Автор: Денис Аветисян
Новый масштабный бенчмарк AVFakeBench позволяет оценить возможности современных мультимодальных моделей в обнаружении аудиовизуальных подделок и выявить их слабые места.
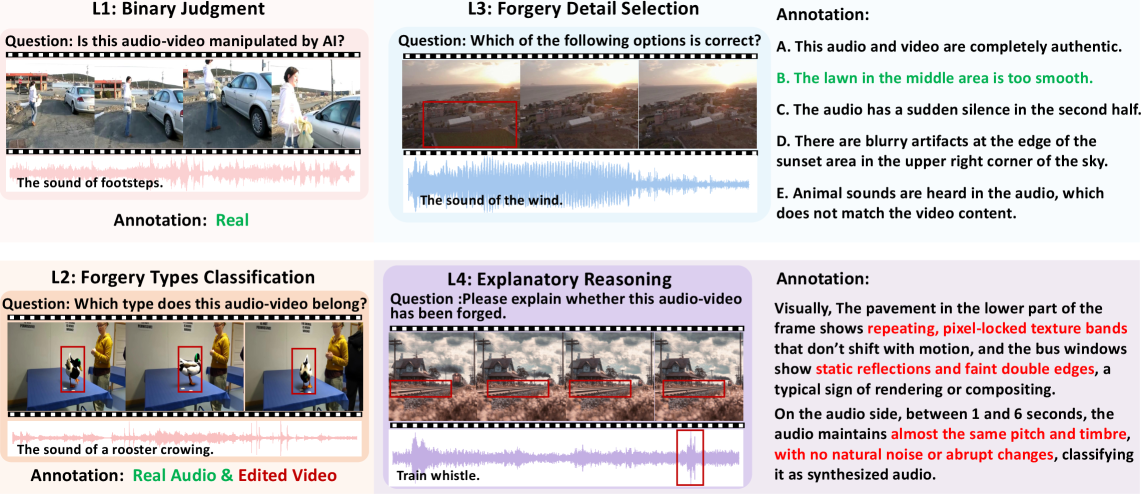
Исследование представляет AVFakeBench — комплексный набор данных для оценки и улучшения алгоритмов обнаружения подделок в аудио- и видеоконтенте, созданных с использованием генеративных моделей.
Несмотря на стремительное развитие технологий глубокого обучения, обнаружение аудиовизуальных подделок выходит за рамки простого выявления дипфейков, требуя анализа сложных манипуляций в реальных сценах. В данной работе представлена AVFakeBench: A Comprehensive Audio-Video Forgery Detection Benchmark for AV-LMMs — первая комплексная база данных для оценки алгоритмов обнаружения подделок, охватывающая широкий спектр семантических искажений как в отношении людей, так и общих объектов. Эксперименты с 11 мультимодальными языковыми моделями показали их перспективность, но и выявили существенные ограничения в тонком восприятии, сопоставлении аудио- и видеоданных и способности к объяснению принятых решений. Какие новые подходы необходимы для создания надежных и прозрачных систем обнаружения аудиовизуальных подделок?
Растущая Угроза Аудиовизуальных Подделок: Вызов для Критического Мышления
Распространение генеративных моделей, таких как нейронные сети, способные создавать гиперреалистичные аудио- и видеоматериалы, представляет собой растущую угрозу достоверности медиаконтента. Современные методы обнаружения подделок, основанные на анализе артефактов сжатия или несоответствий в освещении, оказываются все менее эффективными перед лицом материалов, созданных с использованием этих технологий. Генеративные модели способны воспроизводить мельчайшие детали и нюансы человеческой речи и поведения, что делает выявление манипуляций крайне сложной задачей. В результате, поддельные аудио- и видеоматериалы становятся все более убедительными, представляя серьезную опасность для общественного доверия и потенциально приводя к дезинформации и манипуляциям.
Распространение аудиовизуальных подделок представляет собой серьезную угрозу для современного общества, поскольку способно подорвать доверие к средствам массовой информации и институтам. Искажение реальности через реалистичные, но ложные видео- и аудиозаписи может привести к манипулированию общественным мнением, дезинформации и даже политической нестабильности. Утрата веры в достоверность медиаконтента ослабляет способность граждан к принятию обоснованных решений, что имеет далеко идущие последствия для демократических процессов и социальной сплоченности. Особенно опасным является использование таких подделок для дискредитации отдельных лиц или организаций, что может привести к серьезным репутационным потерям и юридическим последствиям. Поэтому разработка эффективных методов обнаружения и разоблачения подобных подделок является критически важной задачей для защиты информационной безопасности и поддержания стабильности в обществе.
