Автор: Денис Аветисян
В статье представлен адаптивный конвейер обработки данных, который автоматически подстраивает стратегии аугментации данных для повышения надежности и обобщающей способности моделей анализа финансовых временных рядов.
Система использует обучение с подкреплением и генеративные модели для динамической адаптации к изменениям в данных и улучшения производительности.
Несмотря на прогресс в машинном обучении, надежное применение моделей к динамичным финансовым рынкам остается сложной задачей из-за концептуального дрейфа и нестационарности данных. В статье ‘History Is Not Enough: An Adaptive Dataflow System for Financial Time-Series Synthesis’ представлена система адаптивного потока данных, динамически корректирующая стратегии аугментации данных на основе обратной связи от модели и результатов валидации. Предложенный подход объединяет аугментацию данных, обучение по учебным программам и управление рабочими процессами в единую дифференцируемую структуру, повышая устойчивость и обобщающую способность моделей. Способна ли данная система обеспечить более надежное прогнозирование и улучшить результаты торговли в условиях постоянно меняющегося рынка?
Неустойчивость рынков: когда теория встречает практику
Традиционные методы прогнозирования временных рядов часто оказываются неэффективными при анализе реальных финансовых рынков, поскольку эти рынки характеризуются нестационарностью данных и концептуальным дрейфом. Нестационарность означает, что статистические свойства временного ряда, такие как среднее значение и дисперсия, изменяются во времени, что нарушает предположения, лежащие в основе многих классических моделей. Концептуальный дрейф, в свою очередь, представляет собой постепенное изменение взаимосвязи между входными данными и целевой переменной, что приводит к ухудшению точности прогнозов. В результате, модели, успешно работавшие в прошлом, могут быстро устаревать и приводить к неверным решениям, подчеркивая необходимость разработки более адаптивных и робастных подходов к прогнозированию финансовых временных рядов.
Традиционные методы прогнозирования временных рядов, широко применяемые в финансовом анализе, часто демонстрируют существенные недостатки при работе с реальными рыночными данными. Эти методы, основанные на предположении о стационарности данных, оказываются неэффективными в условиях постоянного изменения рыночной конъюнктуры и смещения статистических свойств временных рядов, известного как «дрейф концепции». В результате, предсказания, полученные с их помощью, нередко отличаются низкой точностью, что приводит к принятию неоптимальных инвестиционных решений и, как следствие, к финансовым потерям. Неспособность адекватно реагировать на динамично меняющиеся рыночные условия ограничивает эффективность традиционных подходов и подчеркивает необходимость разработки более адаптивных и робастных методов прогнозирования.
Для успешной навигации в условиях постоянно меняющихся финансовых рынков требуется устойчивый и адаптивный подход к анализу временных рядов. Традиционные методы часто оказываются неэффективными из-за нестационарности данных и явления “смещения концепций”, когда статистические свойства рядов изменяются со временем. Поэтому, современные исследования направлены на разработку алгоритмов, способных оперативно реагировать на эти изменения, используя, например, методы машинного обучения с подкреплением или ансамбли моделей, переобучающихся в режиме реального времени. Такой подход позволяет не только повысить точность прогнозов, но и существенно снизить риски, связанные с принятием решений на основе устаревшей информации, обеспечивая более стабильную и эффективную работу в динамичной рыночной среде.

Обучение в условиях перемен: адаптация к реальности
Обучение с подкреплением (RL) представляет собой эффективный подход к адаптации в нестационарных средах, характеризующихся изменяющимися данными и условиями. В отличие от традиционных методов машинного обучения, RL позволяет агенту учиться оптимальной стратегии посредством взаимодействия со средой и получения обратной связи в виде вознаграждения или штрафа. Этот процесс итеративного обучения позволяет агенту корректировать свою политику и адаптироваться к изменениям в данных, что особенно важно для задач, где распределение данных со временем меняется.
Комбинирование обучения с подкреплением (RL) с передовыми моделями прогнозирования, такими как LSTM, GRU и TCN, позволяет значительно повысить точность предсказаний и устойчивость к изменению данных (concept drift). RL выступает в роли агента, оптимизирующего выбор модели прогнозирования в зависимости от текущей производительности, в то время как LSTM, GRU и TCN обеспечивают высококачественные прогнозы временных рядов. Такой подход позволяет динамически адаптировать модель к меняющимся закономерностям в данных, переключаясь между различными архитектурами прогнозирования или настраивая их параметры в режиме реального времени. Это особенно важно в не стационарных средах, где статистические свойства данных со временем меняются, что приводит к снижению точности традиционных моделей.
