Автор: Денис Аветисян
Новое исследование показывает, что учет неопределенности в системах обнаружения политических дипфейков может повысить их надежность, особенно при принятии критически важных решений.
Оценка неопределенности с помощью стохастических сверточных нейронных сетей позволяет повысить надежность систем обнаружения дипфейков и реализовать стратегии селективного предсказания.
Несмотря на значительные успехи в автоматическом обнаружении дипфейков, существующие системы часто не способны оценить надежность своих предсказаний, что критически важно в политическом контексте. Данная работа, озаглавленная ‘Conditional Uncertainty-Aware Political Deepfake Detection with Stochastic Convolutional Neural Networks’, исследует возможности повышения надежности обнаружения политических дипфейков с помощью стохастических сверточных нейронных сетей и оценки неопределенности. Полученные результаты показывают, что откалиброванные вероятностные оценки и учет неопределенности позволяют разрабатывать более эффективные стратегии модерации, особенно при высокой уверенности в предсказании. Возможно ли, используя подобные подходы, создать системы, способные не только выявлять дипфейки, но и оценивать риски, связанные с их распространением?
Шёпот Хаоса: Растущая Угроза Дипфейков
Распространение синтетических медиа, особенно так называемых “дипфейков”, представляет собой растущую угрозу для целостности информации и доверия общества. Создаваемые с использованием искусственного интеллекта изображения и видеоролики становятся все более реалистичными, что затрудняет их распознавание от подлинных материалов. Это создает благоприятную почву для дезинформации, манипуляций общественным мнением и подрыва доверия к средствам массовой информации, экспертам и даже визуальным доказательствам. Возможность создания убедительных, но ложных повествований ставит под вопрос само понятие правды в цифровой среде и требует разработки новых подходов к верификации информации и защите от злонамеренного использования технологий.
Современные методы обнаружения поддельных изображений сталкиваются с растущими трудностями, поскольку технологии генерации контента становятся все более изощренными. Раньше манипуляции часто были заметны невооруженным глазом или легко выявлялись при анализе метаданных. Однако, новые алгоритмы, использующие глубокое обучение, способны создавать невероятно реалистичные подделки, в которых практически невозможно обнаружить следы вмешательства. Эти технологии не просто заменяют части изображения, но и создают новые пиксели, имитируя естественные текстуры и детали, что делает традиционные методы обнаружения, основанные на поиске артефактов, неэффективными. В результате, даже опытные эксперты испытывают затруднения в различении подлинных изображений от искусно созданных подделок, что представляет серьезную угрозу для достоверности визуальной информации.
Несмотря на критическую важность надежного выявления дипфейков, существующие системы часто демонстрируют недостаточную точность в различении подлинного и синтезированного контента. Современные алгоритмы, основанные на анализе артефактов или несоответствий, все чаще терпят неудачу перед лицом усовершенствованных технологий генерации, способных создавать изображения и видео, практически неотличимые от реальности. Особенно сложной задачей является обнаружение дипфейков, выполненных с высокой степенью реализма и направленных на имитацию естественных человеческих выражений и мимики. Отсутствие универсальных индикаторов подделки и зависимость от специфических признаков, присущих определенным алгоритмам генерации, приводят к ложным срабатываниям и неспособности обнаружить новые типы синтетического контента, что подрывает доверие к цифровой информации и создает серьезные риски для информационной безопасности.