Современные методы выявления подделок аудио- и видеоматериалов сталкиваются со значительными трудностями, обусловленными сложностью тонких манипуляций и стремительным развитием генеративных технологий. Ранее эффективные алгоритмы, основанные на обнаружении явных несоответствий, оказываются неспособными распознать подделки, созданные с использованием передовых нейронных сетей, способных реалистично имитировать человеческую речь и визуальные детали. Особенно проблематичны манипуляции, затрагивающие не глобальную структуру контента, а лишь отдельные его аспекты — мимику, интонацию, освещение — которые остаются незаметными для традиционных методов анализа. В результате, даже незначительные изменения, внесенные в оригинальный материал, могут оставаться необнаруженными, что существенно подрывает доверие к цифровым медиа и создает угрозу распространения дезинформации.
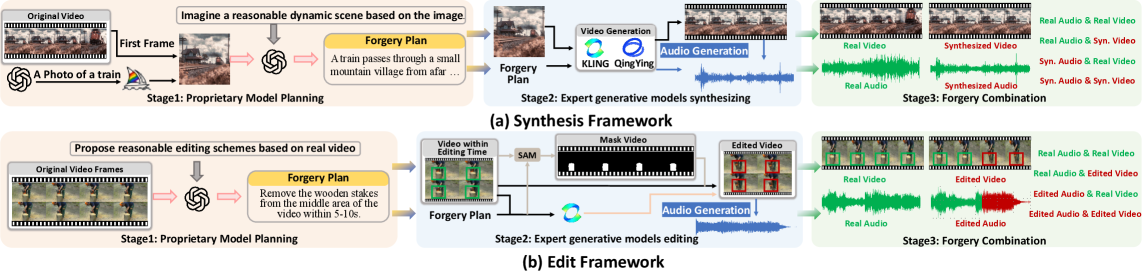
AVFakeBench: Новый Эталон для Оценки Надежности Систем Обнаружения
AVFakeBench представляет собой новый эталонный набор данных, разработанный для строгой оценки возможностей моделей обнаружения аудио- и видеоподделок. В отличие от существующих наборов данных, AVFakeBench нацелен на всестороннюю проверку не только способности моделей идентифицировать манипуляции, но и на оценку их устойчивости к разнообразным и реалистичным типам подделок. Набор данных включает в себя широкий спектр аудиовизуальных материалов, подвергшихся различным видам манипуляций, что позволяет провести более объективную и всестороннюю оценку эффективности алгоритмов обнаружения подделок в условиях, приближенных к реальным.
AVFakeBench использует Гибридную Рамку Подделок (Hybrid Forgery Framework) для создания разнообразных и высококачественных подделок аудио- и видеоматериалов. Данная рамка комбинирует различные методы манипуляции, включая манипуляции с пикселями, сжатием, и временными рядами, что позволяет генерировать подделки, которые сложно обнаружить существующим системам. Использование гибридного подхода направлено на преодоление ограничений, присущих системам, обученным только на определенных типах подделок, и, следовательно, на более строгую оценку возможностей моделей обнаружения. Сгенерированные подделки характеризуются высоким уровнем реалистичности и сложностью, что позволяет эффективно тестировать и совершенствовать алгоритмы выявления фальсификаций.
AVFakeBench оценивает модели по четырем ключевым задачам, предназначенным для всесторонней проверки их возможностей. Бинарная оценка подлинности требует от модели определить, является ли представленный аудиовизуальный контент подлинным или подделанным. Множественный выбор классификации подделок проверяет способность модели идентифицировать конкретный тип манипуляции из заданного набора вариантов. Задача Выбор деталей подделки требует от модели указать точные области, в которых были внесены изменения в контент. Наконец, задача Обоснованное объяснение требует от модели предоставить логическое обоснование своего решения, демонстрируя понимание того, как и где были произведены манипуляции.
