: обучение механизмов, принятие решений и выравнивание» представлен обзор новой парадигмы, формулирующей правила голосования и процедуры агрегирования предпочтений как обучаемые, дифференцируемые модели. Авторы синтезируют достижения в области аукционов, голосования, бюджетного планирования и обратного обучения механизмам, выявляя, как классические аксиомы и невозможности проявляются в качестве целей, ограничений и компромиссов при оптимизации. Какие перспективы открывает дифференцируемый социальный выбор для создания более справедливых и эффективных алгоритмов коллективного принятия решений в эпоху больших данных?
От аксиом к алгоритмам: Пределы традиционного дизайна механизмов
Классический механизм дизайна, лежащий в основе многих экономических моделей и систем стимулирования, опирается на строгие предположения о рациональности участников и полноте информации. Однако, в реальных сложных системах, эти предположения часто не соответствуют действительности. Предполагается, что каждый участник всегда стремится максимизировать собственную выгоду, действуя логично и последовательно, а также честно раскрывает свою частную информацию. В действительности, люди подвержены когнитивным искажениям, эмоциональным факторам и могут действовать иррационально. Кроме того, информация редко бывает полной и доступной всем участникам, что приводит к асимметрии информации и неэффективности механизмов. Игнорирование этих факторов в классическом дизайне механизмов может приводить к непредсказуемым последствиям и снижению эффективности системы в целом, особенно в динамичных и непредсказуемых средах.
Традиционные подходы к разработке механизмов, основанные на строгих аксиомах, зачастую сталкиваются с существенными трудностями при масштабировании и адаптации к меняющимся условиям. Изначально разработанные для упрощенных моделей, эти методы демонстрируют ограниченную эффективность в сложных, динамичных системах реального мира. Проблема заключается в том, что жестко заданные правила и предположения о рациональности участников могут оказаться недействительными при увеличении числа взаимодействующих агентов или при изменении внешних факторов. Попытки учесть все возможные сценарии приводят к экспоненциальному росту сложности алгоритмов, делая их непрактичными для использования в больших масштабах. В результате, возникает потребность в более гибких подходах, способных обучаться на данных и адаптироваться к новым условиям без необходимости пересмотра базовых принципов.
В настоящее время все большее значение приобретают гибкие, основанные на данных подходы к проектированию механизмов, что знаменует собой переход от жестко заданных правил к изучаемым стимулам. Традиционные методы, опирающиеся на строгие предположения о рациональности агентов, часто оказываются неэффективными в условиях динамически меняющихся систем. Вместо этого, современные исследования направлены на разработку алгоритмов, способных адаптироваться к поведению участников и оптимизировать результаты на основе анализа больших объемов данных. Такой подход позволяет создавать механизмы, которые не только более устойчивы к нерациональному поведению, но и способны обучаться и совершенствоваться со временем, обеспечивая более эффективное и справедливое распределение ресурсов и стимулов в сложных системах.
Дифференцируемые механизмы: Новый подход к инженерии стимулов
Дифференцируемый социальный выбор и смежные методы позволяют оптимизировать механизмы с использованием градиентного спуска, рассматривая функцию потерь как явное правило агрегирования. В традиционном дизайне механизмов, определение оптимального механизма требует анализа стратегий участников и вычисления равновесий. Однако, дифференцируемый подход позволяет рассматривать функцию потерь, отражающую желаемые свойства механизма (например, максимизацию социальной полезности или минимизацию несправедливости), как непосредственно оптимизируемый параметр. Это достигается за счет дифференцирования функции потерь по параметрам механизма, что позволяет вычислять градиент и использовать его для итеративного улучшения механизма с помощью алгоритмов оптимизации, таких как стохастический градиентный спуск. Фактически, механизм проектируется как нейронная сеть, где входные данные — это предпочтения агентов, а выходные данные — аллокация ресурсов или распределение выигрышей. \nabla_{\theta} L(D, \theta) представляет собой градиент функции потерь L по параметрам механизма θ при заданном наборе данных предпочтений D .
Представление разработки механизмов как задачи оптимизации позволяет использовать современные алгоритмы машинного обучения для поиска оптимальных правил принятия решений. Вместо традиционного аналитического подхода, требующего строгих предположений о рациональности участников и их функциях полезности, дифференцируемые механизмы позволяют напрямую оптимизировать целевую функцию, определяющую желаемые свойства механизма, например, максимизацию социальной полезности или минимизацию манипуляций. Этот подход особенно эффективен при работе с большими объемами данных о поведении участников, позволяя алгоритмам самостоятельно находить оптимальные параметры механизма, не требуя явного указания всех возможных сценариев и стратегий. Использование градиентного спуска и других методов оптимизации позволяет итеративно улучшать механизм, пока не будет достигнут удовлетворительный результат. \nabla L(\theta) — градиент функции потерь, используемый для обновления параметров θ механизма.