За Гранью Точности: Необходимость Надежных Предсказаний
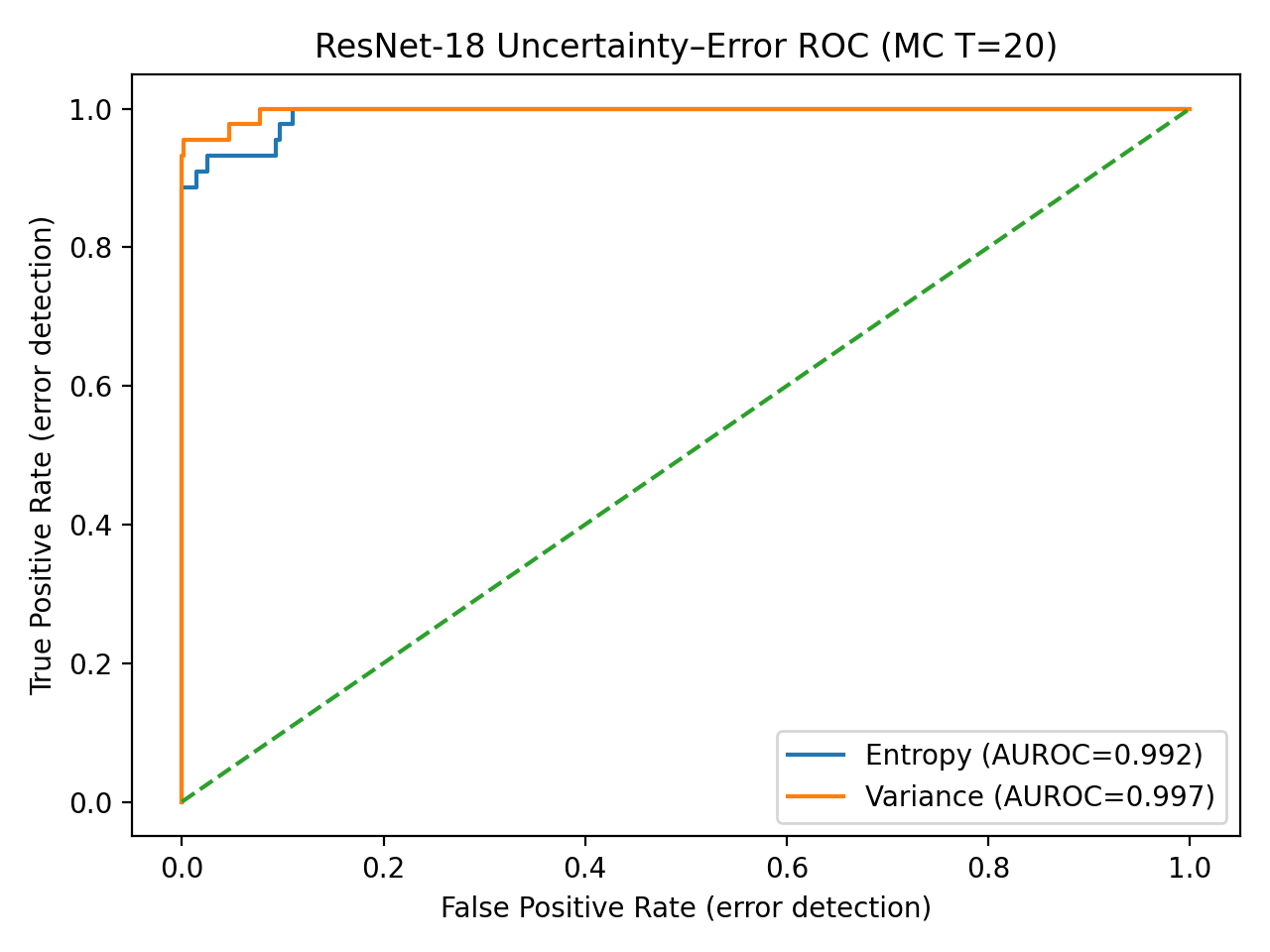
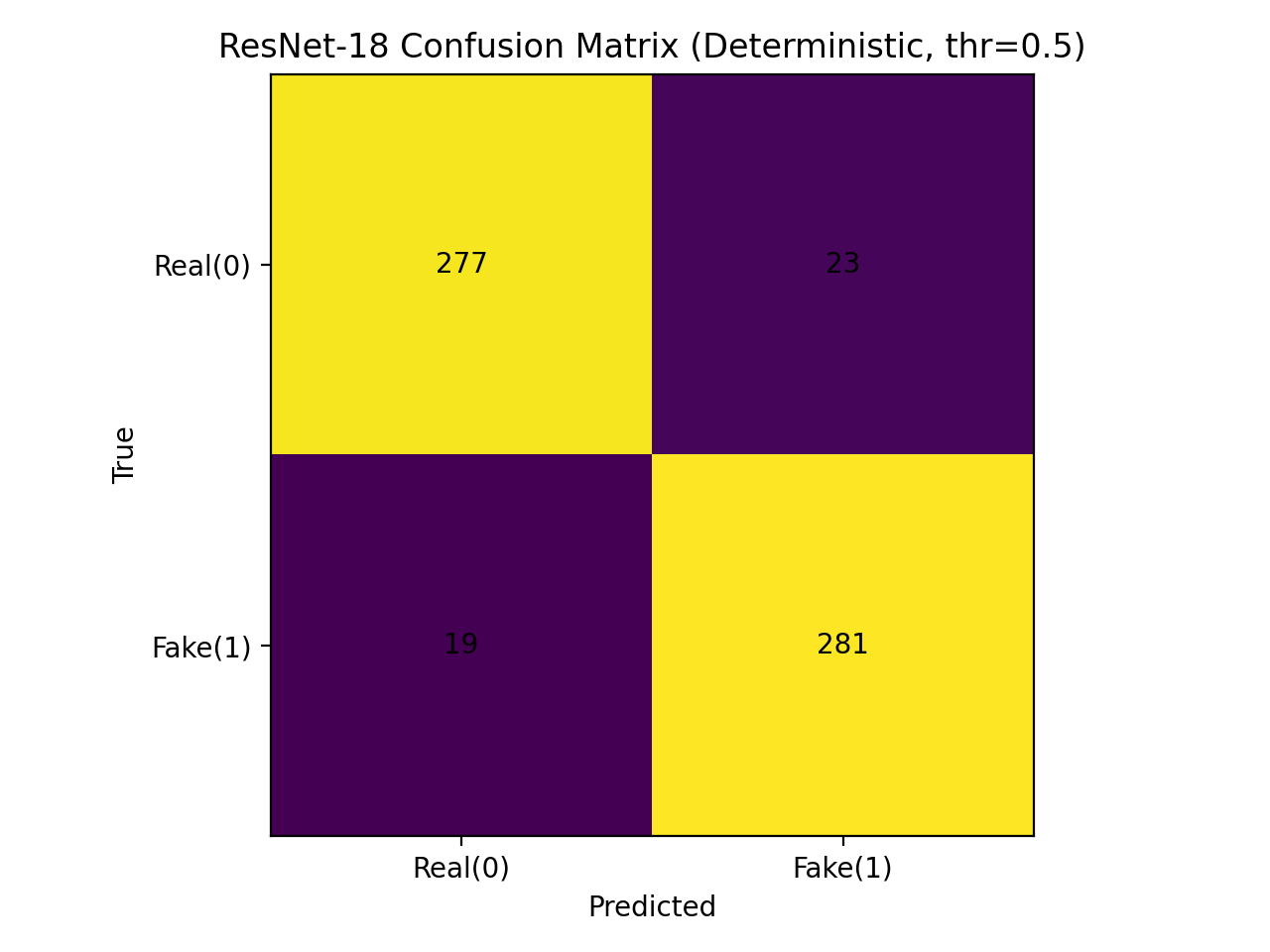
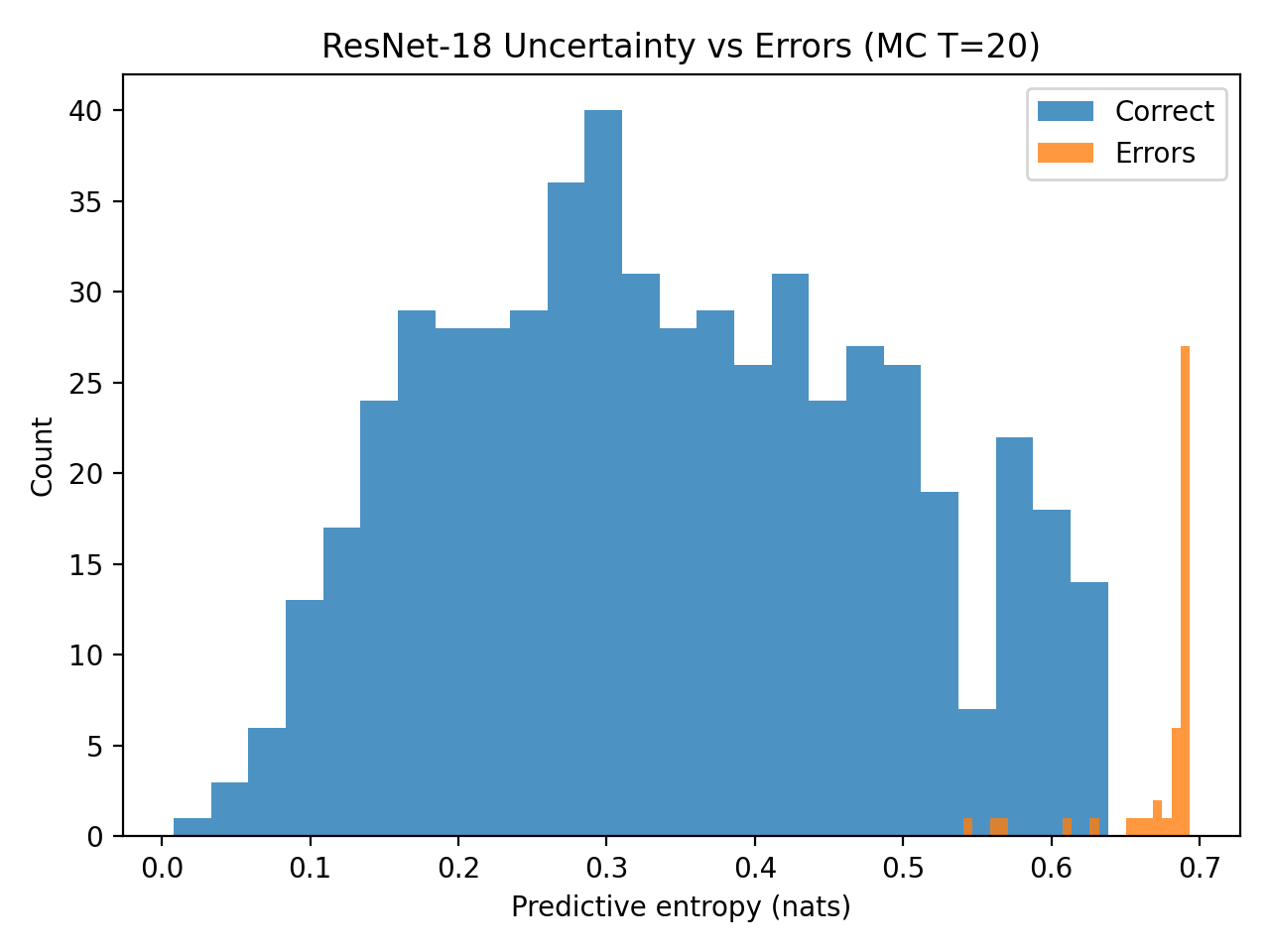
Достижение высокой дискриминационной способности модели недостаточно для обеспечения надежности предсказаний; необходимо оценивать уверенность модели в своих оценках. Высокая точность классификации сама по себе не гарантирует, что модель правильно идентифицирует случаи, близкие к границе принятия решения, или адекватно реагирует на входные данные, выходящие за рамки ее обучающей выборки. Оценка надежности предполагает количественное определение неопределенности предсказаний, позволяя пользователям понимать, насколько можно доверять результатам модели и принимать обоснованные решения, особенно в критически важных приложениях, где ложноположительные или ложноотрицательные результаты могут иметь серьезные последствия.