Многоаспектная оценка, предлагаемая AVFakeBench, выходит за рамки простой детекции подделок, предоставляя комплексную проверку возможностей моделей. Помимо бинарной классификации подлинности, бенчмарк оценивает способность модели к классификации типа манипуляции из нескольких вариантов, выявлению конкретных деталей подделки и, что критически важно, к объяснению как и где были внесены изменения. Такой подход позволяет получить полное представление о способности модели не только идентифицировать подделку, но и понимать природу и локализацию манипуляций, что необходимо для повышения надежности систем обнаружения и анализа аудиовизуального контента.

Аудио-Визуальные Большие Мультимодальные Модели: Новый Инструмент для Обнаружения Подделок
Аудио-визуальные большие мультимодальные модели (AV-LMM) представляют собой перспективный подход к обнаружению подделок, основанный на совместной обработке как аудио-, так и видеоданных. В отличие от традиционных методов, анализирующих каждый поток данных отдельно, AV-LMM способны извлекать и использовать взаимосвязи между звуком и изображением. Это позволяет моделям выявлять несоответствия, которые могут указывать на манипуляции, например, асинхронность движений губ и произносимых слов, или несоответствие звуковой картины и визуального ряда. Совместная обработка данных позволяет AV-LMM более эффективно обнаруживать сложные подделки, которые могут быть незаметны при анализе только одного модального потока.
Аудиовизуальные большие мультимодальные модели (AV-LMM) способны выявлять сложные взаимосвязи между аудио- и видеоданными, что позволяет им обнаруживать тонкие несоответствия, указывающие на манипуляции. Этот процесс основан на обучении модели распознавать согласованность между визуальными и слуховыми признаками; например, несоответствие между движением губ на видео и соответствующим звуком речи может быть идентифицировано как признак подделки. Модели анализируют не только отдельные модальности, но и их совместное представление, что повышает устойчивость к шуму и искажениям в отдельных каналах данных. Способность к мультимодальному анализу позволяет AV-LMM обнаруживать манипуляции, которые могут быть незаметны при анализе только видео или только аудио.
Аудиовизуальные большие мультимодальные модели (AV-LMM) демонстрируют высокую эффективность в задачах, связанных с пониманием синхронизации губ (lip sync) и выявлением несоответствий между визуальными и слуховыми сигналами. Данные модели способны анализировать как визуальные движения губ, так и соответствующие звуковые волны, что позволяет им обнаруживать даже незначительные рассинхронизации, которые могут указывать на манипуляции с видео- или аудиоматериалом. Такой подход особенно полезен в сценариях, где требуется верификация подлинности видеоконтента, например, для выявления дипфейков или поддельных заявлений.
Несмотря на достижение Gemini-2.5-Pro показателя точности в 54.3% при бинарной оценке подлинности, что демонстрирует высокую производительность, мультимодальные аудио-визуальные большие модели (AV-LMM) демонстрируют значительные ограничения в более сложных сценариях. В частности, при решении задачи многовариантной классификации подделок, точность AV-LMM падает до 19.2%, что указывает на существенную разницу в способности моделей к обобщению и выявлению манипуляций в условиях повышенной сложности и неоднозначности данных.
Двойственная Природа Генеративных Моделей: Инструмент для Созидания и Дезинформации
Несмотря на значительные успехи в разработке мультимодальных моделей, способных обнаруживать поддельные аудио- и видеоматериалы, генеративные модели, такие как Sora и KLING, представляют собой серьезную проблему. Эти инструменты демонстрируют растущую способность создавать гиперреалистичный синтезированный контент, что стирает границы между подлинными и сфабрикованными данными. Способность генеративных моделей к правдоподобному воспроизведению визуальной и звуковой информации создает уникальные сложности для систем обнаружения подделок, поскольку отличить оригинал от искусственно созданного контента становится все труднее. По мере развития технологий генерации контента, потенциал для злоупотреблений, например, для создания дезинформации или фальсификации доказательств, возрастает, требуя постоянного совершенствования методов обнаружения и анализа.
Современные генеративные модели, такие как $Sora$ и $KLING$, демонстрируют впечатляющую способность к созданию синтезированного аудио- и видеоконтента, который становится все более реалистичным и неотличимым от подлинного. Этот прогресс стирает границы между реальностью и фальсификацией, создавая серьезные вызовы для верификации информации. По мере улучшения качества генерируемых данных, становится все сложнее определить, является ли представленный контент аутентичным или результатом работы алгоритма. Такая тенденция представляет не только технологическую проблему, но и ставит под вопрос доверие к визуальным и звуковым источникам информации, требуя разработки новых методов проверки и аутентификации контента.