Подход дифференцируемого проектирования механизмов позволяет включать априорные знания (индуктивные смещения) в процесс оптимизации. Это достигается путем явного задания предпочтений или ограничений в целевой функции, что направляет алгоритм обучения к более желаемым решениям. Кроме того, данный подход обеспечивает возможность обучения на сложных поведенческих данных, получаемых из реальных взаимодействий агентов. Анализ этих данных позволяет выявлять закономерности и адаптировать механизм к конкретным условиям, повышая его эффективность и устойчивость к манипуляциям. Использование данных позволяет учитывать гетерогенность предпочтений и стратегий агентов, что недоступно в традиционных методах проектирования механизмов.
Обучение на данных: Методы для надежных и адаптивных механизмов
Обратное обучение механизмам (Inverse Mechanism Learning, IML) позволяет выводить скрытые стимулы и предпочтения участников на основе наблюдаемого поведения, что обеспечивает итеративное улучшение дизайна механизмов. В контексте дифференцируемого IML доказана идентифицируемость разницы в выигрышах (payoff differences) при использовании условных логит-моделей отклика (conditional logit response models). Это означает, что при определенных условиях возможно однозначно определить, как изменения в стимулах влияют на выбор агентов, что необходимо для точной оценки их предпочтений и последующей оптимизации механизма.
Дифференциальная экономика и нейронный социальный выбор предоставляют мощные инструменты для моделирования и оптимизации сложных экономических взаимодействий. Данные подходы позволяют представлять экономические модели в виде дифференцируемых функций, что обеспечивает возможность применения методов градиентного спуска для оптимизации параметров механизмов и достижения желаемых результатов. Нейронные сети, в частности, используются для аппроксимации функций социального выбора, позволяя моделировать сложные предпочтения и находить оптимальные решения в задачах, где традиционные методы оказываются неэффективными. Это открывает возможности для разработки более гибких и адаптивных механизмов, способных эффективно функционировать в динамичных и неопределенных средах, например, в задачах распределения ресурсов или определения цен.
Федеративное обучение позволяет обучать механизмы на децентрализованных данных, обеспечивая конфиденциальность и способствуя сотрудничеству между участниками без необходимости централизованного сбора данных. Статистическая согласованность алгоритмов дифференцируемого обратного обучения механизмов (DIML) в рамках федеративного обучения подтверждена при соблюдении определенных условий регулярности, касающихся распределения данных и свойств обучаемых моделей. Эти условия включают в себя, например, ограниченность функций потерь и достаточное количество данных у каждого участника, что гарантирует сходимость алгоритма к оптимальному решению, не раскрывая при этом индивидуальную информацию о данных.
Применение и будущие направления: Демократизация стимулов и согласование ИИ
Методы, разработанные в области проектирования механизмов, находят все большее применение в сферах, касающихся участия граждан в принятии решений. В частности, их использование в системах партиципаторного бюджетирования и жидкой демократии позволяет значительно расширить возможности для инклюзивного и эффективного управления. Эти подходы позволяют учитывать предпочтения большего числа заинтересованных сторон, оптимизировать распределение ресурсов и повысить прозрачность процесса принятия решений. Благодаря автоматизации и анализу данных, становится возможным более точно определить общественные потребности и разработать решения, которые наилучшим образом соответствуют интересам всех участников. Подобные инструменты способствуют укреплению доверия к органам власти и повышению гражданской активности, создавая более демократичное и ответственное общество.
Разработка механизмов стимулирования на основе естественного языка открывает новые возможности для управления сложными взаимодействиями, выходя за рамки традиционных экономических моделей. Вместо использования числовых показателей или формальных контрактов, эта область исследований позволяет формировать стимулы посредством языка — вопросов, ответов, предложений и даже аргументов. Это особенно важно в ситуациях, где сложно точно измерить вклад каждого участника или определить оптимальные условия сотрудничества, например, в онлайн-сообществах, при совместном написании текстов или в процессе принятия решений, основанном на экспертных оценках. Использование лингвистических инструментов и методов машинного обучения позволяет создавать системы, способные адаптироваться к нюансам человеческого общения и эффективно мотивировать людей к достижению общих целей, что значительно расширяет сферу применения теории игр и механизмов стимулирования.
Конституционный искусственный интеллект представляет собой перспективный подход к решению сложной проблемы согласования — обеспечению соответствия целей и поведения ИИ-систем человеческим ценностям и намерениям. Данная методика использует принципы проектирования механизмов, чтобы обучать ИИ посредством самокритики и самосовершенствования, основанных на заданном наборе конституционных принципов. Вместо прямого программирования желаемого поведения, система обучается оценивать свои собственные ответы и корректировать их в соответствии с этими принципами, что позволяет ей адаптироваться к новым ситуациям и демонстрировать более безопасное и этичное поведение. Такой подход, в отличие от традиционных методов обучения с подкреплением, позволяет создавать ИИ, который не просто выполняет поставленные задачи, но и стремится к соответствию более широким моральным нормам, что особенно важно для систем, взаимодействующих с людьми в сложных социальных контекстах.
