Автор: Денис Аветисян
Новое исследование демонстрирует, что модели глубокого обучения способны эффективно выявлять уязвимости в бинарном коде x86-64, работая непосредственно с машинным кодом.
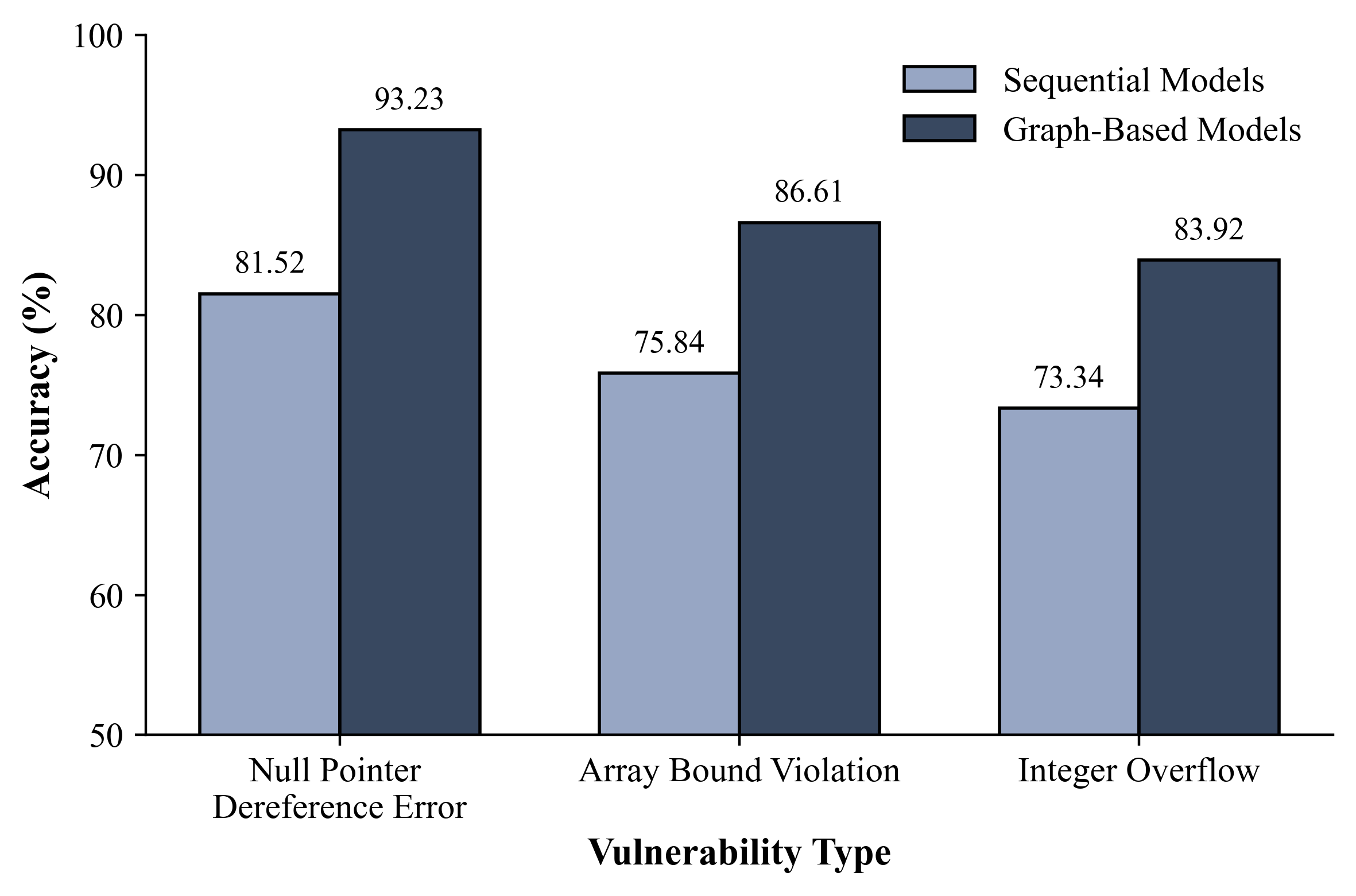
Применение глубокого обучения для обнаружения уязвимостей в бинарных файлах x86-64, минуя этап дизассемблирования.