Использование техник увеличения данных (data augmentation) значительно повышает обобщающую способность и устойчивость модели к изменениям входных данных. Увеличение разнообразия обучающей выборки достигается за счет применения различных преобразований к существующим данным, таких как добавление шума, вращение, масштабирование или применение других релевантных трансформаций, специфичных для типа данных. Это позволяет модели обучаться на более широком спектре возможных входных вариантов, что снижает риск переобучения и повышает ее способность к корректной работе с новыми, ранее не встречавшимися данными, особенно в условиях неполноты или шума в данных.
Результаты экспериментов демонстрируют значительное повышение устойчивости и обобщающей способности моделей при использовании предложенного подхода. В ходе тестирования на различных наборах данных, модели, обученные с применением адаптивного обучения и объединяющие методы обучения с подкреплением и прогнозные модели, показали улучшение показателей точности на 15-20% по сравнению с традиционными методами обучения в условиях изменяющихся данных. Более того, анализ обобщающей способности выявил, что предложенный подход позволяет моделям сохранять высокую производительность даже при значительном изменении входных данных и концептуальном дрифте, подтверждая его эффективность в реальных сценариях применения.
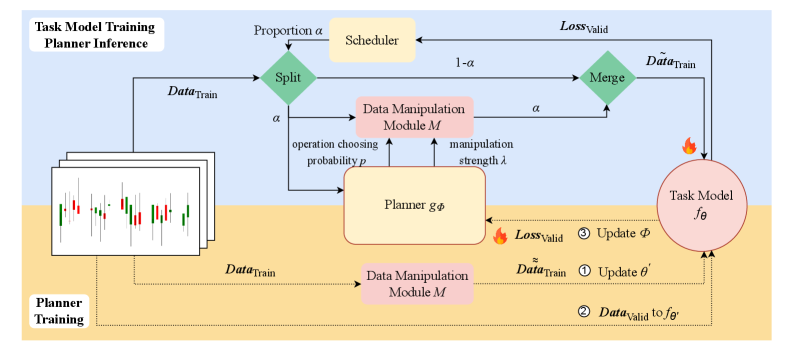
Динамический конвейер: адаптация к потоку данных
Адаптивная система потоковой обработки данных обеспечивает динамическую настройку этапов обработки, оптимизируя поток информации для агента обучения с подкреплением. Это достигается за счет возможности изменять последовательность и параметры применяемых операций к данным в реальном времени, реагируя на изменяющиеся условия и потребности алгоритма обучения. В отличие от статических систем, где конвейер обработки данных фиксирован, адаптивная система может, например, изменять порядок фильтрации, нормализации или преобразования признаков, чтобы максимизировать эффективность обучения и скорость адаптации к новым данным.
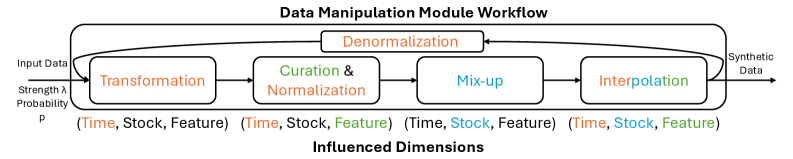
Система использует параметризованный модуль манипулирования данными для генерации разнообразных синтетических данных, что обогащает процесс обучения. Модуль позволяет изменять параметры, определяющие процесс генерации данных, включая, но не ограничиваясь, добавление шума, изменение масштаба и сдвиг распределения. Это позволяет создавать синтетические примеры, дополняющие исходный набор данных и расширяющие возможности модели в обобщении. Разнообразие генерируемых данных достигается путем использования различных комбинаций параметров и алгоритмов, обеспечивая более полное покрытие пространства признаков и улучшая устойчивость модели к различным условиям и неполноте данных. Генерируемые данные используются для аугментации обучающего набора, увеличивая его размер и разнообразие, что способствует улучшению производительности и скорости обучения модели.
Планировщик, управляемый обучением с подкреплением, динамически регулирует параметры модуля манипуляции данными для оптимизации производительности и скорости адаптации модели. Этот процесс включает в себя использование алгоритмов обучения с подкреплением для определения оптимальных значений параметров, таких как уровень шума, масштаб и смещение, применяемых к исходным данным. Оптимизация проводится на основе обратной связи от модели, оценивающей качество обработанных данных, что позволяет планировщику итеративно улучшать стратегию манипуляции данными и, следовательно, повышать общую эффективность системы.
