Автор: Денис Аветисян
Новый подход объединяет возможности федеративного обучения и аугментации данных для повышения точности выявления болезни Альцгеймера по речевым паттернам.
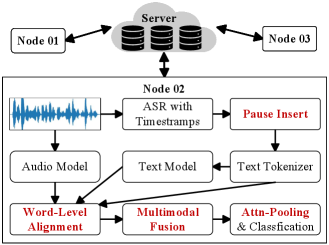
Предложена платформа FAL-AD, использующая федеративное обучение, преобразование голоса и адаптивный выбор модели для преодоления дефицита данных и обеспечения конфиденциальности при диагностике болезни Альцгеймера.
Несмотря на растущий интерес к применению искусственного интеллекта для ранней диагностики болезни Альцгеймера, ограниченность медицинских данных и вопросы конфиденциальности представляют серьезные препятствия. В данной работе, озаглавленной ‘Breaking Data Efficiency Dilemma: A Federated and Augmented Learning Framework For Alzheimer’s Disease Detection via Speech’, предложен инновационный подход FAL-AD, объединяющий федеративное обучение с аугментацией данных на основе преобразования голоса для повышения эффективности. Достигнуты значительные улучшения в точности многомодального анализа — 91.52% на датасете ADReSSo — превосходящие результаты централизованных методов. Сможет ли предложенная архитектура стать практическим решением проблемы дефицита данных и обеспечить более широкое внедрение ИИ в раннюю диагностику нейродегенеративных заболеваний?
Узкое Горлышко в Диагностике: Проблема Данных
Раннее выявление болезни Альцгеймера имеет решающее значение для замедления прогрессирования заболевания и повышения качества жизни пациентов, однако существующие методы диагностики зачастую сопряжены со значительными трудностями. Традиционные подходы, такие как позитронно-эмиссионная томография (ПЭТ) и спинномозговая пункция, являются дорогостоящими, инвазивными и требуют специализированного оборудования и квалифицированного персонала. Эти процедуры не только обременительны для пациентов и их семей, но и ограничивают возможности проведения массовых скринингов, что критически важно для своевременного начала лечения и проведения клинических испытаний новых терапевтических стратегий. Необходимость в более доступных и неинвазивных методах диагностики становится все более актуальной в связи со старением населения и ростом числа людей, подверженных риску развития этого нейродегенеративного заболевания.
Анализ спонтанной речи представляет собой перспективный неинвазивный метод ранней диагностики болезни Альцгеймера, однако его развитие существенно затруднено из-за ограниченного объема размеченных данных. В отличие от традиционных методов, требующих дорогостоящих и инвазивных процедур, анализ речи может проводиться на основе естественной разговорной деятельности пациента. Тем не менее, для обучения эффективных моделей искусственного интеллекта, способных выявлять тонкие лингвистические маркеры заболевания, необходимы обширные наборы данных, содержащие образцы речи пациентов на разных стадиях болезни, а также данные здоровых людей. Нехватка таких данных замедляет прогресс в области автоматизированной диагностики и ограничивает возможности создания точных и надежных систем, способных вовремя выявить болезнь Альцгеймера и обеспечить своевременное начало лечения.
Недостаток размеченных данных для обучения искусственного интеллекта, усугубляемый строгими правилами защиты персональных данных, представляет собой серьезное препятствие для создания надежных моделей диагностики болезни Альцгеймера. Ограниченный доступ к речевым образцам пациентов, необходимым для анализа спонтанной речи, замедляет прогресс в разработке неинвазивных методов выявления заболевания на ранних стадиях. Строгие нормативные акты, направленные на обеспечение конфиденциальности медицинской информации, оправданы, однако они создают дополнительные трудности при сборе и использовании данных для обучения алгоритмов машинного обучения. В результате, исследователи сталкиваются с необходимостью поиска инновационных решений, позволяющих обучать эффективные модели, используя ограниченные и защищенные данные, что требует применения передовых методов, таких как обучение с подкреплением или федеративное обучение.