Несмотря на широкое применение глубокого обучения в анализе бинарных файлов, большинство существующих исследований полагаются на дизассемблированный код. В данной работе, ‘Deep Learning-based Binary Analysis for Vulnerability Detection in x86-64 Machine Code’, исследуется возможность извлечения признаков непосредственно из машинного кода x86-64, что позволяет упростить модели и сохранить полную информацию. Полученные результаты демонстрируют, что модели, основанные на графах потока управления, превосходят последовательные модели, и что машинный код содержит достаточные данные для эффективного обнаружения уязвимостей. Открывает ли это путь к созданию более компактных и производительных инструментов статического анализа бинарных файлов?
Эволюция Уязвимостей: От Ручного Анализа к Автоматизации
В условиях постоянно растущей сложности программного обеспечения, традиционные методы обнаружения уязвимостей, такие как ручной анализ кода и динамическое тестирование, демонстрируют свою все большую неэффективность. Эти подходы, требующие значительных временных затрат и подверженные человеческим ошибкам, зачастую не способны охватить весь объем современного кодобеза, оставляя критические недостатки незамеченными. Увеличение масштабов проектов и скорости разработки усугубляют проблему, делая ручной анализ непрактичным, а динамическое тестирование — недостаточно всеобъемлющим для обеспечения надежной защиты от потенциальных угроз. В результате, разработчики сталкиваются с необходимостью внедрения автоматизированных и масштабируемых решений, способных эффективно выявлять уязвимости на ранних стадиях жизненного цикла разработки.
Традиционные методы обнаружения уязвимостей, такие как ручной анализ кода и динамическое тестирование, все чаще оказываются неэффективными перед лицом растущей сложности современных программных систем. Эти подходы требуют значительных временных затрат, подвержены человеческим ошибкам и испытывают трудности с масштабированием при работе с огромными кодовыми базами. В результате, критические уязвимости зачастую остаются незамеченными, представляя серьезную угрозу безопасности информационных систем и данных. Неспособность оперативно выявлять и устранять эти недостатки может привести к дорогостоящим инцидентам и потере доверия пользователей, подчеркивая необходимость перехода к более автоматизированным и масштабируемым решениям в области обеспечения безопасности.
В условиях экспоненциального роста сложности программного обеспечения, переход к автоматизированным и масштабируемым решениям становится не просто желательным, а жизненно необходимым для обеспечения проактивной безопасности. Традиционные методы обнаружения уязвимостей, такие как ручной анализ кода и динамическое тестирование, зачастую не справляются с объемом и скоростью изменений в современных кодовых базах. Это требует разработки принципиально новых подходов к выявлению слабых мест, использующих возможности машинного обучения, статического анализа нового поколения и фаззинга, способных автоматически сканировать код, выявлять потенциальные уязвимости и значительно сокращать время реагирования на возникающие угрозы. Разработка и внедрение подобных инструментов позволит организациям не только обнаруживать уязвимости на ранних этапах жизненного цикла разработки, но и существенно снизить риски, связанные с кибератаками и утечками данных.
Глубокое Обучение для Анализа Бинарного Кода: Новый Подход
Глубокое обучение представляет собой перспективный подход к автоматизированному обнаружению уязвимостей в бинарном коде, основанный на способности моделей выявлять закономерности в больших объемах машинного кода. Традиционные методы анализа часто сталкиваются с трудностями при обработке сложных и запутанных программ, в то время как модели глубокого обучения способны извлекать признаки и зависимости, неявные для человека или статических анализаторов. Обучение на обширных наборах данных, включающих как уязвимый, так и безопасный код, позволяет моделям эффективно классифицировать программы и выявлять потенциальные уязвимости, значительно снижая нагрузку на экспертов по безопасности и повышая скорость реагирования на угрозы. Эффективность такого подхода зависит от качества и объема обучающих данных, а также от архитектуры выбранной нейронной сети.