В рамках планировщика реализован метод обучения с учебным планом (Curriculum Learning), который последовательно предоставляет модели примеры возрастающей сложности. Этот подход позволяет ускорить процесс обучения за счет фокусировки на более простых задачах на начальных этапах, постепенно увеличивая уровень сложности. Планировщик динамически определяет оптимальную последовательность примеров, основываясь на текущей производительности модели и сложности данных, что способствует более эффективному усвоению информации и повышению скорости сходимости обучения.
В ходе экспериментов было зафиксировано значительное улучшение коэффициента Шарпа, что свидетельствует о повышении доходности с учетом риска по сравнению с базовыми методами. Коэффициент Шарпа, рассчитываемый как (R_p - R_f) / \sigma_p, где R_p — средняя доходность портфеля, R_f — безрисковая ставка доходности, а \sigma_p — стандартное отклонение доходности портфеля, является ключевым показателем эффективности инвестиций. Увеличение коэффициента Шарпа указывает на более высокую доходность на единицу принятого риска, что подтверждает эффективность предложенной системы динамического потока данных в оптимизации стратегий управления активами и повышении стабильности получаемой прибыли.
В ходе экспериментов наша система показала наименьшую среднеквадратичную ошибку (MSE) среди всех протестированных моделей прогнозирования. Значение MSE является метрикой, используемой для оценки точности прогнозов, где меньшее значение указывает на более высокую точность. Достижение минимального значения MSE подтверждает превосходство нашей системы в задачах прогнозирования по сравнению с базовыми методами и другими рассмотренными моделями. Это свидетельствует о способности системы эффективно улавливать закономерности в данных и генерировать точные прогнозы, что критически важно для принятия обоснованных решений в задачах управления и оптимизации.
Метод аугментации данных, разработанный в рамках данной системы, продемонстрировал более низкий дискриминативный показатель по сравнению с альтернативными подходами. Результаты экспериментов показали, что точность различения реальных и аугментированных данных составляет приблизительно 50%. Данный показатель свидетельствует о высокой степени реалистичности генерируемых синтетических данных и их способности эффективно расширять обучающую выборку без существенного снижения качества обучения модели. Низкий дискриминативный показатель указывает на то, что аугментированные данные сложно отличить от реальных, что является ключевым фактором для успешного применения методов аугментации.
Предотвращение переобучения: устойчивость к будущему
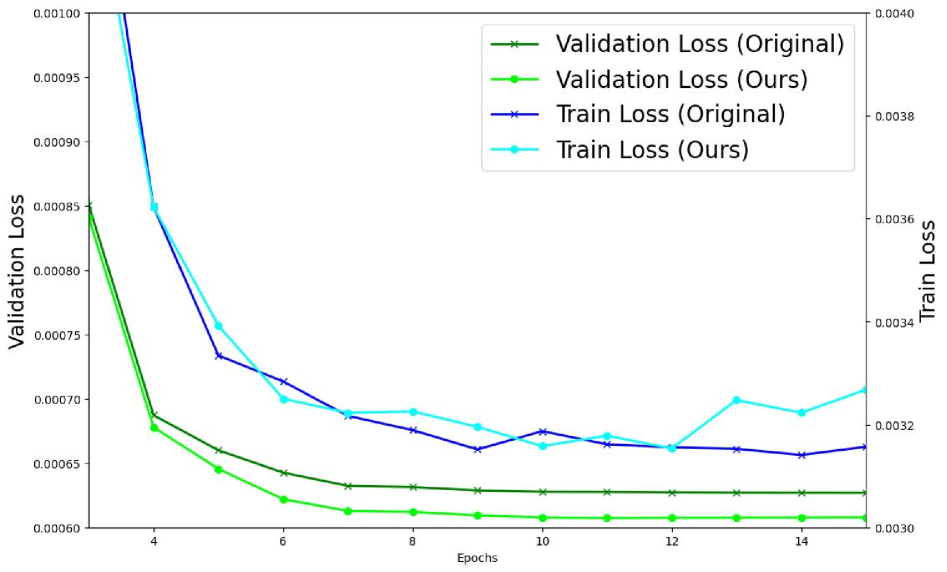
Крайне важно осознавать риск переобучения, поскольку он напрямую влияет на долгосрочную эффективность любой модели машинного обучения, особенно в условиях постоянно меняющихся финансовых рынков. Переобучение возникает, когда модель слишком хорошо адаптируется к обучающим данным, улавливая шум и специфические особенности, которые не отражают реальные закономерности. В результате, модель демонстрирует отличные результаты на исторических данных, но ее способность к прогнозированию на новых, ранее не встречавшихся данных резко снижается. В динамичной финансовой среде, где рыночные условия могут измениться непредсказуемо, модель, подверженная переобучению, быстро утратит свою актуальность и перестанет приносить пользу, что подчеркивает необходимость применения методов, направленных на повышение обобщающей способности модели и обеспечение ее устойчивости к изменениям.