В сценариях с высокими ставками, таких как обнаружение дипфейков, надежность предсказаний имеет первостепенное значение. Ложноположительные результаты, когда подлинное изображение ошибочно классифицируется как дипфейк, могут привести к необоснованному обвинению или дискредитации. Ложноотрицательные результаты, когда дипфейк не обнаруживается, могут иметь серьезные последствия для национальной безопасности, репутации или личной жизни. Таким образом, критически важно не только обнаружить дипфейки, но и уверенно определить, является ли изображение подлинным, чтобы минимизировать риски, связанные с ошибочными решениями.
Оценка достоверности предсказаний модели является критически важной задачей, и неопределенность, учитываемый вывод (uncertainty-aware inference) предоставляет возможность количественно оценить эту уверенность при определении аутентичности изображений. Наши исследования показывают, что методы, использующие учет неопределенности, достигают значений ROC-AUC, близких к 1.0, что свидетельствует о сохранении высокой дискриминационной способности модели как при детерминированном, так и при вероятностном подходе к оценке. Это означает, что добавление оценки уверенности не приводит к снижению точности классификации, а лишь предоставляет дополнительную информацию о надежности предсказаний.
Калибровка Уверенности: Методы Надежного Вывода
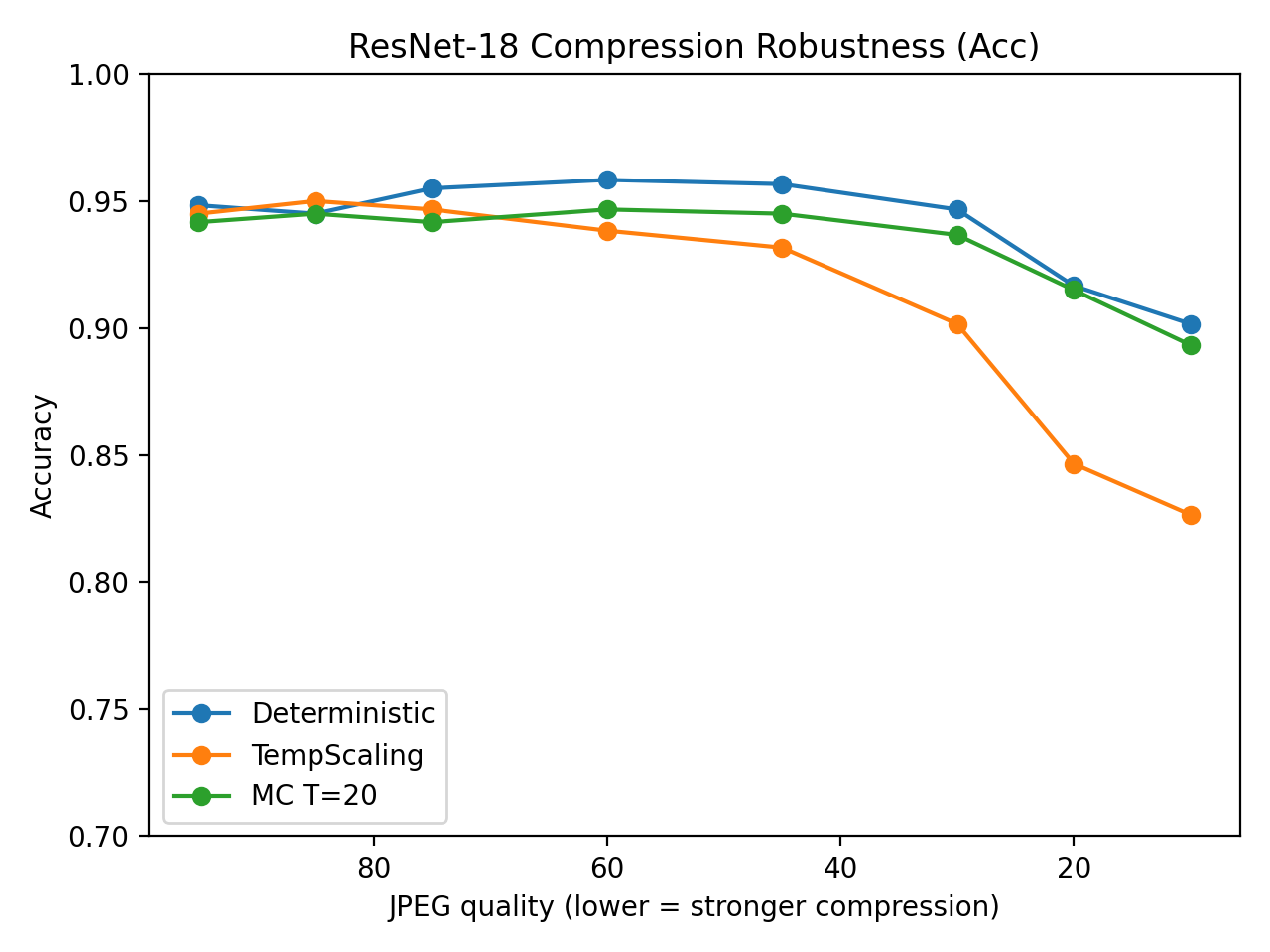
Методы, такие как Монте-Карло Дропаут, температурная калибровка (Temperature Scaling) и однопроходный стохастический вывод (Single-Pass Stochastic Inference), направлены на улучшение калибровки модели, то есть на приведение соответствия между предсказанными вероятностями и фактической точностью. Монте-Карло Дропаут, применяя случайное отключение нейронов во время предсказания, позволяет получить распределение вероятностей, отражающее