Автор: Денис Аветисян
Исследователи представили TimeMar — инновационную архитектуру, позволяющую создавать реалистичные и длинные временные ряды с повышенной эффективностью.

Предложенная модель TimeMar объединяет многомасштабное авторегрессионное моделирование, двойной VQ-VAE кодировщик и реконструкцию с грубым управлением для достижения высокого качества и масштабируемости генерации.
Несмотря на прогресс в генеративном моделировании, сохранение многомасштабной структуры и гетерогенности временных рядов остается сложной задачей. В данной работе, представленной под названием ‘TimeMar: Multi-Scale Autoregressive Modeling for Unconditional Time Series Generation’, предлагается новый подход, основанный на многомасштабном авторегрессионном моделировании с использованием кодирования на основе VQ-VAE и реконструкции с управляемым восстановлением сезонных сигналов. Это позволяет генерировать высококачественные временные ряды с меньшим количеством параметров и превосходить существующие методы по качеству и масштабируемости. Сможет ли предложенный фреймворк стать основой для новых, более эффективных методов анализа и прогнозирования временных рядов в различных областях?
В погоне за реалистичными временными рядами: вызовы и перспективы
Создание высокоточных временных рядов данных имеет первостепенное значение для широкого спектра применений, начиная от прогнозирования и заканчивая моделированием сложных систем. В области прогнозирования, например, точные временные ряды позволяют предсказывать будущие тенденции в экономике, финансах, потреблении энергии и других областях, что критически важно для принятия обоснованных решений. В сфере моделирования, реалистичные временные ряды необходимы для тестирования и оптимизации алгоритмов, обучения искусственного интеллекта и проведения виртуальных экспериментов, обеспечивая достоверные результаты и снижая риски, связанные с реальными испытаниями. Более того, в областях, связанных с мониторингом и анализом данных, таких как здравоохранение и климатология, высокоточные временные ряды позволяют выявлять аномалии, отслеживать изменения и прогнозировать будущие события с большей уверенностью, что способствует улучшению качества жизни и устойчивому развитию.
Традиционные методы генерации временных рядов часто оказываются неспособными адекватно отразить сложность реальных данных. В природе временные ряды характеризуются нелинейными зависимостями, проявляющимися на разных временных масштабах — от краткосрочных колебаний до долгосрочных трендов. Статистические модели, такие как ARIMA, хоть и эффективны для простых рядов, испытывают трудности при анализе данных с нелинейными взаимосвязями или при наличии шума на различных частотах. Более того, традиционные подходы, как правило, требуют ручной настройки параметров для каждого конкретного ряда, что делает их неэффективными при работе с большими объемами данных или при необходимости автоматической генерации разнообразных временных рядов. Неспособность уловить эти многомасштабные зависимости и сложные взаимосвязи приводит к генерации нереалистичных или искаженных данных, ограничивая применимость традиционных методов в задачах, требующих высокой точности и достоверности.
Существующие генеративные модели, такие как генеративно-состязательные сети (GAN) и вариационные автоэнкодеры (VAE), часто демонстрируют неудовлетворительные результаты при работе с данными временных рядов. Проблема заключается в том, что эти модели, успешно применяемые к изображениям или тексту, испытывают трудности при моделировании сложных временных зависимостей и нелинейных динамик, характерных для реальных временных рядов. В результате, генерируемые данные могут содержать артефакты, нереалистичные колебания или демонстрировать нестабильность, что существенно ограничивает их применимость в задачах прогнозирования, моделирования и анализа. Особенно остро проявляется эта проблема при работе с данными высокой частоты или длинными последовательностями, где даже небольшие ошибки могут накапливаться и приводить к значительным искажениям.
Точное воспроизведение временной динамики в различных масштабах представляет собой устойчивую проблему в области генерации временных рядов. Реальные данные часто демонстрируют закономерности, проявляющиеся на разных уровнях детализации — от долгосрочных трендов до краткосрочных колебаний и шумовых процессов. Существующие методы, как правило, испытывают трудности с одновременным моделированием этих многомасштабных зависимостей, что приводит к потере важных характеристик и снижению реалистичности генерируемых данных. Для эффективного решения этой задачи требуются модели, способные адаптироваться к различным временным масштабам и улавливать взаимосвязи между ними, обеспечивая таким образом генерацию высококачественных и достоверных временных рядов, пригодных для широкого спектра приложений — от прогнозирования финансовых рынков до моделирования климатических изменений.
TimeMAR: многомасштабный подход к генерации временных рядов
TimeMAR решает задачу реалистичной генерации временных рядов посредством комплексного подхода, объединяющего авторегрессионное моделирование, кодирование с использованием VQ-VAE и реконструкцию с грубым управлением. Авторегрессионная модель обеспечивает последовательную генерацию данных, учитывая предыдущие значения временного ряда. VQ-VAE (Vector Quantized Variational Autoencoder) используется для сжатия данных во временном ряду в дискретное представление, что упрощает моделирование долгосрочных зависимостей. Реконструкция с грубым управлением дополняет этот процесс, обеспечивая соответствие сгенерированных данных общим тенденциям и сезонности исходного временного ряда, повышая стабильность и реалистичность генерируемых данных.