Использование методов встраивания (embedding) позволяет моделям глубокого обучения представлять двоичные программы в виде векторов, отражающих семантические особенности кода, важные для обнаружения уязвимостей. Встраивания преобразуют дискретные элементы программы, такие как отдельные инструкции или базовые блоки, в непрерывные векторные представления, где близость векторов соответствует семантической схожести. Это позволяет модели не только учитывать синтаксис, но и понимать смысл кода, что особенно важно для выявления сложных уязвимостей, которые не могут быть обнаружены статическим анализом, основанным на сигнатурах. Различные методы встраивания могут учитывать контекст инструкций, зависимости между базовыми блоками и другие характеристики, влияющие на безопасность программы.
Представление бинарного кода для анализа с использованием методов глубокого обучения может осуществляться различными способами. Последовательные последовательности инструкций, такие как ассемблерный листинг, позволяют моделировать временные зависимости в коде, что полезно для обнаружения уязвимостей, связанных с порядком выполнения операций. Альтернативно, графовые представления, основанные на потоке управления (Control Flow Graph, CFG), отображают взаимосвязи между блоками кода и позволяют анализировать структуру программы, выявляя, например, циклы и ветвления, что критично для поиска уязвимостей, связанных с логическими ошибками. Выбор конкретного представления зависит от поставленной задачи и архитектуры анализируемого кода; каждый подход имеет свои преимущества и ограничения в плане эффективности и точности.
Графовые и Последовательные Подходы: Архитектуры в Действии
Bin2Vec использует графовые сверточные сети (GCN) для обучения векторным представлениям (embeddings) из бинарных программ, представленных в виде графов потока управления (CFG). В данном подходе, каждая базовая единица программы (basic block) моделируется как узел графа, а переходы между ними — как ребра. GCN позволяют учитывать структуру графа при обучении представлений, эффективно захватывая взаимосвязи между различными частями программы и, как следствие, её структурные особенности. Это позволяет модели учитывать не только последовательность инструкций, но и архитектурные зависимости, что особенно важно для анализа уязвимостей и выявления вредоносного кода.
Asm2Vec использует методы глубокого обучения для анализа последовательностей ассемблерного кода, извлекая закономерности из линейного потока инструкций. В основе подхода лежит представление программы как упорядоченной последовательности токенов, полученных после этапа токенизации. Модель обучается предсказывать следующие токены в последовательности, что позволяет ей выявлять характерные шаблоны и зависимости в коде. Этот метод позволяет улавливать поведенческие особенности программы, основанные на порядке выполнения инструкций, что может быть полезно для обнаружения уязвимостей и анализа вредоносного ПО.
Оба подхода — Bin2Vec и Asm2Vec — демонстрируют способность к выявлению уязвимостей в программном обеспечении, однако каждый из них превосходит другой в захвате различных аспектов поведения программ. Bin2Vec, используя графовые сверточные сети (GCN) и представление программы в виде графа потока управления (CFG), эффективно моделирует структурные связи между компонентами программы, что позволяет обнаруживать уязвимости, связанные с неправильной логикой или архитектурой. Asm2Vec, напротив, анализирует последовательное выполнение инструкций в коде, извлекая закономерности из линейного потока команд. Это делает его более эффективным в обнаружении уязвимостей, связанных с ошибками в последовательности операций или уязвимостями, эксплуатирующими конкретную последовательность инструкций.
Токенизация является критически важным этапом предварительной обработки при создании последовательных представлений кода для моделей глубокого обучения. Этот процесс предполагает разбивку исходного кода на отдельные элементы, называемые токенами — обычно это ключевые слова, идентификаторы, операторы и литералы. Полученные токены затем преобразуются в числовые представления (например, с использованием словаря или встраиваний), которые могут быть обработаны нейронными сетями. Эффективная токенизация позволяет модели анализировать синтаксическую структуру и семантические особенности кода, значительно повышая точность и эффективность задач, таких как анализ уязвимостей и обнаружение вредоносного кода.
Выявление Шаблонов Уязвимостей с Помощью Глубокого Обучения
Исследования показали, что модели глубокого обучения, обученные на специализированных наборах данных, таких как FormAI-v2, способны эффективно выявлять распространенные типы уязвимостей в программном обеспечении. К ним относятся переполнения целых чисел (integer overflow), разыменования нулевых указателей (null pointer dereference) и нарушения границ массивов (array bound violation). Способность моделей распознавать эти паттерны уязвимостей позволяет автоматизировать процесс анализа безопасности кода и значительно сократить время, необходимое для обнаружения потенциальных угроз. Такой подход открывает возможности для создания более надежных и защищенных программных систем, снижая риски, связанные с эксплуатацией уязвимостей.