неопределенность модели. Температурная калибровка масштабирует логиты, полученные от модели, для получения более откалиброванных вероятностей. Однопроходный стохастический вывод использует стохастические операции в прямом проходе для оценки неопределенности, не требуя дополнительных проходов. Все эти подходы стремятся к тому, чтобы вероятность, которую модель присваивает определенному классу, отражала реальную вероятность правильности этого предсказания.
Ансамблевые методы повышают надежность оценки неопределенности путем комбинирования прогнозов нескольких моделей. Вместо использования одной модели, ансамбль объединяет прогнозы, полученные от различных моделей, обученных на одних и тех же данных или с использованием различных архитектур и параметров. Это позволяет уменьшить дисперсию прогнозов и получить более стабильную и точную оценку вероятностей. При объединении прогнозов используются различные стратегии, такие как усреднение, взвешенное усреднение или более сложные методы, учитывающие производительность каждой модели в ансамбле. В результате, ансамблевые методы предоставляют более надежные оценки неопределенности, что критически важно для приложений, требующих высокой степени достоверности прогнозов.
Для количественной оценки калибровки модели используются метрики, такие как ожидаемая ошибка калибровки (ECE) и оценка Бриера. ECE измеряет разницу между средней уверенностью модели для правильных предсказаний и фактической точностью. Оценка Бриера, в свою очередь, оценивает общую точность вероятностных прогнозов. Результаты проведенных исследований показали, что применение определенных методов, ориентированных на учет неопределенности, привело к снижению ECE, однако данное улучшение не было последовательным для всех методов и статистическая значимость полученных результатов осталась ограниченной.