Инструменты, такие как FoleyCrafter, значительно расширяют возможности по созданию синхронизированного аудио- и видеоконтента, делая подделки всё более убедительными. Данные программы позволяют детально контролировать звуковое сопровождение видео, имитируя реалистичные шумы и эффекты, идеально совпадающие с визуальным рядом. В результате, даже опытному зрителю становится сложно отличить сгенерированный контент от оригинального, поскольку отсутствует диссонанс между тем, что он видит, и тем, что слышит. Такая высокая степень синхронизации представляет серьезную проблему для систем обнаружения подделок, поскольку традиционные методы, основанные на анализе отдельных модальностей, оказываются неэффективными против столь реалистичных манипуляций.
Несмотря на значительный прогресс в области мультимодальных моделей, оценка показывает, что даже современные системы, такие как GPT-4o, испытывают трудности с распознаванием тонких деталей подделок. В ходе тестирования, модель продемонстрировала всего 27.5% Macro-F1 при задаче выбора деталей, указывающих на подделку, и лишь 29.0 баллов из 100 по шкале оценки обоснованности обнаружения. Это указывает на существенные ограничения в способности модели не просто идентифицировать подделку, но и объяснить, какие именно признаки указывают на её искусственное происхождение. Таким образом, даже передовые системы сталкиваются с проблемами при анализе сложных визуальных и аудио данных, необходимых для выявления высококачественных подделок, что подчеркивает необходимость дальнейших исследований в области тонкого анализа и интерпретации мультимедийного контента.
Современные генеративные модели, такие как те, что используются для создания реалистичного аудио и видео контента, демонстрируют двойственное применение. С одной стороны, они открывают беспрецедентные возможности для творчества и инноваций в различных сферах, от искусства до развлечений. С другой стороны, эти же технологии могут быть использованы для создания убедительных подделок и распространения дезинформации, что представляет серьезную угрозу для доверия к медиа и общественной безопасности. Эта двойственность требует внимательного рассмотрения этических и социальных последствий развития подобных технологий, а также разработки эффективных мер по предотвращению их злоупотребления и защите от манипуляций.

Исследование, представленное в данной работе, подчеркивает сложность задачи выявления аудиовизуальных подделок, особенно в отношении тонких манипуляций и обеспечения корректной синхронизации аудио- и видеопотоков. Данный аспект согласуется с принципом математической чистоты, поскольку любое отклонение от идеальной синхронизации или несоответствие в данных указывает на потенциальную ошибку. Как однажды заметил Дэвид Марр: «Представление должно быть достаточно богатым, чтобы поддерживать процессы, которые оно представляет». Эта фраза отражает необходимость глубокого и точного представления аудиовизуальной информации для эффективного обнаружения подделок, ведь недостаточно просто «зафиксировать», что что-то работает на тестовых примерах — необходимо понимать и доказывать корректность алгоритма.
Куда двигаться дальше?
Представленный бенчмарк AVFakeBench выявил закономерную, хотя и несколько печальную истину: масштабные мультимодальные модели, несмотря на впечатляющие возможности, все еще испытывают трудности с точным восприятием и, что особенно важно, с пониманием причинно-следственных связей в аудиовизуальных данных. Обнаружение подделок — это не просто классификация, это доказательство несоответствия, и существующие модели часто не способны предоставить убедительное обоснование своих решений. В конечном счете, алгоритм, не способный объяснить свой вывод, остается лишь сложным оракулом.
Перспективы развития очевидны: необходим акцент на разработке методов, обеспечивающих не только обнаружение манипуляций, но и их локализацию с высокой точностью. Более того, критически важным является внедрение принципов объяснимого искусственного интеллекта (XAI), позволяющих модели демонстрировать, какие именно признаки в аудио- и видеопотоках привели к определению подделки. Это требует выхода за рамки простых карт внимания и перехода к более формализованным, математически обоснованным методам рассуждений.
В хаосе постоянно усложняющихся методов генерации контента, спасает только математическая дисциплина. Подобно тому, как геометрия обеспечивает надежность измерений, строгие математические модели и алгоритмы станут фундаментом для надежной и прозрачной системы обнаружения подделок. Лишь в этом случае можно будет говорить об истинной элегантности и практической ценности решений в области аудиовизуальной криминалистики.
Оригинал статьи: https://arxiv.org/pdf/2511.21251.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
2025-11-29 11:08