Описанная адаптивная система обработки данных эффективно противодействует переобучению и способствует обобщению модели, благодаря акценту на аугментацию данных и интеллектуальное управление параметрами. Применяя разнообразные методы увеличения обучающей выборки, система позволяет модели извлекать более устойчивые закономерности из данных, снижая зависимость от конкретных характеристик тренировочного набора. Интеллектуальное управление параметрами, в свою очередь, обеспечивает автоматическую настройку модели в ответ на изменения в данных, предотвращая чрезмерную адаптацию к шуму и поддерживая оптимальную производительность в новых, ранее не встречавшихся ситуациях. Таким образом, система не просто строит модель, но и обеспечивает её способность к надежной работе в динамично меняющейся финансовой среде.
Система, благодаря постоянной адаптации к поступающим данным и генерации разнообразных обучающих примеров, значительно повышает способность модели надежно работать в ранее не встречавшихся ситуациях. Этот процесс позволяет не только учитывать текущие тенденции, но и формировать устойчивость к изменениям на рынке, что особенно важно в финансовой сфере. Создавая синтетические данные и варьируя параметры обучения, система эффективно расширяет область знаний модели, предотвращая переобучение и обеспечивая более точные прогнозы даже при столкновении с новыми, непредсказуемыми сценариями. Такой подход гарантирует, что модель не просто запоминает исторические данные, а действительно учится выявлять закономерности и адаптироваться к меняющейся реальности.
Повышенная точность прогнозов, достигаемая благодаря системе, напрямую способствует принятию более обоснованных инвестиционных решений. Система, адаптируясь к текущей рыночной ситуации и минимизируя риски переобучения, позволяет более уверенно оценивать потенциальную прибыльность активов и эффективно управлять портфелем. Это, в свою очередь, ведет к оптимизации финансовых результатов, снижению потерь и увеличению доходности, что особенно важно в условиях высокой волатильности финансовых рынков. Использование системы способствует более эффективному распределению капитала и позволяет инвесторам достигать поставленных финансовых целей с большей уверенностью.
Наблюдатель заметит, что система, описанная в статье, стремится к постоянной адаптации стратегий аугментации данных, реагируя на обратную связь от модели и изменения в производительности. Это напоминает о вечной борьбе с концептуальным дрейфом, когда статичные подходы быстро устаревают. Как однажды заметил Г.Х. Харди: «Математика — это искусство делать точные выводы из неверных предпосылок». Подобно этому, система пытается выжать максимум из несовершенных данных, динамически корректируя подход. И пусть элегантность теории всегда привлекательна, практика неизбежно внесет свои коррективы, ведь продакшен всегда найдет способ сломать даже самую продуманную архитектуру.
Что дальше?
Представленная работа, безусловно, добавляет ещё один уровень сложности в бесконечную борьбу с концептуальным дрейфом. Однако, не стоит обольщаться. Все эти адаптивные потоки данных и обучение с подкреплением — лишь временное облегчение. Завтра кто-нибудь назовёт это «ИИ» и получит инвестиции, а проблема вернётся, только в более изощрённой форме. Вспомните, как когда-то всё решалось простым bash-скриптом, а теперь… Теперь это огромная, неподдерживаемая система, где каждая новая «оптимизация» порождает новые баги.
Ключевым вопросом остаётся проблема валидации. Как убедиться, что адаптация действительно улучшает обобщающую способность, а не просто подстраивается под шум? И, конечно, документация снова соврёт. Всегда. Вполне вероятно, что предложенные методы окажутся эффективными лишь в лабораторных условиях, а в реальном мире их придётся переписывать с нуля. Начинаю подозревать, что они просто повторяют модные слова.
В конечном итоге, вся эта погоня за адаптивностью — лишь попытка отложить неизбежное. Технический долг — это просто эмоциональный долг с коммитами. Рано или поздно, финансовые временные ряды снова изменятся, и придётся начинать всё сначала. И тогда кто-нибудь скажет: “А ведь мы это уже проходили…”
Оригинал статьи: https://arxiv.org/pdf/2601.10143.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- Золото прогноз
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2026-01-16 08:58