Робастность в Реальном Мире: Оценка Обобщения
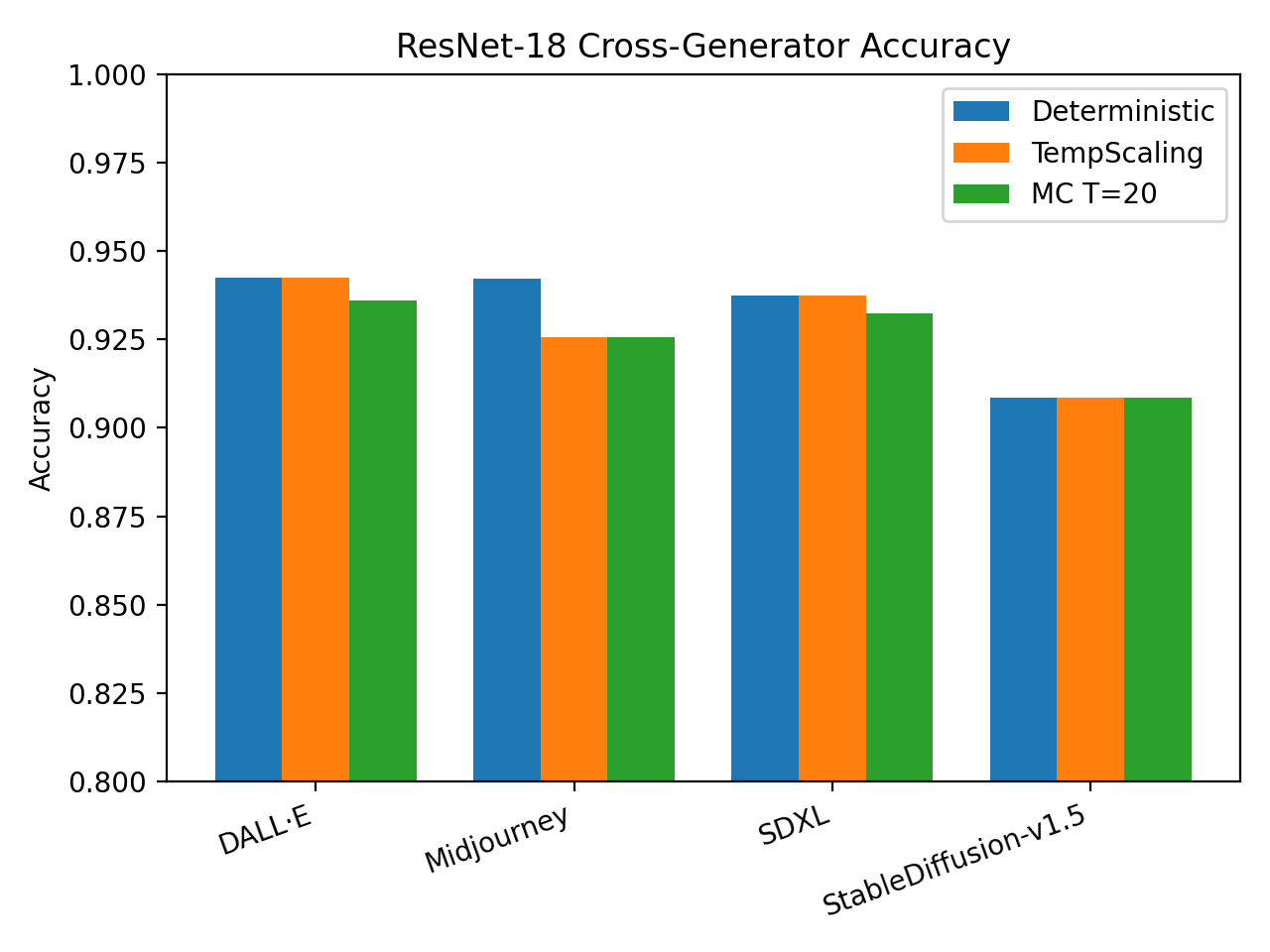
Оценка обобщающей способности моделей обнаружения дипфейков с использованием метода Generator-Disjoint OOD является критически важной процедурой. Данный подход предполагает тестирование модели на дипфейках, созданных генеративными сетями, которые не использовались в процессе обучения. Это позволяет оценить, насколько хорошо модель способна распознавать новые, ранее невиданные техники создания поддельных изображений и видео. В отличие от оценки на тех же самых генераторах, которые использовались при обучении, Generator-Disjoint OOD позволяет выявить истинную способность модели к обобщению и её устойчивость к изменениям в методах генерации дипфейков, что особенно важно в условиях постоянно развивающихся технологий.