Для разделения базовых закономерностей временных рядов в TimeMAR используется разложение на тренд и сезонность. Этот процесс позволяет выделить отдельные компоненты, подверженные различным динамикам. Далее, полученные компоненты обрабатываются независимо друг от друга посредством двойного (Dual-Path) кодирования. Такой подход позволяет модели более эффективно захватывать и воспроизводить сложные временные зависимости, поскольку тренд и сезонность кодируются и декодируются независимо, что повышает стабильность и реалистичность генерируемых данных.
Иерархическая квантизация в TimeMAR позволяет представить временные ряды в виде дискретных последовательностей токенов, что способствует эффективному захвату временных зависимостей на различных масштабах. Процесс включает в себя многоуровневое разделение временного ряда на сегменты и присвоение каждому сегменту уникального токена из дискретного словаря. Несколько уровней квантизации позволяют моделировать как краткосрочные, так и долгосрочные зависимости, поскольку каждый уровень захватывает информацию о временном ряде с разной степенью детализации. Такое представление позволяет модели эффективно обучаться на дискретных данных, снижая вычислительные затраты и улучшая стабильность генерации по сравнению с работой непосредственно с непрерывными значениями временного ряда.
Целью TimeMAR является генерация реалистичных и стабильных временных рядов посредством интеграции нескольких методов. Комбинация авторегрессионного моделирования, кодирования VQ-VAE и реконструкции с грубым руководством позволяет создавать данные, точно отражающие сложные временные зависимости. Стабильность обеспечивается за счет контроля над процессом генерации на различных масштабах, предотвращая отклонения и обеспечивая согласованность генерируемых рядов. Реалистичность достигается за счет моделирования как трендов, так и сезонности, что позволяет воссоздавать сложные паттерны, характерные для реальных временных рядов.
Подтверждение эффективности TimeMAR: количественная и качественная оценка
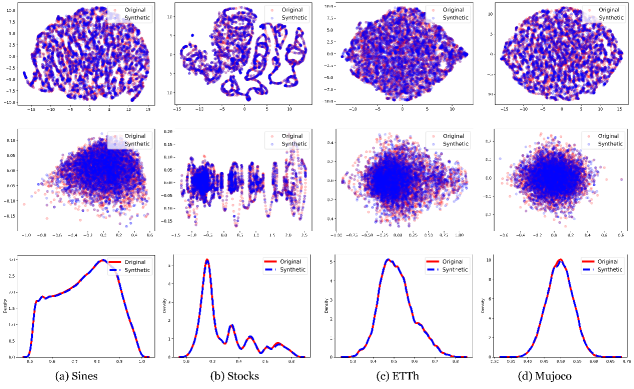
Генерация временных рядов с использованием TimeMAR демонстрирует повышенный уровень реалистичности, что подтверждается как качественным, так и количественным анализом. Качественная оценка проводилась визуальным анализом сгенерированных данных для выявления артефактов или неправдоподобных паттернов. Количественная оценка осуществлялась с использованием различных метрик, включая Predictive Score для оценки точности прогнозирования и Context-FID для измерения статистического сходства с реальными данными. Полученные результаты свидетельствуют о значительном улучшении реалистичности генерируемых временных рядов по сравнению с существующими методами, что подтверждает эффективность предложенного подхода.
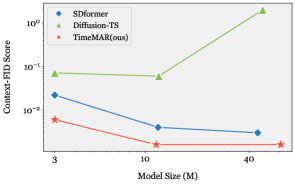
Для оценки производительности TimeMAR использовались два ключевых показателя: Predictive Score и Context-FID. Predictive Score предназначен для количественной оценки точности прогнозирования временных рядов, позволяя определить, насколько хорошо модель предсказывает будущие значения на основе исторических данных. Context-FID (Frechet Inception Distance) измеряет статистическое сходство между сгенерированными и реальными данными, оценивая разницу в распределениях признаков. Низкое значение Context-FID указывает на высокую степень соответствия сгенерированных данных реальным временным рядам, что свидетельствует о реалистичности и правдоподобности модели.
Для оценки степени реалистичности генерируемых временных рядов используется метрика Discriminative Score, определяющая, насколько хорошо сгенерированные образцы отличаются от реальных данных. Низкое значение Discriminative Score указывает на высокую степень схожести между сгенерированными и реальными данными, что свидетельствует о высокой fidelity модели. В ходе экспериментов TimeMAR демонстрирует значение Discriminative Score менее 0.1 на различных наборах данных, подтверждая способность генерировать реалистичные временные ряды, практически неотличимые от реальных.
В ходе экспериментов TimeMAR демонстрирует стабильное превосходство над существующими методами генерации временных рядов. На наборе данных ETTh снижение показателя Context-FID достигло 87.5% по сравнению с SDformer. Набор данных, включающий Sines, Stocks и Energy, показал снижение Discriminative Score на 50% при использовании TimeMAR, что свидетельствует о повышенном качестве генерируемых данных и их большей схожести с реальными временными рядами по сравнению с результатами, полученными с помощью SDformer.