Традиционные методы глубокого обучения, демонстрирующие впечатляющие результаты в различных областях, требуют огромных объемов размеченных данных для эффективной работы. В контексте выявления болезни Альцгеймера, где получение достаточного количества таких данных сопряжено с трудностями из-за конфиденциальности пациентов и ограниченности ресурсов, этот фактор становится серьезным препятствием. Неспособность обучить модели глубокого обучения на адекватном наборе данных приводит к снижению точности диагностики, увеличению количества ложноположительных и ложноотрицательных результатов, и в конечном итоге — замедляет прогресс в разработке эффективных методов раннего выявления этого нейродегенеративного заболевания. Таким образом, потребность в данных для глубокого обучения усугубляет существующую проблему «узкого горлышка» в диагностике болезни Альцгеймера, ограничивая потенциал искусственного интеллекта в этой критически важной области.
Федеративное Обучение: Совместное Решение
Федеративное обучение (FL) представляет собой перспективный подход к совместной тренировке моделей машинного обучения, позволяющий использовать данные, распределенные между множеством децентрализованных источников, таких как мобильные устройства или больницы, без необходимости их централизованной передачи. В рамках FL, каждая сторона (клиент) тренирует модель локально на своих данных, а затем обменивается только параметрами модели (например, весами нейронной сети) с центральным сервером. Сервер агрегирует эти обновления, формируя улучшенную глобальную модель, которая затем распространяется обратно на клиентов для следующей итерации обучения. Этот процесс позволяет создавать мощные модели, используя большие объемы данных, сохраняя при этом конфиденциальность и снижая риски, связанные с передачей данных.
Федеративное обучение (FL) решает проблемы нехватки данных и сохранения конфиденциальности путём исключения необходимости централизованного сбора данных. В традиционных подходах машинного обучения данные из различных источников должны быть собраны в одном месте для обучения модели, что создаёт риски для приватности и требует значительных затрат на передачу и хранение. FL позволяет обучать модель непосредственно на децентрализованных устройствах или серверах, где данные и находятся. Вместо передачи самих данных, клиенты передают обновления модели, полученные в результате локального обучения. Это позволяет сохранить данные в исходном месте, снижая риски нарушения конфиденциальности и обходя ограничения, связанные с передачей больших объёмов данных, а также решая проблему недостатка данных, так как каждый клиент вносит вклад в общее обучение модели, используя собственные данные.
Стандартные алгоритмы федеративного обучения сталкиваются с трудностями при работе с данными, распределенными по клиентам неравномерно (non-IID). Это означает, что статистические свойства данных (например, распределение классов или частота встречаемости определенных признаков) существенно различаются между отдельными клиентами. Такая неоднородность может приводить к смещению глобальной модели в сторону доминирующих распределений данных и снижению производительности на клиентах с менее представленными данными. Проблема усугубляется при значительном дисбалансе в объемах данных между клиентами, когда небольшое количество клиентов с большим объемом данных оказывает непропорциональное влияние на глобальную модель. Для решения этой проблемы разрабатываются специализированные алгоритмы, учитывающие неоднородность данных и позволяющие адаптировать модель к индивидуальным особенностям каждого клиента.
Персонализация моделей в федеративном обучении является критически важной для адаптации глобальной модели к специфическим особенностям данных каждого клиента и повышения общей производительности. Стандартные подходы федеративного обучения предполагают обучение единой глобальной модели, которая может недостаточно хорошо работать с данными, существенно отличающимися по распределению между клиентами (non-IID данные). Методы персонализации включают в себя fine-tuning глобальной модели на локальных данных каждого клиента, использование адаптеров, добавляемых к глобальной модели, или обучение отдельных слоев модели для каждого клиента. Эти техники позволяют учитывать индивидуальные характеристики данных каждого клиента, что приводит к улучшению точности, скорости сходимости и общей эффективности модели в условиях децентрализованного обучения. Применение персонализации особенно важно в сценариях, где данные клиентов имеют значительные различия по объему, качеству и распределению.