Исследования показали, что на точность и надежность систем обнаружения дипфейков оказывают влияние не только способности модели к обобщению на неизвестные методы генерации, но и такие факторы, как разрешение изображений и методы нормализации. В частности, пониженное разрешение может значительно усложнить задачу обнаружения, поскольку важные артефакты, указывающие на манипуляции, становятся менее заметными. Кроме того, выбор метода нормализации изображений, используемый для приведения данных к единому масштабу, может существенно повлиять на эффективность алгоритмов обнаружения. Некорректная нормализация может привести к потере информации или усилению шума, что снижает способность модели различать подлинные и сгенерированные изображения. Таким образом, для обеспечения высокой надежности систем обнаружения необходимо учитывать и оптимизировать как характеристики входных данных, так и алгоритмы обработки изображений.
Оценка качества вероятностных предсказаний осуществлялась с помощью показателя отрицательного логарифмического правдоподобия (Negative Log-Likelihood), позволяющего судить об уверенности модели в своих оценках. Анализ результатов выявил, что, хотя метрика ROC-AUC не демонстрировала существенных статистических различий (менее 0.05 для некоторых сравнений), доверительные интервалы для ожидаемой калибровки ошибок (ECE) и точности зачастую перекрывались. Это указывает на то, что наблюдаемые улучшения калибровки не всегда были статистически значимыми и могут быть обусловлены случайными колебаниями, что подчеркивает необходимость комплексной оценки различных метрик для получения полной картины эффективности модели.
Исследование показывает, что неопределенность — не враг, а скорее индикатор. Система, осознающая границы своей компетенции, гораздо ценнее той, что выдает уверенный, но ошибочный вердикт. Особенно применительно к политическим дипфейкам, где цена ошибки может быть непомерно высока. Это напоминает о словах Дэвида Марра: «Любая модель — это заклинание, которое работает до первого продакшена». Ведь даже самая изощренная нейросеть, обученная на идеально чистых данных, столкнется с хаосом реального мира. Работа подчеркивает, что не столько важно добиться абсолютной точности, сколько научиться распознавать моменты, когда система начинает галлюцинировать, и вовремя отступить, используя методы селективного предсказания.
Куда же это всё ведёт?
Изучение неопределённости в обнаружении политических дипфейков, как показывает эта работа, не даёт универсального лекарства от обмана. Скорее, это — тонкая настройка шепота хаоса, попытка различить правду, спрятанную в шуме. Модели, уверенно заявляющие о своей правоте, часто оказываются самыми лживыми — идеальные графики всегда должны вызывать подозрение. Важно понимать, что повышение надёжности системы не означает победу над обманом, а лишь умение вовремя отказаться от сомнительных решений.
Следующий шаг, вероятно, лежит в плоскости не просто количественной оценки неопределённости, но и её качественного понимания. Что именно заставляет модель сомневаться? Какие признаки дипфейка наиболее трудно распознать? И, что важнее, как использовать эти знания для создания систем, способных не только детектировать, но и объяснять свои ошибки? Потому что цифры — это лишь тени, а истина прячется в полутонах.
Вероятно, в будущем нас ждёт отказ от идеи «абсолютной» детекции. Вместо этого, системы будут строиться на принципах селективного прогнозирования — осознанного отказа от выдачи вердикта в ситуациях высокой неопределённости. Шум — это не ошибка, а признак честности. И умение признать своё незнание, возможно, важнее, чем способность обманывать.
Оригинал статьи: https://arxiv.org/pdf/2602.10343.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-12 18:59