Влияние и перспективы: расширение возможностей анализа временных рядов
TimeMAR представляет собой эффективный инструмент для увеличения объемов данных, позволяющий создавать синтетические наборы данных и, тем самым, повышать производительность моделей машинного обучения. Возможность генерировать реалистичные временные ряды особенно ценна в ситуациях, когда доступ к реальным данным ограничен или дорогостоящ. Создавая искусственные данные, близкие к реальным, TimeMAR позволяет тренировать модели более эффективно, улучшая их обобщающую способность и устойчивость к шуму. Это особенно важно для задач, где точность прогнозирования критична, например, в финансовом моделировании или прогнозировании погоды, где даже небольшое улучшение может привести к значительным результатам.
Возможность TimeMAR генерировать реалистичные временные ряды данных открывает значительные перспективы для различных областей применения. В финансовом моделировании это позволяет создавать синтетические данные для тестирования и улучшения алгоритмов прогнозирования рыночных тенденций, а также для оценки рисков. В метеорологии, сгенерированные временные ряды могут быть использованы для расширения исторических данных, что повышает точность моделей прогнозирования погоды и климатических изменений. Не менее важна эта возможность и в сфере обнаружения аномалий — создание реалистичных, но содержащих отклонения, данных позволяет обучать системы, способные эффективно выявлять необычные события в различных потоках данных, будь то мошеннические транзакции или сбои в работе оборудования. Таким образом, TimeMAR представляет собой ценный инструмент для повышения надежности и точности систем, работающих с временными рядами.
Перспективные исследования направлены на объединение TimeMAR с другими генеративными моделями, в частности, диффузионными моделями. Такая интеграция позволит значительно расширить возможности TimeMAR в создании синтетических временных рядов, обеспечивая генерацию данных с еще более высокой степенью реалистичности и детализации. Предполагается, что комбинирование преимуществ TimeMAR — эффективной аугментации и управления структурой данных — с мощными возможностями диффузионных моделей в области генерации сложных распределений, приведет к созданию гибридных систем, способных решать задачи, недоступные для каждой из моделей по отдельности. В результате, появится возможность генерировать временные ряды, максимально приближенные к реальным данным, что критически важно для повышения точности и надежности моделей машинного обучения в различных областях, включая финансовый анализ и прогнозирование погоды.
Перспективным направлением развития системы TimeMAR представляется расширение ее функциональности для обработки многомерных временных рядов. В текущей реализации система ориентирована на анализ одномерных данных, однако реальные процессы часто характеризуются взаимосвязанными переменными. Интеграция возможности моделирования корреляций между различными временными рядами позволит создавать более реалистичные и информативные синтетические наборы данных. Кроме того, включение в алгоритм предметно-ориентированных знаний, например, специфических для финансового моделирования или прогнозирования погоды, значительно повысит точность и релевантность генерируемых данных. Такой подход позволит TimeMAR стать незаменимым инструментом для решения широкого спектра практических задач, требующих анализа сложных временных процессов.
Исследование представляет TimeMAR — попытку покорить неизбежный техдолг в генерации временных рядов. Авторы предлагают многомасштабный подход, комбинируя авторегрессию с VQ-VAE, что, конечно, выглядит элегантно. Однако, как показывает практика, масштабируемость любой модели — это иллюзия до первого серьёзного прогона под нагрузкой. Время покажет, насколько эффективно TimeMAR справляется с реальностью, но уже сейчас очевидно, что стремление к идеальной генерации данных — это постоянная борьба с энтропией. Как однажды заметил Роберт Тарджан: «Программирование — это больше искусство, чем наука». И в этом искусстве всегда найдется место для компромиссов и неожиданных решений.
Что дальше?
Представленная работа, безусловно, демонстрирует улучшение в области генерации временных рядов. Однако, стоит помнить: каждая элегантная архитектура — это просто отложенный технический долг. Проблема масштабируемости, хоть и смягчена, никуда не делась. В реальных условиях, данные всегда будут грязнее, шумнее и сложнее, чем в контролируемых экспериментах. И тогда даже самые продвинутые модели столкнутся с необходимостью обработки пропусков, выбросов и аномалий — а это уже совсем другая история.
В перспективе, вероятно, потребуется смещение фокуса с улучшения самих моделей генерации к более эффективным методам валидации сгенерированных данных. Ведь легко создать красивую, но бессмысленную последовательность. Гораздо сложнее убедиться, что она действительно отражает скрытые закономерности и может быть использована для принятия решений. Иначе, это просто ещё один способ автоматизировать производство случайных чисел.
Если код выглядит идеально — значит, его ещё никто не запустил в продакшене. Поэтому, в ближайшем будущем, вероятно, мы увидим больше исследований, направленных на разработку инструментов для мониторинга, отладки и автоматического исправления ошибок в сгенерированных временных рядах. Иначе говоря, на создание систем, которые будут спасать нас от последствий нашей же изобретательности.
Оригинал статьи: https://arxiv.org/pdf/2601.11184.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-20 15:42