FAL-AD: Расширенное Федеративное Обучение для Болезни Альцгеймера
В рамках FAL-AD (Federated and Augmented Learning) для решения проблемы ограниченности данных при обучении моделей диагностики болезни Альцгеймера используется искусственное расширение обучающей выборки посредством аугментации данных. Этот подход позволяет генерировать новые, синтетические примеры, увеличивая разнообразие и объем данных, доступных для обучения. Аугментация позволяет компенсировать недостаток реальных данных, особенно в случаях редких или сложных патологий, что способствует повышению обобщающей способности модели и улучшению точности диагностики. Использование аугментации данных является ключевым элементом стратегии FAL-AD, направленной на создание надежной и эффективной системы обнаружения болезни Альцгеймера.
Для преодоления ограниченности реальных данных при обучении моделей диагностики болезни Альцгеймера в рамках FAL-AD используется метод кросс-категорийной конвертации голоса (Cross-Category Voice Conversion). Данная технология позволяет синтезировать разнообразные образцы патологической речи, имитирующие различные стадии и проявления заболевания. В отличие от использования только реальных записей, что ограничивает количество и разнообразие данных, конвертация голоса генерирует новые, искусственно созданные образцы, расширяя обучающую выборку и повышая устойчивость модели к вариациям в речи пациентов. Это особенно важно, учитывая, что доступ к достаточному объему размеченных данных о патологической речи крайне ограничен.
В основе улучшения извлечения признаков в FAL-AD лежит механизм кросс-модального слияния на основе внимания, построенный на фреймворке CogniAlign. Для точного выравнивания на уровне слов используется автоматическое распознавание речи Whisper ASR. Этот подход позволяет синхронизировать и объединять информацию из различных модальностей данных (например, речь и текстовые данные), выявляя важные корреляции и улучшая качество представлений, используемых для диагностики болезни Альцгеймера. Фреймворк CogniAlign обеспечивает механизм внимания, который динамически взвешивает вклад каждой модальности в процессе слияния, что позволяет модели фокусироваться на наиболее релевантной информации.
Адаптивное федеративное обучение в FAL-AD оптимизирует выбор моделей и взаимодействие между участниками федерации, что позволяет максимизировать производительность и стабильность системы. В процессе обучения алгоритм динамически корректирует веса моделей, основываясь на их локальной производительности и вкладе в глобальную модель. В результате, FAL-AD достигает передовой многомодальной точности в 91.52% для диагностики болезни Альцгеймера, превосходя существующие методы анализа данных. Данный показатель был получен на стандартном наборе данных, используемом для оценки алгоритмов машинного обучения в области нейродегенеративных заболеваний.
К Надежной и Персонализированной Диагностике Болезни Альцгеймера
Разработанная система FAL-AD демонстрирует значительный прорыв в области диагностики болезни Альцгеймера, позволяя создавать надежные и точные модели даже при ограниченном объеме данных. Достигнутая мультимодальная точность в 91.52% превосходит показатели существующих централизованных подходов к анализу данных, что указывает на эффективность предложенного метода. Данный результат свидетельствует о возможности более ранней и точной диагностики заболевания, что открывает перспективы для своевременного вмешательства и улучшения качества жизни пациентов, находящихся в группе риска. Высокая точность, достигнутая при ограниченном объеме данных, особенно важна для случаев, когда сбор обширных клинических данных затруднен или невозможен.
В основе разработанной системы лежит принцип децентрализации данных и обеспечения конфиденциальности, что способствует укреплению сотрудничества между медицинскими учреждениями и повышению доверия пациентов. Вместо централизованного хранения информации, данные остаются в ведении каждого учреждения, а алгоритмы машинного обучения распределяются для локальной обработки. Такой подход не только снижает риски, связанные с утечкой персональных данных, но и позволяет использовать данные из различных источников, сохраняя при этом приватность каждого пациента. Это создает благоприятную среду для обмена знаниями и совместной разработки более точных и эффективных методов диагностики болезни Альцгеймера, не нарушая этические нормы и требования к защите информации.