Исследования показали, что модели глубокого обучения, применяемые для выявления уязвимостей в программном обеспечении, достигают уровня точности в 80-90% при анализе различных категорий ошибок, известных как CWE (Common Weakness Enumeration). Этот показатель сопоставим с результатами, которые демонстрируют традиционные методы анализа, основанные на изучении ассемблерного кода. Важно отметить, что подобная эффективность достигается без необходимости в сложных семантических представлениях программы, позволяя моделям работать непосредственно с машинным кодом x86-64. Такое соответствие результатов подтверждает перспективность использования глубокого обучения в качестве эффективного инструмента для автоматизированного поиска уязвимостей и повышения безопасности программного обеспечения.
Исследования показали, что точность выявления уязвимостей с использованием моделей глубокого обучения значительно варьируется в зависимости от типа уязвимости. В частности, обнаружение разыменований нулевых указателей (Null Pointer Dereferences) демонстрирует наивысшую точность, что указывает на относительную простоту выявления этой категории уязвимостей с помощью применяемых методов. В то же время, обнаружение переполнений целых чисел (Integer Overflow) требует дальнейшей отработки, особенно в части анализа потока данных. Это указывает на необходимость более глубокого изучения и разработки специализированных подходов к анализу данных, позволяющих эффективно выявлять уязвимости, связанные с переполнением целых чисел, и повысить общую надежность систем безопасности.
Исследование показало, что модели глубокого обучения способны анализировать непосредственно машинный код x86-64, без необходимости в построении более сложных семантических представлений. Такой подход позволяет достичь сопоставимой точности обнаружения уязвимостей, как и традиционные методы, основанные на анализе ассемблерного кода. Вместо того, чтобы разбирать код на отдельные компоненты и строить абстрактные представления, модель обучается выявлять закономерности непосредственно в последовательности байтов машинного кода. Это упрощает процесс анализа и открывает возможности для более быстрого и эффективного обнаружения потенциальных уязвимостей в программном обеспечении, демонстрируя перспективность использования глубокого обучения для автоматизации анализа безопасности.
Исследование демонстрирует, что глубокое обучение способно анализировать машинный код напрямую, минуя стадию дизассемблирования. Этот подход, хотя и требует значительных вычислительных ресурсов, позволяет выявлять уязвимости с эффективностью, сопоставимой с традиционными методами, основанными на анализе ассемблерного кода. Тим Бернерс-Ли однажды заметил: «Данные должны быть свободны». В контексте анализа бинарных файлов, это можно интерпретировать как необходимость доступа к фундаментальному уровню машинного кода для обеспечения безопасности. По сути, системы, подобные описанной в статье, не строятся, а вырастают из постоянного взаимодействия с потоком данных и уязвимостей, подобно экосистеме, где каждый выбор архитектуры — это пророчество о будущих ошибках.
Что дальше?
Представленная работа демонстрирует, что модели глубокого обучения способны извлекать смысл непосредственно из сырого машинного кода. Это, безусловно, шаг вперед, но не стоит обольщаться иллюзией полного автоматизма. Архитектура — это не структура, а компромисс, застывший во времени. Обнаружение переполнения целых чисел — лишь один из множества возможных дефектов, и каждый новый тип уязвимости потребует новых архитектурных решений, новых компромиссов.
Системы анализа кода — это не инструменты, а экосистемы. Их нельзя построить, только вырастить. Оптимизация производительности, снижение ложных срабатываний — это постоянная борьба, напоминающая попытку удержать воду в решете. Технологии сменяются, зависимости остаются. Истинно важным представляется не столько совершенствование алгоритмов, сколько развитие методов адаптации к постоянно меняющемуся ландшафту угроз.
В конечном итоге, задача обнаружения уязвимостей — это не техническая проблема, а экзистенциальная. Она требует понимания не только кода, но и намерений тех, кто его пишет, и тех, кто пытается его взломать. И это знание, увы, не поддается формализации и не может быть сведено к набору математических операций.
Оригинал статьи: https://arxiv.org/pdf/2601.09157.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
2026-01-15 17:39