За пределами оптимизации: Обеспечение надежности и проверяемости
Анализ устойчивости является критически важным этапом оценки эффективности механизмов в условиях намеренных воздействий и стратегических манипуляций. Исследования показывают, что даже незначительные отклонения от идеальных условий или преднамеренные искажения входных данных могут привести к существенным нарушениям в работе механизмов, что особенно опасно в критически важных приложениях. Оценка устойчивости включает в себя моделирование различных сценариев атак и выявление слабых мест, позволяя разработчикам создавать более надежные и безопасные системы. Этот процесс требует не только проверки на стандартных тестовых данных, но и проведения стресс-тестов в условиях, имитирующих действия злоумышленников, стремящихся обойти или взломать механизм. Игнорирование устойчивости может привести к серьезным последствиям, включая финансовые потери, нарушение конфиденциальности и потерю доверия к системе.
Прозрачность алгоритмов, или возможность аудита, играет ключевую роль в обеспечении доверия к системам, управляемым данными. Аудит позволяет детально изучить логику работы механизма, проверить его на соответствие заданным критериям и выявить потенциальные отклонения от ожидаемого поведения. Это особенно важно в критически важных приложениях, где необходима гарантия предсказуемости и справедливости. Способность к проверке и пониманию внутренних процессов способствует укреплению ответственности и позволяет выявлять и устранять возможные предвзятости или ошибки, тем самым повышая надежность и обоснованность принимаемых решений.
Дальнейшие исследования в области устойчивости и проверяемости механизмов, основанных на данных, открывают перспективы для их широкого внедрения в критически важные приложения. Недавние работы демонстрируют, что использование пропорциональных прокси и методов оптимизации с ограничениями позволяет существенно снизить предвзятость в принимаемых решениях. Такой подход обеспечивает не только повышение надежности работы механизмов в условиях намеренных манипуляций или неблагоприятных сценариев, но и возможность детального анализа и проверки их функционирования, что крайне важно для построения доверия и обеспечения ответственности в областях, где решения оказывают значительное влияние на жизнь людей, например, в здравоохранении, финансах или правосудии. Продолжающаяся работа в этом направлении направлена на создание систем, которые не просто оптимизированы для достижения определенных целей, но и способны эффективно функционировать в реальных условиях и демонстрировать прозрачность своей работы.
Исследование в области дифференцируемого социального выбора, представленное в данной работе, подчеркивает необходимость целостного подхода к проектированию механизмов коллективного принятия решений. Как отмечал Дональд Дэвис: «Всё ломается по границам ответственности — если их не видно, скоро будет больно». Это наблюдение особенно актуально при анализе сложных систем, где нечетко определенные границы ответственности могут привести к неожиданным сбоям и манипуляциям. Работа демонстрирует, что эффективное агрегирование предпочтений и обеспечение устойчивости к стратегическим манипуляциям требует глубокого понимания взаимосвязей между компонентами системы и четкого определения границ ответственности каждого из них. Игнорирование этой взаимосвязи, как справедливо указывает Дэвис, неизбежно приведет к уязвимостям и, в конечном итоге, к краху системы.
Что Дальше?
Представленный обзор обнажает любопытную закономерность: стремление к «дифференцируемому» управлению коллективными решениями зачастую оборачивается заменой одной сложности на другую. Если механизм держится на «костылях» дифференцируемых приближений, значит, мы переусложнили задачу, пытаясь втиснуть нелинейную природу человеческих предпочтений в рамки градиентного спуска. Модульность, предлагаемая как панацея, оказывается иллюзией контроля, когда контекст взаимодействия игнорируется.
Ключевая проблема — не столько в разработке новых алгоритмов агрегации предпочтений, сколько в понимании того, что мы вообще пытаемся оптимизировать. Если «конституция» искусственного интеллекта строится на основе неявно заданных целей, а не на глубоком анализе этических принципов, то возникает риск воспроизведения существующих социальных неравенств в новом, алгоритмически усиленном виде.
Будущие исследования должны сместить акцент с чисто технических решений в сторону междисциплинарного подхода, объединяющего методы машинного обучения с достижениями теории игр, экономики и политологии. Необходимо разработать более надежные инструменты для выявления и смягчения стратегических манипуляций, а также для обеспечения прозрачности и подотчетности алгоритмических систем принятия решений. В противном случае, «дифференцируемое» управление рискует превратиться в изящный способ легитимизировать предвзятость.
Оригинал статьи: https://arxiv.org/pdf/2602.03003.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-02-04 12:14