Разработанная система FAL-AD демонстрирует способность преодолевать проблему неоднородности данных (non-IID), что позволяет создавать персонализированные модели для диагностики болезни Альцгеймера. В отличие от традиционных подходов, где данные пациентов могут значительно различаться, FAL-AD адаптируется к индивидуальным особенностям каждого человека, повышая точность диагностики. Подтверждением эффективности является значительное улучшение результатов: применение методов увеличения данных позволило повысить общую точность модели с 89.70% при использовании стандартного федеративного обучения до 91.52% в системе FAL-AD. При этом, локальное обучение также выиграло от оптимизаций, показав рост точности с 78.59% до 80.61%. Такой подход открывает возможности для более ранней и точной диагностики, что критически важно для своевременного начала лечения и улучшения качества жизни пациентов.
Разработка новой платформы для диагностики болезни Альцгеймера открывает перспективные возможности для раннего выявления заболевания и, как следствие, своевременного начала терапевтических вмешательств. Ранняя диагностика позволяет замедлить прогрессирование болезни, улучшить когнитивные функции и сохранить качество жизни пациентов на более длительный срок. Благодаря возможности создания персонализированных моделей, учитывающих индивидуальные особенности каждого пациента, появляется шанс на более эффективное лечение и профилактику. Помимо этого, улучшение точности диагностики способствует снижению неопределенности и тревожности у пациентов и их семей, что является важным аспектом комплексного подхода к лечению болезни Альцгеймера и повышению общего благополучия.
Представленная работа демонстрирует стремление к созданию устойчивых систем анализа данных, что находит отклик в философии разработки. Как отмечает Линус Торвальдс: «Плохой код похож на раковую опухоль: если его не удалить, он будет распространяться». В контексте диагностики болезни Альцгеймера, где доступ к данным ограничен соображениями конфиденциальности, предложенный подход к федеративному обучению с аугментацией данных можно рассматривать как своеобразную «иммунотерапию» для системы. Он позволяет обойти проблему нехватки данных, одновременно защищая частную информацию пациентов. Подобное решение, направленное на долгосрочную устойчивость и адаптивность, соответствует принципам создания систем, способных достойно стареть, а не быстро устаревать под давлением внешних обстоятельств.
Что дальше?
Представленная работа, стремясь обойти дефицит данных и вопросы конфиденциальности в диагностике болезни Альцгеймера, демонстрирует, как система может адаптироваться к неизбежному ограничению — нехватке информации. Однако, адаптация — не вечное решение. Каждая система стареет, и представленный подход, хотя и эффективен на данном этапе, не является иммунитетом к энтропии. Повышение производительности за счет аугментации и федеративного обучения лишь отодвигает момент, когда необходимость в принципиально новых подходах станет очевидной.
Будущие исследования, вероятно, сосредоточатся на преодолении фундаментальных ограничений — не столько в улучшении алгоритмов, сколько в поиске альтернативных источников информации. Переход от анализа исключительно речевых данных к многомодальному подходу, включающему биомаркеры, генетические данные и поведенческие паттерны, представляется неизбежным. При этом, стоит помнить, что стабильность, достигнутая за счет интеграции различных источников, может оказаться лишь временной задержкой катастрофы, если не учитывать сложность и взаимосвязанность биологических систем.
Вопрос не в том, чтобы создать идеальный алгоритм, а в том, чтобы понять, как долго данная система сможет функционировать в условиях постоянного изменения. Время — не метрика, а среда, в которой существуют системы, и каждая адаптация — лишь способ отсрочить неизбежное. Задача исследователя — не победить время, а достойно наблюдать за течением процесса.
Оригинал статьи: https://arxiv.org/pdf/2602.14655.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-18 04:45